深度学习在路径规划上有哪些应用?
12 个回答

终于来了个自己研究方向的题目~
PS:路径规划(Path Planning)与运动规划(Motion Planning)在数学上是同一个问题,所以我在文中就直接混用了。
首先,我们要先明确路径规划/运动规划的定义:


简单地说,就是给定环境、机器人模型,指定规划目标(如无碰撞到达目的点),自动计算出机器人的运动路径(可以是一序列离散状态,也可以是运动策略)。
当然,传统的运动规划方法可以看我之前发过的两篇文章(运动规划 | 简介篇,运动规划 | 视频篇),这里就不展开了。所以,如 @Pickles Husky 所说,如果想将机器学习直接塞到现有的运动规划,似乎并不是一个好方法。于是,只能想办法发明新的运动规划框架了。
第一种,当然就是监督学习(Supervised Learning )的形式了。
这个其实很简单,Andrew Ng 的机器学习公开课(https://www.youtube.com/watch?v=_2zt4yVCkGk )里就提到了这样的一个例子
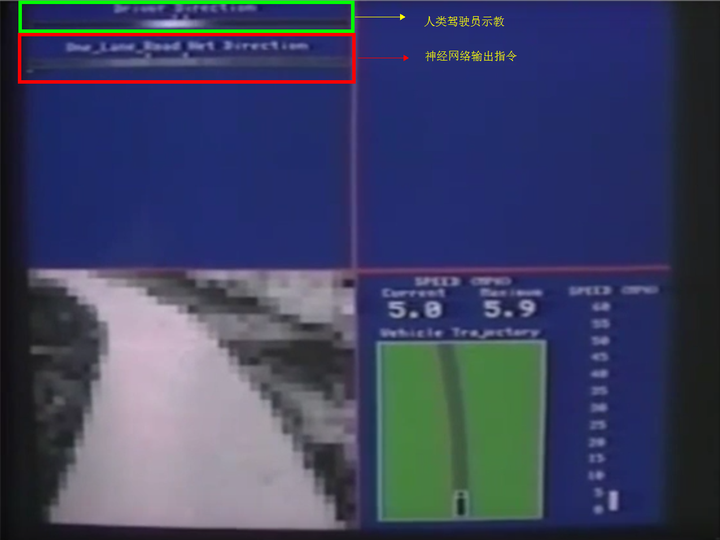

如上图所示,无人车通过输入前方图像,在人类驾驶员的标记动作下训练一段时间后,即可实现汽车的自主驾驶。
当然,上面这个例子的还是很简单的,所能应对的应用场景也极其有限;深度学习出来后,当然也有人做了类似的工作(前面的答主也有提到过这篇文章):
Pfeiffer, Mark, et al. "From Perception to Decision: A Data-driven Approach to End-to-end Motion Planning for Autonomous Ground Robots." arXiv preprint arXiv:1609.07910 (2016).
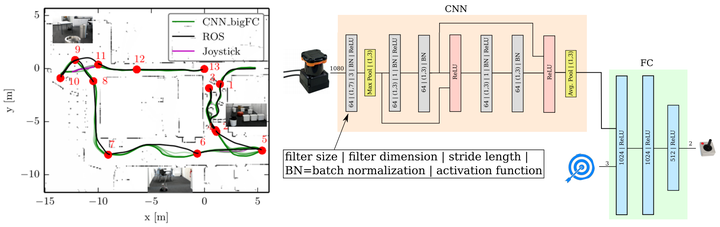

这篇文章的意思大概就是利用 CNN 解析激光信息,然后利用 A* 算法作为标记信息,进行监督学习。所以,这篇论文的工作其实跟前面那个自动驾驶的例子没什么太大区别。
目前看来,用监督学习的框架做运动规划,在环境变化不大的情况下,有可能实现;但是这种方法强烈依赖于标记算法(平面还好,有A*;高维机械臂的话,没什么好的『最优』算法),而且对环境变化的泛化能力比较弱。
第二种框架就是强化学习(Reinforcement Learning)了。这里我就先不详细展开强化学习的内容了,有兴趣的可以先去刷一遍 Sutton 的书:
Sutton, Richard S., and Andrew G. Barto. Reinforcement learning: An introduction. Vol. 1. No. 1. Cambridge: MIT press, 1998.
简而言之,路径规划就是一个标准的 MDP 问题,强化学习可以通过值迭代(value iteration)等方法建立一个表格,用以存储状态 s (如机器人当前位置)到动作 a (控制指令)的映射。这样,把机器人放在地图中任何一个位置,它都能迅速地确定自己下一时刻的动作,而这个动作将引导机器人运动到目标点。
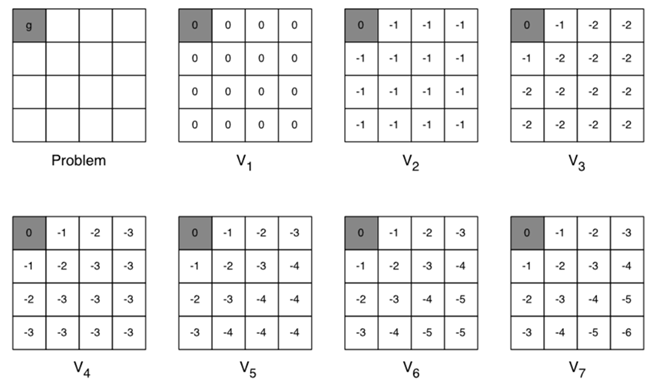
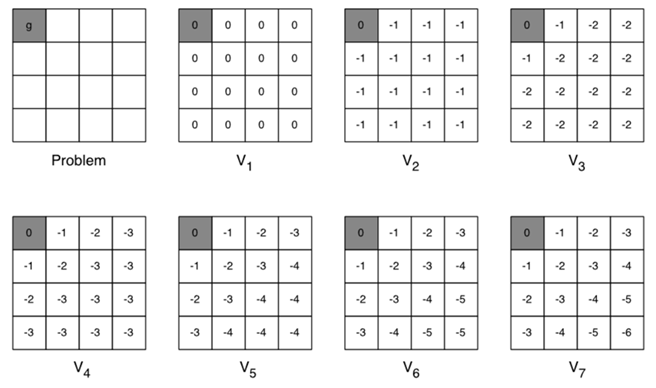
当然,如果目标点不同、障碍物位置不同,我只需生成多张表格即可。但是,这样就是造成表格太大,占用内存太多的问题。
后来,深度学习出现了,它有可能地完成两件事:1)从传感器观测数据 o 中提取出状态 s;2)拟合出状态 s 与动作 a 的映射关系(就是前面说的表格)。
大名鼎鼎的 DQN 就可以简单地认为在做这两件事(当然,它就是 End-to-End 的结构,实际上并不能简单地分为这样的两个步骤):
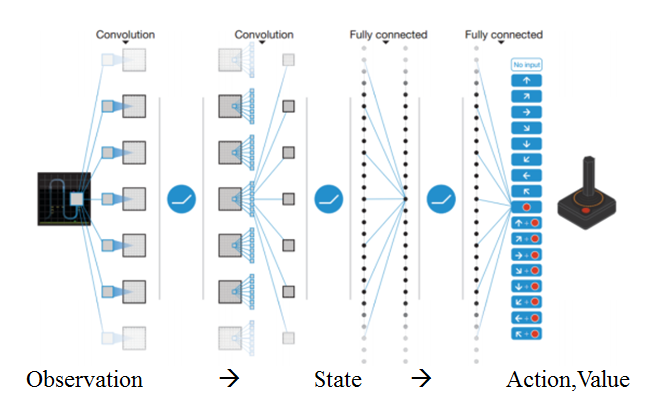

Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning." Nature 518.7540 (2015): 529-533.
深度强化学习的好处是我们不依赖于人工标记的轨迹,只需要指定规划目标(无碰撞、到达目的地、路径最短等),让机器人不断尝试、迭代更新网络即可。
当然,这一块用在路径规划的工作也已经有了:
Tai, Lei, and Ming Liu. "Towards cognitive exploration through deep reinforcement learning for mobile robots." arXiv preprint arXiv:1610.01733(2016). Tai, Lei, Giuseppe Paolo, and Ming Liu. "Virtual-to-real Deep Reinforcement Learning: Continuous Control of Mobile Robots for Mapless Navigation." arXiv preprint arXiv:1703.00420 (2017).

这篇文章就是让移动机器人在仿真环境中不断尝试学习、训练 DQN,最终得到一个较好的路径规划结果。
毕竟,现在 Planning-from-scratch 的规划方法总是给我一种『人类不是这样规划的呀』的感觉;深度强化学习又跟人类的技能学习方法很相似;如果成功,规划时间很短(一次前向传播的时间)。所以,我感觉,深度强化学习有希望成为彻底解决机器人运动规划问题的途径,未来几年应该也会涌现出一大堆 paper。
PS:从个人角度而言,如果还只是刚开始做路径规划的小伙伴,极度不建议直接上深度学习;我还是比较建议先至少把传统的规划算法体系都搞清楚,之后,如有可能,再去尝试深度学习。理由的话,以后有机会再聊吧。

分享一篇论文:Value Iteration Networks([1602.02867] Value Iteration Networks)。这篇文章发在了16年nips上。大致思路就是把2d navigation的问题转化成一个MDP问题来求解。我觉得比较新颖的地方是巧妙的运用CNN框架里面的max pooling来实现强化学习里面value iteration算法,从而用训练CNN的方法来实现强化学习的目的。
不过个人感觉强化学习用在路径规划里面都有种强行套模型的感觉,没看出比传统的路径规划的优势体现在何处。这一点欢迎大家来讨论