关于Linux Preempt RT补丁的实时编程问题?
5 个回答

本来是发一下rk3588 xenomai实时数据的,居然有好几个收藏,那整体回答一下,这是一个很大的话题,涉及面广,每个拎出来都是很大的话题,所以回答略显粗糙,还请见谅。
一、首先,什么是实时操作系统(RTOS)?
什么是实时
实时的分类
常见的RTOS
latency和jitter
总结一下,实时其实说的是系统响应事件需要的时间的确定性,时间必须确定,打死都不能超过这个时间。
二、 linux为什么不是实时操作系统?
要保证系统实时性(事件响应计算输出的时间确定),我们可以将整个过程时延分别分解如下,只有保证了各个部分时间的确定性,才能保证整体响应时间的确定性。而操作系统仅能保证系统层面时延,也就是完成实时任务的调度执行,至于你的实时任务执行时间确不确定取决于你的软件算法设计,然后输出计算或控制结果。


下面对操作系统延时进行分解,可分解为系统延时=中断响应延时+中断处理延时+调度延时+进程切换延时,所以我们一一来看,linux为什么不实时?
- 中断响应时间
任何条件下,linux中断响应时间确定吗(也就是最大中断屏蔽时间确定吗)?全球这么多开发者一起开发,linux支持这么多外设驱动,谁的驱动屏蔽中断执行多久谁知道呢?
- 中断处理时间
那linux的中断处理延时确定吗?同样未知!不同的板子,不同的外设,中断处理需要的时间均不一样。
- 任务调度时间
那一个事件产生,现在要找到下一个使用cpu的任务,如果系统中有成千上万个任务,linux从中选择运行的任务的时间要多少,这个调度过程的时间确定吗? 这就是为什么要有不同调度类和调度算法,不同调度类之间还要有不同的优先级,EDF调度类>RT调度类>完全公平调度调度类>idle调度类。但linux的实时问题不是出在这,而是什么时候能调度的问题!!!
任何操作系统的调度追求2个目标:吞吐率大和延迟低,但这个目标是相互矛盾的。调度和上下文切换过程本身也是要CPU时间的,频繁的上下文切换会导致CPU时间的浪费,降低系统的吞吐量,
Linux是通用操作系统(GPOS), linux定位是尽量缩短系统的平均响应时间,提高吞吐量,注重操作系统的整体功能需求,达到更好的平均性能。(过度追求响应时,过多的上下文切换把 CPU 时间消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,从而缩短进程真正运行的时间,导致系统的整体性能大幅下降),所以规定在哪可以调度很重要,也就是我们说的调度点或者抢占点。
说白了,调度也是一段代码,一个函数,什么时候可以调用这个函数呢?不同的抢占模型抢占点不同,目前linux主线提供了3种抢占模型。
1、No Forced Preemption(Server)
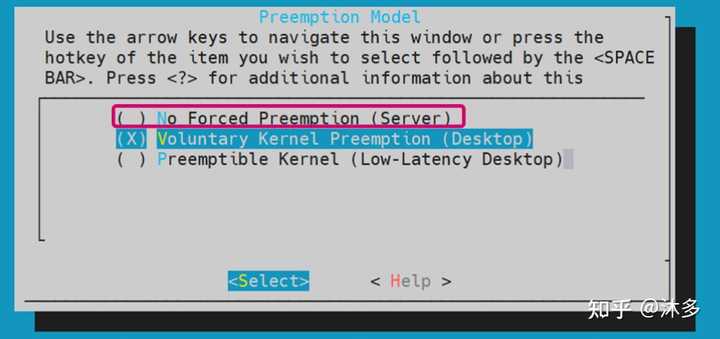



早期linux为追求最大吞吐量,只能在内核态返回用户态时 和中断处理返回用户态时进行调度,也就是整个内核态执行的过程中都不能抢占,那外部事件产生到p3任务执行,这时间就可大了去了。
这是传统的抢占模型,目标是使吞吐量最大化。大多数时候提供良好的延迟,但是没有保证,可能偶尔出现长的延迟。这种模型主要用于服务器和科学计算系统。如果希望使内核的处理能力最大化,不考虑调度延迟,那么应该选择这种模型。
2、Voluntary Kernel Preemption(Desktop)

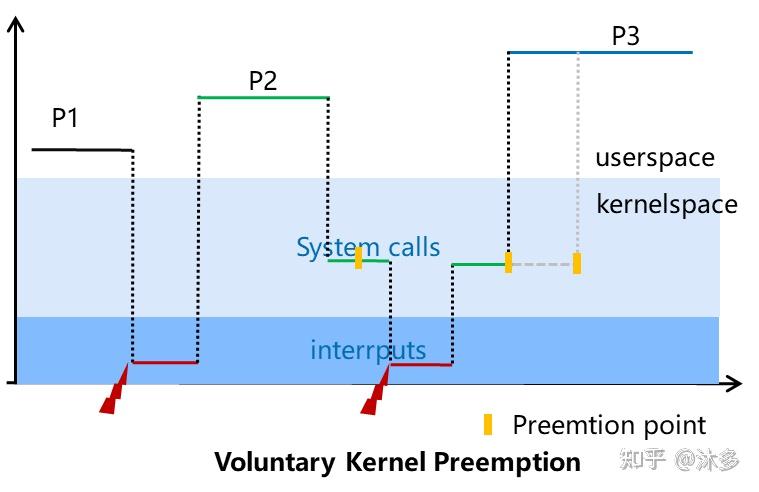
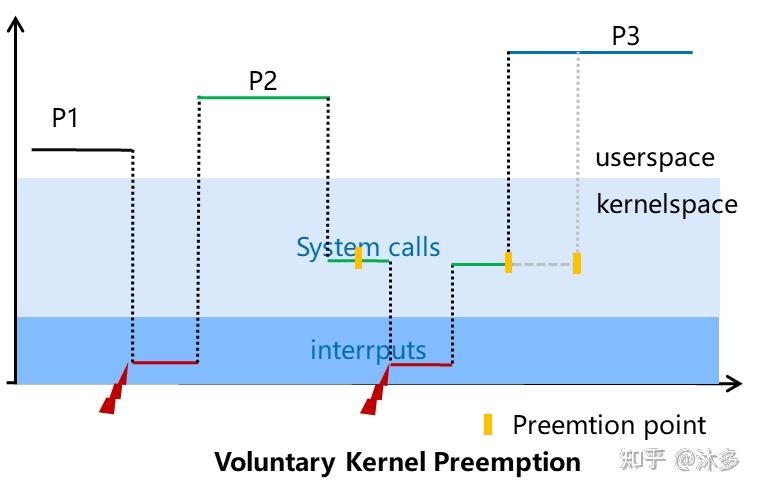
后来呢,为降低系统整体的响应时间,加入了自愿调度,也就是我是内核开发者,我在开发这个驱动或者子系统的时候,我觉得这里我占用CPU太久了,我主动加一行代码调用might_resched()增加抢占点,让别的任务执行一下,相比No Forced Preemption P3事件响应时间明显减少了,这种方式对吞吐量几乎没影响。
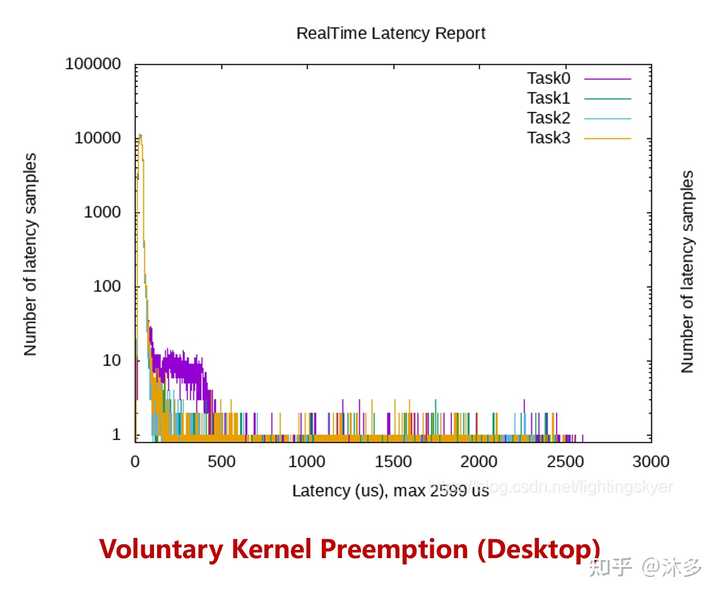

3、Preemptible Kernel(Low-Latency Desktop)

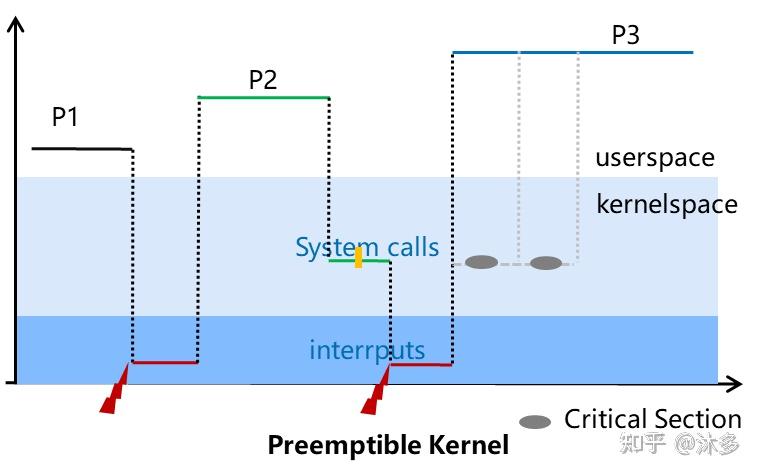

可抢占内核,就是内核态执行过程中,除了临界区以外的所有内核代码可抢占,也就是在上面的基础上增加了中断处理返回内核态(内核态抢占)的抢占点。
提供了很低的响应延迟,最坏情况的延迟时间是几毫秒,代价是稍微降低吞吐量和稍微增加运行时开销。相比Voluntary Kernel Preemption,从事件发生到高优先级的p3到得到运行之间的时间更少了。
这种模型主要用于有毫秒级别延迟需求的桌面系统和嵌入式系统(linux 2.6 以上),比如音频处理。
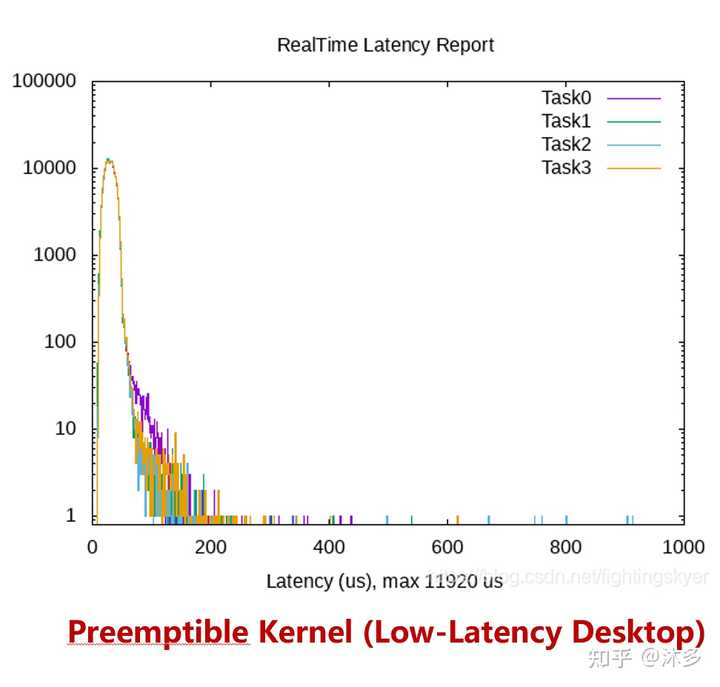

那为什么到这linux还不是一个硬实时操作系统呢?因为增加了中断处理返回内核态的抢占点,内核态中,只要不是关中断的地方,都可能发生抢占,这时候内核开发就变复杂了,任何内核代码都要考虑不同的上下文会不会有重入/死锁问题,多核下死锁的问题,进而增加了更多的临界区,这些临界区是不能抢占的。
所以就算linux启用可抢占内核,还有很多临界区和机制是默认不能抢占的,spinlock默认禁止抢占(整个内核态有10万+地方使用),同时硬中断的执行时间不确定,软中断总是抢占应用上下文等等影响任务调度时间的地方。
4、Full Real Time Preemption(PREEMPT-RT)、
也就是我们说的实时补丁,linux实时化的方案之一。
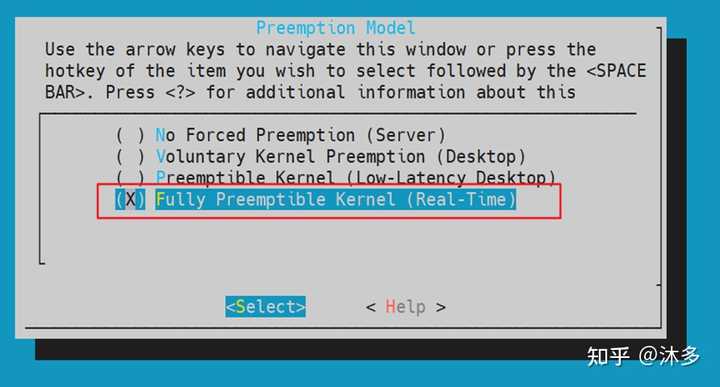

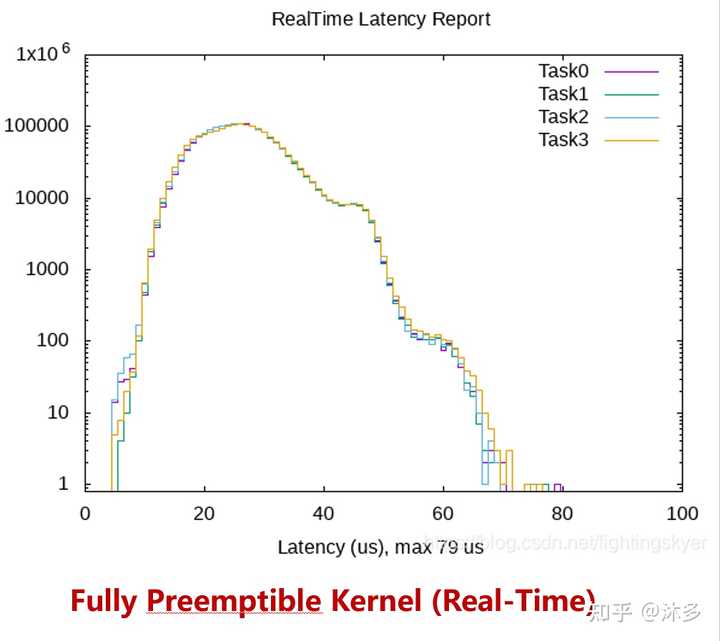
使能RT补丁,得到硬实时kernel,几乎任何地方都可以发生抢占,这种模型主要用于延迟要求为100微秒或稍低(几十微秒)的实时系统。 降低吞吐量、增加更多运行时开销。
PREEMPT-RT包含了hrtimer、优先级翻转、可抢占RCU、中断线程化、Full Tickless、EDF调度等等这些机制来保证系统的整体实时性。其中的90%多已经进入主线内核。
(1)仓库http://git.kernel.org/cgit/linux/kernel/git/rt/linux-rt-devel.git
(2)仓库http://git.kernel.org/cgit/linux/kernel/git/rt/linux-stable-rt.git

- 上下文切换时间
那下一个运行的任务选出来了,linux完成上下文切换需要多久?得益于现在的CPU针对性优化设计,linux上下文切换时间是很短的,与处理器架构相关。
三、linux实时化的方案有哪些?
详见:实时linux概述?


方案一:直接修改现有Linux代码
修改现有内核部分机制达到实时(基本上涉及内核中的每个文件)
RT-patch(PREEMPT-RT)已成为Linux实时增强的标准。它被广泛使用在各行各业:电信,工业自动化,专业音频,医疗设备,数据采集,汽车等。
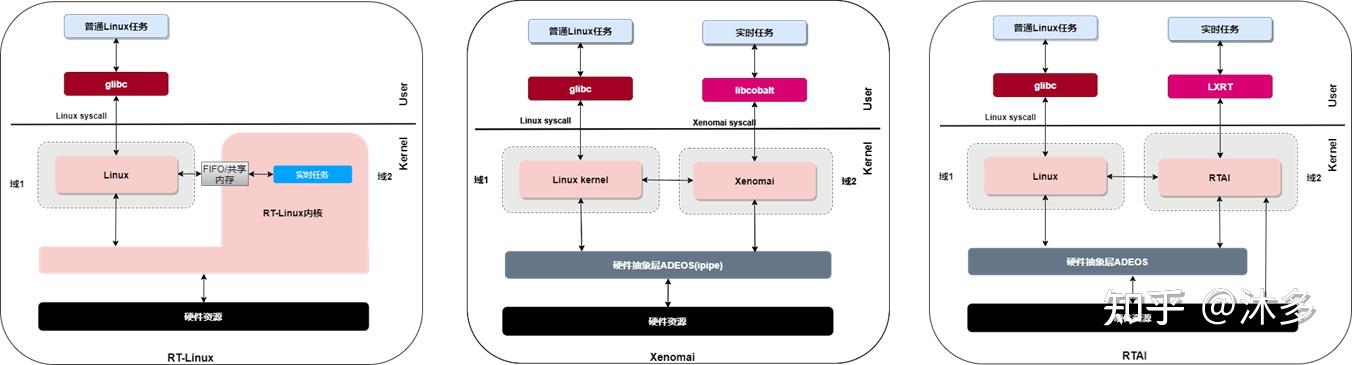
方案二:双内核
内核空间添加一个实时调度核(linux作为实时核的低优先级任务受实时核调度),常用的双内核法有RT-Linux、RTAI(Real-Time Application Interface)和 Xenomai

方案三:多核异构+实时虚拟化
AMP CPU上,一个或多个核跑linux,其他核跑裸机或RTOS,操作系统调度层面完全隔离。
SMP CPU通过虚拟化实现,实时虚拟化介绍详见:虚拟化技术及实时虚拟化概述 。
四、 xenomai的实时性
最近在RK3588上适配了xenomai和igh,并初步测试了一下,很强。

更多实时linux相关文章详见:沐多_xenomai内核解析,linux,X86-CSDN博客
更多实时linux相关文章详见:沐多_xenomai内核解析,linux,X86-CSDN博客
原文链接:有利于提高xenomai/PREEMPT-RT 实时性的一些配置建议
原文链接: 嵌入式实时linux概述
原文链接:【原创】xenomai内核解析之xenomai初探 - 沐多 - 博客园
参考链接:https://blog.csdn.net/fightingskyer/article/details/118877564

最近在研究Preempt RT,即apply rt patch后让Linux达到硬实时。
关于RT patch的详细介绍,岛主打算后面详细地总结一下。今天先讲一下,假设成功apply rt patch之后,那么如何验证实时性呢?
最常用的工具就是cyclictest,本文较为粗略地介绍该工具及其原理,供感兴趣或工作中恰好会用到的同学们参考。
注:Debian/Ubuntu系统下可以直接使用apt-get install rt-tests来安装cyclictest。而本文主要介绍基于ARM的交叉编译方式。
安装cyclictest
1. 下载rt_tests源码
两种方法:
方法1:
如果你能正常访问github,那么直接运行:
$ git clone git://git.kernel.org/pub/scm/utils/rt-tests/rt-tests.git
$ git checkout origin/stable/v1.0
如果不能,使用方法2:
$ wget https://mirrors.edge.kernel.org/pub/linux/utils/rt-tests/rt-tests-1.10.tar.gz
$ gzip -d rt-tests-1.10.tar.gz
$ tar -xf rt-tests-1.10.tar.gz
2. 交叉编译
需要修改Makefile文件
CC = arm-none-linux-gnueabi-gcc -static
AR = arm-none-linux-gnueabi-ar这里我们直接使用static build的方式,这样生成的bin文件不依赖于其他.so文件,方便测试。
3. 解决报错
执行make指令如下:
报错:
src/cyclictest/rt_numa.h:29:18: fatal error: numa.h: 没有那个文件或目录
解决:
1)安装apt-file 来找到依赖库
apt-get install apt-file
apt-file update #更新源
2)寻找 numa.h
apt-file install numa.h
3) 安装相应的库
apt-get install libnuma-dev
测试:
$ file cyclictest
cyclictest: ELF 32-bit LSB executable, ARM, EABI5 version 1 (SYSV), statically linked, for GNU/Linux 4.9.0, with debug_info, not stripped
最后,通过tftp/adb push等方式将bin文件传到board上即可。
| 参数 | 完整参数 | 参数含义 |
|---|---|---|
| 常用的基本选项 | ||
| -a | --affinity | 设置测试线程的亲核性,或设置线程的cpuset |
| -A | --aligned=USEC | align thread wakeups to a specific offset |
| -d | --distance=DIST | 当每个CPU上只有一个线程时,建议将它设置为0。若CPU上有多个实时线程,需要设置一个distance用来隔开线程唤醒的时间,distance会累加到interval的值上,默认是500us |
| -D | --duration=TIME --latency=PM_QOS | 指定测试持续事件,可以加单位 'm' 'h' 'd' 分钟 小时 天 write PM_QOS to /dev/cpu_dma_latency |
| -F | --fifo= | 在指定路径下创建一个管道,用来向它写stats |
| -i | --interval=INTV | 线程睡眠的时间,默认是1000us,即实时线程1000us被唤醒一次 |
| -l | --loops=LOOPS --laptop | 循环次数,默认次数是0(无数次),cyclictest运行的时间等于interval×loops,或是--duration=TIME 省电模式运行cyclictest,得到的结果相对不那么realtime。 |
| -m | --mlockall | 将当前和接下来的内存通过mlock锁定,防止发生swap影响测试 |
| -n | --nanosleep --notrace | 使用精度更高的纳秒睡眠api:clock_nanosleep 抑制追踪的行为(因为ftrace会有一定的overhead) |
| -p | --priority=PRIO | 指定实时线程的优先级 |
| 关于timer和时间的选项 | ||
| -c | --clock=CLOCK | 选择时钟类型。默认是=0 0代表CLOCK_MONOTONIC 1代表CLOCK_REALTIME |
| -N | --nsecs | 测试结果使用精度更高的ns显示(默认是us) |
| -r | --relative | 使用相对时间的timer来代替绝对时间的timer |
| -R | --resolution --secaligned [USEC] | check clock resolution. align thread wakeups to the next full second |
| -s | --system | 使用sys_nanosleep()和sys_setitimer()设置定时器 |
| -t | --threads | 每个处理器分配一个线程 |
| -t | --threads=NUM --tracemark | 指定总线程数,若不指定,线程数等于max_cpus;若不使用-t参数,则线程数为1。 write a trace mark when -b latency is exceeded |
| -S | --smp --smi | 标准smp架构测试,所有的线程将使用相同的-a -t -n和优先级 Enable SMI counting |
| 关于输出打印的选项 | ||
| -h | --histogram=US | 测试完成后输出一个直方图,并输出延时小于US的次数统计。 |
| -H | --histofall=US --histfile= | 类似于-h,输出一个柱状图 指定输出文件的路径 |
| -M | --refresh_on_max | delay updating the screen until a new max latency is hit. Userful for low bandwidth. |
| -q | --quiet | 测试结束后再输出结果 |
| -o | --oscope=RED | 使用'示波器'模式,以减少RED冗长的输出信息 |
| -u | --unbuffered | force unbuffered output for live processing |
| -v | -verbose | 把测试信息输出到stdout |
| tracing相关的选项 | ||
| -b | --breaktrace=USEC | 当出现大于USEC的延时后,立即退出测试 |
| -O | --traceopt=TOPT | trace option |
| -T | --tracer=TRACER | (同-b一起使用)用来指定ftrace的tracer类型,例如:function_graph function nop blk |
| -B | --preemptirqs | (同-b一起使用)追踪preempt和irqoff |
| -E | --event | (同-b一起使用)进行event tracing |
| -I | --irqsoff | (同-b一起使用)追踪irqsoff |
| -P | --preemptoff --policy=NAME --priospread | (同-b一起使用)追踪Preempt off 设置实时进程的调度策略:other, normal, batch, idle, fifo or rr. spread priority levels starting at specified value |
| -w | --wakeup | (同-b一起使用)追踪wakeup |
| -f | --ftrace | (同-b一起使用)使用ftrace |
| -C | --context | (同-b一起使用)追踪context switch |
| -W | --wakeuprt --dbg_cyclictest | (同-b一起使用)追踪wakeuprt。 打印cyclictest的调试信息。 |
例子:
#运行5个线程,线程优先级80,无限循环
sudo cyclictest -t 5 -p 80 -n
#clock_nanosleep 线程优先级80,间隔10000微秒,10000次循环,无负载
cyclictest -t1 -p 80 -n -i 10000 -l 10000
#POSIX间隔计时器 线程优先级80,间隔10000微秒,10000次循环,无负载
cyclictest -t1 -p 80 -i 10000 -l 10000实测:
$ sudo cyclictest -t5 -p 80 -n -i 10000 -l 10000
# /dev/cpu_dma_latency set to 0us
policy: fifo: loadavg: 0.04 0.03 0.07 3/757 6676
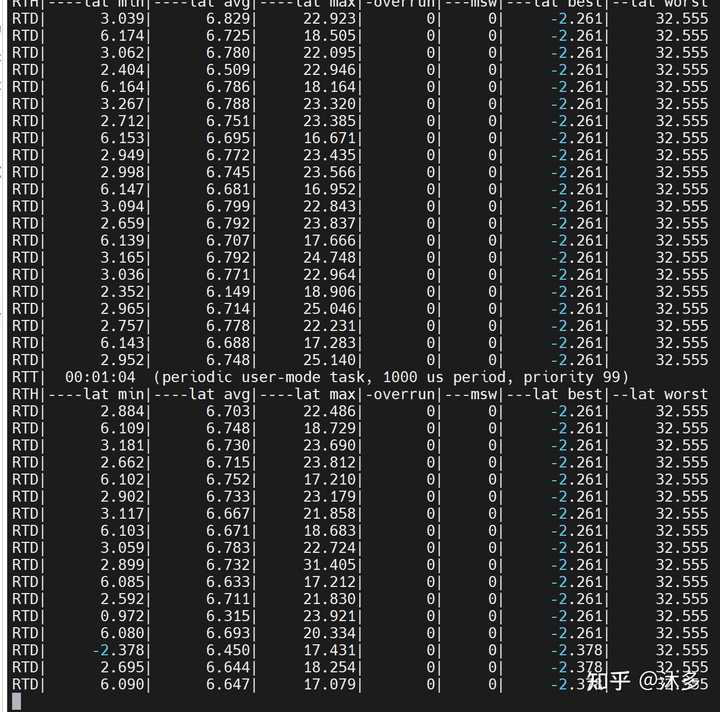
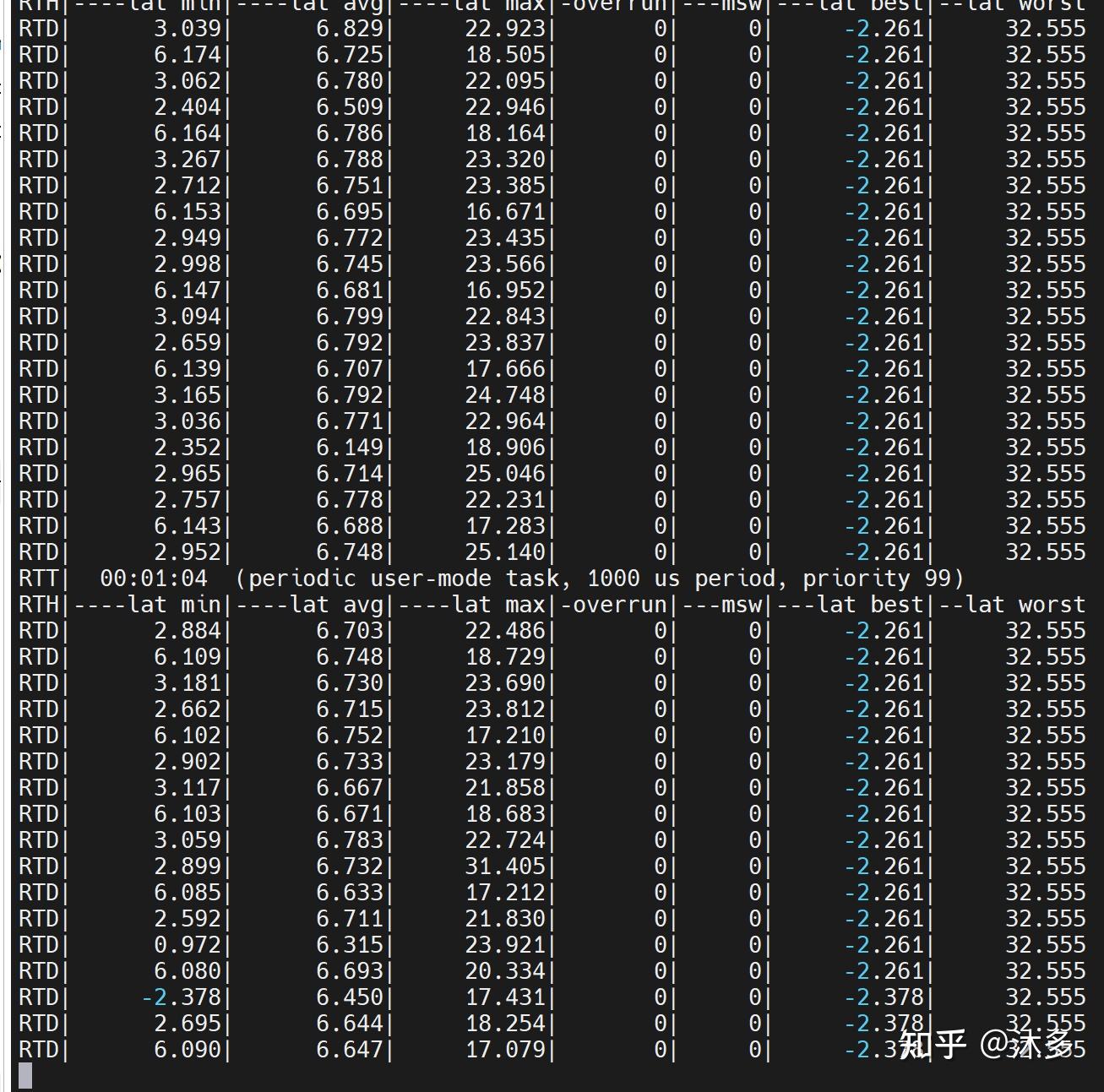
T: 0 ( 6672) P:80 I:10000 C: 830 Min: 30 Act: 96 Avg: 626 Max: 6198
T: 1 ( 6673) P:80 I:10500 C: 791 Min: 13 Act: 428 Avg: 508 Max: 9664
T: 2 ( 6674) P:80 I:11000 C: 755 Min: 14 Act: 807 Avg: 558 Max: 9003
T: 3 ( 6675) P:80 I:11500 C: 722 Min: 13 Act: 758 Avg: 536 Max: 2933
T: 4 ( 6676) P:80 I:12000 C: 692 Min: 31 Act: 717 Avg: 485 Max: 1882打印参数含义:
| T | 线程 |
|---|---|
| P | 线程优先级 |
| C | 计数器。线程的时间间隔每达到一次,计数器加1 |
| I | 时间间隔(us) |
| Min | 最小延时(us) |
| Act | 最近一次的延时(us) |
| Avg | 平均延时(us) |
| Max | 最大延时(us) |
cyclictest 的原理浅谈
从src/cyclictest/cyclictest.c 的 main函数入手:
main进程再启动指定数量指定优先级的实时进程,实时进程会设置一个timer周期性的唤醒自己(从timer溢出触发中断并进入ISR调用wake_up_process()唤醒实时进程,到进程真正能被运行,这中间的时间即我们需要测量的延时)。实时进程得到运行后会再次获取当前系统时间,减去睡眠时间时的时间以及睡眠的时间即可得到延时时间,并通过共享内存将该值传递给main进程进行统计,如此周而复始,最终由main进程将结果输出。
注意:当造成延时的事件发生在timer溢出之前,那么这样的延时将不会被捕捉到,所以我们需要足够久的运行cyclictest才能更大概率的抓取全面的延时数据。
master线程的逻辑:先创建num_threads个指定优先级的实时线程,然后在while循环中读取实时线程放在共享内存中的数据。伪代码如下:
int main(int argc, char **argv)
{ ...
for (i = 0; i < num_threads; i++) {
if (histogram)print_hist(parameters, num_threads)
stat->min = 1000000;
stat->max = 0;
stat->avg = 0.0;
stat->threadstarted = 1;
status = pthread_create(&stat->thread, &attr, timerthread, par);
...
}
while (!shutdown) {
for (i = 0; i < num_threads; i++)
print_stat((stats[i]), i))
usleep(10000)
}
...
}重点放在线程函数timerthread:
void *timerthread(void *param)
{ ...
interval.tv_sec = par->interval // 首先将参数中的间隔数赋给函数中的间隔数
interval.tv_nsec = (par->interval % USEC_PER_SEC) * 1000;
...
/* Get current time */
clock_gettime(par->clock, &now); // 获取当前时间,存在 now 中
next = now; //\
next.tv_sec += interval.tv_sec; // = 这三行是将当前时间(now 的值)加上间隔数(interval)算出下次间隔的时间,存在next
next.tv_nsec += interval.tv_nsec; ///
tsnorm(&next);
...
/* Wait for next period */ 等到下次循环
...
if ((ret = clock_gettime(par->clock, &now))) { //下次循环中记录循环时的时间到now 中,此时now 值中存的数是真实的下次循环的值,而上面存在next 的值是上次循环加上间隔值所以是理论上的下个循环的值。
if (ret != EINTR)
warn("clock_getttime() failed. errno: %d\n", errno);
goto out;
}
if (use_nsecs)
diff = calcdiff_ns(now, next); // 上面已经说过了,now 中是下次循环的真值,而next是理论的值,所以两者的差就是延时!延时赋值给diff
else
diff = calcdiff(now, next);
if (diff < stat->min) // 假如延时比min 小,将min 改为这个更小的延时值diff
stat->min = diff;
if (diff > stat->max) { // 假如延时比max 大,将max 改为这个更大的延时值diff
stat->max = diff;
if (refresh_on_max)
pthread_cond_signal(&refresh_on_max_cond);
}
stat->avg += (double) diff; // 计算新的平均延时
...
/* Update the histogram */ // 更新histogram中存的延时统计数据
if (histogram) {
if (diff >= histogram) { // 假如延时比histogram大,添加一次溢出
stat->hist_overflow++;
if (stat->num_outliers < histogram)
stat->outliers[stat->num_outliers++] = stat->cycles;
}
else // 如果没有溢出,将histogram 中的相应值加1
stat->hist_array[diff]++;
}
stat->cycles++; // 循环加1
next.tv_sec += interval.tv_sec; // 继续计算下次循环的值 ...
next.tv_nsec += interval.tv_nsec;
...
}可见,实时线程的逻辑为:在while循环中先睡眠interval微秒,醒来后获取当前时间,计算延时,然后周而复始。伪代码如下:
clock_gettime((&now))
next = now + par->interval
while (!shutdown) {
clock_nanosleep((&next))
clock_gettime((&now)) //获取指定类型时钟的时间,例如CLOCK_MONOTONIC
diff = calcdiff(now, next) //计算此次延时
# update stat-> min, max, total latency, cycles
# update the histogram data
next += interval
}具体测试时通过创建线程,在线程中进行测试以及记录.刚开始记录开始时间为t_1,时间间隔为l,理论值为t_1 + l。
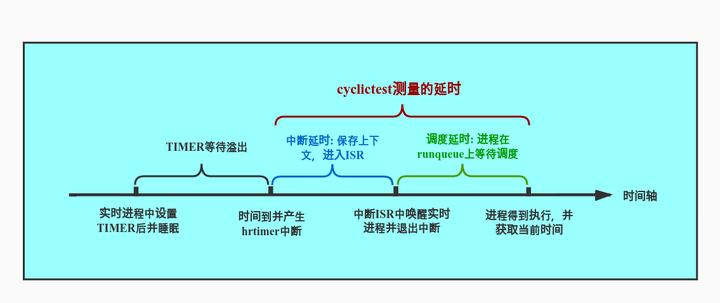
执行结束后再次记录时间t_2, latency即为t_2 - (t_1+l)。
延时在不同的上下文有不同的含义,而cyclictest所测得的延时是中断延时加调度延时,如下图。中断延时(interrupt latency),即中断发生到进入中断处理程序ISR的延时。调度延时(scheduling latency),即当任务被唤醒到任务真正获得CPU使用权中间的延时。