
Abstract
DNA is the molecule that contains all the genetic information necessary for the life of an individual. The way in which this information is expressed through the appearance of an individual is explained by the flow of information known as the central dogma of molecular biology. This dogma encompasses the processes of DNA replication, transcription of the DNA message into an RNA molecule (called messenger RNA), and translation of the message carried by the mRNA from a code based on sequences of nucleotides to a code based on amino acids, which results in the formation of a polypeptide. The resulting polypeptide may have a structural function, or enzymatic function, or will become part of a more complex protein by binding to other polypeptides. The polypeptides determine the phenotype of the individual, either by acting in the cell in which they were obtained, or in other cells. This flow of information is basically the same for all living organisms, whether they are prokaryotes or eukaryotes. There are of course small differences in some aspects of the processes involved when prokaryotes and eukaryotes are compared. The replication of DNA occurs on the entire molecule, whereas transcription occurs on a single gene that will later be translated. In eukaryotes, there are several systems of gene regulation that favor or prevent the transcription of a given gene; this being the explanation for why there are different appearances and protein contents for the cells that make up the same multicellular organism, even though they all have exactly the same information in the DNA. The information contained in the DNA of an organism is normally invariant as it passes from generation to generation; however, random and infrequent changes may occur at the time of replication, changing the information contained by adding, subtracting, or substituting any of the nucleotides. These changes are called gene or point mutations.
1 Introduction
Based on Watson and Crick’s model, a series of research studies were initiated that sought to determine how the genetic information contained in DNA was ultimately expressed as a particular phenotype. This is how it is established that the information contained in DNA is transcribed into a molecule of ribonucleic acid (RNA) and translated using the genetic code and is then used to produce a polypeptide or protein.
Crick called this flow of information, the central dogma of molecular biology, which is presented as:

Four processes (represented by arrows) can be observed in this information flow, of which three are naturally present in absolutely all living beings (solid arrows), constituting together the essence of life. The first natural process is the replication of DNA, in which a DNA molecule is capable of producing two exactly alike molecules. The second process is the transcription, in which the information contained in a section of DNA is transcribed into an RNA molecule. Under in vitro conditions, reverse transcription has been achieved, i.e., DNA has been obtained from RNA. The third natural process is translation, in which the message carried by RNA is translated in the ribosomes by means of the genetic code to synthesize a polypeptide chain. These chains or proteins will shape the phenotype of an individual. Figure 3.1 summarizes the central dogma of molecular biology illustratively, in a cell of a eukaryote organism.

Processes of central dogma of molecular biology in a eukaryotic cell. At nucleus are achieved: DNA replication (just once in the cell life) and gene transcription (as many times as necessary in the cell life). Transcription product or messenger RNA (mRNA) goes to cytoplasm, ribosomes assemble to read the RNA message and transform the information encoded in nucleotides to information in amino acids to form a protein
The purpose of this chapter is to explain how the three natural processes of the central dogma of molecular biology occur: replication, transcription, and translation.
2 DNA Replication
2.1 Proposed Models
Three hypothetical models had been proposed for DNA duplication, named as a conservative, semi-conservative and dispersive model (Fig. 3.2). In the first model, it is established that two molecules are obtained from one DNA molecule. In one of them, the two strands that constitute it are totally new, and in the other one, the two strands are the same that gave rise to the new molecule. In the semiconservative model, the two resulting molecules have one strand from the original molecule and the other one is new, while in the dispersive model, both strands of each DNA molecule have original segments and new segments.

Proposed hypothetical models for DNA replication
In 1958, M. Meselson and F. Stahl determined which model was the best fit to reality (Fig. 3.3). For this, they placed a population of Escherichia coli in a growth medium with the heavy isotope of nitrogen 15N, and the other was placed in a medium containing normal nitrogen 14N. Nitrogen is an important constituent of nitrogenous bases of DNA nucleotides (Fig. 2.4).

Meselson and Stahl experiment. This experiment demonstrated that semiconservative model is the model followed in DNA replication
Those placed at 15N were extracted from that medium after many cell divisions and placed in a medium with 14N. Two samples were taken from here: one after one generation and another after two generations. In each of these samples, DNA was extracted and placed in test tubes with a salt gradient achieved with cesium chloride (CsCl), which allows the weight of different molecules to be differentiated by density. The authors observed that the sample extracted after one generation, formed a single band of intermediate density, between the density of E. coli DNA placed at 14N and density of E. coli DNA placed at 15N. The sample extracted after two generations formed two bands: one intermediate (same as above) and another one like that of E. coli DNA when it was grown on 14N. These results could be explained by the authors via the semiconservative model for DNA replication, because theoretically the other two models would not have given these results. In the same year, H. Taylor et al., ratified the semiconservative theory of DNA replication by working with Vicia faba roots. They placed root cells in a medium containing radioactively labeled thymine. Cell division took place by several generations in such a way that all cells would have this marked nitrogenous base. Subsequently, they added colchicine to prevent cell division but not replication of the DNA. They extracted these cells from that medium, and placed them in another medium with non-radioactive thymine also adding colchicine. In both cases, they subjected the cells to autoradiography, i.e., they placed a photographic film capable of capturing radiation. Chromatids (chromosome arms, see Chap. 5) in the medium with radioactive thymine had the full extent of radioactivity, while those placed later in a medium with non-radioactive thymine, emitted radioactivity in only two of their four chromatids; these results only fit the semiconservative model.
2.2 Process
The DNA replication process has two steps: origin of replication and DNA elongation (Fig. 3.4). The overall process has been extensively studied in prokaryotes as well as in eukaryotes; however, the differences are minimal, which is why the process will be explained as it occurs in prokaryotes, taking E. coli as a model, and then pointing out the differences in eukaryotes. For replication to be initiated DNA is required for a point of origin, which is a specific DNA sequence from 245 base pairs (bp), called ORI. This sequence possesses sites that allow it to be linked by a set of proteins called replisome, with helicase function (they unwind and unroll DNA) and gyrase (separating the two strands). In this way, the nitrogenous bases are exposed from the two strands of DNA, which allows an enzyme called RNA polymerase to locate the 3′-5′ band (this direction is referred to the forward direction of replisome), bind to it, to read it and synthesize an oligonucleotide (short sequence of nucleotides) of 6–10 bp, complementary to the exposed bases of this strand. This oligonucleotide is called a primer. Continuously, the replisome moves over the 3′-5′ leaving the nitrogenous bases exposed. For elongation of DNA, the DNA polymerase III enzyme must act, but because it is incapable of initiating DNA synthesis on its own, it needs to bind to segments of DNA or RNA already synthesized to initiate its polymerase action. This is why the RNA polymerase locates the primer on the 3′-5′ strand in such a way that the DNA polymerase can elongate the DNA strand in the 5′-3′ direction using the band exposed by the replisome as a template, and by locating on it, by base complementarity, the nucleotides that will make up the new band. Because the DNA polymerase enzyme is only capable of synthesizing DNA in the 5′-3′ direction, and that, as is known, the strands that make up DNA are antiparallel, it becomes impossible for new strands to be synthesized in the same direction at the same time. The strand that originates in the 5′-3′ direction, having as a pattern the 3′-5′ strand, is called the leading strand, and its synthesis is continuous since the direction of work of the DNA polymerase is the same that leads to the opening of the template DNA favored by the replisome. On the contrary, the other pattern strand, being antiparallel, is 5′-3′ so that the synthesis of the new strand (3′-5′) cannot be done continuously since this is not the working direction of DNA polymerase III. This enzyme, acting at the same time on both bands, can synthesize continuously to the leader band, but by using the 5′-3′ band as a pattern, it can only synthesize small DNA fragments in their direction of synthesis, which is, over this strand, inverse to the displacement it has. Because of this, new small fragments are placed in the space that the enzyme is occupying at the moment of its displacement. For this reason, this strand is called a lagging strand. Of course, prior to this, the RNA polymerase has placed several primers along the pattern strand. These discontinuous DNA fragments are called Okasaki fragments, and they are subsequently joined by DNA polymerase I and DNA ligase to achieve the two new DNA strands.

DNA replication. It has been arbitrarily indicated that the replisome and later the DNA polymerase advance in this illustration from right to left; therefore, the band to be considered as 3′-5′ is the lower band, and the upper one is 5′-3′. (a) Circular DNA of E. coli. (b) Replisome on DNA. (c) Exposing nitrogen bases. (d) Action of RNA polymerase. (e) Action of DNA polymerase
In eukaryotic organisms, one of the differences from prokaryotes is that there are several sites of origin and not only one. In these organisms with cells with a defined nucleus, it is necessary to consider the cell cycle to locate at what point replication occurs. The cycle of eukaryotic cells are divided into:
-
(a)
G1: in this stage the cell prepares for the DNA replication by synthesizing the components required for this.
-
(b)
S: this is the step where replication takes place.
-
(c)
G2: the cell prepares for cell division.
-
(d)
M: cell division.
3 DNA Transcription
3.1 General
There is plenty of evidence that allow us to affirm that DNA cannot produce polypeptides on its own, but requires another compound to mediate in the protein synthesis process. This evidence includes:
-
(a)
The site of protein synthesis, which is the ribosomes, does not contain DNA but RNA.
-
(b)
When protein synthesis is initiated in the cell, the amount of RNA increases in the cell, but not that of DNA.
In view of this, it was thought that the genetic information contained in the DNA was transferred to the RNA (a process known as transcription) and subsequently the RNA was capable of directing the ribosome for protein synthesis (a process known as translation).
3.2 Process
The transcription of each gene has the steps of initiation, elongation, and termination. DNA in each of the genes has a promoter region (sequence), which is a DNA region that allows the beginning of the transcription, a coding region that allows the elongation of the new RNA strand, and a termination region that allows the ending of the process, indicating that the DNA message will be read up to there. The new strand, as already mentioned, is composed of ribonucleic acid (RNA), which is a molecule that differs from DNA in three fundamental aspects:
-
(a)
The sugar in its structure is a pentose called ribose, and not deoxyribose as in DNA.
-
(b)
One of its pyrimidine bases is uracil instead of thymine.
-
(c)
It has a single and not a double strand structure.
The largest amount of RNA extracted from a cell corresponds to three types:
-
(a)
Messenger RNA (mRNA): is the product of transcription.
-
(b)
Ribosomal RNA (rRNA): component of ribosomes.
-
(c)
Transfer RNA (tRNA): these are small molecules with high specificity for particular amino acids, very important during translation.
3.2.1 Initiation
The promoter region of the DNA must be recognized by the enzyme that polymerizes or synthesizes RNA: RNA polymerase. This enzyme consists of the subunits α, β and β′, which conform the enzymatic center, and it binds to the subunit σ to form the RNA holoenzyme RNA polymerase. The holoenzyme searches for the promoter region, consisting of sequences called consensus sequences, located at −35 and −10 bp (−35 and −10 bp are indicated because these sequences are found 35 and 10 base pairs prior to the initiation of the coding region of the gene, it means, base pairs can be numbered in a gene as 1, 2, 3, …, n for the base pair that conforms the coding region of the gene, and −1, −2, −3, …, −n for the bases placed just before the start of the coding region) thus forming the closed promoter complex. The factor σ recognizes the promoter and binds tightly to it by unwinding the DNA in the region of the promoter, close to −10 bp. This allows conforming the open promoter complex (Fig. 3.5).

Transcription initiation. (a) Strand of DNA that will be transcribed, indicating the consensus sequences. (b) Formation of the closed promoter-complex when the sequence located at −35 bp is recognized by the RNA polymerase. (c) Formation of the open promotor complex: RNA polymerase recognizes the sequence located at −10 bp and breaks the hydrogen bonds so that the molecule can open up and thus be able to read the DNA message
3.2.2 Elongation
RNA synthesis is made on a single DNA band, and the direction of polymerization of the RNA polymerase is 5′-3′ (Fig. 3.6). Once the open promoter complex is formed, elongation of the RNA chain is initiated, releasing the factor σ from the RNA polymerase.

Elongation of mRNA during the transcription. RNA polymerase synthetize a molecule of mRNA in direction 5′-3′ by reading DNA strand 3′-5′
Elongation occurs when the enzyme acts on the four types of RNA nucleotides and join them sequentially according to the information of complementarity that RNA polymerase reads on the strand 3′-5′ of the DNA: reading thymine will place adenine, reading cytosine will place guanine, reading guanine will place cytosine, and reading adenine will place uracil.
3.2.3 Termination
There are two mechanisms to stop RNA polymerization. The first involves complementary palindromic sequences, which at the RNA level produces an “RNA head pin”, which conformationally triggers the uncoupling of RNA polymerase (Fig. 3.7). In the template DNA there are GC-rich regions at the end of the gene, and at the end several A repeatedly. The complementarity in the RNA (between RNA nucleotides) is what causes the pinhead. The other mechanism is mediated by the rho protein, which binds to the RNA at a site and uncouples the synthesized RNA from the polymerase.

Transcription termination mechanisms: (a) Hairpin. (b) Rho protein-mediated mechanism
3.2.4 Post-transcriptional Changes
The RNA polymerase synthesizes the strand along the entire length of the template DNA, i.e., absolutely all the bases of the template DNA are read between the boundaries of the coding region of the gene being transcribed. In eukaryotic DNA there is the presence of introns, which are DNA sequences with no known function that do not reach the level of translated. For this to be the case, the RNA synthesized in the transcription process of eukaryotes, or primary transcript, must undergo some changes before it becomes the mRNA that will be directed to the ribosomes. Among these changes is the enzymatic elimination of sequences corresponding to introns. In addition, since the mRNA must exit into the cytoplasm it has to be protected from the restrictive action of some of the enzymes present in the cytoplasm, which is achieved by adding methyl groups and a tail of several adenines, collectively referred to as the poly-A-tail.
4 Translation
Once the mRNA contains the genetic information from the DNA, it is directed toward the ribosomes, where, in the presence of enzymes, protein factors, amino acids and energy, it is capable of directing the synthesis of polypeptide chains. For this to occur, it is necessary to translate the “nucleotide language” carried by the mRNA into an “amino acid language,” in such a way that the amino acids are joined in the required order to form the necessary protein. This translation is carried out using the genetic code.
4.1 Genetic Code
It is well known that proteins are made up of different combinations of the 20 existing amino acids. One of the first questions that were raised, already confirmed experimentally by means of the flow of genetic information, was how the four nitrogenous bases that make up mRNA (A, U, C, G) are organized to produce 20 different messages, one for each of the amino acids. If each of the bases were one of messages, there would only be 41 = 4 messages, which is not sufficient to differentiate between the 20 amino acids. If they were grouped two by two (e.g., AU, CG, AC, etc.) there would be 42 = 16 possible combinations, 16 different messages, which also does not allow us to differentiate between all amino acids. If they are grouped in threes (e.g., AUC, GAG, CCG, etc.), they would give 43 = 64 possible combinations, which would be a sufficient number of messages to encode 20 amino acids. Based on this, it is pointed out that in the genetic code each amino acid is encoded by sequences of three nitrogenous bases, which are named codon. Second, the question arose as to how this code acted, i.e., whether or not the different messages overlapped. This concern had its response in the analysis of mutationally altered proteins since the study of these proteins observed that there were only changes one amino acid at a time in a certain region of the protein. This was an indication that changes in one of the nitrogenous bases of a codon would result in the following changes in only one amino acid, which led to the conclusion that the genetic code was not overlapping, because if it did, changes in only one base of a codon would result in changes in several codons, and if it did, changes in only one base of a codon would result in changes in several amino acids (Fig. 3.8). Based on this knowledge, studies were initiated to determine the codon–amino acid correspondence, i.e., the genetic code began to be deciphered. This was accomplished through the work of H. Khorana, who used copolymers nucleotide repeats, (e.g., AGAAGAAGAA…, or UCGUCGUCGUCG…, etc.) together with everything necessary for protein synthesis (ribosomes, tRNAs, amino acids, energy) in vitro. Of the amino acid constituents of the chain polypeptide formed, and of the possible chains or triplets that could be grouped in the copolymers, it was possible to obtain the codon–amino acid correspondence, and it was observed that some amino acids are encoded by more than one codon (Table 3.1). It was also noted that three triplets in particular did not encode any amino acids. All this information enables us to recognize the following characteristics in the genetic code:

Possibilities of genetic code overlap. In an overlapping code, each nitrogenous base can belong to up to three codons, while in a non-overlapping code each base can belong to only one codon
-
(a)
They do not overlap their elements in an mRNA strand to give the information it contains.
-
(b)
The information is read in only one direction, the genetic code is unidirectional.
-
(c)
Three bases, collectively called triplet or codon, encode for an amino acid.
-
(d)
For specific information, i.e., to obtain a certain protein, the code is read from a fixed starting point.
-
(e)
The code is degenerate since some amino acids are specified by more than one triplet or codon.
-
(f)
It is universal, since it is the same in all living organisms, from unicellular beings such as bacteria to complex multicellular beings such as mammals.
-
(g)
There are three codons which do not code to an amino acid; they are stop signals for the translation process.
4.2 Process
As mentioned before, translation is the decoding of messages carried by the mRNA. For this to occur, another type of RNA, transfer RNA (tRNA), is required, which has the function of binding to a specific amino acid (which is free in the cytoplasm, coming from nutrition in animals, and from synthesis from mineral nutrients in plants) and take it to the ribosome where mRNA has also arrived. This mRNA molecule directs the order in which the amino acids carrying each of the tRNAs will be placed. In this translation process, it is also possible to identify three steps: initiation, elongation, and termination.
4.2.1 Initiation
The understanding of the initiation and the rest of the process requires knowledge of the ribosomes and tRNA. Ribosomes are cellular components that are mainly found in the rough endoplasmic reticulum in eukaryotes. They are made up of two subunits: a large one, with a sedimentation constant (this is an indirect measure of the size) of 50S in prokaryotes and 60S in eukaryotes, and a small with sedimentation constants of 30S and 40S for the same types of organisms, respectively. Each subunit consists of proteins and rRNA (ribosomal RNA), having active sites that allow mRNA, tRNA, and protein factors related to translation to bind to the ribosome. The tRNA is a molecule with secondary structure cloverleaf-shaped. It has a sequence of bases called the acceptor, and it is here that the amino acid is bound by enzymatic action. The opposite end to the acceptor arm has three nitrogenous bases called anticodon, which are the ones that by complementarity will be able to bind to the mRNA. As long as translation does not occur, the two ribosomal units are separate, free in the cell cytoplasm. For the ribosomes to assemble, the mRNA must bind to the small subunit of the ribosome, which is stimulated by prior binding of the ribosome to a protein factor (IF3) (Fig. 3.9). Another protein factor (IF2) binds to a tRNA that carries a modified form of the amino acid methionine: the formylmethionine. This modified amino acid initiates the protein sequences of a large number of organisms. It should be noted that the anticodon of this tRNA is the same as that of the tRNA carrying methionine; it should also be noted that the complementary codon to this anticodon (AUG) is the only one that encodes for methionine. The same IF2 factor stimulates the binding of this complex to the mRNA bound to the small subunit of the ribosome, tRNA is located in one of the two binding sites of the ribosome to this molecule: the P box. Subsequently, the large subunit of the ribosome is assembled with this complex.

Translation initiation. In the upper left part of the illustration, we can see the assembly of mRNA with the small subunit of the ribosome, thanks to the protein factor IF3. The right side of the illustration shows the location of the tRNA in the P-box, to finally observe the assembly of everything needed to start translation
4.2.2 Elongation
The next tRNA must have an anticodon complementary to the mRNA. The one that does, thanks to the action of the protein factor EF-Tu, is located at the other binding site of the ribosomes, the A box (Fig. 3.10). The ribosomes move over the mRNA in the direction 5′-3′ and do so in three bases. The P site is oriented in the 5′ direction and the A site in the 3′ direction. The amino acid that is in the P-box (formylmethionine) is transferred to the A box and linked to the amino acid found there. Subsequently, ribosome displacement occurs, thus allowing the nascent polypeptide chain to be located on the ribosome in the P-box and the A-box becomes free again, waiting for another tRNA loaded with an amino acid whose anticodon is complementary to the mRNA codon. This is repeated as many times as there are codons in the mRNA.

Elongation of the polypeptide chain
4.2.3 Termination
There are protein factors that recognize the UAG, UAA, and UGA termination codons. When the polypeptide chain is located in the P-box, and one of the codons mentioned is in the A-box (Fig. 3.11), the protein termination factors recognize them and induce the release of the polypeptide chain and the dissociation of the ribosomal subunits. In this way, it is possible to obtain a polypeptide that is located in the cytoplasm and that will be taken to the site where it is required, either to form part of the cellular structure or to fulfill enzymatic functions or to combine with other polypeptides to form complex proteins that can fulfill any of the functions already described, either in the same cell where it was synthesized, or in another cell.

Translation termination
Based on the central dogma of molecular biology, currently the concepts of genomics, transcriptomics, proteomics, and metabolomics are often used, which refer to the study of genome, transcriptome, proteome, and metabolome, respectively. Because the genome is the set of DNA sequences or genes, genomics is the study of genes; transcriptome is the set of transcripts of DNA, it means RNA, therefore transcriptomics is the study of RNA; proteome is the set of proteins, therefore proteomics is the study of the proteins; and metabolome is the set of metabolites, therefore metabolomics is the study of metabolites, a metabolite being a substance produced as a consequence of the metabolism. Because metabolism is highly influenced by enzymes, which are proteins, metabolites can be considered dependent on the central dogma of molecular biology.
5 Regulatory Mechanisms
When observing any multicellular living being, it can be detected that in each of the cells that make it up expression of the same genes does not occur, despite the fact that the genetic content of the genes of an individual is exactly the same in all its cells. If the leaves of a maize plant are observed, it is evident that they present a different appearance to the appearance of the maize plants roots. Similarly, if a maize plant is observed 10 days after germination, appearance is also different as compared to the same plant when inflorescences appear. A similar situation will be observed in any animal: the appearance of the legs of an animal is absolutely different from the appearance of its eyes (and in both legs and eyes there is exactly the same DNA, with the same information), or if a newborn animal is observed, it will have a different appearance than when it is an adult, but the information contained in the DNA in its cells has not changed.
This type of observation allows us to point out that both the location of the cells in an organism, as well as their stage of development, will determine the expression of certain genes. This is due to the fact that there are mechanisms that regulate the expression of certain genes, which can be explained by the presence of proteins that react with environmental factors (light, temperature, concentration of a certain substance in the cells, etc.). Thus, these molecules, when stimulated by these factors, achieve a response at the level of any of the observed steps in the flow of genetic information. A certain stimulus from environmental factors, e.g., light, can modify the configuration of a certain protein which attaches to the DNA in the promoter region of a certain gene, thus preventing the gene’s RNA polymerase from synthesizing mRNA, thus preventing transcription. There are other post-transcriptional regulatory mechanisms and others at the level of translation. Any of them can be negative or repressor, or positive or inducible, i.e., either of them can be negative or repressor, or positive or inducible, can prevent or stimulate the expression of certain genes, either by preventing or stimulating transcription, or translation.
6 Genetic or Point Mutations
Mutations are defined as changes that occur in the structure of the genetic material.
The genetic material is hereditary, and is transmitted to the offspring of the cell that carries it. There are two types of mutations:
-
(a)
Chromosomal.
-
(b)
Gene or point mutation.
This chapter will only consider gene or point mutations (chromosomal mutations are explained in Chap. 10), which are defined as alterations in the sequence of nitrogenous bases in DNA. These mutations can occur spontaneously, or be induced by the action of mutagenic agents such as ionizing radiation (for example, X-rays) and chemical agents. Whatever their nature, gene mutations are classified as follows:
-
(a)
Substitutions
-
(i)
Transition
-
(ii)
Transversion
-
(i)
-
(b)
Addition
-
(c)
Deficiency
Substitutions involve the exchange of one base for another. If a purine is substituted for another purine, or a pyrimidine is substituted by another pyrimidine, transition is the name of this kind of mutation, whereas, the term transversion is used when a purine is replaced by a pyrimidine or vice versa. Any of them can give rise to the following types of mutations:
-
1.
Silent mutation: the mutated codon encodes for the same amino acid as the original codon, e.g., UUA CUA (both encode for leucine).
-
2.
Neutral mutation: the codons code for different amino acids, but they are functionally equivalent in the polypeptide chain.
-
3.
Nonsense mutation: the mutated codon encodes for a termination signal, for example, CAG UAG.
Addition is the incorporation of a nitrogenous base into the DNA, while a deficiency is the loss of one of these bases. Both will cause a change in the DNA reading frame since the genetic code is read three bases at a time, the addition or subtraction of one of the bases will change the entire message. This causes a change in the composition and/or size of the protein.
Recommended Reading
Meselson M, Stahl F (1958) The replication of DNA in Escherichia coli. Proc Natl Acad Sci 44(7):671–682
Author information
Authors and Affiliations
Knowledge Integration Questions
Knowledge Integration Questions
Starting from the following DNA molecule,

and using the genetic code, point out:
-
(a)
The product of its duplication
Knowing that DNA duplication is semiconservative, i.e., from each of the strands that make up the molecule, a new strand will originate to result in, finally, two DNA molecules that are exactly the same, the product of the replication of this molecule is as follows:
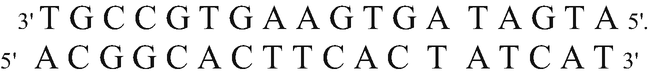
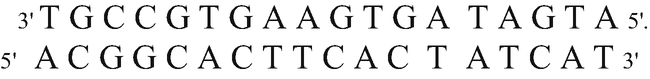
-
(b)
The constituents of the protein that would be formed from the strand identified with an asterisk (*)
DNA must be transcribed into an RNA molecule to be able to subsequently be translated. RNA polymerase, which reads DNA to form RNA, polymerizes in the 5′-3′ direction, so it reads in the 3′-5′ direction. For this reason, the synthetized RNA would be:
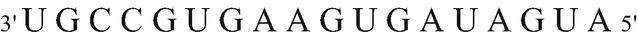
The mRNA is read by ribosome in the 5′-3′ direction. Amino acids that will make up the polypeptide will be sorted according to genetic code.
-
AUG: Methionine AUA: Isoleucine GUG: Valine
-
AAG: Lysine UGC: Cysteine CGU: Arginine
-
-
(c)
How many times and at what point in the cellular life do the processes occur that allowed us to answer part (a) and (b) of this question.
-
DNA replication: only once, shortly before cell division.
-
Transcription and translation: as many times as the protein to be formed requires.
-
-
(d)
Indicate what differences exist (if any) between prokaryotic and eukaryotic organisms in the processes you applied in part (b) of this question.
In prokaryotes, transcription and translation do not occur in cellular compartments, whereas in eukaryotes transcription takes place in the cell nucleus and translation occurs in the cytoplasm.
In prokaryotes, there are no post-transcriptional changes. In eukaryotes, there are the following post-transcriptional changes on the primary transcript to form the mRNA: removal of introns, addition of methyl groups, and addition of the poly-A tail.
-
(e)
Will the DNA molecule indicated remain unchanged over time?
Normally yes. Through the replication of DNA, the cells resulting from mitosis will have exactly the same DNA and therefore the same information. However, due to some eventual biological mistakes during the replication, some nitrogenous bases may be lost, or added, or replaced with others as a consequence of a mispairing between the nitrogenous bases of the DNA molecule during replication. These errors will cause changes in the DNA, which are known as mutations.
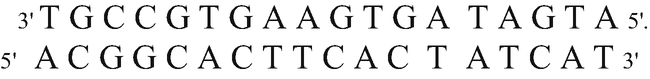
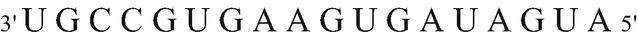
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this chapter

Cite this chapter
Laurentin Táriba, H.E. (2023). Central Dogma of Molecular Biology. In: Agricultural Genetics. Springer, Cham. https://doi.org/10.1007/978-3-031-37192-9_3
Download citation
DOI: https://doi.org/10.1007/978-3-031-37192-9_3
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-37191-2
Online ISBN: 978-3-031-37192-9
eBook Packages: Biomedical and Life SciencesBiomedical and Life Sciences (R0)