如何计算两份代码的相似度?
20 个回答


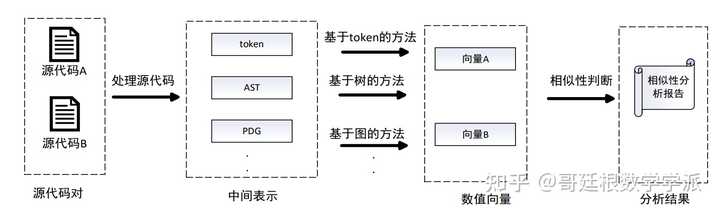
输入是一对待比较的源代码,输出为这对源代码的相似度。无论代码是否以同种编程语言完成,检测时通常不会直接对源代码进行比较,而是首先对输入的一对源代码进行处理,将其转换为某一种中间表示,该中间表示可以抽象出代码的某种特征,如语法特征或语义特征等。之后根据不同中间表示的特点采用不同的方法进行处理,将其转化为可以进行相似性比较的形式,最后度量两段代码间的相似度。
源代码相似性的检测过程通常分为3步:
1)处理源代码。
由于源代码中包含了许多与相似性比较无关的信息,为了减少这些噪声信息的干扰,提取出代码的某些特征,通常的方法是将源代码转化成中间表示形式,如代码单元token、抽象语法树AST或程序依赖图PDG等;
2)处理特征表示。
经过处理后的代码虽然可以反应代码某些维度的特征,但仍无法通过中间表示形式直接计算其相似度,因此需根据不同的代码表示采用对应的方法将其转化为数值特征向量。
3)相似性判断。使用余弦相似度等相似性度量算法通过向量相似度计算代码间相似度,给出相似性分析报告。



有源码的情况下计算起来比较容易,这点已经有很多人提到了,比如Textual comparison,AST语法树等。
没有源码的情况下,可以选择反编译来找出程序的源代码,但反编译主要还是用来分析代码的原理、结构、逻辑、敏感数据等核心要素,对于二进制代码的相似度计算来说可能多了个步骤,会带来很多未知的内容。


关于二进制代码相似度检测,其实现在可以借助机器学习来计算,最近正好看了usenix 2022一篇文章:How Machine Learning Is Solving the Binary Function Similarity Problem,对已有的研究成果进行筛选,系统性地分析了不同方法来准确计算两段二进制代码之间相似性的能力。
基于文章的分析,共确定了30种在下图中表示的技术,然后选择了十种代表性解决方案。
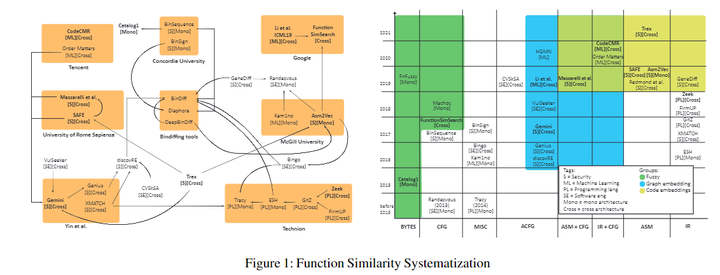

文章“3.1Selection Criteria”讲了选择方法的标准:
- Scalability and real-world applicability
- Focus on representative approaches and not on specific papers
- Cover different communities
- Prioritize latest trends(方法的代表性和前沿性)
并且在“3.2 Selected Approaches”给出了选择计算相似度的方法:
- 基于Bytes fuzzy hashing的
Catalog1:https://www.xorpd.net/pages/fcatalog.html - 基于CFG fuzzy hashing的
FunctionSimSearch:https://googleprojectzero.blogspot.com/2018/12/searching-statically-linked-vulnerable.html - 基于Attributed CFG and GNN的
Gemini:Neural network-based graph embedding for cross-platform binary code similarity detection,CCS 2017 - 基于Attributed CFG, GNN, and GMN:Graph matching networks for learning the similarity of graph structured objects,PMLR 2019
- 基于IR, data flow analysis and neural network的
Zeek:Binary Similarity Detection
Using Machine Learning,PLAS 2018 - 基于Assembly code embedding的
Asm2Vec:Asm2Vec: Boosting Static Representation Robustness for Binary Clone Search against Code Obfuscation and Compiler Optimization,IEEE S&P 2019 - 基于Assembly code embedding and self-attentive encoder的
SAFE:Safe: Self-attentive function embeddings for binary similarity,DIMVA 2019 - 基于Assembly code embedding, CFG and GNN的论文: Investigating Graph Embedding Neural Networks with Unsupervised Features Extraction for Binary Analysis,BAR(workshop of NDSS)2019
- 来自TX的
CodeCMR/BinaryAI:BinaryAI Python SDK. https://github.com/binaryai/sdk 以及论文 Codecmr: Cross-modal retrieval for function-level binary source code matching,NeuIPS 2020 Trex:Trex: Learning execution semantics from micro-traces for binary similarity. arXiv 2020
数据集可以在这里看到:


部分的实验结果如下:
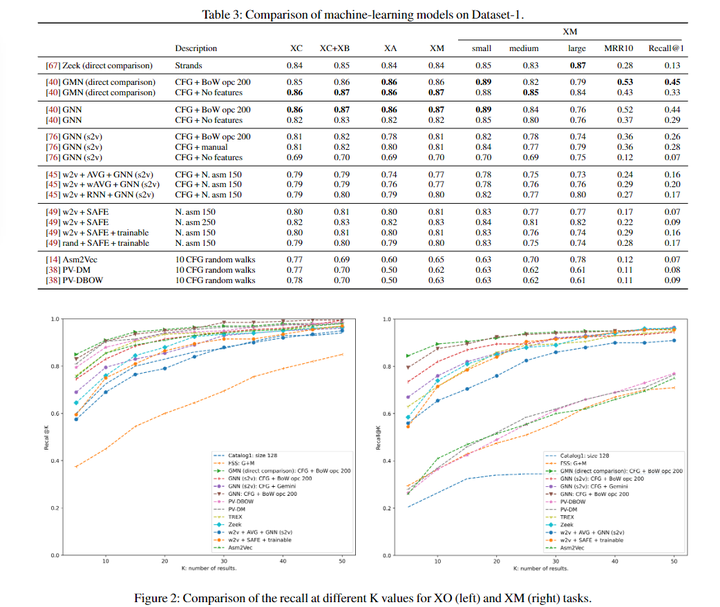



各种情况下,Graph Matching Networks (GMN)的相似度检测结果都是表现很好的,所以无源码的情况下,可以通过 GMN 方法来计算两份代码的相似度。

