如何看待微软亚洲研究院的Swin Transformer?
40 个回答


大家好,Swin Transformer Official Code已经release啦:
Image Classification: microsoft/Swin-Transformer
Object Detection: Swin-Transformer-Object-Detection
Semantic Segmentation: Swin-Transformer-Semantic-Segmentation
其中包括ImageNet-22K的预训练模型(top-1 acc 87.3),欢迎star和试用~

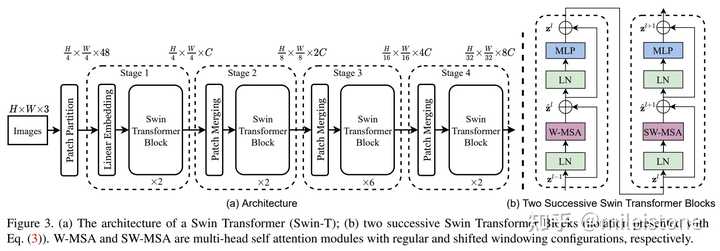
Swin Transformer最重要的两点是hierarchical feature representation和SW-MSA(Shifted Window based Multi-head Self-attention)。

Hierarchical Feature Representation
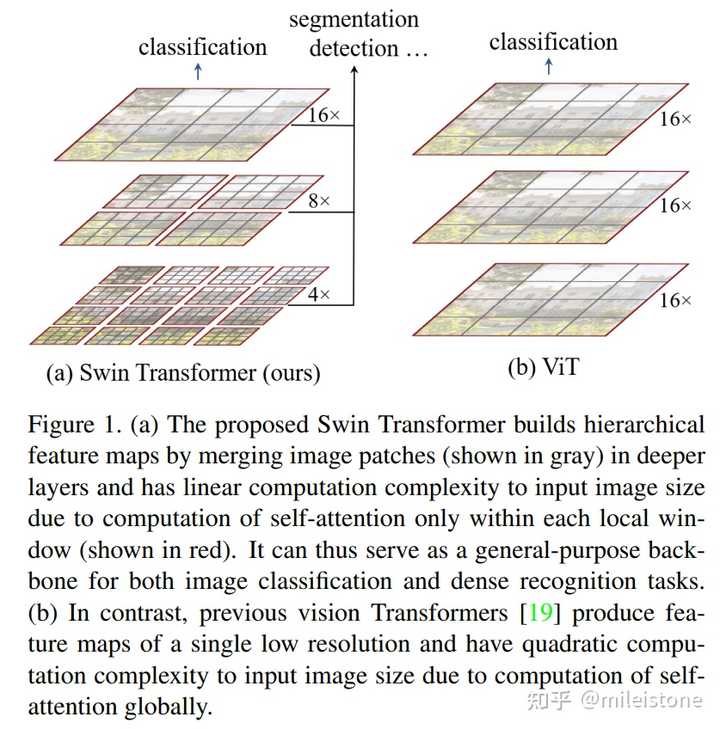
Hierarchical feature representation的思路取自CNN结构,整个模型分为不同stage,每个stage对上一个stage输出的feature map进行降采样(H、W变小);stage中每个block对局部进行建模而非全局。

降采样
Swin Transformer中通过Patch Partition和Patch Merging来实现降采样,实际上二者是一个东西,也就是kernel size与stride相同的conv。Patch Partition的kernel size和stride为4,Patch Merging的kernel和stride为2,跟CNN中的降采样方法相同。
局部dependency
W-MSA(window based Multi-head Self-Attention)建模的是局部window的dependency,而不是MSA(Multi-head Self-Attention)中的全局,这有助于降低模型的计算复杂度,这个思路跟conv是一样的。
W-MSA跟conv类似,也有kernel size和stride两个参数,在同一个stage里,conv的kernel size一般大于stride,比如经典的kernel size为3,stride为1。但是W-MSA在同一个stage里的kernel size和stride相同,这导致了一个问题——feature map上相邻的window之间永远不会交互,也就是一个stage中有1个W-MSA和N个W-MSA的感受野是没区别的。
CNN中因为kernel size比stride大,随着conv的堆叠,感受野会逐步增加;MSA因为kernel size完全覆盖feature map,所以每个MSA都具备全局感受野。
为了缓解这个问题,作者给W-WSA打了个补丁,得到了SW-MSA(Shifted Window based Multi-head Self-attention)
SW-MSA
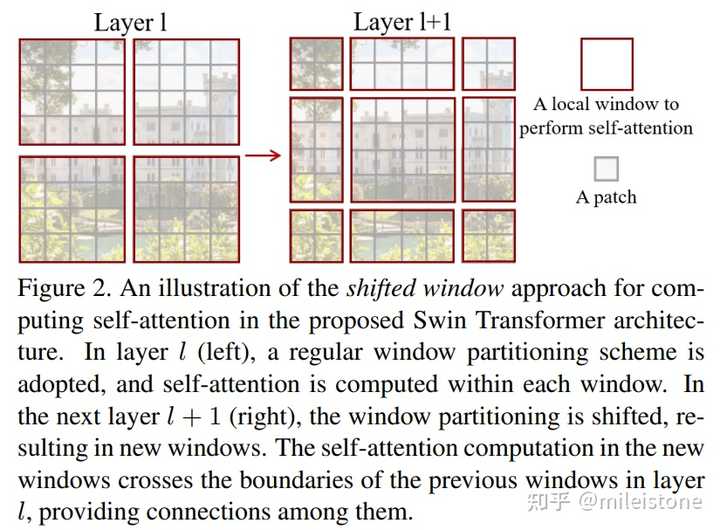

Swin Transformer中连续的block会依次交替使用W-MSA和SW-MSA。SW-MSA相比W-MSA唯一不同的地方在于将window进行shift,这种思路跟TSM异曲同工之妙。TSM想通过2D conv将时序信息encode进来,于是将各个frame的feature map在T维度进行shift;SW-MSA为了让相邻window之间产生交互,对window进行shift。


一些感想
关于Swin Transformer
Swin Transformer使用CNN结构设计中的一些理念(降采样、局部dependency、TSM)来重新设计Transformer,和我之前在如何看待Transformer在CV上的应用前景,未来有可能替代CNN吗?的回答不谋而合。
SW-MSA这种解决方法我感觉不够优雅,应该有其他替代方案,比如W-MSA中的kernel size大于stride,这样就类似于CNN,随着block的增加感受野可以逐渐变大。
天下文章一大抄
这里的抄不是抄袭的意思,而是说研究中的新思路大部分以前已经有了,面对一个问题,重新组合历史上已有的思路或者使用新的技术来实现历史上的思路,可能就会得到一个不错的结果。
一个领域的技术会不断发展,以计算机视觉为例,从局部特征子、CNN到Transformer,但是背后核心的思路是相对固定的。我们可以在CNN中看到局部特征子时代的印记,同样我们也会在Transformer应用在计算机视觉领域时,看到CNN的影子。
现在技术发展日新月异,只有抓住一个领域背后演进相对缓慢的思路,我们才可以以不变应万变,不然我们永远在追赶新技术,累得气喘吁吁。