一般来说,三层神经网络可以逼近任何一个非线性函数,为什么还需要深度神经网络?
47 个回答


因为从approximation error(拟合误差)的角度,无论是实验结果来看,还是从理论分析来看,大部分情况下“深”都比“宽”更有效。
理论层面的话,分享一篇我比较喜欢的paper里的结果(Why Deep Neural Networks for Function Approximation?,ICLR 2017),作者是UIUC的Shiyu Liang和R. Srikant。
简单来说,这篇文章证明了,如果想要达到 \epsilon 的拟合误差(approximation error),深度为常数(与\epsilon 无关)的神经网络需要 \Omega(\text{poly}(1/\epsilon)) 个神经元,也就是说,shallow neural network的神经元数量随着精度( 1/\epsilon )的上升多项式增长。然而,深度为 O(\log(1/\epsilon))的神经网络只需要 O(\text{polylog}(1/\epsilon)) 个神经元,也就是说,deep neural network的神经元数量随着精度的上升对数增长。换言之,想要达到同样的拟合误差,更深的神经网络需要的神经元数量远小于层数少的神经网络。

因为效率更高,理论上来说,只要把隐层宽度加上去,什么都能拟合。极限的情况下,无非就是隐层直接把数据都记下来。但这个效率不高。
Topology of deep neural networks
这篇文章谈到,使用Relu的神经网络每一层相当于都是在对高维流形进行折叠来把数据点分开。文章使用贝蒂数来测量每一层折叠之后的流形和最终目标流形之间的距离,发现对于浅层网络而言,最后一层完成了大部分的任务,而深层网络每一层折叠的程度,或者说向着目标进发的程度相当。也就是说深层网络每一层都只做了一点点事情,而浅层网络最后一层要做很多事情。
那很好理解,深层网络效率高一些,直观的理解就是深层次网络是一点一点的抽象,浅层网络是一步到位。要一步到位,根据经验数据,训练的时间会长很多。
但并不是越深越好,比如这篇文章:
Increasing Depth Leads to U-Shaped Test Risk in Over-parameterized Convolutional Networks
告诉我们,一开始是深度越深越好了,一旦过了某一个临界点,就会变差。
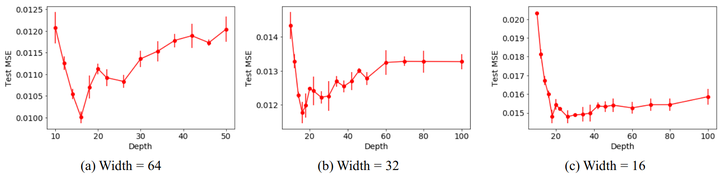

从左到右是不同宽度的ResNet,改变深度之后test error的变化。很明显,无论什么宽度,深度都是到18层左右触底,所以ResNet18非常好。之后再加深就变差。
这当然也和任务的复杂程度,数据集大小都有关系,但意思反正是这个意思,假定数据集不变,深度不是越深越好的,存在一个最优深度。
不负责任暴论:解决多复杂的问题,就需要多复杂的脑回路,问题如果不难,脑回路太多,反而被绕晕了。如果问题很复杂,脑回路太简单也想不清楚。