微软联合清华推出 RetNet,能否取代 Transformer?
53 个回答


谢致知任务的邀请,2小时限时任务,看得很仓促,如有疏漏,欢迎探讨。
太长不看:
- RetNet结构想法很简单:爆改Transformers,既能并行训练,又能串行解码。但说到底,还是Transformer的一个变种。
- 这篇文章牛逼之处在于,不光有语言模型的PPL,还有下游任务的实验:6.7B+类似SuperGLUE。
- 影响方面,让子弹再飞一会儿。个人比较担忧长距离依赖的建模能力。
RetNet结构想法很简单:爆改Transformers,既能并行训练,又能串行解码
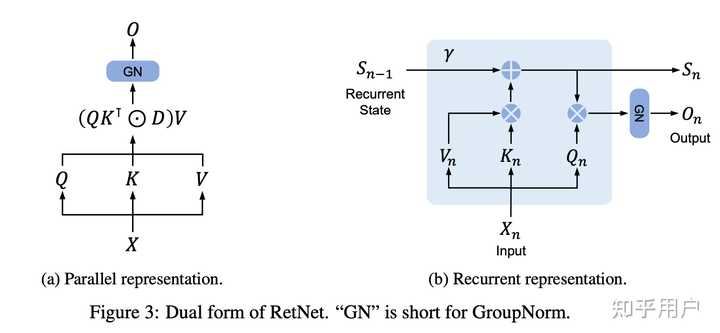

1、我们看下这张图,先看右边,其实改得很粗暴。
Transformers使用query和key计算权重分布,对value加权。然而,在因果解码下,所有前序节点都会有key和value,所以解码需要O(n)的复杂度。
而RetNet为了解码只用O(1)的复杂度,把所有前序节点的表示拍成一个向量。咋拍呢?就是像RNN一样循环更新。用key和value计算出一个向量之后,去更新权重向量S,这个相当于RNN中的记忆向量。而输出,就是query和向量S的计算结果。
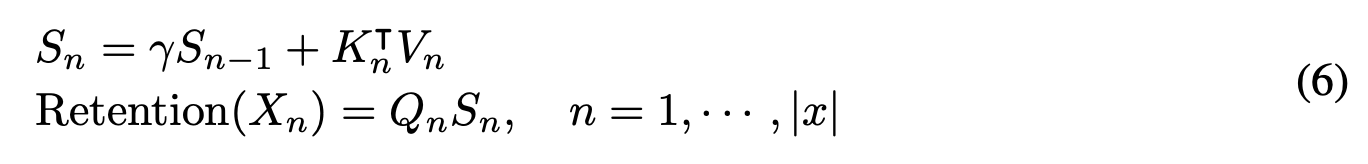

注意看,上面这个公式是不是和下图的RNN很像?但是有一点差别,标准RNN是当前输入和记忆向量接起来过全连接层,而RetNet是用一个实数γ做权重,进行线性加权。这点改动,在后面很重要,记住,要考。


2、我们再看左图,为了方便阅读,我又把图复制了一份。
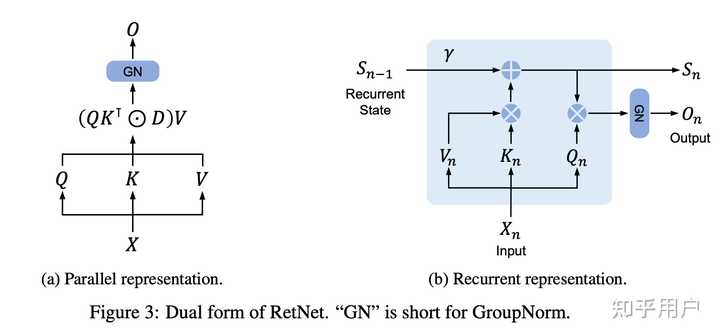

看出来和标准Transformers有什么差别了么?除了GroupNorm这些边角料之外,最重要的是修改了QKV的组合方式。
标准Transformers是: softmax(QK)V
而RetNet是:(QK·D)V
除去和尺度、稀疏化等相关的softmax之外,只差了一个D:
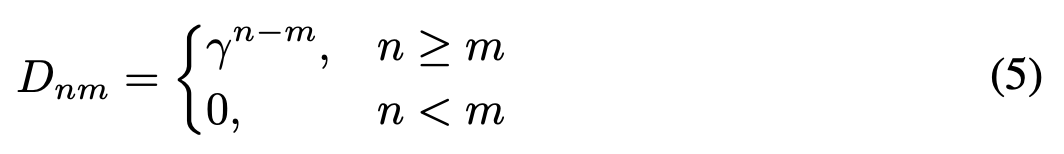

可以看到,这个D就是之前公式6里,合并RNN(划掉,RetNet)记忆节点的线性加权权重系数。相当于一个逐渐衰减的不可训练的相对位置编码。
这样,就完美的让左右两种形式统一起来:两张图,算的是同一样东西。
显然,左边和Transformers很像,可以并行训练。右图和RNN很像,可以每个时刻O(1)空间复杂度地串行解码。
有了这个优势之后,下图(左半)就理所应当了。

剩下的改动,应该就是一些为了配合上述设计,结合工程实践结果,做的配件了。这里不去多说。
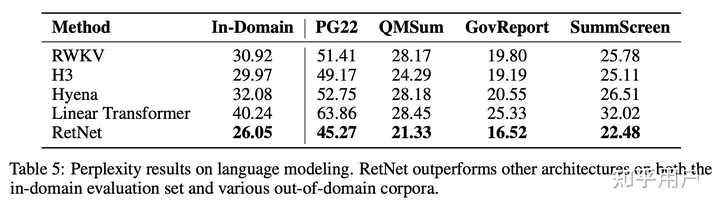
这篇文章牛逼之处在于,不光有语言模型的PPL,还有下游任务的实验
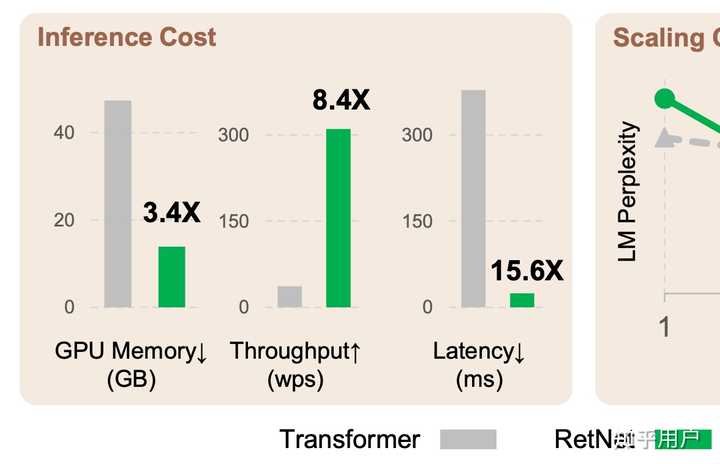
上图的inference cost看上去很唬人,被放了图1。但看了模型结构之后,这个实验结果很理所当然,没看头。包括图6的结果也是。
一方面,LLM的PPL吊打之前优化Transformer的工作,这个算是基操。

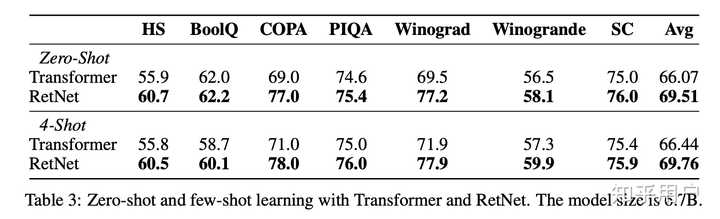
而下游任务表现,很好地展现了这个结构训练的语言模型对下游任务的帮助。在67亿参数规模上的实验,也不算抠门。参考价值还是不错的。美中不足的是,下游任务测得比较少,测得看上去和SuperGLUE重叠度很高但又不完全一样,有cherry picking的嫌疑。但我要是审稿人的话,这组实验我会买账。
这里要批评一下本文作者前几天的一篇工作了:https://arxiv.org/pdf/2307.02486.pdf。饼画得很大,实验看着不够过瘾呀。

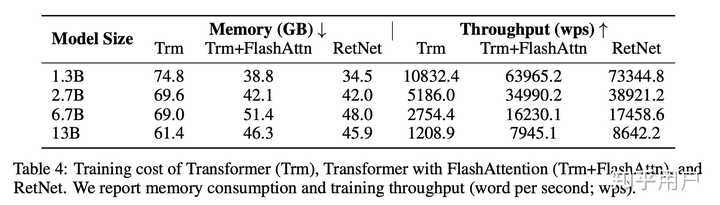
训练效率的对比,提升其实不重要,重点是展示了这个结构的可行性。当然,想想去掉了softmax这个复杂操作,效率有点提升也算正常。

影响方面,让子弹再飞一会儿
Transformers能火成这样,最重要的还是下游任务,以及LLM的应用。
所以我们还需要更多的实验,看看RetNet的表现是可复现的么?在不同尺度和不同任务上的表现是否稳定?基于RetNet的LLM是否可以取得相当的表现?
毕竟,魔改Transformers时,那个D矩阵,让人很担心RetNet模型建模长距离依赖的能力。这个担忧在循环更新部分的记忆单元也会体现。而我们知道,建模长距离依赖,是LLM推理能力的重要基础。
所以,能否取代Transformers,让子弹在飞一会儿吧。
说句题外话,RetNet也只能算Transformers的一个变种,就算取代了Transformers,和Transformers取代LSTM的意义也还是不一样的。

简单来说,retnet = linear attention + rope + 显式衰减(即 \gamma ),其中前两点算是已有的linear attention工作了,最后的“显式衰减“属于新的,但考虑到rwkv成功在前(我认为rwkv的成功就是引入了显式衰减),所以往linear attention引入显式衰减也是不难想到的思路。
作为linear attention来看,rwkv相当于num heads=hidden size的linear attention,而retnet允许更一般的组合,并且还引入了复相位(更一般的rope),所以最终能比rwkv好我是不意外的。retnet让我比较惊讶的地方是,显式衰减的加入可以如此简单,甚至无须训练,直接人为设定,感觉这里边rope(复相位变换)起到了关键作用。
但是,“显式衰减”其实也是RNN被诟病的地方,它相当于attention+alibi,是一种soft的local attention,意味着对于长序列,RNN必然不能有效地获得全局依赖(即截断了前面的信息),同时也意味着它会对prompt的形式比较敏感(需要先给定task token,再给context token效果才比较好),这些问题rwkv其实已经暴露得比较明显了。
个人愚见,retnet的table 6所做的消融实验更值得让人关注,table 6显示即便不引入 \gamma ,retnet的效果也优于rwkv(table 5),尽管从指标上看,去掉 \gamma 不如引入 \gamma ,但因为没有显式衰减,意味着它理论上对于任意长度都能建立全局依赖,这看起来比带有显式衰减的retnet更值得深挖。
能否取代transformer?如果去掉 \gamma 后效果效果能进一步上去,我认为是有机会的;如果还是免不了 \gamma ,我觉得我会更倾向于选择HFWA。