如何使用R语言做DID模型?
4 个回答

1. 简介
双重差分模型 (Difference in Difference,DID) 是政策评估的常用方法。其中,经典的 DID 方法通常拥有两期 (处理前和处理后) 和两组 (处理组和对照组) 数据。在具体应用中,考虑到个体和时间异质性,我们常用 DID 固定效应模型对平均处理效应 (ATE) 进行估计。
但这种经典的 DID 方法在实际应用中往往面临挑战。例如,当存在多个政策时点冲击时,DID 固定效应模型对处理效应的估计时可能会产生严重偏误。为此,本文将介绍一个基于 R 语言的 did 包来解决上述问题,以及进行平行趋势检验。
2. 理论背景
2.1 两期 DID 固定效应模型的问题
基本的两期 DID 设定模型为:
y_{i t}=\alpha+\beta\left(G_{i} \times D_{t}\right)+\gamma G_{i}+\delta D_{t}+\epsilon_{i t} \\
其中, G_{i} 为分组虚拟变量 (处理组 =1 ,控制组 =0 ), D_{t} 为分期虚拟变量 (政策实施后 =1 ,政策实施 前 =0) ,交互项 G_{i} \times D_{t} 系数 \beta 为 DID 模型重点考察的平均处理效应 (Average Treatment Effect, ATE)。 上述基本的 DID 模型本质上是一种固定效应模型,常数项 \alpha 是对照组的固定效应, \gamma 是处理组与对 照组的固定效应差异, \delta 是事件发生前后的固定效应差异, \beta 是事件固定效应 (处置效应)。 当然,如果我们有更多时间信息的面板数据,就可以通过细化组别和时期的固定效应来提高上述模 型的精度。具体地,将处理组和对照组的固定效应 (\alpha, \gamma) 细化为个体效应 \mu_{i} ,以及将事件前后的时 期固定效应 \delta 细化为每年的固定效应 \lambda_{t} ,细化后的模型则可以较好地降低估计系数的方差。 两期 DID 的固定效应模型设定如下:
y_{i t}=\alpha+\beta\left(G_{i} \times D_{t}\right)+\gamma X_{i t}+\mu_{i}+\lambda_{t}+\epsilon_{i t} \\
但两期 DID 固定效应模型估计可能会受到多期政策冲击的挑战。由于多期 DID 政策冲击时点不同因 而存在多个不同的对照组,比如后接受政策冲击的处理组可能是先接受政策冲击的对照组,故存在 一种动态的平均处理效应估计,导致估计偏误。
那么我们如何识别这种动态的平均处理效应呢?
2.2 多期 DID 平行趋势假设 DID 进行估计的前提是平行趋势假设,即处理组和对照组在政策冲击之前应具有相同的趋势。两期 DID 平行趋势假设条件为:
E\left[\Delta Y_{t}(0) \mid C=0\right]=E\left[\Delta Y_{t}(0) \mid C=1\right] \\
多期 DID 的平行趋势假设条件为: 对 g=2, \ldots, \tau, t=2, \ldots, \tau ,当 g \leq t 时,
E\left[\Delta Y_{t}(0) \mid G=g\right]=E\left[\Delta Y_{t}(0) \mid C=1\right] \\
考虑控制变量后的多期 DID 平行趋势假设条件为: 对 g=2, \ldots, \tau , t=2, \ldots, \tau \mathrm{~ , 当 ~} g \leq t 时,
E\left[\Delta Y_{t}(0) \mid X, G=g\right]=E\left[\Delta Y_{t}(0) \mid X, C=1\right] \\
在上式中, Y_{i t}(0) 表示末接受处理的个体 i 在 t 时期的潜在结果; Y_{i t}(g) 表示个体 i 在 t 时期的潜 在结果,该个体在 g 时期接受政策冲击; G_{i} 表示个体 i 接受处理的时间段; C_{i} 表示个体是否为对 照组 (对照组随 t 变化,为简单起见,这里将从末接受过处理的个体作为对照组); Y_{i t} 表示个体 i 在 t 时期观察到的结果; X_{i} 表示参与回归的控制变量。
2.3 处理效应估计 ATE (Average Treatment Effects) =E\left[Y_{i t}(1)-Y_{i t}(0)\right] 指的是从样本中随机抽取某个体的期望处理 效应,即平均处理效应; ATT (Average Treatment Effects on the Treated) = E\left[Y_{i t}(1)-Y_{i t}(0) \mid D_{i}=1\right] 仅考虑处理组的平均处理效应,即处理组处理效应。 在随机分组的条件下 D_{i} 独立于 \left[Y_{i t}(1), Y_{i t}(0)\right] ,此时 ATE = ATT。由于 ATE 既包括了处理组也包 括了对照组个体,很多学者批评其定义过于宽泛。而对于政策制定者来说,ATT 可能是更加重要的 考虑因素,因为他直接衡量了处理组中个体接受政策冲击前后的收益。 多期 DID 下的 ATT 的计算公式为:
A T T(g, t)=E\left[Y_{t}(g)-Y_{t}(0) \mid G=g\right] \\
其中,当 g=2, t=2 时, A T T(g=2, t=2) 表示两期 DID 处理组的平均处理效应。此外,考 虑多期 DID 情况下, \operatorname{ATT}(g=2, t=3) 表示个体在第 2 期接受处理在 t=3 时的处理效应; A T T(g=3, t=3) 表示个体在第 3 期接受处理在 t=3 时的处理效应。 下面我们表示出平均处理效应 (ATE) 的估计公式:
\theta_{s}(g)=\frac{1}{\tau-g+1} \sum_{t=2}^{\tau} 1[g \leq t] A T T(g, t) \\
上式表示每组分别接受政策冲击后的 ATT;
\theta_{s}^{o}(g)=\sum_{g=2}^{\tau} \theta_{s}(g) P(G=g) \\
上式表示所有处理组个体在参与处理后的总体处理效应;
\theta_{D}(e)=\sum_{g=2}^{\tau} 1[g+e \leq \tau] A T T(g, g+e) P(G=g \mid G+e \leq \tau) \\
上式中的 e 表示处理组已经暴露在政策冲击下的时间, \theta_{D}(e) 可以看作一种动态效应估计指标。
3. R 语言实操
3.1 命令简介
did 是 Callaway 和 Sant’Anna 创建的用于多期 DID 处理效应估计的 R 命令包,其主要操作命令包括:


3.2 \mathrm{R} 程序实操 下面我们用 R 语言来演示 did 包的使用。数据来自 Callaway 和 Sant'Anna (2020),研究问题是 各州提高最低工资对县级青少年就业率影响。 样例数据集包含 2003 年至 2007 年 500 个县级青少年就业率的数据,其中一些州在 2004 年首次接 受治疗,也有一些在 2006 年或 2007 年接受治疗。 主要变量 l e m p 是县级青少年就业率的对数值, first. treat 是某个州首次提高最低工资的时间, 可能是 2004 年、2006 年或 2007 年;year 是年份;countryreal 是每个县的 ID。 首先,在 \mathrm{R} 中安装 did 包。
writeLines('PATH="${RTOOLS40_HOME}\\usr\\bin;${PATH}"', con = "~/.Renviron") #创建路径配置文件.Renviron
Sys.which("make") #测试配置路径是否成功
options(repos=structure(c(CRAN="https://mirrors.tuna.tsinghua.edu.cn/CRAN/"))) #设置镜像
install.packages("did") #从CRAN上下载did包
library(did) #调用did包
data(mpdta) #调入样例数据
did 包使用 att_ gt 命令估计处理组平均处理效应 (ATT)。
out <- att_gt(yname = "lemp",
gname = "first.treat",
idname = "countyreal",
tname = "year",
xformla = ~1,
data = mpdta,
est_method = "reg"
)
summary(out)
#> Call:
#> att_gt(yname = "lemp", tname = "year", idname = "countyreal",
#> gname = "first.treat", xformla = ~1, data = mpdta, est_method = "reg")
#>
#> Group-Time Average Treatment Effects:
#> Group Time ATT(g,t) Std. Error [95% Simult. Conf. Band]
#> 2004 2004 -0.0105 0.0259 -0.0796 0.0586
#> 2004 2005 -0.0704 0.0312 -0.1535 0.0127
#> 2004 2006 -0.1373 0.0375 -0.2373 -0.0372 *
#> 2004 2007 -0.1008 0.0352 -0.1947 -0.0069 *
#> 2006 2004 0.0065 0.0229 -0.0547 0.0677
#> 2006 2005 -0.0028 0.0203 -0.0568 0.0513
#> 2006 2006 -0.0046 0.0179 -0.0522 0.0430
#> 2006 2007 -0.0412 0.0210 -0.0972 0.0148
#> 2007 2004 0.0305 0.0159 -0.0118 0.0728
#> 2007 2005 -0.0027 0.0164 -0.0465 0.0410
#> 2007 2006 -0.0311 0.0183 -0.0797 0.0176
#> 2007 2007 -0.0261 0.0179 -0.0737 0.0215
#> ---
#> Signif. codes: `*' confidence band does not cover 0
#>
#> P-value for pre-test of parallel trends assumption: 0.16812
#> Control Group: Never Treated, Anticipation Periods: 0
#> Estimation Method: Outcome Regression
从上面 summary 的输出结果可以看出,该命令不仅估计出 g \leq t 的平均处理效应,也估计出了 g \geq t 的平均处理效应用以检验平行趋势假设。这里我们使用 Wlad 检验的 p 值统计量来进行平行 趋势检验。 多期 DID 的平均处理效应的图示命令如下:
ggdid(out, ylim = c(-.25,.1))
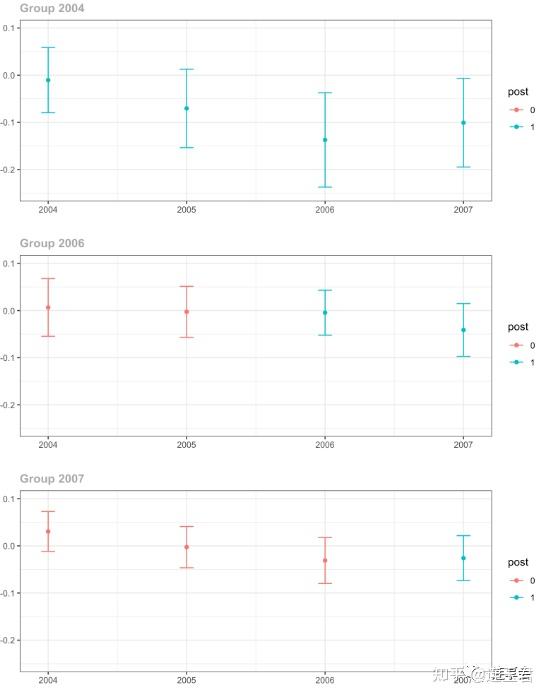

上图中的红色圆点是政策冲击前的平均治疗效果 (采用了 95% 的置信区间),可以看出红色圆点在 95% 的置信水平下趋近于 0,符合平行趋势假设。蓝色圆点表示接受政策冲击后的平均治疗效果,在本案例中表示提高最低工资水平对县级青少年就业率的影响。
es <- aggte(out, type = "dynamic")
summary(es)
#> Call:
#> aggte(MP = out, type = "dynamic")
#>
#> Overall ATT:
#> ATT Std. Error [95% Conf. Int.]
#> -0.0772 0.0205 -0.1175 -0.037 *
#>
#> Dynamic Effects:
#> Event time Estimate Std. Error [95% Simult. Conf. Band]
#> -3 0.0305 0.0153 -0.0102 0.0712
#> -2 -0.0006 0.0132 -0.0356 0.0345
#> -1 -0.0245 0.0145 -0.0630 0.0141
#> 0 -0.0199 0.0120 -0.0518 0.0120
#> 1 -0.0510 0.0175 -0.0977 -0.0042 *
#> 2 -0.1373 0.0396 -0.2426 -0.0319 *
#> 3 -0.1008 0.0346 -0.1929 -0.0087 *
#> ---
#> Signif. codes: `*' confidence band does not cover 0
#>
#> Control Group: Never Treated, Anticipation Periods: 0
#> Estimation Method: Outcome Regression
did 包允许使用 aggte 估计动态处理效应,命令如下:
es <- aggte(out, type = "dynamic")
summary(es)
#> Call:
#> aggte(MP = out, type = "dynamic")
#>
#> Overall ATT:
#> ATT Std. Error [95% Conf. Int.]
#> -0.0772 0.0205 -0.1175 -0.037 *
#>
#> Dynamic Effects:
#> Event time Estimate Std. Error [95% Simult. Conf. Band]
#> -3 0.0305 0.0153 -0.0102 0.0712
#> -2 -0.0006 0.0132 -0.0356 0.0345
#> -1 -0.0245 0.0145 -0.0630 0.0141
#> 0 -0.0199 0.0120 -0.0518 0.0120
#> 1 -0.0510 0.0175 -0.0977 -0.0042 *
#> 2 -0.1373 0.0396 -0.2426 -0.0319 *
#> 3 -0.1008 0.0346 -0.1929 -0.0087 *
#> ---
#> Signif. codes: `*' confidence band does not cover 0
#>
#> Control Group: Never Treated, Anticipation Periods: 0
#> Estimation Method: Outcome Regression
上面 summary 的输出结果中,event time 表示个体第一次接受政策冲击时的处理效应,比如 event time=0 表示个体刚好处于政策冲击期的处理效应,event time=-1 表示个体在接受政策冲击前一年的处理效应。
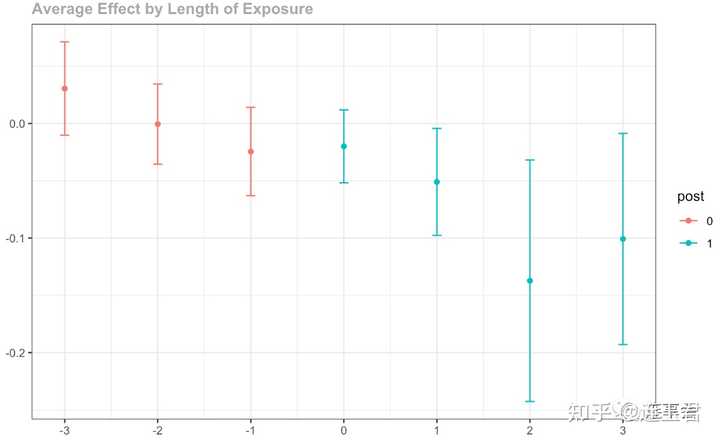

上图与多期 DID 平均处理效应的图相似,但这里将政策冲击看作一个事件,横坐标轴表示事件发生时间。通过对每段时期的处理效应进行估计,上图表示个体参与治疗的总体处理效应。
总体平均处理效应 (ATE) 的计算程序如下:
group_effects <- aggte(out, type = "group")
summary(group_effects)
#> Call:
#> aggte(MP = out, type = "group")
#>
#> Overall ATT:
#> ATT Std. Error [95% Conf. Int.]
#> -0.031 0.0125 -0.0554 -0.0066 *
#>
#> Group Effects:
#> Group Estimate Std. Error [95% Simult. Conf. Band]
#> 2004 -0.0797 0.0274 -0.1388 -0.0207 *
#> 2006 -0.0229 0.0165 -0.0585 0.0127
#> 2007 -0.0261 0.0176 -0.0641 0.0120
#> ---
#> Signif. codes: `*' confidence band does not cover 0
#>
#> Control Group: Never Treated, Anticipation Periods: 0
#> Estimation Method: Outcome Regression
从总体平均处理效应 (ATE) 的结果来看,提高最低工资会使青少年就业率下降 3.1%,在 10% 的置信水平下显著。
详细内容参见连享会推文
相关推文
Note:产生如下推文列表的 Stata 命令为:. lianxh DID. songbl DID
安装最新版lianxh/songbl命令:. ssc install lianxh, replace. ssc install songbl, replace
- 专题:专题课程
- 专题:倍分法DID
- DID偏误问题:多时期DID的双重稳健估计量(下)-csdid
- DID偏误问题:两时期DID的双重稳健估计量(上)-drdid
- Stata+R:合成DID原理及实现-sdid
- DID的陷阱和注意事项
- Stata:事件研究法的稳健有效估计量-did_imputation
- DID最新进展:异质性处理条件下的双向固定效应DID估计量 (TWFEDD)
- Stata:空间双重差分模型(Spatial DID)-xsmle
- 如何在R语言中实现多期DID
- 公开课:双重差分方法的新进展——交错型DID
- Stata:平行趋势不满足?主成分DID来帮你!- pcdid
- Stata:DID入门教程
- 倍分法:交错DID与Stata操作
- Stata倍分法新趋势:did2s-两阶段双重差分模型
- Stata倍分法:全国一刀切的DID
- Stata-DID:不同处理时点不同持久期的倍分法(flexpaneldid)
- 队列DID:以知识青年“上山下乡”为例-T401
- DID功效计算中的序列相关问题-T407
- 多期DID文献解读:含铅汽油与死亡率和社会成本-L113
- DID陷阱解析-L111
- DIDM:多期多个体倍分法-did_multiplegt
- 面板PSM+DID如何做匹配?
- 倍分法:DID是否需要随机分组?
- Fuzzy DID:模糊倍分法
- DID:仅有几个实验组样本的倍分法 (双重差分)
- 考虑溢出效应的倍分法:spillover-robust DID
- tfdiff:多期DID的估计及图示
- 倍分法DID:一组参考文献
- Stata:双重差分的固定效应模型-(DID)
- 倍分法(DID)的标准误:不能忽略空间相关性
- 多期DID之安慰剂检验、平行趋势检验
- DID边际分析:让政策评价结果更加丰满
- Big Bad Banks:多期 DID 经典论文介绍
- 多期DID:平行趋势检验图示
- Stata:多期倍分法 (DID) 详解及其图示
- 倍分法DID详解 (二):多时点 DID (渐进DID)
- 倍分法DID详解 (一):传统 DID
- 倍分法DID详解 (三):多时点 DID (渐进DID) 的进一步分析

