行人重识别(re-ID)与跟踪(tracking)有什么区别?
12 个回答

从任务的角度来看,两者最主要的区别如下:
- 行人再识别:给定一张切好块的行人图像 (probe image, 即图像大部分内容只包含这个人), 从一大堆切好块的图像 (gallery images) 中找到跟probe image中同一身份的人的图像。这些图像通常是由不同摄像头拍摄的不连续帧。
- 行人跟踪:给定一张切好块的行人图像 (probe image), 从一段全景视频 (panorama track, 视野中只有一小部分是这个行人) 中找到 probe 所在的位置。这段全景视频是由单个摄像头拍摄的连续帧。
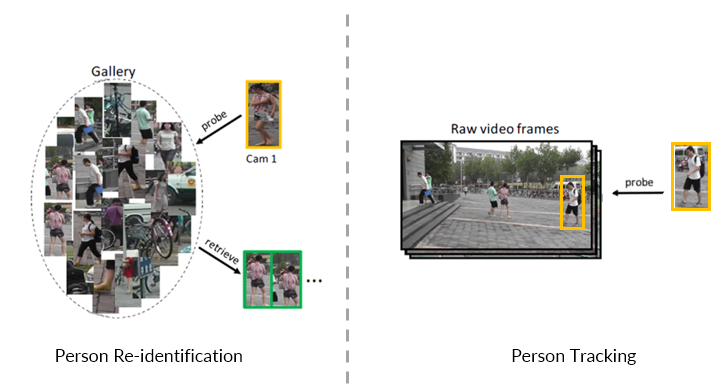
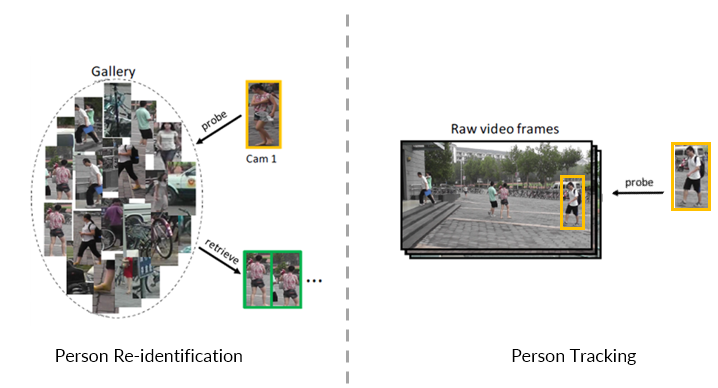
在视频监控领域,我们的最终目标是要做到多目标跨摄像头跟踪 (Multi-target Multi-camera Tracking, 简称MTMC Tracking). 而行人再识别和行人跟踪都是为了达到这个最终目标的子任务。


简单画了个图~ 如上,Re-ID 在图中的第三象限,处理的是静态图像,并且是已经切好块的patch.
然而在实际应用中,摄像头拍摄到的都是全景图像,于是就需要加入行人检测 (Pedestrian Detection) 技术,从全景图像中找到行人的位置,再将包含行人的图像块切出来。此时就形成了位于第二象限的新任务:行人搜索 (Person Search).
行人搜索处理的对象依然是静态图像,在实际应用中摄像头拍摄到的通常是动态的视频。如果能将时序信息 (Temporal Information) 利用起来,加上行人跟踪 (Tracking) 技术,特别是 Tracking by Detection 技术,就能大致实现位于第一象限的最终目标 MTMC Tracking.
另一方面,在 Re-ID 的基础上,如果不考虑行人检测,直接将时序信息利用起来,就形成了位于第四象限的任务:基于视频的行人再识别 (Video-based Re-ID), 有时也被称作 Multi-shot Re-ID. 同样地,将这个任务扩展到全景视频上也能够达到最终目标。
目前大量的工作都集中在第三象限的 Re-ID 上,相比之下 Person Search 和 Video-based Re-ID 的工作就少了很多。直接解决 MTMC Tracking 的工作更是少之又少。各位同僚们一起努力吧~

高赞回答写的很好。
- 重识别关注单个bounding box直接的匹配
- 跟踪 (multi-target multi-camera tracking)则更加复杂:需要现在视频的每帧中,找到目标可能出现的位置(detection),之后估计目标之间的相似度(similarity estimation),最后结合数据(data association)。这是一套标准的tracking-by-detection流程。
在跟踪问题中,相似度估计是一个重要的部分。但是,直接利用bounding box的外观信息,使用重识别特征,计算相似度,并不是最优的方式。


由于目标移动轨迹的连续性,跟踪系统一般将匹配范围限制在局部邻域内;而重识别系统一般无法得到目标轨迹,因此它的匹配范围也一般是全局的。
- 局部邻域:对单相机跟踪,指相同相机内的相邻帧(上图第二行);不考虑不同相机内的样本(红叉)。对多相机跟踪,指相邻的相机(第三行);不考虑距离太远,目标不可能连续出现的相机(红叉)。
- 全局:对于重识别问题,给定一个query,系统需要查找所有相机内的所有样本(第一行)。
正因如此,在相似度估计这个关键部分,出现了局部vs全局的失配。这会对系统整体性能有很大影响。如下图所示,全局度量(global metric)一般利用模型的全部性能照顾各类外观变化。在局部邻域内,样本直接的区分一般较小(同相机连续帧/相邻相机之间,可能出现的外观变化有限;远远小于全部相机间的各种组合),全局模型由于能力有限,却不能有效区分相似样本(见下图A)。
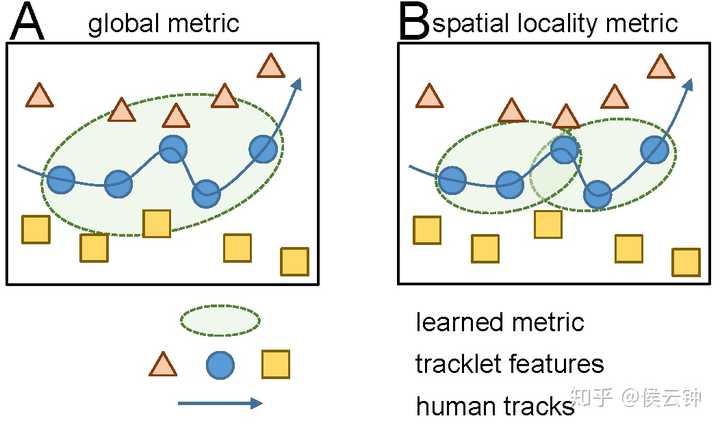

在最新的研究中,我们重点讨论了这个问题,并提出了一套针对局部邻域内外观特征的度量。欢迎观光、吐槽、提问!谢谢!