SDImageGenerator
A downloadable tool for Windows
SDImageGeneator is a text-to-image generation AI desktop app for Windows/Linux. It is still actively under development. The Linux version of the app is coming soon.
We are releasing SDImageGenerator v2.0.0 for Windows. Thanks for the support and feedback.
New stable diffusion app DiffusionMagic for Windows/Linux/MacOS
https://rupeshsreeraman.itch.io/diffusionmagic
https://github.com/rupeshs/diffusionmagic
Minimal version of SDImageGenerator for Android with 50+ styles Install from PlayStore
Two download variants are available:
- Download with stable diffusion model 1.5 by runwyml and VAE model (5.6 GB)
- Download without models (For advanced users)(1.9GB). Follow the instructions in the readme.txt.
Version 2.0.0, What's New?
- Works on CPU/GPU but CPU image generation is slow(Recommended to use GPU for faster image generation)
- The stable diffusion 1.5 model is used as default
- Added model switching (For advanced use)
- Supports dreambooth models (checkpoint files (.ckpt) supported)
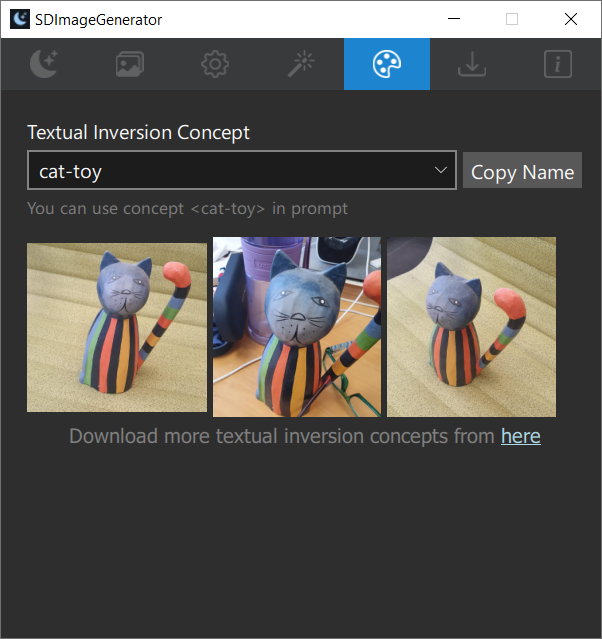
- Added textual inversion support(Hugging Face's concepts library models supported)
- Added VAE(Variational autoencoder) support for fine details
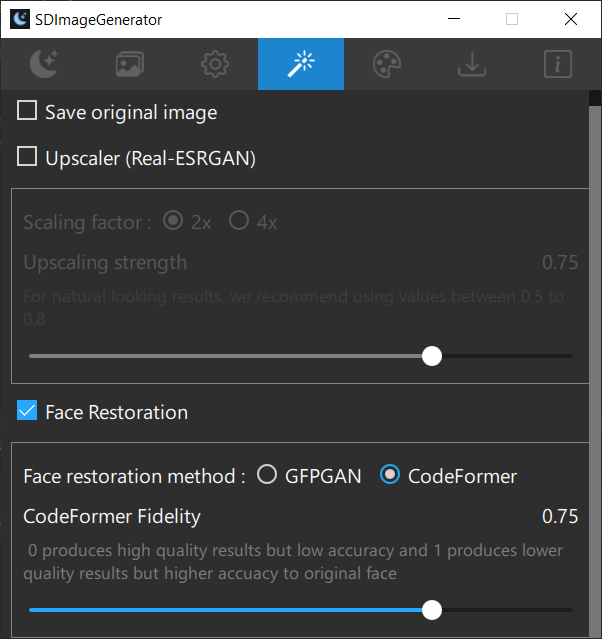
- Added CodeFormer support
- Updated full precision mode with float32
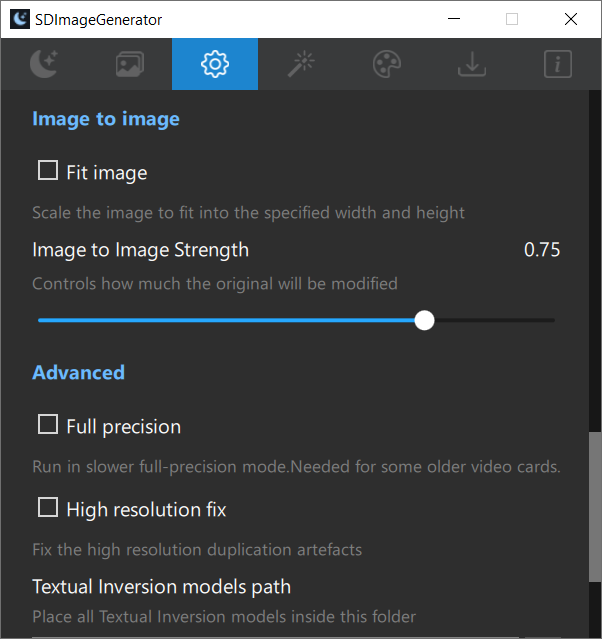
- Added high-resolution duplication fix setting
- Image-to-image now supports k-diffusion samplers
- Added Image-to-image mask image support
- Added cancel functionality
- Negative prompt support, use [ ] to use negative prompt
E.g: a cute [white] dog
- Added Attention control support in prompt :
Use "+" to increase attention - a house, apple++ tree
Use "-" to decrease attention - a house, apple- tree
- Supports prompt-to-Prompt editing (Cross attention control)
E.g: In the below prompt cat will be replaced with a dog
A cat.swap(dog) riding bicycle
- Supports prompt blending
E.g: car:0.30 boat:0.70 hybrid
How to use custom models with SDImageGenerator?
https://nolowiz.com/how-to-use-custom-stable-diffusion-models-with-sdimagegenera...
System Requirements:
- Windows 10/11 64-bit
- Works on CPU/GPU
- Recent Nvidia GPU, preferably RTX ( 4 GB or more VRAM memory)
- 12 GB System RAM (16+ recommended)
- ~11 GB disk space after installation (on SSD for best performance)
Features:
- Simple interface
- Portable package, just extract and run the app
- Image viewer for generated images
- Application logs
- Configurable image generation settings
- Extract and run, no complex installation steps
- The default sampler is now k_lms
- Added seamless mode support
- Grid mode support
- Full precision support
- Upscaler(Real-ESRGAN) support
- Face restoration(GFP-GAN) support
- Image-to-image generation
- Image variations support
- Weighted prompts support
- Works with NVIDIA GPU (minimum VRAM 4GB)
GitHub : https://github.com/rupeshs/SDImageGenerator
Download
Click download now to get access to the following files:
Development log
- SDImageGenerator 2.0 releasedNov 27, 2022


Comments
Log in with itch.io to leave a comment.
If so, how do I proceed?
You can try other diffusion models or tweak the input prompt.
Here is a guide to use custom models with SDIG https://nolowiz.com/how-to-use-custom-stable-diffusion-models-with-sdimagegenera...
One option announced, is not configurable in the interface, it is the use of the CPU or the GPU. I think that a checkbox CPU or GPU would be useful for 4 vram cards, by switching to CPU we might not be limited by the vram of our small card, and could generate large illustrations, at the expense of speed.
Can I run this with my amd?
AMD is not yet supported for the Windows version.
Hi
Great, I was looking forward to this v2, thanks for your work, so nice!
About: -Support for dreambooth templates (checkpoint (.ckpt) files supported)
I tried version 2, and looked to use a .ckpt template generated with Dreamboth.
The template was placed in the stable-diffusion-v1 folder :(E:\SDImageGenerator-2.0.0-portable-x64\sdenv\stablediffusion\models}.
But alas, in the options window, at : "Models Switch", my model named stnyb, does not appear in the menu : "select a model and switch".
And inpainting 1.5 or SD1.4 is not present.
How to integrate my stnyb.ckpt model in the application? Where to download inpainting 1.5?
Thanks again for your work, I'm looking forward to test everything, like the use of the CPU, it may allow to go beyond the limits of cards with little VRam, and thus generated illustrations of larger size.
I found a solution (How to integrate my stnyb.ckpt ?).
You have to edit the models.yaml file (SDImageGenerator-2.0.0-portable-x64\sdenv\stablediffusion\configs\models.yaml)
and added your model.
The easiest solution is to copy and paste from :
--------------------
your_model:
description: of your model
config: configs/stable-diffusion/v1-inference.yaml
weights: models/ldm/stable-diffusion-v1/your_model.ckpt
vae: models/ldm/stable-diffusion-v1/vae-ft-mse-840000-ema-pruned.ckpt
width: 512
height: 512
---------------------
replace 'your_model' with the name of your ckpt file.
Don't forget to copy your custom template into :
SDImageGenerator-2.0.0-portable-x64\sdenv\stablediffusion\models\ldm\stable-diffusion-v1
Now,
1- Open: 'SDImageGenerator.exe"
2- Click on the "Dream" button and wait (the load)
3- Go to "Models Switch" in the settings tab
4- In the drop down menu Models Switch, choose your model (it appears thanks to the little manipulation above)
5- Click on : 'Switch model'
6- Wait for the confirmation window to appear
That's it! You can use your custom model
Thanks, you can read more about it https://nolowiz.com/how-to-use-custom-stable-diffusion-models-with-sdimagegenera...
In another known SD interface, the simple fact of dropping a personal model in a folder intended for the personal ckpt, makes the model automatically available in the interface.
So I looked for why this was not working in SDgenerator, and I found the solution by opening each file that could have modifiable parameters, related to the Switch Model menu interface. I thought I would have to modify other files, but no!
I have it installed, but I'm running into a problem. When I try to download the models, the "stable diffusion 1.4 original" seems to download instantly. But when I restart, I can only go to the download and info tabs. I cannot put a check in the 1.4 model. If i click download again it says it's already downloaded. If I attempt to download it again anyway, the same thing happens.
have the same problem....
06/11/2022 19:44:10 Stable diffusion original model(v1.4) check: Failed
this is what I see in the log file
I got a different ckpt model file and dropped it in the folder. This got me to the point that I can enter a prompt but it always generates a completely green image
Could you please download the model from https://huggingface.co/CompVis/stable-diffusion-v-1-4-original
I've tried it with both the
files. But I get the same result. If I just drop them in the model folder, it keeps asking me to download the model file again. If I rename it to "model.ckpt" it runs but only produces the same green screen
Please download the latest version SDImageGenerator v 1.0.6
It has the SD model file so no need to download it
Please download latest version SDImageGenerator v 1.0.6
It will fix those broken downloads
I cannot get it to work. After downloading a model I cannot select it, it says initializing every time I open it, and even if I restart or redownload the model that is all I can do. Does this need additional python libraries or something?
and the second model always fails to download for some reason
okay after disabling my antivirus, the second model is now ticked, but the first just downloads but I cannot enable it
I tried reinstalling (2 times), running as administrator every time, and the first model still cannot be ticked :(
06/11/2022 19:44:10 Stable diffusion original model(v1.4) check: Failed
this is what I see in the logs, so there has to be something with the first model not downloading properly...
Please download the latest version SDImageGenerator v 1.0.6
No special libraries are needed, initially, it will take some time to verify environment.
after manually adding the model from huggingface it does seem to work now! thanks for the help!
Is there a way to add more pretrained models for the image generator?
Yes, it is possible in the upcoming release 2.0, as of now it will support stable diffusion 1.4 model
is there a way currently to use different custom cpkt model files? renaming to "model.ckpt" and changing the original model didnt work as the app was able to tell that it wasnt the normal sd.v1.4 model.
Oh, bummer. The beta version let me rename them to swap models. I haven't tried 1.05 yet, been mainly using AUTOMATIC1111.
SDImageGenerator version 2.0 will support custom models, textual inversion etc, coming soon...
This works really well! I'm able to run this on a 4GB VRAM 3060ti mobile if I decrease the width and height to 448x448. If you're reading this and haven't checked it out, give it a try. This is the best and easiest low VRAM solution for text-to-image I've found that doesn't rely on cloud computing.
A few requests for improvements:
-Default to sampler k_lms instead of plms.
-Ability to batch more than 20 images at a time. (100?)
-Ability to switch between models (without manually having to move/rename the model file.)
-Ability to redownload the Environment files incase things get corrupted.
-Typing a Seed of 7 character length seems to throw an error during the "weights" evaluation step of image generation.
-A "stop" button to stop rendering after the next image is complete. (Currently the only way to cancel a job is to close/reopen the program.)
-Eventual inclusion for stuff like textual inversion, img2img, GFPGAN, inpainting, outpainting, etc.
Hope that feedback was valuable. Again, great job.
Thanks for the feedback, I will consider suggestions.
First I thought I didn't wait long enough for the environment model to install, so I deleted it and re-extracted and tried again, but it still didn't complete. I deleted and re-extracted again and I waited for it to say "installation completed successfully, please restart app" literally all day, and it never did. So I restarted and it says "Installation already exists!" but the logs say "Environment is not ready,please install it from the install tab". Should I delete again and try again? Is it pointless? Is there a way to try the installation again without having to delete it all and re-extract it all? I've been trying to do this for three days.
getting this error
Extract and install again and wait for the "installation completed successfully" message.
I'll try again later and let you know.
I'm oly getting this options.
GFPGAN model (Optional)
Code Former model (Optional)
Not the Enviroment one
And still the --No module named 'ldm'-- error
There's any way of doing it manually?
Thanks for using SDImageGenerator. Seems like it's an issue with your installation. Could you please try this?
Download the latest version of SDImageGenerator v 2.0
1. Extra the SDIG 7z file to a nonsystem drive (other than a C drive)
2.Start SDImageGenerator and wait for the dialogue to close automatically. It will automatically set everything.
3. Now check again, it will work.