如何看待 Meta 发布 Llama3,并将推出 400B+ 版本?
163 个回答

LLAMA-3的发布是大模型开源届的大事,蹭下热度,在这里谈下有关LLAMA-3、大模型开源与闭源以及合成数据的一些个人看法。
一.LLAMA-3的基本情况:
-模型结构与LLAMA-2相比没有大的变动,主要变化一点在于Token词典从LLAMA-2的32K拓展到了128K,以增加编码效率;另外一点是引入了Grouped Query Attention (GQA),这可以减少推理过程中的KV缓存大小,增加推理效率;还有一点是输入上下文长度从4K拓展到了8K,这个长度相比竞品来说仍然有点短。
-最重要的改变是训练数据量的极大扩充,从LLAMA-2的2T Tokens,扩展了大约8倍到了15T Tokens,其中代码数据扩充了4倍,这导致LLAMA-3在代码能力和逻辑推理能力的大幅度提升。15 T token数据那是相当之大了,传闻中GPT 4是用了13T的Token数据。
-LLAMA-3分为大中小三个版本,小模型参数规模8B,效果比Mistral 7B/Gemma 7B略好基本持平;中等模型参数规模70B,目前效果介于ChatGPT 3.5到GPT 4之间;大模型400B,仍在训练过程中,设计目标是多模态、多语言版本的,估计效果应与GPT 4/GPT 4V基本持平,否则估计Meta也不好意思放出来。
-LLAMA-3并未如很多人预期的那样,采取MOE结构,这也很正常。MOE的主要作用是降低模型训练及推理成本,从效果上比较的话,同等规模的MOE是肯定干不过Dense模型的。当然,如果模型规模大了,怎么降低推理成本方面可能要多花心思。
-感觉LLAMA-3制作8B模型的思路是非常非常正确的。对于小模型来说,如果你固定住模型大小,那么只要持续增加高质量数据,那么模型效果肯定会持续提升,这个其实从2021年发表的Chinchilla law的论文就能得到这个结论。一般模型大小乘以20,就是Chinchilla law对应的最优训练数据量,比如对于8B模型,160B训练数据对应最优Scaling law。但是,我们不能机械地理解和应用Scaling law,从Chinchilla的论文实验数据可以看出,还有另外两条路提升模型性能,尽管它不是训练最优的。一个是固定住模型大小,持续增加训练数据,模型效果会持续变好,只要你有源源不断的新数据能加进来,那么小模型就能效果持续变好;另外一个是固定住训练数据量,那么你持续放大模型参数规模,同样的,模型效果也会越来愈好。如果我们把按指定比例同时增加训练数据和模型容量叫做“Optimal Chinchilla Law”,那么这两种做法可以被称为“Sub-optimal Chinchilla Law”。
-从上面可以看出,到2025年下半年之前,我们仍然可以走目前的Scaling law的路子,一般是同时增加数据和模型规模,来快速提升模型能力。到2025年下半年,很可能到时候已经无法找到大量新数据了,那么那时候,需要“合成数据”技术有突破,能靠机器自己产生新的训练数据,否则的话……那么到时候是否模型能力就无法提升了呢?也不是,那时候就只能在不增加训练数据的情况下,只增加模型规模,原则上模型能力是能继续提升的。只是提升的效率不如目前这种同时增加训练数据和模型规模那么快而已。
二.开源与闭源
-Meta是目前大模型开源届的中流砥柱,目前判断LLAMA-3系列都会开源,包括400B的模型也会在几个月后开源出来,这意味着我们会拥有效果与GPT 4基本持平的开源大语言模型,这对于很多复杂应用来说是个很好的消息(当然400B规模的模型太大,这是个实际问题)。
-如果Meta 的LLAMA-3系列全面开源,甚至之后的LLAMA-4也持续开源(目前看这个可能性是较大的,Meta的开源决心比较大,相比而言,谷歌还是决心不太够,商业利益考虑更多些),那么国内应该重视研究如何将LLAMA系列更好中文化的相关技术(因为一些原因,LLAMA专门把中文能力弱化了,但是这其实不是大问题。做好的中文模型并不一定需要特别大量的中文数据,比如GPT 4),包括扩充中文Token词典、用中文训练数据低成本地进行继续预训练、有害信息的去除以通过审查等。这样随着Meta未来不断发布能力更强的新版本模型,国内有可能出现如此局面:通过LLAMA中文化得到的超强大模型(包括语言模型及多模态模型),出现的时间节点甚至快于绝大多数国内发布的最强大模型,包括闭源及开源大模型。
-如果几个月后市面上出现GPT 4级别(“中文化改造得较好+模型压缩比较成功”的LLAMA-3 400B模型)的开源文本及多模态模型,那么压力会给到国内大模型开发厂商,无论是开源还是闭源。 不排除国内之后会出现要求封杀LLAMA的声音,封杀原因其实很好找,还是希望不要走到这种局面。
-目前从模型能力而言,整体来说开源阵营确实是弱于闭源阵营的,这是事实,但是从最近一年半的技术发展来看,开源模型(包括国外和国内的模型)和最好闭源模型的差距是在逐步缩小的,而不是越来越拉大的,这也是事实,很多数据可以说明这一点。
- 那么什么因素会严重影响开源和闭源模型的能力差异呢?我觉得模型能力增长曲线的平滑或陡峭程度比较重要。如果模型能力增长曲线越陡峭(单位时间内,模型各方面能力的增长数量,越快就类似物体运动的“加速度”越大),则意味着短时间内需要投入越大的计算资源,这种情况下闭源模型相对开源模型是有优势的,主要是资源优势导致的模型效果优势。反过来,如果模型能力增长曲线越平缓,则意味着开源和闭源模型的差异会越小,追赶速度也越快。这种由模型能力增长曲线陡峭程度决定的开源闭源模型的能力差异,我们可以称之为模型能力的“加速度差”。
-让我们往后多看几年,之后开源和闭源模型的能力是逐步缩小还是逐步增大?这取决于我们在“合成数据”方面的技术进展。如果“合成数据”技术在未来两年能获得突破,则两者差距是有可能拉大的,如果不能突破,则开源和闭源模型能力会相当。所以,“合成数据”是未来两年大语言模型最关键的决定性的技术,很可能没有之一。
三.合成数据
-总体而言,“合成数据”是个新兴研究方向,还很不成熟,目前尚未能看到能主导未来技术方向的主流方法,探索性和不确定性比较强。目前能看到的“合成数据”应用的最好的产品应该是DALLE-3,以及Sora,就是里面的图像和视频Re-caption模型,本质上这就是机器产生的“合成数据”。
-“合成数据”目前应该投入大量资源来做,这是未雨绸缪,也能形成核心竞争力。到了明年下半年,可能用来训练大语言模型的高质量新数据就没有了,靠线性新增数据支持指数速度发展的模型能力是不够的。如果“合成数据”在未来两年不能取得突破性进展,大模型发展速度会骤然下降,无法维持目前这种高速发展的局面。目前AIGC高速发展本质上还是吃的数据红利,如果GPT 5达不到AGI,同时合成数据也没有技术突破,那么大模型能否通向AGI就存在很大疑问。
-寄希望于多模态数据来大幅增强大模型的关键能力,比如逻辑推理能力,目前看只是很多人的愿望,目前并无明确的数据或实验能支持这一点。我个人认为这条路走不通。所以不应该把进一步提升AGI能力的希望寄托在多模态数据上。
-未来如何,取决于我们在“合成数据”上的进展,有两种不同的未来图景。一种是长时间内合成数据无法大规模实用化。如果这样,未来会出现如下现象:大模型能力基本到顶,各种质疑目前AGI技术路线的声音会逐步放大,而开源和闭源模型能力会持平,这对于很多闭源模型公司来说是灭顶之灾(尽管我们可以继续通过放大模型规模来进一步提升模型能力,但是模型能力增长曲线会比现在平缓很多,即模型能力“加速度差”减小,开源模型较为容易赶上闭源模型)。另外一种是在未来两年内要么我们在“合成数据”方面取得大进展,要么即使没有新数据,但是我们有突破性的技术,可以在数据量不变情况下,极大提升大模型的数据利用效率(相同数据量,相同模型大小,如果模型效果更好,则说明模型的数据利用率更高。当然这块目前也未看到可以主导未来发展的主流技术)。那么,我们会继续按照Scaling law往后发展,就是继续增加新数据,推大模型规模,来持续增强模型能力。如果这样,AGI是可能通过大模型技术路线达到的,而在这种情况下,意味着需要相比目前数以十倍、百倍的资源投入,基本是个天文数字了,而在如此巨量投入的情况下,Meta等公司是否还会这样大力度支持开源就是有疑问的,此时开源模型是有可能越来越落后于闭源模型的。


Highlight:
- 美中不足的是 LLaMa3 不会有 MoE 架构的模型,包括 400B+ 版本也是 Dense。
- 其次 LLaMa3 也没有发布多模态版本的模型,甚至是 Early Access 的效果展示
- 8B 模型吃 15T token 仍然有效,比 Mistral-7B 的 8T token 又翻了一倍 (最开始 Chinchilla 的 Scaling Laws 预测的 Compute-Optimal 是 8B model-0.2T token, 70B model-1.4T token)。
- 用 LLaMa2 模型做 LLaMa3 的数据质量分类器很有指导意义。
- LLaMa3 70B 应该是 70B 模型以内最强的模型, GPT-3.5+ 水平。
- 如果 LLaMa3 400B+ 训练完成后也开源,则会是接近 GPT-4-Turbo 水平的模型。
4.19 10:00 更新
为什么要强调 MoE 呢?
- OpenAI 的 GPT-3.5-Turbo、GPT-4、GPT-4-Turbo 均为 MoE 模型。 如果 Dense 是更优的架构的话,OpenAI 没理由不用。
- GPT-4-Turbo 的模型推理成本(激活参数量)预估是 120B 左右,所有性能都全面领先 LLaMa3-400B+,GPT-4-Turbo 的推理成本比 LLaMa3-400B+ 便宜 3-4 倍。如果是后端应用的话,基于 400B+ 模型做微调推理,不如直接调用 GPT-4-Turbo 成本更低。
除了 OpenAI, Claude3、 Mistral-Medium/Large、 Gemini 1.5 、Grok1.5 也全部都是 MoE。 且 Mistral、Google 都是在搞定 Dense 之后又转到 MoE 上了。 如果大家都是理性决策的话, MoE 相比于 Dense 有技术架构上的优势是一个共识。
因此推测: 有可能 LLaMa4 就都是 MoE 的模型了。
Chinchilla 的 Compute-Optimal 相关问题:
Chinchilla 的 Compute-Optimal 是给定 FLOPs 以后,算一个最优的 Model Size 和 Data Size。
LLaMa3-8B 的训练 FLOPs 开销是: 6ND = 6 x 8B x 15T = 7.2 x 10^23 FLOPs。这个 FLOPs 下 Chinchilla Compute-Optimal 给出来的最优解大概是 75B 模型训练 1.6T token。

从 Chinchilla 75B Model + 1.6T tokens -> LLaMa3 8B Model 15T tokens,相同 FLOPs 下 模型大小和数据量的误差有 10 倍。
当然也可以质疑说, Compute-Optimal 只是一种最优化训练成本的选择,而实际推理成本更重要,所以在训练成本给定的情况下,减小模型大小,增加数据量显然对推理更友好。 但核心是这个 模型减小、数据增加的程度。 从原始论文的实验中看, 6B -> 3B 模型大小差 1 倍,还是可以说在一个相对优的 loss 区间上, 但如果差 10 倍,则模型效果至少弱一到两个档次。
在 Compute-Optimal 之后,同一个模型继续喂更多的数据,边际效益是递减的,因此肯定有一个阶段是模型 overtrained 再喂数据能力也不涨了。只是这个阶段比预计的要更晚。至少 LLaMa3-8B 证实了这点。
如果从推理成本角度来说,为什么 LLaMa3 不训练一个 1B 模型 15T token 的版本呢?岂不是推理成本更低很多倍? 一个猜测是 1B 模型吃不下这么多数据,可能到 2T token 以后就没变化了。
LLaMa3 不包含 MoE 和 多模态能力
LLaMa3-8B 和 LLaMa3-70B 都是 Dense 模型,从 LLaMa3-400B+ 的训练成本上来看,也不会是一个 MoE 的架构,MoE 的 400B 模型训练成本在 100B 左右,1.6W 张 H100 40% MFU 不会训练这么久还没训练完。
另外,LLaMa3 的博客中只介绍了 DP、TP、PP 传统的 3-D 并行,不包含 EP(Expert Parallel 的介绍)


LLaMa3 的技术博客放出来的指标都是纯文本的 benchmark,多模态属于后续工作。 GPT-4 的技术报告中就包含了 Vision 的惊艳展示,而实际 GPT-4V 发布间隔了半年。 因此推断 LLaMa3 的 Vison 版本可能要比半年还要久。
LLaMa3 证明了小模型仍可以吃掉更多的数据
无论是 8B 还是 70B 模型,训练 15T tokens 均可以看到 log 线性的提升,这与 Chinchilla 预测的 70B 1.4T tokens 差别甚远。固定大小的模型能力的上限仍未可知, 8B 模型是否可以再加更多的数据以获得进一步提升? 15T 的数据已经接近训练 GPT-4 的数据量。 限制进一步探索的应该是暂时无法获取更多同等质量的优质数据了。


LLaMa3 的数据构建
除了很精细的数据清洗规则以外, LLaMa3 还是用 LLaMa2 作为文本数据的质量分类器,这种数据清洗的方式值得所有团队学习和实践。 在人工绝对无法看完超过 1T tokens 的前提下,用大模型来检查数据质量是非常有效的。


当然也需要付出巨量的数据处理成本, LLaMa2-70B 的推理成本大概是 $1/1M tokens,15T 的 tokens 将花费 1500w 美元。
LLaMa3 几乎摸到了 70B 模型的上限
LLaMa3-70B 是一个 GPT-3.5+ 的模型,确实干掉了一众闭源模型,包括: Claude3-Sonnet、 Mistral-Medium、GPT-3.5-Turbo:
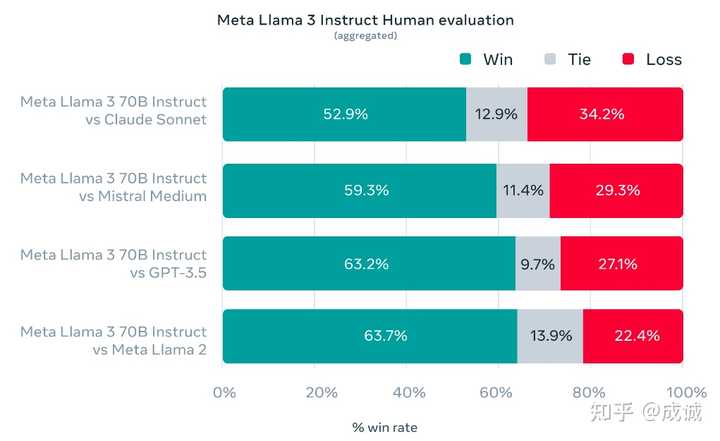

不过 Meta 并没有放出来 LLaMa3-70B 和 GPT-4-Turbo、Mistral-Large、Claude3-Opus 的比较,70B 相较于巨头的最强模型肯定仍有不小差距。
LLaMa3-400B+ 接近 GPT-4 的 (开源?)模型
400B+ 的版本仍在训练中,从目前 checkpoint 的评测结果来看已经非常强了,该模型的训练成本也会达到一亿美元。 暂不清楚 Meta 是否会开源 LLaMa3 的超大杯。 不过很有可能会开源,届时其他公司也会有接近 GPT-4 水平的开源模型开发后续的应用。
如果今年 7 月份 400B+ 的版本真的开源了,则对国内大模型应用公司来说则是重大利好。 而对 OpenAI、Anthropic、Mistral、Google 而言都不是一个好消息。