深度学习的理论解释有哪些?
13 个回答

深度学习现在据我所知理论解释还是比较少的,但也有各种不同的角度的解释,有兴趣可以看看:
比如之前看过,《看穿机器学习(W-GAN模型)的黑箱》,顾险峰博士想用最优传输理论来解释W-GAN模型,写的挺好的,当然,也可以到他的公众号看看顾博士其他关于机器学习黑箱的解释文章:比如:看穿机器学习的黑箱....
还有就是之前也看过用Deep Learning and Quantum Entanglement: Fundamental Connections with Implications to Network Design来解释深度学习的, @机器之心 之前对这篇文章有报道,可以看看新研究发现深度学习和量子物理的共同点,或可用物理学打开深度学习黑箱
还有就是New Theory Cracks Open the Black Box of Deep Learning这篇博文,作者希望通过Information Bottleneck理论来尝试解释深度学习,可以看看。
奥,对了,这篇好像也有挺多中文解释的比如“信息瓶颈”理论揭示深度学习本质,Hinton说他要看1万遍
最后就是题主说的The Holographic Principle: Why Deep Learning Works这篇啦,全息理论解释深度学习。
总之,现在来说,理论还在发展,上面说的看起来也有些复杂.....有些看得我稀里糊涂......黑箱还是黑箱,但相信之后,大佬们会给这个黑箱一个明确,精美又易懂的解释!


标题:A Generalized Neural Tangent Kernel Analysis for Two-layer Neural Networks
作者:Zixiang Chen and Yuan Cao and Quanquan Gu and Tong Zhang
前言
根据我们上一篇的介绍,mean field (feature learning) regime 用的是 1/m ,其中m是网络的宽度,而neural tangent kernel (lazy training) regime用的是 1/m^{1/2} 。两个框架各有优缺点:
(1)Mean field 框架 很难刻画网络的泛化结果
(2)NTK 框架 很难分析weight decay以及有很大噪声的情况
一个自然的问题是,有没有一个统一的理论分析框架来统一这两个无限宽分析呢?
答案是有的, 我们可以加一个scaling factor, \alpha : 如果 \alpha=1 ,那么就是mean field regime;如果 \alpha=m^{½} 那么就是NTK regime。
今天我们要介绍的文章就采取了这个方法,另外有一篇更偏向于数值模拟的文章也用了相似的思想,信息如下:
Disentangling feature and lazy training in deep neural networks
Mario Geiger, Stefano Spigler, Arthur Jacot, Matthieu Wyart
https://arxiv.org/abs/1906.08034
设定
我们考虑两层(one hidden layer)神经网络:
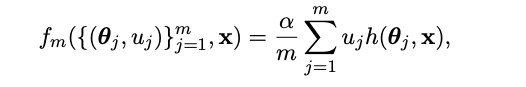

其中m是网络的宽度
我们考虑用平方损失和权重衰减正则化训练神经网络,那么目标函数就可以写成
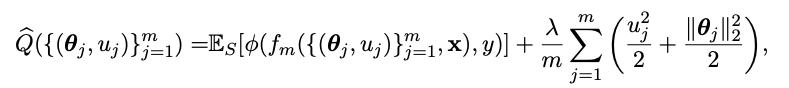

接下来我们考虑noisy gradient descent算饭来优化上面的目标函数,算法如下


那么无限宽网络参数的演化可以用PDE来描述:
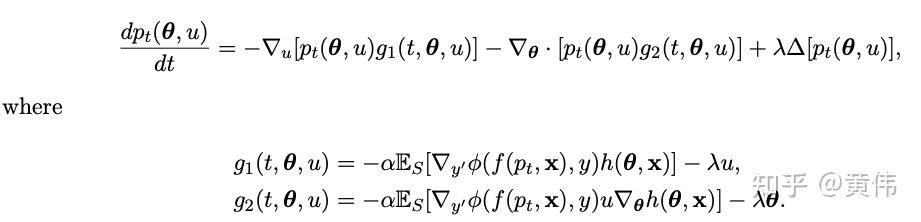

上面的PDE方程同时也是在优化另外一个目标函数(能量方程)
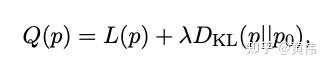
其中,
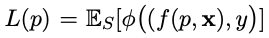
是squared error loss,
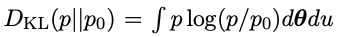
是KL-divergence。
主要结果
根据PDE方程,我们可以获得关于网络的收敛保证:
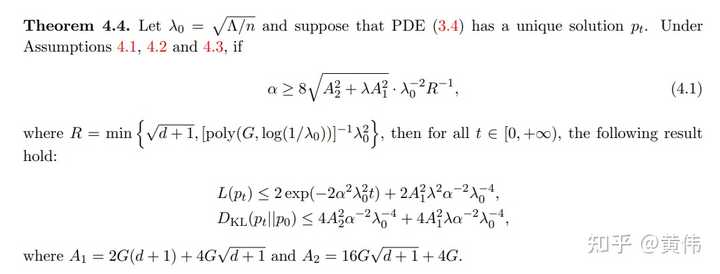

其中,收敛速率依然是指数式的,而且由NTK的最小特征值来主导,这和NTK的文献结果一致。同时,KL一项会随着 \alpha 的增大而减小,这也和NTK文献中认为权重的变化是有限的一致。
最后介绍泛化的结果:


这里的 1/\sqrt{n} 和标准的bound是一致的。而 \chi^2 -divergence是一个比较新的点。
总结
我们这次介绍了一个尝试将NTK和mean field统一的文章,它启发我们一方需要精心设计面模型,另一方面对于NTK在mean field的框架中是如何起作用的也是一个值得深入探究的点。