
【无中生有的AI】关于deepfake的入门级梳理

本文发于公众号【机器学习与生成对抗网络】,欢迎文末扫码关注、并诚邀您加入GAN交流群一起讨论)


上述素材源于网络,侵删
前言
- Deepfake这个词是“深度学习”和“假冒”两个词的组合。
- 一般来说,Deepfake指的是由人工智能生成的、现实生活中不存在的人或物体,它们看上去是逼真的。
- Deepfake的最常见形式是人类图像的生成和操控。例如,对外国电影进行逼真的视频配音,在购物时虚拟地穿上衣服,对演员进行换脸等等。
- 尽管Deepfake兴起时,也因其不道德和恶意方面的应用而臭名昭著。 2017年底,名为“deepfakes”的Reddit用户将名人的面孔用于色情视频转换生成,并将其发布到网络上。这迅速传遍各媒体和网络,此后大量新的Deepfake视频开始出现。2018年,BuzzFeed发布了奥巴马(Barak Obama)的deepfake演讲,它也是使用Reddit用户的软件(FakeApp)制作,这引起了人们对身份盗用,假冒以及错误信息在社交媒体上传播的担忧。
- 在这些事件之后,这一相关的deepfake制作和检测研究在学术界引起了人们的关注:自2017年以来,相关论文数从3篇增加到150篇以上(2018-19年)。
- 本文参考整理于论文 The Creation and Detection of Deepfakes: A Survey(https://arxiv.org/abs/2004.11138),有增删。


上述素材源于网络,侵删
1、分类
- 一般地,deepfake可划分为如下四类:重现(reenactment),替换(replace),编辑(editing)和合成(synthesis)。
- 人脸编辑和合成是十分火热的研究课题,但重现和替换是最大的问题:它们可以让攻击者进行控制身份和欺骗。下图展示了一些示例。其中,s和t表示为源身份和目标身份,将x_s和x_t表示为对应身份的图像,

- 重现和替换的对比


- 编辑


- 合成


1.1 重现(reenactment)
- 重现使用源身份x_s驱动目标身份x_t,使得x_t做的行为和x_s一样。
- 从已有研究来看,主要从以下方面展开:表情、嘴部、眼部、头部或身体躯干。
- 表情重现,让目标身份的表情模仿源身份的表情(极端一点,泰罗奥特曼像你一样咧嘴大笑)。这在电影和视频游戏行业中具有极大的应用价值,如对演员的表情表演进行后期调整(安吉拉福音?)、在教育行业中对历史人物牛顿进行表情再现以讲解牛顿定理等。
- 嘴部重现,或者说“配音”,目标身份x_t的嘴部由x_s驱动,或者是包含语音的音频输入。该技术的应用比如将逼真的语音配音成另一种语言并进行编辑。
- 眼部重现是x_s的视线驱动x_t眼睛的方向和眼睑的位置。这用于改善照片质量或在视频采访中自动保持眼神交流,哈哈。
- 头部重现,x_t的头部位置由x_s驱动。这项技术主要用于在安全录像中对人脸进行朝向转正,并用作改善人脸识别软件的手段。
- 身体重现(也称为姿态迁移和人的姿势合成)与上面列出的面部重现类似,不同之处在于身体躯干的重现。
- 重现作为一种deepfake技术之一,攻击者能够用其假冒身份,控制一些说或做的事情,如诽谤、散布错误信息、篡改证据。比如,攻击者冒充他人,骗取朋友或家人信任,以此谋利;攻击者还可能出于勒索目的而生成令人尴尬的虚假材料,影响公众人物等。
1.2 替换(replace)
- 替换指的是使用源身份x_s的 内容替换目标身份x_t ,使得目标身份变成了源身份s。
- 迁移(transfer) 常见的转移类型是面部转移,在时尚行业中用于不同服装中的个人虚拟试穿。
- 交换(swap) 中最流行的是“换脸”,比如将普通人的身份与著名人物的身份交换来产生讽刺或不良的内容效果。换脸的另一种健康用途是在公共平台、场合中匿名化身份,以代替模糊或像素化。
- 替换这种deepfake技术因其有害应用而闻名。例如,攻击者将受害者的脸庞换成色情女演员的身体,以侮辱、诽谤和勒索受害者。又比如,这种方法已被用作传播政治观点的工具(Oscar Schwartz. You thought fake news was bad? – the guardian. https://www.theguardian.com/technology/2018/nov/12/ deep-fakes-fake-news-truth, 5 2018. (Accessed on 03/02/2020))。

上述素材源于网络,侵删
1.3 编辑(editing)
- 通过添加、更改或删除目标身份的属性。例如,更换目标对象的衣服、胡子、年龄、体重、颜值和甚至种族、肤色。诸如FaceApp之类的应用程序使用户可以更改其外观,以娱乐之用。
- 攻击者可以使用相同的过程来建立虚假的角色而误导他人。例如,可以使一个患病的领导者看起来健康的,震慑“敌方”(刘邦?诸葛亮?)。
- 还有一种不道德的用途是:去除受害者的着装使其裸露,即所谓的一键脱衣。
1.4 合成(synthesis)
- 合成是在没有目标身份作为基础的情况下,所创建的Deepfake角色。
- 人脸和身体合成技术可以创建素材,生成电影和游戏角色。
- 但是,但负面之用同样是:在线创建假角色以进行其它诈骗、违法行为。
2、基础实现技术
deepfake技术通常由几种神经网络结合而来
2.1 编码-解码网络(ED)
- encoder-decoder networks(ED)由编码网络encoder和解码网络decoder组成。
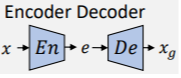
- 连接编码和解码的中间层较窄,因此当训练:De(En(x))= x_{g}时,网络将被迫学习、汇总训练样本的高层语义概念。
- 给定x的分布X,En(x)= e,通常称e为编码或嵌入(embedding),而E = En(X)被称为“潜在空间(latent space)”。
- Deepfake技术通常使用多个编码器或解码器,并操纵编码来影响输出x_g。如果编码器和解码器是对称的,并且以目标De(En(x))= x训练网络,则该网络称为自动编码器,输出是x的重建。
- ED的另一种特殊类型是变分自动编码器(VAE),其中编码器学习给定X的解码器后验分布。VAE比自动编码器在生成内容方面更好,因为潜在空间中的表征可以被更好地解耦。
2.2 卷积神经网络(CNN)
- 与全连接网络相反,CNN擅长学习数据中(局部)结构模式并组合得到高层次表征,因此在处理图像方面效率更高。
- CNN中的卷积层学习的是卷积核/滤波器参数,这些滤波器在输入图像上移动,提取抽象的特征图作为输出。
- 随着网络变得越来越深,池化层降低维数,上采样层提高维数;它们可以灵活地构建用于图像的ED CNN。
2.3 生成对抗网络(GAN)
- GAN是由Goodfellow等人于2014年首次提出的。
- GAN由互相作用的两个神经网络组成:生成器G和鉴别器D。
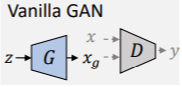
- G旨在欺骗D来创建伪样本x_g,D学会区分真实样本(x∈X)和伪样本( x_g = G(z)其中z〜N)。
- 具体来说,有一个分别用于训练D和G的对抗损失:
\min _{G} \max _{D} \mathbb{E}_{\mathbf{x} \sim p_{\text {data }}}[\log D(\mathbf{x})]+\mathbb{E}_{\mathbf{z} \sim p_{\mathbf{z}}}[\log (1-D(G(\mathbf{z})))] \\
- 在对抗博弈下,G学习如何生成与原始分布无法区分的样本。
- 训练后,将D丢弃,并使用G生成内容。当应用于图像时,此方法的优点是通常可以生成更高质量、逼真的图像样本。
2.4 图像转换网络(Pix2Pix、CycleGAN)
- pix2pix可以完成从一个图像域到另一个图像域的转换。
- 在pix2pix中,G以输入图像x_c作为输入,在给定目标标签x_t,希望G学习x_c->x_t的映射。即希望G所生成的图像x_g和x_t无限接近,而D区分(x_t,x_c)和(x_g,x_c)。
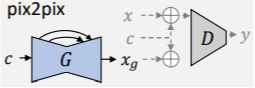
- pix2pix是一种监督式、成对式的训练方式,对数据有严苛要求。
- 提升版本的pix2pixHD可以用来生成具有更好保真度的高分辨率图像。
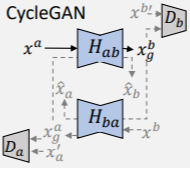
- CycleGAN可以通过不成对的训练样本来进行图像转换。该网络由两组GAN构成,并形成一个循环约束:将图像从一个域转换为另一个域,然后再次返回时,确保一致性。
2.5 递归神经网络(RNN)
- RNN是可以处理序列和可变长度数据的神经网络。
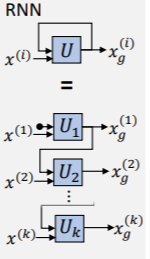
- 在Deepfake制作中,RNN通常用于处理音频、视频。
- RNN的更高级版本包括长期短期记忆(LSTM)和门递归单元(GRU)。
3、特征表示
大多数神经网络结构使用一些中间表示来捕获、控制源身份s和目标身份t的面部结构、姿势和表情等。
- 有的使用面部动作编码系统( facial action coding system,FACS)并测量面部的每个分类动作单元(AU)。
- 有的使用单目重建,从2D图像获得头部的3D可变形模型(3DMM),其中,姿势和表情使用矢量和矩阵参数化。使用3D渲染等。
- 有的使用头部或身体的UV图来使网络更好地了解形状的方向。
- 有的使用图像分割来帮助网络分离不同的语义区域(面部,头发等)。
- 最常见的表示形式是特征点(也称为关键点),即面部或身体上一组定义的位置点。
- 有的按通道分隔特征点,以使网络更容易标识和关联它们。
- 类似地,面部边界和身体骨骼点的表示等。
- 对于音频,常见方法是衡量音频段(主要语音频率)的Mel-Cepstral Coefficients(MCC)


上述素材源于网络,侵删
4、Deepfake的一些流程示例
要生成目标的x_g,重现和(人脸)替换类型的网络一般遵循以下过程(将x传递到以下pipeline):
- (1)检测并裁剪面部;
- (2)提取中间特征表示;
- (3)根据一些驱动信息(例如,另一张脸)生成新(面部)内容;
- (4)将生成的脸融合到目标帧中。
通常,一些驱动图像生成的方法有:
- (1)让网络直接在图像上执行映射学习,
- (2)使用ED解耦身份,然后进行修改/交换编码特征;
- (3)在将其传递给解码器之前添加其他编码;
- (4)在生成之前将中间人脸/身体的特征表示转换为所需的身份;
- (5)通过光流驱动生成
- (6)使用3D渲染,warped image或生成的内容进行组合,以创建初始内容(头发,场景等),然后将该合成(粗略结果)通过另一个网络( (例如pix2pix)以改善真实感。
5、技术挑战
- 泛化性。生成网络是数据驱动的,因此在所生成的结果中反映了训练数据的特性;良好的效果受限于训练数据集,特定身份的高质量图像需要该身份的大量样本。
- 成对式监督训练。其实还是数据问题,带标签成对具有GT的数据实在难以获取。为了避免这个问题,许多Deepfake网络通过使用自监督的方式进行训练,或者使用不成对的网络(例如CycleGAN),或者利用的ED网络的编码在潜在空间进行特征编辑。
- 非期望特征迁移。有时会把源身份的特征或区域迁移到目标身份上。也许可以使用注意力机制、few-shot学习,解耦学习、跳跃连接等方法将更相关的信息传递给生成器。
- 遮挡。遮挡可能是手、头发、眼镜或任何其他物品,这可能导致出现伪影、不合理的生成效果等。
- 时间连贯性。 Deepfake视频通常会产生更明显的伪影,例如闪烁和抖动。这是因为大多数Deepfake网络在没有先前帧的上下文的情况下单独处理每个帧。为了减轻这种情况,一些研究人员要么将这种情况提供给G和D,要么进行时间连贯损失约束,要么使用RNN,或者对它们进行组合使用。
6、科技是一把双刃剑
- deepfake技术日渐成熟,deepfake检测技术也在日益受到重视;
- 技术如若用于邪处,那是极其可怕的。你支持deepfake的研究吗?日益成熟的deepfake是好是坏呢?

图自网络,侵删
GAN&CV交流群,无论小白还是大佬,诚挚邀您加入!
GAN相关阅读入门:
综述和论文:
- GAN整整6年了!是时候要来捋捋了!
- 数百篇GAN论文已下载好!搭配一份生成对抗网络最新综述!
- 新手指南综述 | GAN模型太多,不知道选哪儿个?
- CVPR2020之MSG-GAN:简单有效的SOTA?
- CVPR2020之姿势变换GAN
- CVPR2020之多码先验GAN:预训练好的模型怎么使用?
- 两幅图像!这样能训练好 GAN 做图像转换吗?
- 最新下载!一览2020年3月至今90多篇GAN论文!
- 最新下载!一览2020年2月50多篇GAN论文!
- 一览!2020年1月份的GANs论文!
- 2019年12月份的GANs论文一览
- 这么多!11月份来的这些GAN论文都在解决什么方向的问题?
部分应用介绍:
编辑于 2021-04-16 00:12

