When you’re learning SQL or database design, it’s helpful to use other databases as a reference.
Many articles online refer to Oracle’s HR database, or SQL Server’s AdventureWorks database. These can be helpful, but often you’re looking for answers that these databases don’t help with.
Which is where this post comes in.
This post describes a sample database containing data about movies. It includes:
- An ERD (entity relationship diagram) for the sample movie database
- An explanation of the tables and columns
- A download of sample data to create and populate this database
- An example query on the database
Why is this helpful? Firstly, you can understand more about how a movie database might work.
Also, you can practice SQL against realistic data and write your own queries, both simple (how many movies has Tom Cruise been in?) and complex (which movies have Tom Cruise and Matt Damon both been in?).
So, let’s take a look at the database.
Sample Movie Database: ERD
The ERD or database design of the sample movie database is here (open in new tab, or save, to see a larger version):
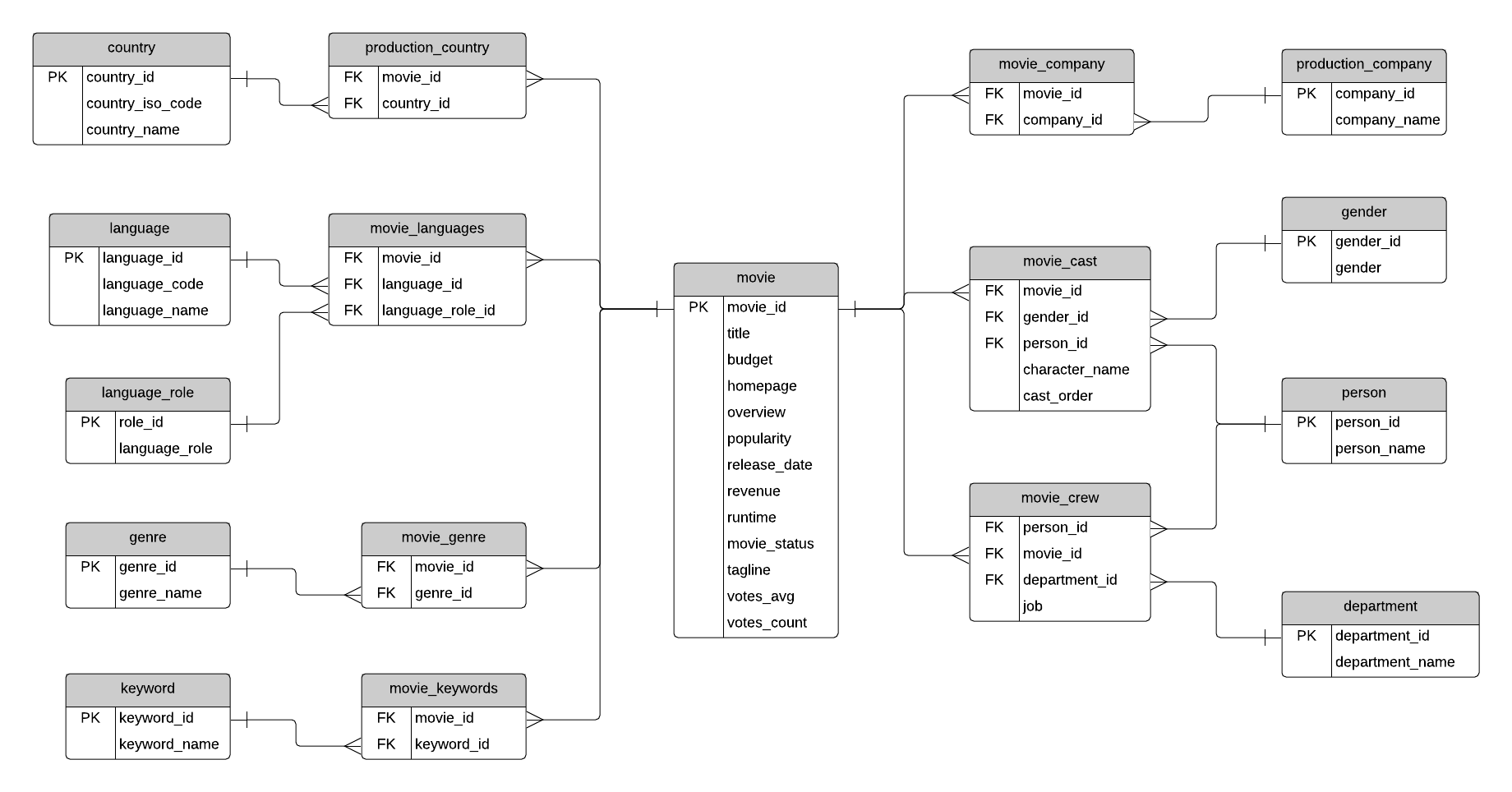
This database stores information about movies, the cast and crew involved, where the movie was produced and by which company, and other information about movies such as the languages, genres, and keywords.
The sample data was obtained from a free online data source. It contains about 4,800 movies, 104,000 cast and crew, and thousands of metadata records such as languages and keywords.
What do all of these tables and columns mean?
While you’re here, if you want an easy-to-use list of the main features in SQL for different vendors, get my SQL Cheat Sheets here:
Table Explanations
The movie table contains information about each movie. There are text descriptions such as title and overview. Some fields are more obvious than others: revenue (the amount of money the movie made), budget (the amount spent on creating the movie). Other fields are calculated based on data used to create the data source: popularity, votes_avg, and votes_count. The status indicates if the movie is Released, Rumoured, or in Post-Production.
The country list contains a list of different countries, and the movie_country table contains a record of which countries a movie was filmed in (because some movies are filmed in multiple countries). This is a standard many-to-many table, and you’ll find these in a lot of databases.
The same concept applies to the production_company table. There is a list of production companies and a many-to-many relationship with movies which is captured in the movie_company table.
The languages table has a list of languages, and the movie_languages captures a list of languages in a movie. The difference with this structure is the addition of a language_role table. This language_role table contains two records: Original and Spoken. A movie can have an original language (e.g. English), but many Spoken languages. This is captured in the movie_languages table along with a role.
Genres define which category a movie fits into, such as Comedy or Horror. A movie can have multiple genres, which is why the movie_genres table exists.
The same concept applies to keywords, but there are a lot more keywords than genres. I’m not sure what qualifies as a keyword, but you can explore the data and take a look. Some examples as “paris”, “gunslinger”, or “saving the world”.
The cast and crew section of the database is a little more complicated. Actors, actresses, and crew members are all people, playing different roles in a movie. Rather than have separate lists of names for crew and cast, this database contains a table called person, which has each person’s name.
The movie_cast table contains records of each person in a movie as a cast member. It has their character name, along with the cast_order, which I believe indicates that lower numbers appear higher on the cast list.
The movie_cast table also links to the gender table, to indicate the gender of each character. The gender is linked to the movie_cast table rather than the person table to cater for characters which may be a different gender than the person, or characters of unknown gender. This means that there is no gender table linked to the person table, but that’s because of the sample data.
The movie_crew table follows a similar concept and stores all crew members for all movies. Each crew member has a job, which is part of a department (e.g. Camera).
Sample Data
I’ve prepared some sample data for this database. You can use this to create this database on your own computer, explore the tables, and write SQL on it.
The sample data is available for Oracle, SQL Server, MySQL, and Postgres, and is stored on my GitHub repository. Find out how to access it and load the data here: Sample Data for SQL Databases
Sample Query
With the sample data in the database, let’s take a look at some of the data in the movie table. This query shows the movie title, budget, and other attributes of the movie, sorted by the movies with the highest revenue.
SELECT
title,
budget,
release_date,
revenue,
runtime,
vote_average
FROM movie
ORDER BY revenue DESC;
Results (top 20 rows only):
| title | budget | release_date | revenue | runtime | vote_average |
| Avatar | 237000000 | 2009-12-10 | 2787965087 | 162 | 7.2 |
| Titanic | 200000000 | 1997-11-18 | 1845034188 | 194 | 7.5 |
| The Avengers | 220000000 | 2012-04-25 | 1519557910 | 143 | 7.4 |
| Jurassic World | 150000000 | 2015-06-09 | 1513528810 | 124 | 6.5 |
| Furious 7 | 190000000 | 2015-04-01 | 1506249360 | 137 | 7.3 |
| Avengers: Age of Ultron | 280000000 | 2015-04-22 | 1405403694 | 141 | 7.3 |
| Frozen | 150000000 | 2013-11-27 | 1274219009 | 102 | 7.3 |
| Iron Man 3 | 200000000 | 2013-04-18 | 1215439994 | 130 | 6.8 |
| Minions | 74000000 | 2015-06-17 | 1156730962 | 91 | 6.4 |
| Captain America: Civil War | 250000000 | 2016-04-27 | 1153304495 | 147 | 7.1 |
| Transformers: Dark of the Moon | 195000000 | 2011-06-28 | 1123746996 | 154 | 6.1 |
| The Lord of the Rings: The Return of the King | 94000000 | 2003-12-01 | 1118888979 | 201 | 8.1 |
| Skyfall | 200000000 | 2012-10-25 | 1108561013 | 143 | 6.9 |
| Transformers: Age of Extinction | 210000000 | 2014-06-25 | 1091405097 | 165 | 5.8 |
| The Dark Knight Rises | 250000000 | 2012-07-16 | 1084939099 | 165 | 7.6 |
| Toy Story 3 | 200000000 | 2010-06-16 | 1066969703 | 103 | 7.6 |
| Pirates of the Caribbean: Dead Man’s Chest | 200000000 | 2006-06-20 | 1065659812 | 151 | 7 |
| Pirates of the Caribbean: On Stranger Tides | 380000000 | 2011-05-14 | 1045713802 | 136 | 6.4 |
| Alice in Wonderland | 200000000 | 2010-03-03 | 1025491110 | 108 | 6.4 |
| The Hobbit: An Unexpected Journey | 250000000 | 2012-11-26 | 1021103568 | 169 | 7 |
Conclusion
So that’s the sample database for movie information. There’s an ERD you can use to help you understand it or to design your own. You can also download the sample database tables and data to run your own queries on it.
While you’re here, if you want an easy-to-use list of the main features in SQL for different vendors, get my SQL Cheat Sheets here:
deficient file CSV from Dataset Movies
is it possible to get the dataset in postgres formart
Thanks!
where can I find ER diagram for this example?
The ER diagram is near the beginning of this post.
Hello Ben,
Thanks for the DB. I used it in my PostgresSQL DB class last year. In case it interests you, the last column of the table “language” has a very strange charset (as far as I am concerned it was perfect, since I always like when students experience an unexpected challenge). Thanks again.
Neither the SQL File or it’s Oracle variant seem to work. Total waste of time
Hi Sebastian, what errors or issues are you having with these files? I’d like to help get them working for you.
Your oracle .sql scripts are not working because you’re escaping apostrophes with \’ .
This is the proper way to escape them:
https://stackoverflow.com/questions/5139770/escape-character-in-sql-server
This python script would do the trick:
import os
directory = ‘test’
def function(f):
with open(f, ‘r’) as file:
data = file.read()
data = data.replace(“\\'”,””” )
data = data.replace(“\\\””, “\”\””)
with open(f, ‘w’) as file:
file.write(data)
for filename in os.listdir(directory):
f = os.path.join(directory, filename)
if os.path.isfile(f):
function(f)
where instead of ‘test’ for the directory, you put ‘oracle’ or whatever directory you want to apply it on
Write SQL query to show all the data in the Movie table and the ERD is same
WOW helped alot in practicing my SQL Thanks a bunch MAN
Can you also add practice questions with movies database.?