LLM学习记录(五)--超简单的RoPE理解方式

尝试理解了一下苏神的RoPE,主打一个土味解读,记录思考的过程。
1. 为什么要加位置编码?
由于attention的设计,网络感知不到token的位置关系,也就是说只要是同一批token,任何顺序输入网络,输出结果都是一样的。但是在自然语言中文本的顺序是很重要的。
于是需要引入位置关系,让模型能够感知到token的顺序。
2. 位置编码的设计
2.1 直接编号
为了表示每个token的顺序,需要给位置一个表示方法 f(x) ,最简单的就是给每个token直接进行编号。
第0个token,第1个token,,,,第n个token,相当于:
f(x) = x
这种表示方式的性质满足
f(m-n) = f(m) - f(n)
但是attention计算时是 q向量和k向量做乘法,而不是做减法,性质再好也没法直接用。
2.2 乘法表示
假如有两个token,第m个token和第n个token。
因为attention的公式,位置编码考虑乘法的情况,看看有没有可能设计一个函数,使得:
f(m-n) = f(m)*f(n)
选择几个边界情况就可以发现,只有下面2种情况可以满足条件:
f(x) = 1
f(x) = 0
但是把位置信息编码成一个常数,对我们完全没意义。
于是,退而求其次,我们对性质的要求放宽一点,希望:
h(m-n) = f(m)*f(n)
但是我们遇到了一个重要的问题,就是对称性问题,乘法是满足交换律的。
h(m-n) = f(m) * f(n) = f(n) * f(m) = h(n-m)
如果第m个token和第n个token的顺序对调,结果还一样,这是我们完全无法接受的。
于是把token位置映射到一个实数,且在乘法时有我们所期望的性质,是不可能实现的。
2.3 向量表示
下一步试图把位置信息编码成向量,然而向量内积同样满足交换律的。
所以同样会遇到对称性问题,
h(m-n) = h(n-m)
我们可以不期望他是一个奇函数,但是至少不能是个偶函数。
也就是说第m个token与第n个token的位置关系,和第n个token与第m个token的位置关系一定要有区分度。
但是无论将位置编码成1维的向量还是d维的向量,都因为交换律的影响,无法区分 <m,n>和<n,m>
所以我们还是需要重新探索。
2.4 矩阵表示
尽管从1维拓展到d维向量都无法支持我们很好的编码位置,但是不代表矩阵不可以。
矩阵乘法通常不满足交换律,也就是:
R_{m}^{T} * R_{n} \ne R_{n}^{T} * R_{m}
终于,我们可以设计一个第m位的token的位置编码矩阵R,满足:
R_{m}^T * R_{n} = R_{m-n}
这里从一个2*2的矩阵入手,我们可以令m=0
R_{0}^T * R_{n} = R_{-n}
实际上,我们可以在设计性质时,加上一个负号,让整个过程更好推导。
R_{m}^T * R_{n} =R_{n-m}
R_{0}^T * R_{n} = R_{n}
R_{0} = \left( \begin{array}{1} 1 & 0 \\ 0 & 1 \end{array} \right)
另外可以推出,R矩阵的性质:
R = \left( \begin{array}{cc} a11 & a12 \\ -a12 & a22 \\ \end{array} \right)
3. RoPE的二维情形
苏神提出的RoPE的推导过程,可以参考原博客。
设计(推导?)出符合我们要求的2*2矩阵为:
\left( \begin{array}{cc} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{array} \right)
对应复数领域的“旋转式位置编码”
可以简单计算验证一下:
R_{m}^{T} * R_{n} = \left [ \begin{matrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \\ \end{matrix} \right ] ^{T} * \left [ \begin{matrix} \cos n\theta & -\sin n\theta \\ \sin n\theta & \cos n\theta \\ \end{matrix} \right ] = \left [ \begin{matrix} \cos n\theta\cos m\theta + \sin n\theta\sin m\theta & \sin m\theta\cos n\theta -\sin n\theta\cos m\theta \\ \sin n\theta\cos m\theta -\sin m\theta\cos n\theta & \cos n\theta\cos m\theta + \sin n\theta\sin m\theta \\ \end{matrix} \right ] = \left [ \begin{matrix} \cos (n-m)\theta & -\sin(n-m)\theta \\ \sin (n-m)\theta & \cos (n-m)\theta \\ \end{matrix} \right ] = R_{n-m}
另外,我们发现m和n是非对称的
R_{m-n} = \left [ \begin{matrix} \cos (m-n)\theta & -\sin(m-n)\theta \\ \sin (m-n)\theta & \cos (m-n)\theta \\ \end{matrix} \right ] \ne \left [ \begin{matrix} \cos (m-n)\theta & \sin(m-n)\theta \\ -\sin (m-n)\theta & \cos (m-n)\theta \\ \end{matrix} \right ] = R_{n-m}
4. 拓展到d维
4.1 公式说明
参考苏神的另一篇博客
我们上面得到了满足要求的2*2矩阵,但是attention的q向量是d维,
需要对于d//2组的位置编码进行设计。
让我们先忘掉上面的矩阵,如何把第m个位置表示为一个d//2维的向量M,让m在增加时,向量M的变化很均匀。
可以进行设计,把位置变成一个β进制的编码,比如104的10进制表示为(1,0,4),而105的10进制表示为(1,0,5)只变化了1,还比较均匀。
这里的β等于 10000^{2/d}
4.2 举个例子
比如d=8,也就是我们要把输入向量转换成一个4维的向量,采用10进制。
某个token的位置是第9999位的话,他的向量表示是(9,9,9,9)
按照transformers的计算公式的思路,会在每个位置做除法,也就是说按位除(1,10,100,1000),每个位置上的结果(9999,999.9,99.99,9.99)。
这个(9,9,9,9)与(9999,999.9,99.99,9.99)差距太大了,如果只保留个位数及以下的部分(9,9.9,9.99,9.99)才是我们可以接受的范畴,也就是说需要进行一个取余数的操作。
考虑到cos和sin的周期性,我们可以通过引入三角函数来近似取余数。
但是引入周期函数又会带来新的问题,如果函数周期是10,那么在0和1的表示很接近的同时,9和0也会很接近。因为0和10的表示一致,而9和10很接近。
也就是说(0,0,0,0)和(9,9,9,9)可能很接近,但实际上,两者一个是序列开头,一个是序列结尾,我们期望他们相距很远。
为了避免这一问题,比如BERT限制长度512,但是我们的base不能设置为512,而是要远大于512。
所以transformer会使用一个在当时超长的base:10000,在那个年代10k长度已经是不可能达到的长度了。
当然,这个数看起来取的如此随意,也说侧面证明了模型对β进制的β其实不大敏感?更说明NTK-Aware Scaled RoPE在外推性上的成功是合理的。
4.3 RoPE矩阵
最终,RoPE矩阵可以拆解为2步生成
- 把位置m,转成β进制,构成一个d//2维的向量。
- 每维的数值,映射到一个2*2的矩阵上。
于是得到:


4.4 实现优化
参考苏神的博客,因为RoPE矩阵的稀疏性,可以用等价的实现。
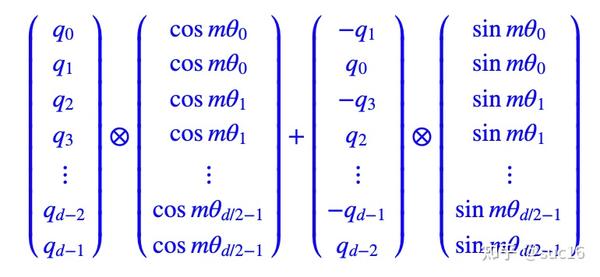

所以计算的核心变成了计算每个位置的cos和sin值。
5. ChatGLM-6B里的实现
据说llama的实现更接近原版,但是这里还是引用chatglm-6b的实现,更符合本文。(chatglm2-6b更换了实现方式)
class RotaryEmbedding(torch.nn.Module):
def __init__(self, dim, base=10000, precision=torch.half, learnable=False):
super().__init__()
inv_freq = 1. / (base ** (torch.arange(0, dim, 2).float() / dim))
inv_freq = inv_freq.half()inv_freq代表β进制相关的向量,其实用这个向量就能算出β进制表示。
(1, \beta^{-1},\beta^{-2},...,\beta^{-d//2+1})
t = torch.arange(seq_len, device=x.device, dtype=self.inv_freq.dtype)
freqs = torch.einsum('i,j->ij', t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1).to(x.device)
if self.precision == torch.bfloat16:
emb = emb.float()
# [sx, 1 (b * np), hn]
cos_cached = emb.cos()[:, None, :]
sin_cached = emb.sin()[:, None, :]freqs代表着所有可能位置长度的β进制表示,比如seq_len长度限制1000,进行10进制表示。
\left[ \begin{array}{ccc} 0&0&0\\ 1&0&0\\ 2&0&0\\ ...\\ 8&9&9\\ 9&9&9 \end{array} \right]
再计算矩阵中每个位置的cos和sin值,实际上RoPE矩阵的关键值都包含在cos_cached和sin_cached中了。
也就是获得了图2需要的向量。
position_ids = position_ids.transpose(0, 1)
cos, sin = self.rotary_emb(value_layer, seq_len=position_ids.max() + 1)
# [seq_len, batch, num_attention_heads, hidden_size_per_attention_head]
query_layer, key_layer = apply_rotary_pos_emb_index(query_layer, key_layer, cos, sin, position_ids) 最后在计算attention时,参考图2的公式进行实现。对于与sin_cached的部分进行rotate_half,得到:
\left[ \begin{array}{c} q1 \\ -q0 \\ q3 \\ -q2 \\ ... \end{array} \right]
def rotate_half(x):
x1, x2 = x[..., :x.shape[-1] // 2], x[..., x.shape[-1] // 2:]
return torch.cat((-x2, x1), dim=x1.ndim - 1) # dim=-1 triggers a bug in earlier torch versions
@torch.jit.script
def apply_rotary_pos_emb_index(q, k, cos, sin, position_id):
# position_id: [sq, b], q, k: [sq, b, np, hn], cos: [sq, 1, hn] -> [sq, b, 1, hn]
cos, sin = F.embedding(position_id, cos.squeeze(1)).unsqueeze(2), \
F.embedding(position_id, sin.squeeze(1)).unsqueeze(2)
q, k = (q * cos) + (rotate_half(q) * sin), (k * cos) + (rotate_half(k) * sin)
return q, k最终就成功将RoPE应用到了transformer中。
