







深度神经网络(Deep Neural Networks, DNN)或深度卷积网络中的Inception模块是由Google的Christian Szegedy等人提出,包括Inception-v1、Inception-v2、Inception-v3、Inception-v4及Inception-ResNet系列。每个版本均是对其前一个版本的迭代改进。另外,依赖于你的数据,低版本可能实际上效果更好。这里是整理的Inception的v1、v2、v3、v4内容。
对于深度神经网络来说,提升网络性能最直接的办法就是增加网络深度和宽度(网络的深度指的是网络的层数,宽度指的是每层的通道数),这就意味着网络的参数数量会非常庞大。但是,海量的参数很容易产生过拟合,同时也会大大增加计算量。2014年,受Network in Network和稀疏网络的启发,Google公司提出了一个深度卷积神经网络来解决这些问题。这个名叫GoogLeNet的网络获得了ILSVRC2014的冠军。这个模型的设计理念认为解决上述两个缺点的根本方法是将全连接甚至一般的卷积结构都转化为稀疏连接。这样做的理由是在现实中生物神经系统的连接也是稀疏的,另外一方面也有许多研究证明了对于大规模的稀疏神经网络,可以通过分析激活值的统计特性和对高度相关的输出进行聚类来逐层构建出一个最优网络。以上这些表明了庞大臃肿的稀疏网络可以被简化并且性能不会受到太多影响。在早期深度学习的一些研究中,为了使打破网络对称性和提高学习能力,很多网络都采用了随机稀疏连接的做法。但是,计算机对非均匀稀疏数据的计算效率很差。于是现在需要一种方法,既能保持网络结构的稀疏性,又能使网络利用到密集矩阵的高计算性能。许多研究已经表明可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能,据此GoogLeNet网络采用了Inception-v1模块来实现此目的。GoogLeNet网络有时又称为Inception-v1网络,即GoogLeNet网络中使用的是Inception-v1模块。
Inception模块的核心思想就是将不同的卷积层通过并联的方式结合在一起,经过不同卷积层处理的结果矩阵在深度这个维度拼接起来,形成一个更深的矩阵。Inception模块可以反复叠堆形成更大的网络,它可以对网络的深度和宽度进行高效的扩充,在提升深度学习网络准确率的同时防止过拟合现象的发生。Inception模块的优点是可以对尺寸较大的矩阵先进行降维处理的同时,在不同尺寸上对视觉信息进行聚合,方便从不同尺度对特征进行提取。
Inception-v1论文名为《Going deeper with convolutions》,论文见:https://arxiv.org/pdf/1409.4842.pdf 。此模块使用了3种不同尺寸的卷积核(1*1、3*3、5*5)和1个最大池化核(3*3),增加了网络对不同尺度的适应性,论文截图如下所示:当感兴趣区域分布更全局时,倾向选择一个较大的核;当感兴趣区域分布的更局部时,倾向选择一个较小的核。
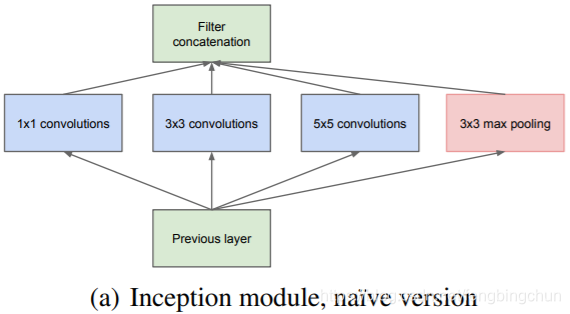
上图为Inception模块的原始版本:Inception模块中包含卷积操作,但是不同于传统卷积神经网络,此模块中可以设置多个通路,每个通路可以是不同的操作,相同的操作也可以设置不同的kernel size和stride。不同的卷积尺寸提供了不同的感受野,可以做不同级别上的特征提取,池化操作本身有提取特征的作用,而且因为没有参数不会产生过拟合,所以池化操作也作为此模块的一个通路。
此模块采取了几个措施来使密集的成分能够近似最优的稀疏结构。首先,在同一层中采用了不同大小的卷积核来提取上一层的特征,并在最后进行拼接。这样意味着在同一层中网络就能从感受不同大小的图像局部区域,并对不同尺度的特征进行融合。卷积核大小普遍采用1、3和5,再设定卷积步长为1,只要图像的填充值(padding)分别设置为0、1、2,那么卷积之后便可以得到相同维度的特征,之后便可以将这些特征值直接拼接在一起。此外,由于池化层在很多网络中都起到相当大的作用,因此在Inception模块中也嵌入了这一操作。最后由于神经网络随着深度的增加所提取的特征也逐渐抽象,每个特征涉及到更大的感受区域,因此在网络的深层应该逐渐增加大尺寸卷积核的比例。

上图为降维(dimension reductions)后的最终Inception-v1版本:优点:(1).同时使用不同尺寸的卷积核可以提取到种类更加丰富的特征;(2).使用稀疏矩阵分解为密集矩阵计算的原理,增加了收敛速度。
由于5*5的卷积核仍然会带来巨大的计算量,考虑到这一点,此模块加入了1*1卷积核来进行降维即限制输入通道数量。
Inception-v1中使用了多个1*1卷积核,其作用:(1).在大小相同的感受野上叠加更多的卷积核,可以让模型学习到更加丰富的特征。传统的卷积层的输入数据只和一种尺寸的卷积核进行运算,而Inception-v1结构是Network in Network(NIN),就是先进行一次普通的卷积运算(比如5*5),经过激活函数(比如ReLU)输出之后,然后再进行一次1*1的卷积运算,这个后面也跟着一个激活函数。1*1的卷积操作可以理解为feature maps个神经元都进行了一个全连接运算。(2).使用1*1的卷积核可以对模型进行降维,减少运算量。当一个卷积层输入了很多feature maps的时候,这个时候进行卷积运算计算量会非常大,如果先对输入进行降维操作,feature maps减少之后再进行卷积运算,运算量会大幅减少。
Inception模块中,1*1、3*3、5*5的卷积核并不是固定的,可以根据实验进行调整。
下图来自于https://blog.csdn.net/fengbingchun/article/details/80786455 ,可以形象地说明Inception-v1模块内是如何能够拼接在一起的:

Inception-v2、Inception-v3论文名为《Rethinking the inception architecture for computer vision》,论文见:https://arxiv.org/pdf/1512.00567.pdf 。 此模块在Inception-v1的基础上进行了改进。
Inception-v2:有三种形式,论文截图如下所示:

Figure 5:参考VGG,用两个3*3的卷积核代替5*5的大卷积核,这样在保持相同感受野的同时减少了参数,而且加强了非线性表达能力,还可以提升速度。

Figure 6:引入了factorization into asymmetric convolutions的思想,就是用两个1*n和n*1的卷积核替换一个较大的n*n卷积核。这种分解方法减少了大量参数,并且可以提高运算速度,减轻过拟合,同时给模型增加了一层非线性结构,提升了模型的表达能力,让模型可以处理更丰富的空间特征,增加了特征的多样性。但经过试验发现,在网络的前期用这种分解效果并不好,而且这种分解在中等大小的特征图上使用效果最好,如n=7。

Figure 7:模块中的滤波器组(filter banks)被扩展(使得更宽而不是更深),以消除representational bottleneck(降低representational bottleneck:其思路是,当卷积不会大幅改变输入尺寸,神经网络的性能会更好。减少维度会造成信息大量损失,也就是所说的 representational bottleneck)。如果模块变得更深,尺度将会过度缩小,从而导致信息的丢失。较适合于高维特征。
Inception-v2还提出了Batch Normalization(BN)方法。深度神经网络的训练过程十分复杂,如果前面几层发生微小的变化,这个微小的变化经过后面几层的传递会被放大。神经网络在训练的时候参数会不断更新,前面层训练参数的变化会导致后面层的输入数据分布发生改变。网络中间层在训练过程中数据分布发生改变,这种现象称之为”Internal Covariate Shift”。BN算法就是为了解决这个现象被提出来的。BN算法的核心原理就是:在网络的每一层的前面,插入一个归一化层,也就是上一层的输出数据先经过归一化处理,然后再输入到下一层,但是这个归一化层不是简单的归一化层,而是可以学习并且有参数的归一化层。如果只是使用简单的归一化,就是对网络某一层的输出数据进行归一化处理,然后输入到下一层神经网络,这样会对这一层神经网络学习到的特征造成影响。BN算法对每一个经过激活函数的值都引入了可以学习的参数γ、β,这两个参数可以对经过归一化处理后的输入进行缩放和平移。
Inception-v3:针对Inception-v2的升级,增加了以下内容:(1).RMSProp优化器。(2).分解为7*7卷积。(3).辅助分类BatchNorm。(4).标签平滑(Label Smoothing,添加到损失公式中的正则化组件类型,防止网络过于准确,防止过度拟合)。
Inception-v4、Inception-ResNet论文名为《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》,论文见:https://arxiv.org/pdf/1602.07261.pdf。
Inception-v4:将原来卷积、池化的顺次连接(网络的前几层)替换为stem模块,即Inception模块之前执行的最初一组操作,来获得更深的网络结构,论文截图如下所示为stem模块结构:

Inception-v4有三个主要的Inception模块,分别为A、B、C,论文截图如下所示:依次为Inception-A、Inception-B、Inception-C



Inception-v4采用专门的Reduction Blocks用于更改网络的宽度和高度。论文截图如下所示:

上图为Reduction Block A,将35*35尺寸缩小至17*17。

上图为Reduction Block B,将17*17尺寸缩小至8*8。
Inception-v4的整个网络布局,论文截图如下所示:

注:以上所有的内容的整理均来自网络,除参考原始论文外,还主要参考:
2. https://cloud.tencent.com/developer/article/1166837
3. 《基于卷积神经网络的多目标定位研究》,2019,硕论,长安大学
4. 《基于深度学习的细粒度图像识别研究》,2018,硕论,北京邮电大学














 3479
3479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









