







Prometheus busca ser una nueva generación dentro de las herramientas de código abierto de monitorización. Una aproximación diferente y sin herencias del pasado.
Desde hace años, muchas herramientas de monitorización han estado vinculadas a Nagios por su arquitectura y filosofía o directamente por ser un fork completo (CheckMk, Centreon, OpsView, Icinga, Naemon, Shinken, Vigilo NMS, NetXMS, OP5 y otras).
Prometheus software, sin embargo, es fiel al espíritu “Open”: si quieres utilizarla, tendrás que juntar varias partes diferentes.
De alguna manera, como Nagios, podemos decir que es una especie de Ikea de la monitorización: podrás hacer con ella muchísimas cosas, pero necesitarás juntar tú mismo las piezas y dedicarle mucho tiempo.
- Arquitectura de Prometheus monitoring
- ¿Quieres monitorizar tus sistemas gratis con uno de los mejores softwares de monitorización que existen?
- Prometheus y las series de datos
- Para qué usar Prometheus
- Configuración en Prometheus
- Informes en Prometheus
- Dashboard y pantallas visuales
- Escalabilidad en Prometheus
- Monitorizando sistemas con Prometheus: exporters y colectores
- Conclusión
Arquitectura de Prometheus monitoring
Prometheus, escrito en el lenguaje de programación go, tiene una arquitectura basada en la integración de tecnologías libres de terceros:
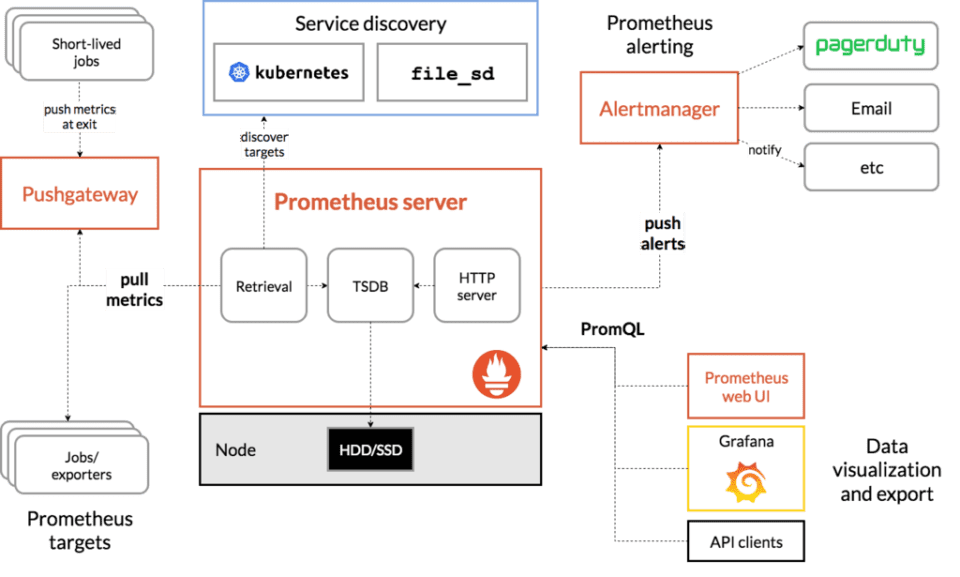
Al contrario que otros sistemas más conocidos, que también tienen muchos plugins y piezas para presentar mapas, Prometheus necesita terceras partes para, por ejemplo, visualizar datos (Grafana) o ejecutar notificaciones (Pagerduty).
Todos esos elementos de alto nivel pueden ser reemplazados por otras piezas, pero Prometheus es parte de un ecosistema, no una única herramienta. Por eso tiene exporters y piezas clave que en el fondo son otros proyectos Opensource:
- HAProxy
- StatsD
- Graphite
- Grafana
- Pagerduty
- OpsGenie
- y un larguísimo etcétera.
¿Quieres monitorizar tus sistemas gratis con uno de los mejores softwares de monitorización que existen?
Pandora FMS, en su versión Open Source, es gratis para siempre y para el número de dispositivos que tú quieras.
Te lo contamos todo aquí:
Prometheus y las series de datos
Si te suena RRD estás pensando en lo correcto.
Prometheus se plantea como un framework de recolección de datos de estructura no definida (clave valor), más que como una herramienta de monitorización. Esto permite definir una sintaxis para su evaluación y de esa forma almacenar solo en caso de evento de cambio.
Prometheus no almacena datos en una base de datos SQL.
Al igual que Graphite, que realiza algo similar, lo mismo que otros sistemas de otra generación que almacenan series numéricas en ficheros RRD, Prometheus almacena cada serie de datos en un fichero especial.
Si lo que estás buscando es una herramienta para recoger información en base de datos de series temporales (en inglés “Time series database”), deberías echar un vistazo a OpenTSBD, InfluxDB o Graphite.
Para qué usar Prometheus
O mejor dicho, para qué NO usar Prometheus.
Ellos mismos lo dicen en su web: si vas a utilizar esta herramienta para recoger logs, NO LO HAGAS, te proponen ELK en su lugar.
Si quieres utilizar Prometheus para monitorizar aplicaciones, servidores o equipos remotos usando SNMP, podrás hacerlo y generar bonitas gráficas con Grafana, pero antes…
Configuración en Prometheus
Toda la configuración del software de Prometheus se realiza en ficheros de texto YAML, con una sintaxis bastante compleja. Además, cada exporter empleado tiene su propio fichero de configuración independiente.
Ante un cambio en la configuración, deberás reiniciar el servicio para asegurarte de que coja los cambios.
Informes en Prometheus
Por defecto, Prometheus monitoring no tiene ningún tipo de informe.
Tendrás que programarlos tú usando su API para extraer datos.
Eso sí, existen algunos proyectos independientes para conseguirlo.
Dashboard y pantallas visuales
Para tener un dashboard en Prometheus, tendrás que integrarlo con Grafana.
Existe documentación de cómo hacerlo, ya que Grafana y Prometheus coexisten amigablemente.
Escalabilidad en Prometheus
Si en Prometheus necesitas procesar más fuentes de datos, siempre puedes añadir más servidores.
Cada servidor procesa su propia carga de trabajo, porque cada servidor de Prometheus es independiente y puede funcionar aunque se caigan sus compañeros.
Eso sí, tendrás que “dividir” los servidores por áreas funcionales para poder diferenciarlos, p.e: “servicio A, servicio B”. De manera que cada servidor sea independiente.
No parece una manera de “escalar” tal como lo entendemos, ya que no existe una manera de sincronizar, recuperar datos, no dispone de alta disponibilidad ni un framework de acceso común a la información en los diferentes servidores independientes.
Pero tal y como advertimos al principio, esto no es una solución “cerrada” sino un framework para diseñar tu propia solución final.
Eso sí, que no te quepa duda de que Prometheus es capaz de absorber muchísima información, en otro orden de magnitud que otras herramientas más conocidas.
Monitorizando sistemas con Prometheus: exporters y colectores
De alguna forma, cada “manera” diferente de obtener información con esta herramienta, necesita una pieza de software que ellos denominan “exporter”.
No deja de ser un binario con su propio archivo de configuración YAML que debe ser gestionado de manera independiente (con su propio demonio, fichero de configuración, etc).
Sería el equivalente de un “plugin” en Nagios.
Así, por ejemplo, Prometheus tiene exporters para SNMP (snmp_exporter), monitoreo de logs (grok_exporter), etcétera.
Ejemplo de la configuración de un exporter snmp como servicio:

Para obtener información de un host, podemos instalar un “node_exporter” que funciona como un agente convencional, similar a los de Nagios.
Estos “node_exporter” recolectan métricas de diferentes tipos, en lo que llaman “colectores”.
Por defecto, Prometheus trae activados decenas de estos colectores. Puedes consultarlos todos navegando hasta el anexo 1: colectores activos.
Y, además, existen multitud de “exporters” o plugins, para obtener información de diferentes sistemas hardware y software.
Si bien el número de exporters es relevante (unos 200), no llega al nivel de plugins disponibles para Nagios (más de 2000).
Aquí te hemos incluido un ejemplo de exporter de Oracle.
Conclusión
El enfoque de Prometheus para una monitorización moderna es mucho más flexible que el de otras herramientas más antiguas. Gracias a su filosofía, podemos integrarlo en entornos híbridos con mayor facilidad.
Sin embargo, echarás en falta informes, dashboards y un sistema centralizado de gestión de las configuraciones.
Es decir, una interfaz que permita observar y monitorizar información agrupada en servicios / hosts.
Porque Prometheus es un ecosistema de procesado de datos, no un sistema de monitorización IT al uso.
Su potencia en el procesamiento de datos es muy superior, pero el uso de esos datos para un día a día lo hace extremadamente complejo de gestionar, ya que requiere muchos ficheros de configuración, muchos comandos externos distribuidos y todo debe ser mantenido manualmente.
Anexo 1: Colectores activos en Prometheus
Estos son los colectores que Prometheus trae activos de serie:
Estos “node_exporter” recolectan métricas de diferentes tipos, en lo que llaman “colectores”, estos son los colectores de serie que están activados:
| arp | Exposes ARP statistics from /proc/net/arp. |
| bcache | Exposes bcache statistics from /sys/fs/bcache/. |
| bonding | Exposes the number of configured and active slaves of Linux bonding interfaces. |
| btrfs | Exposes btrfs statistics |
| boottime | Exposes system boot time derived from the kern.boottime sysctl. |
| conntrack | Shows conntrack statistics (does nothing if no /proc/sys/net/netfilter/ present). |
| cpu | Exposes CPU statistics |
| cpufreq | Exposes CPU frequency statistics |
| diskstats | Exposes disk I/O statistics. |
| dmi | Expose Desktop Management Interface (DMI) info from /sys/class/dmi/id/ |
| edac | Exposes error detection and correction statistics. |
| entropy | Exposes available entropy. |
| exec | Exposes execution statistics. |
| fibrechannel | Exposes fibre channel information and statistics from /sys/class/fc_host/. |
| filefd | Exposes file descriptor statistics from /proc/sys/fs/file-nr. |
| filesystem | Exposes filesystem statistics, such as disk space used. |
| hwmon | Expose hardware monitoring and sensor data from /sys/class/hwmon/. |
| infiniband | Exposes network statistics specific to InfiniBand and Intel OmniPath configurations. |
| ipvs | Exposes IPVS status from /proc/net/ip_vs and stats from /proc/net/ip_vs_stats. |
| loadavg | Exposes load average. |
| mdadm | Exposes statistics about devices in /proc/mdstat (does nothing if no /proc/mdstat present). |
| meminfo | Exposes memory statistics. |
| netclass | Exposes network interface info from /sys/class/net/ |
| netdev | Exposes network interface statistics such as bytes transferred. |
| netstat | Exposes network statistics from /proc/net/netstat. This is the same information as netstat -s. |
| nfs | Exposes NFS client statistics from /proc/net/rpc/nfs. This is the same information as nfsstat -c. |
| nfsd | Exposes NFS kernel server statistics from /proc/net/rpc/nfsd. This is the same information as nfsstat -s. |
| nvme | Exposes NVMe info from /sys/class/nvme/ |
| os | Expose OS release info from /etc/os-release or /usr/lib/os-release |
| powersupplyclass | Exposes Power Supply statistics from /sys/class/power_supply |
| pressure | Exposes pressure stall statistics from /proc/pressure/. |
| rapl | Exposes various statistics from /sys/class/powercap. |
| schedstat | Exposes task scheduler statistics from /proc/schedstat. |
| sockstat | Exposes various statistics from /proc/net/sockstat. |
| softnet | Exposes statistics from /proc/net/softnet_stat. |
| stat | Exposes various statistics from /proc/stat. This includes boot time, forks and interrupts. |
| tapestats | Exposes statistics from /sys/class/scsi_tape. |
| textfile | Exposes statistics read from local disk. The –collector.textfile.directory flag must be set. |
| thermal | Exposes thermal statistics like pmset -g therm. |
| thermal_zone | Exposes thermal zone & cooling device statistics from /sys/class/thermal. |
| time | Exposes the current system time. |
| timex | Exposes selected adjtimex(2) system call stats. |
| udp_queues | Exposes UDP total lengths of the rx_queue and tx_queue from /proc/net/udp and /proc/net/udp6. |
| uname | Exposes system information as provided by the uname system call. |
| vmstat | Exposes statistics from /proc/vmstat. |
| xfs | Exposes XFS runtime statistics. |
| zfs | Exposes ZFS performance statistics. |
Anexo 2: Ejemplo de exporter de Oracle
Este es un ejemplo del tipo de información que devuelve un exporter de Oracle, que se invoca mediante configuración de un fichero y una serie de variables de entorno que definen credenciales y SID:
- oracledb_exporter_last_scrape_duration_seconds
- oracledb_exporter_last_scrape_error
- oracledb_exporter_scrapes_total
- oracledb_up
- oracledb_activity_execute_count
- oracledb_activity_parse_count_total
- oracledb_activity_user_commits
- oracledb_activity_user_rollbacks
- oracledb_sessions_activity
- oracledb_wait_time_application
- oracledb_wait_time_commit
- oracledb_wait_time_concurrency
- oracledb_wait_time_configuration
- oracledb_wait_time_network
- oracledb_wait_time_other
- oracledb_wait_time_scheduler
- oracledb_wait_time_system_io
- oracledb_wait_time_user_io
- oracledb_tablespace_bytes
- oracledb_tablespace_max_bytes
- oracledb_tablespace_free
- oracledb_tablespace_used_percent
- oracledb_process_count
- oracledb_resource_current_utilization
- oracledb_resource_limit_value
Para hacernos una idea de cómo se configura un exporter, veamos un ejemplo, con un fichero de configuración del exporter JMX:
---
startDelaySeconds: 0
hostPort: 127.0.0.1:1234
username:
password:
jmxUrl: service:jmx:rmi:///jndi/rmi://127.0.0.1:1234/jmxrmi
ssl: false
lowercaseOutputName: false
lowercaseOutputLabelNames: false
whitelistObjectNames: ["org.apache.cassandra.metrics:*"]
blacklistObjectNames: ["org.apache.cassandra.metrics:type=ColumnFamily,*"]
rules:
- pattern: 'org.apache.cassandra.metrics<type=(\w+), name=(\w+)><>Value: (\d+)'
name: cassandra_$1_$2
value: $3
valueFactor: 0.001
labels: {}
help: "Cassandra metric $1 $2"
cache: false
type: GAUGE
attrNameSnakeCase: falseEl equipo de redacción de Pandora FMS está formado por un conjunto de escritores y profesionales de las TI con una cosa en común: su pasión por la monitorización de sistemas informáticos. Pandora FMS’s editorial team is made up of a group of writers and IT professionals with one thing in common: their passion for computer system monitoring.









