Position Encoding 是怎么回事?
关注者
94被浏览
90,70110 个回答


路漫漫求索

成为企业和政府组织数字化、智能化转型最值得信赖的合作伙伴
BoW是词袋模型,不考虑词语在句子中的先后顺序。有些任务对词序不敏感,有些任务词序对结果影响很大。
- 当我们使用卷积核大小为1的TextCNN模型做情感分类任务时,它就不考虑词语的先后顺序(它抽取到的是uni-gram特征),也可以取得不错的效果。
- 但是有些任务就必须要考虑位置信息。例如机器翻译,“我爱你”和“你爱我”的翻译结果是不相同。不考虑位置信息的话,“我爱你”和“你爱我”Encoding的结果是相同。
《Attention is All You Need》的Transformer模型用到Position Embedding。Transformer摒弃了之前机器翻译任务中常用的RNN结构,使得并行性更好。RNN的这种结构天生考虑了词语的先后顺序关系。当Transformer模型不使用RNN结构时,它就要想办法通过其它机制把位置信息传输到Encoding的部分。所以在该模型中中,每个时刻的输入是Word Embedding+Position Embedding。
Position Embedding有多种方法可以获得每个位置的编码:
- 为每个位置随机初始化一个向量,在训练过程中更新这个向量;
- 《Attention is All You Need》使用正弦函数和余弦函数来构造每个位置的值。作者发现该方法最后取得的效果与Learned Positional Embeddings的效果差不多,但是这种方法可以在测试阶段接受长度超过训练集实例的情况。
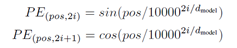
参考文献
Vaswani A , Shazeer N , Parmar N , et al. Attention Is All You Need. In 31st Conference on Neural Information Processing Systems. 2017