
62 个回答

情理之中,但没有意料之外!
感谢tesla对机器人事业的支持!
今天Tesla展示的机器人,早在小米的机器人的回答中,就大致说过人形机器人目前还看不到任何的现实应用的可能性,尤其是需要物理交互的场景下(Physical human robot interaction)。
你对小米发布的人形机器人 CyberOne 有什么看法? - 李淼robot的回答 - 知乎 https://www.zhihu.com/question/547996316/answer/2622292495
其中一个主要的原因就是物理世界的不确定性(uncertainty),在机器人与现实世界交互时,我们先不看全身的交互,就只看手(grasping and manipulation)和足部(walking)。关注人形机器人,只需要看着两个点,基本就能估计技术水平的发展阶段了。毕竟一个不走路,不用手的机器人,也就是一个大号的玩具了。
walking:tesla这个机器人的走路功能就不去详细评价了,从视频上看还是比较小心翼翼的,并没有很动态的感觉,手与腿部的协调也比较少,感觉还是这方面的工程师不足。




grasping:在抓取这个事情上,我们可以关注在几个点上:有没有grasp planning, 有没有feedback control, 手的机械设计上有没有本质的创新(还是有一些的,这些其实国内很多同仁也做得很优秀了)。 从有限的视频中看,打招呼的时候的手是黑色的,抓取水壶和铝条的时候,感觉抓取点是事先写好的,并没有用任何的real time planning,要不然那个水壶在抓取的时候被推动了那么多,机器人肯定是要做一点调整的。
另外抓取的时候手部似乎是橡胶的白色(打招呼的机器人手部是黑色的手部),个人感觉这个是为了增加手部的摩擦力。另外选择一个空的塑料水壶和一个轻质的铝条,也恰恰说明在grasping上,这个手包括手臂的能力还很欠缺(也许最大也就可以抓一瓶500ml的可口可乐)。
对抓取和操作中不确定感兴趣的,也可以关注我们组织的workshop,这些现实中的不足之处,也许都是研究中的有意思的方向。(https://sites.google.com/view/the-role-of-uncertainty/home?authuser=0)




亮点:在actuator的设计上,其中有一页一闪而过,集成了大量的sensor,感觉还是很有想象力的。tesla的工程能力还是让人佩服的,持续的投入下去,也许可以打开新的大门,这个希望后面有更多的资料出来。
总之,这还是一个非常早期的原型机,离世界最好的水平还有不小的距离。对于机器人,“这不是结束,这甚至不是结束的开始。但,这可能是开始的结束”。

10⽉1⽇,⼀年⼀度的科技春晚,特斯拉AI Day 来了。
整场发布会⾮常硬核,⼲货也很多。
FSD、Dojo、Tesla Bot超级计算机是这次发布会的三⼤看点。
不过,我们主要关注的,还是特斯拉在FSD ⽅⾯的新进展。
此前,绝⼤部分⻋⼚都循着特斯拉的步伐,⾛上渐进式⾃动驾驶发展之路。
但是随着能⼒参差以及对⾃动驾驶理解不同,特斯拉与⼀众⻋企分道扬镳。

特斯拉⾛上了纯视觉路线,其他⻋企则开始投⼊激光雷达怀抱。但是,对于⼤多数⻋⼚来说,特斯拉依然是⻛向标。
他们也都很好奇:特斯拉纯视觉⾃动驾驶究竟有何进展?
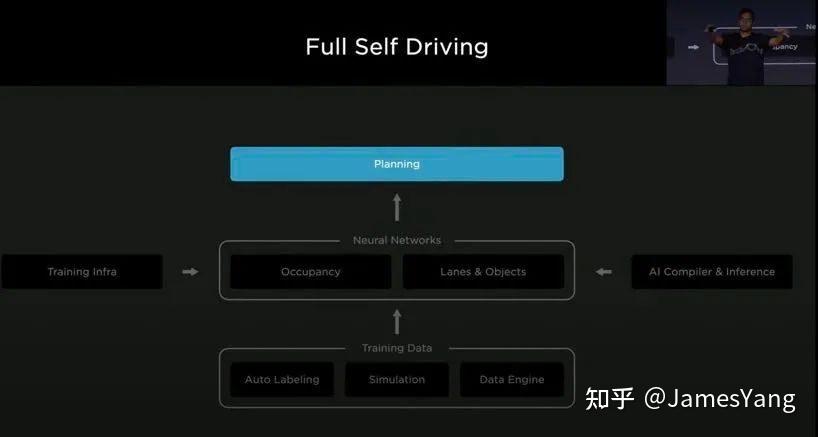
聊进展之前,还是先了解⼀下,特斯拉FSD 的基本框架。
01
FSD框架
先说测试规模,2021 ⼤概有2000 位「勇⼠」参与到FSD Beta 的测试, 今年,这个数字增加到160000 位。
从去年到现在,FSD 进⾏过35 个版本迭代,训练了 7.5万 个神经⽹络模型,基本上8 分钟训练1 个,并推送了35个版本更新。
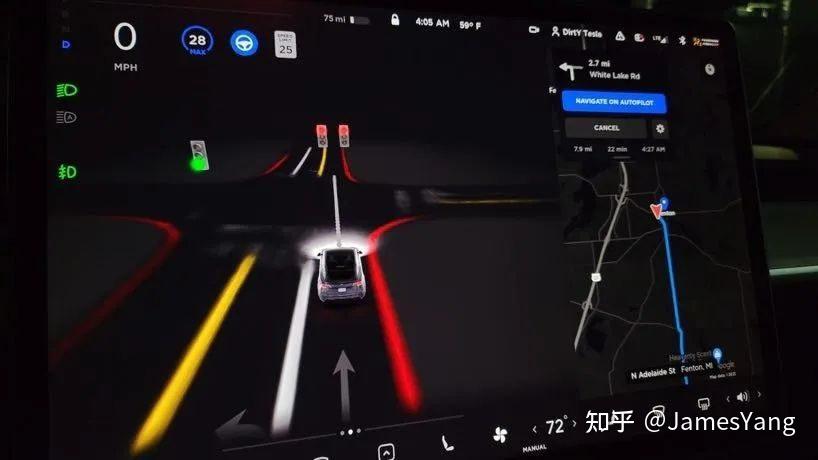
⽬前FSD Beta 在⼀定程度上已经可以实现从⼀个停⻋场导航到另⼀个停⻋场,可以⾃动完成识别红绿灯并通⾏、通过⼗字路⼝、转弯等操作。
来看看特斯拉FSD基本框架。
所有的⼀切完全依靠单⻋智能实现。通过⻋上运⾏神经⽹络的摄像头⽣成环境模型,⽽后基于此模型进⾏⻋辆的规划和控制。

这是⼀个多摄像头神经⽹络,系统通过收到的图像来推测物理世界各个坐标都有什么东⻄。
没错,推测。虽然我们看到的是图⽚,但是在摄像头看来,它看到的就是其实是⼆维⽹格,需要进⾏转换和编码。
⽽后通过不断的模型训练,才能识别出图像中的物体到底是什么,譬如树⽊、墙壁、汽⻋。
当然,识别的内容不⽌这些,还有各种语义层,包括各种⻋道线、交通信号灯、停⻋线等。


⽽在识别物体之后,系统会得出这些物体现在的状态坐标,并预测这些物体接下来的运动。
对于典型计算机视觉技术来说,处理这些内容⾮常困难,所以特斯拉在不断深⼊到语⾔技术领域,然后从其他领域提取最先进的技术,融合进来。
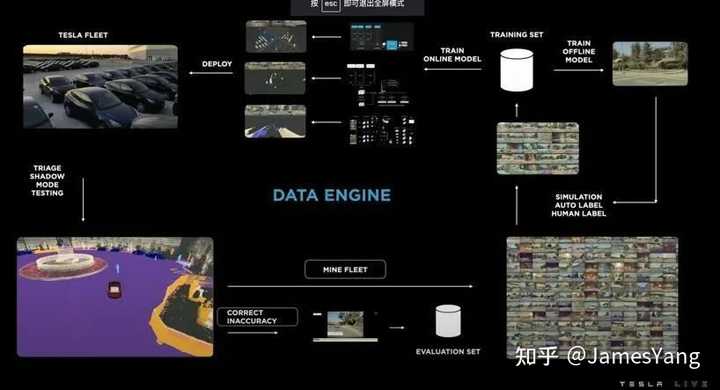
但是,很多物体还是⽆法被探测到或者被准确识别,这⾥就需要对数据进⾏标注,特斯拉已经拥有⾃⼰的⾃动标注系统。
此外,特斯拉利⽤⾃⼰的仿真系统来构建图像,通过数据引擎管道,⽤⼀些数据训练模型,然后把它放到⻋上,看是否可⾏。
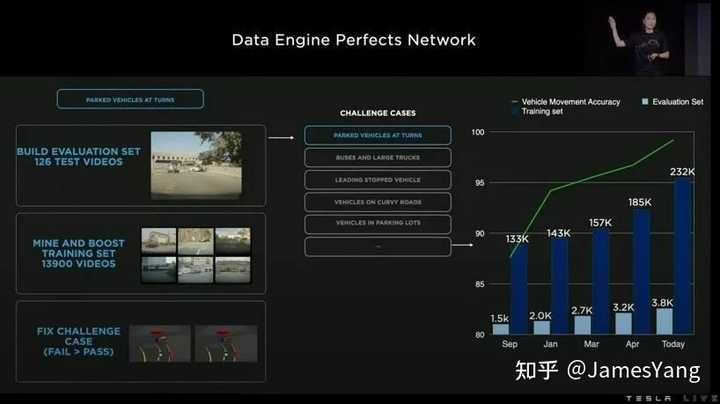

如果发⽣故障,⻋队会进⾏分析,并提供当前标签并将数据添加⼤训练集,这个过程系统地解决了问题。
为了训练这些新的⼤规模神经⽹络,特斯拉今年把训练基础设施扩展了40%-50%,今年特斯拉在美国训练集群已搭载⼤约14000 个GPU。
同时,特斯拉还开发了⾃⼰的⼈⼯智能编译器,⽀持这些神经⽹络所需的新操作,并将它们映射到特斯拉最好的底层硬件上。
⽬前,特斯拉推理引擎能够将单个神经⽹络的执⾏分布在芯⽚上的两个独⽴系统上。本质上其实就是连接在同⼀台⾃动驾驶计算机中的独⽴计算机。


其实就是同⼀神经⽹络在两块FSD芯⽚都进⾏运算,为此,必须严格控制新系统端到端的延迟。
为此,特斯拉布局了很多新的代码,所有这些在⻋⾥运⾏的新⽹络,产⽣向量空间。
进⽽在汽⻋周围建⽴起新的模型,规划系统在此基础上得出运⾏轨迹。通过基于模型的神经⽹络的组合,特斯拉FSD 正在⻜速成⻓。
02
交叉路口规控策略
⽆保护左转,是⾃动驾驶的⼀⼤难题。
⾃动驾驶⻋辆在进⾏决策规划的时候就会涉及到多种变量,需要梳理不同变量之间的关系,进⽽推演出最合理的通⾏⽅式。
下⾯这个就是⼀个很有代表性的场景:⽆保护左转还遇到通过的⾏⼈。


这基本上可以归结为解决多智能体在⾃我和所有其他智能体轨迹上的精确规划问题。
这就需要系统能够在很短时间内厘清出各个对象之间的关系,然后推导出最合理的通⾏策略。
别忘了,系统还要预测这些对象接下来的运动,相关交互组合的数量会爆炸式增⻓。
这个计算量⾮常⼤,⽽规划者需要每50 毫秒做⼀个决定。
很多⼚商都不太能做好这个场景。包括⽆⼈驾驶Robotaxi 公司。那么,特斯拉是怎么做的呢?
特斯拉采⽤⼀种名为Interaction Search(⾳译交互搜索)的框架,对⼀系列运动物体进⾏研究。
这⾥的状态空间对应于⾃我的运动状态,其他主体的运动状态,多模型未来预测,以及场景中所有的静态实体。
可以使⽤⼀组物体运动轨迹来看场景中不同交互决策,同时也可以加⼊新的变量,来获得更多决策优化。
⽐如还是刚刚的过⼗字路⼝案例。我们从⼀系列视觉测量开始。
1、被看⻅的物体。⽐如⻋道、移动物体、其他不可动实体,这些元素为潜在特征。
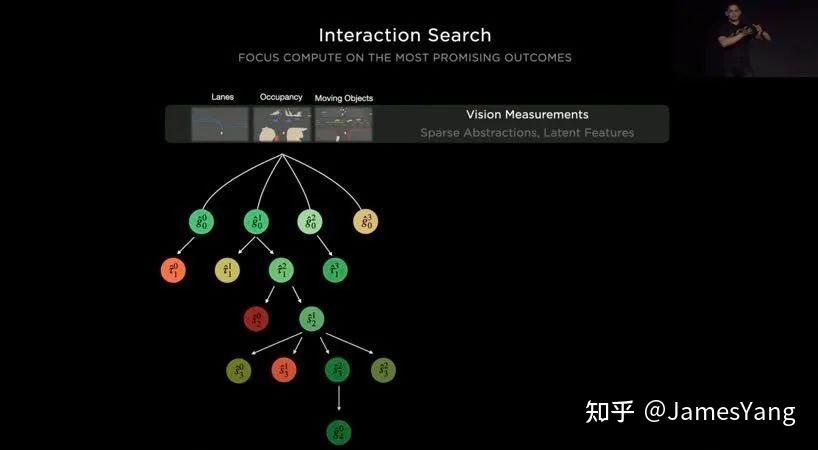

2、构建路径。我们⽤它从⾮结构化区域的⻋道⽹络中来创造最优通⾏路径。
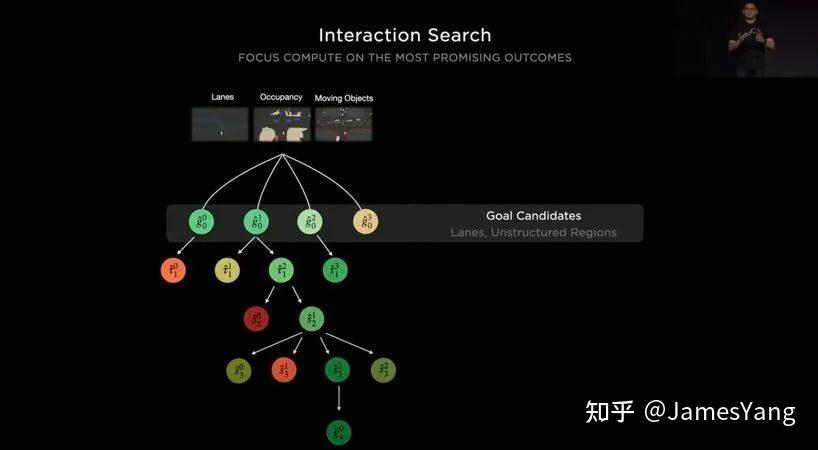

3、路径推演。以此来创建项⽬树,使⽤来⾃客户群的数据进⾏训练。与此同时就会⽣成多种不同决策结果,我们也能从中找到最优解。
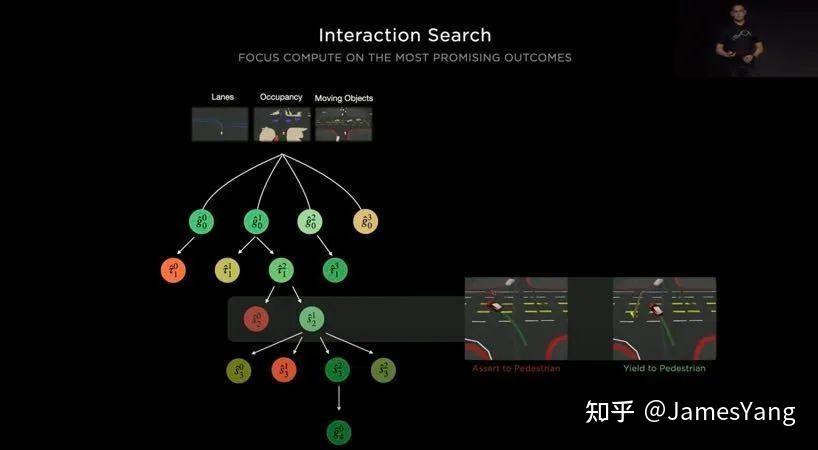

4、引⼊新变量,再次寻求最优。在这个最优解之上,你也可以加⼊新的变量,⽐如加⼊右侧驶来的⻋辆,这样就会产⽣新的决策树,新的分⽀,然后再从中选出其中的最优解。

就像刚刚说的这个运算量⾮常巨⼤。
所以特斯拉选择构建轻量级⽹络来进⾏轨迹⽣成。结果就是:把每个动作的运⾏时间缩短到100 微秒。对⽐之下,此前每个动作需要1-5 毫秒。
这个提升,⾮常明显。
此外,特斯拉还会有⼀项「轨迹评分」标准,此举是为了提升FSD⽤户使⽤舒适度。
说⼈话就是:FSD 不仅要能够做到,还要能够做好,让⻋开起来像⼀个⽼司机⼀样稳健。
在这⾥,特斯拉会运⾏两个可变神经⽹络,可以相互增强。
其中⼀套是FSD Beta,这让我们知道在接下来的⼏秒钟内,⼀个⼈受到⼲预的可能性有多⼤。
第⼆套源⾃⼈类驾驶数据,给FSD系统的表现评分,可以帮助特斯拉更好的优化FSD 的体验。
特斯拉表示:「这个架构最酷的地⽅在于,它允许我们在数据驱动的⽅法之间创建⼀个很酷的融合,没有那么多⼿⼯成本,但结果的核查检验依然是基于现实。」
这⼀part简⾔之就是:特斯拉⾃动驾驶规划决策所需时间变短、能⼒更强、体验更好。
03
3D建模
特斯拉所有感知都要靠这8 个摄像头。
特斯拉依靠摄像头获取图像信息,然后⽤算法,取得类激光雷达3D 成像的效果(从 image space 到 vector space )。
现在FSD UI 中展示的只是所渲染的空间向量中的⼀部分:
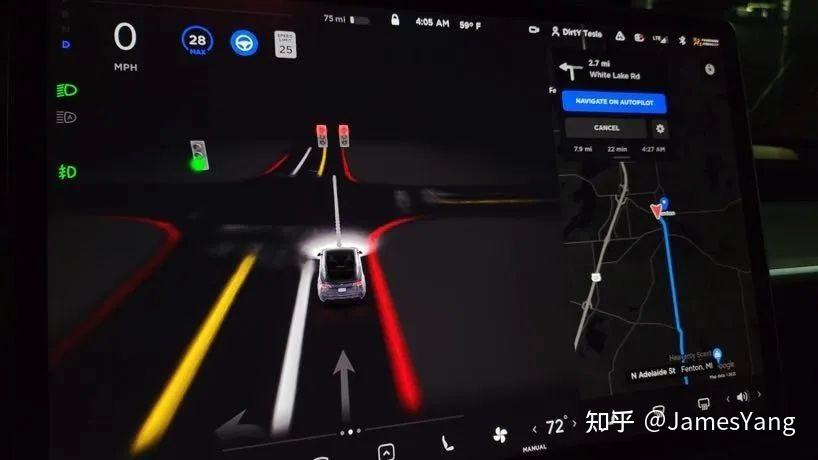
但是在精度上还是⽆法与真正的激光雷达相⽐。
⽐如,当有⻋辆经过时,⽆法准备识别该物体。这也是去年难到特斯拉的⼀个⼤问题:




对于采⽤激光雷达⽅案的公司来说,可以⾮常精准且轻松的检测到物体并捕捉物体的移动。
但是视觉想要做到这⼀点,并不容易。
特斯拉运⽤⼏何占⽤率了解视觉3D 中的遮挡⼤⼩。
下⾯这个占⽤神经⽹络(the occupancy network)就是他们的成果。这⾥看到的是来⾃系统内部第⼆层的规则⽹络输出。
(这个3D 建模并没有出现在⽬前特斯拉推送给⽤户的可视化UI 中,但也很酷)
具体来说,占⽤⽹络将8 个摄像头的视频流作为输⼊,在⽮量空间中直接为所有汽⻋周围的每个三维位置⽣成统⼀的体积精度,然后预测该地点被⼤量占⽤的概率。


与此同时,联系输⼊的视频上下⽂,它还会预测即将可能被遮挡的障碍物。
在每个位置,它都会⽣成⼀组语义,⽐如⻢路⽛⼦、汽⻋等,然后⽤不颜⾊标注。
于是就有了下图的建模:


与此同时,对于运动中的占有率情况也可以进⾏预测。
由于该模型是⼀个⼴义⽹络,它没有区分静态和动态对象,也能够建模随机运动。


⽬前,这个⽹络正在所有特斯拉FSD计算机上,⽽且⾮常⾼效,使⽤特斯拉新的加速器,⼤概每10 毫秒运算⼀次。
所以,这就是特斯拉在纯视觉取代激光雷达上所做的⼀点⼯作。
除了⽴体像素,占⽤⽹络还能输出路⾯相关信息,⽐如它的路⾯⼏何情况(⽐如坡度),还有路⾯语义。
这会对系统规控有很⼤的帮助。
直接上案例吧。看这⾥的这张图,坡道三维信息也被很很好的预测出来,有了这样的信息输⼊,后续系统可以决定接下来是否要减速⾏驶。
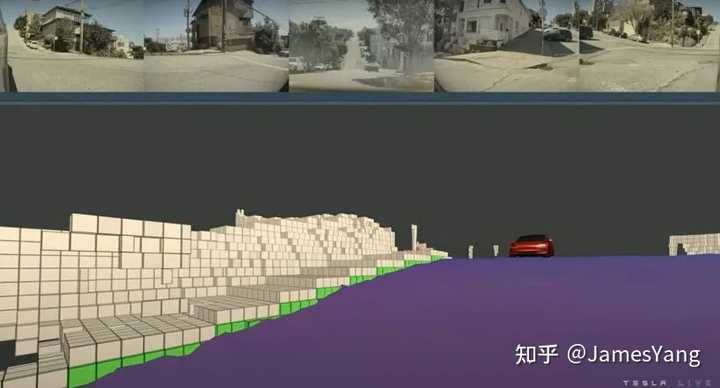

如果这件事交给直接采⽤⾼精地图⽅案的公司来说,这⼀步就很简单。
因为⾼精地图公司已经将这些道路信息包括坡度、弯道曲率等信息录⼊地图,当⻋辆⾏驶到这⾥,⻋辆可以提前根据这些已知做出预判和控制。
所以,这就是特斯拉在替代⾼精地图上取得了不错的进展。
04
具体怎么实现的?
⾸先,摄像头提取图像数据并校正,然后采⽤RegNets和BiFPNS 来提取图像特征,构建3D 位置查询,所有图像以及特征都有其⾃⼰的键和值。
通过这些键和值,你可以知道前⽅是什么物体,亦或者是某个部分被遮挡的物体。
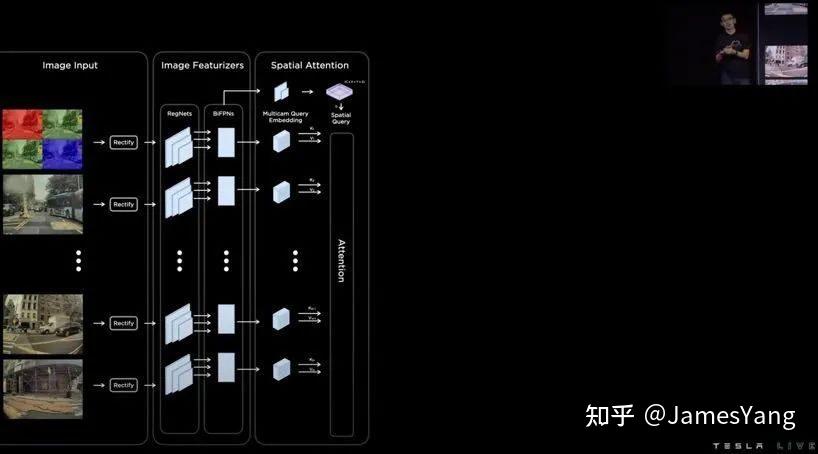

这些内容再通过注意⼒模块输出⾼维空间特征,这些空间特征⼀致。然后使⽤⻋辆瞬时测程推导运动轨迹。
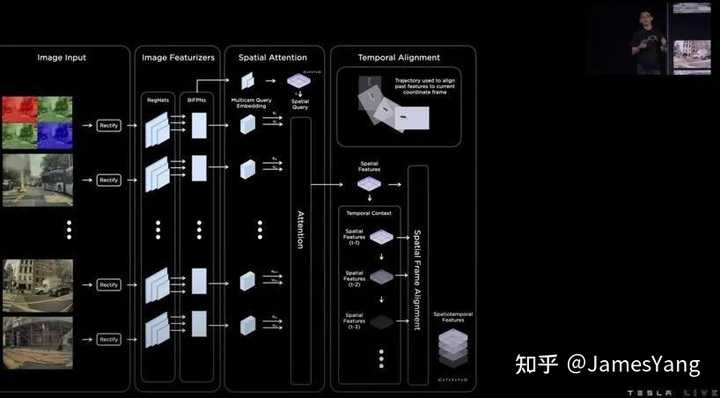

将这些时空特性通过反卷积神经⽹络,推出最终的占⽤率和占⽤流,形成固定尺⼨的盒⼦。
但是这对于规划和控制来说精度可能不是很够。
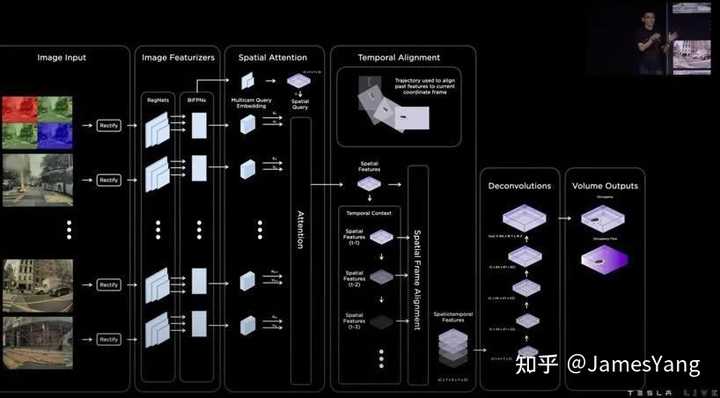

为了获得更⾼分辨率,特斯拉还⽣成每个像素形状映射,你就当做是⼀个个坐标,然后把这些坐标和 3D 空间点查询送⼊给MLP(多重感知机),以获得任意点的位置和语义。
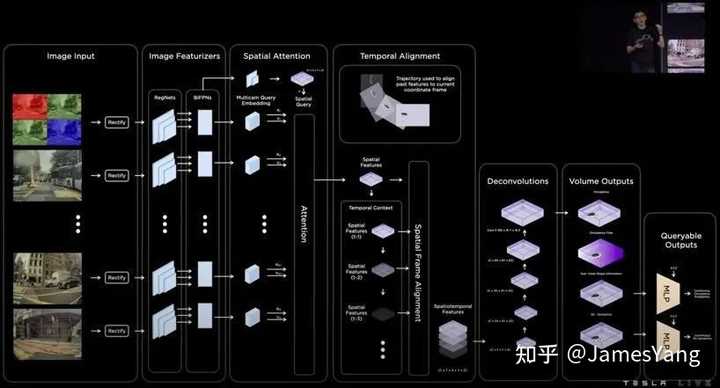

很多⼈看到这⾥可能就晕了,来看看这个案例:




特斯拉在不断⾏驶,前⽅的⼤巴被识别为「L」的红⾊盒⼦,当⻋辆逐渐靠近,巴⼠也在移动,⻋头直接从红⾊变成了蓝⾊。
随着时间推移,整个巴⼠都变成了蓝⾊,你甚⾄可以看到这个⽹络预测巴⼠向左运动时的精确曲率。


对于传统⽬标检测⽹络来说,这是⼀个⾮常复杂的问题,可能会⽤⼀个或者两个⻓⽅体来拟合曲率。
但是对于占⽤⽹络来说,只需注意有可⻅空间的占⽤情况,⽽后就能精确的建⽴曲率模型。
此外还有刚刚说的,弯曲路⾯的⼏何以及相关语义的识别。
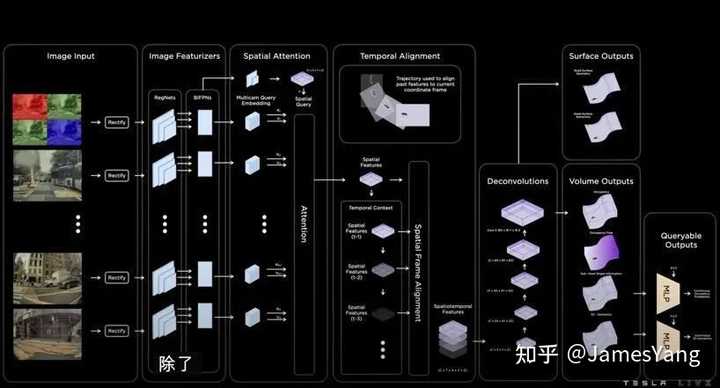

最后就是使⽤⼤型⾃动标记数据集对占⽤⽹络进⾏训练。


此外,特斯拉也在关注其他神经⽹络,⽐如NeRF((Neural Radiance Fields)
这⾥简单解释⼀下。NeRF,神经辐射场。是⼀项利⽤多⽬图像重建三维场景的技术。
直接上案例吧。
⽐如眼前的这个架⼦⿎。通过多组图像在神经⽹络的训练,就可以构建出这个架⼦⿎的三维场景,⽽且还能给到两组不同于之前图像的新视图。
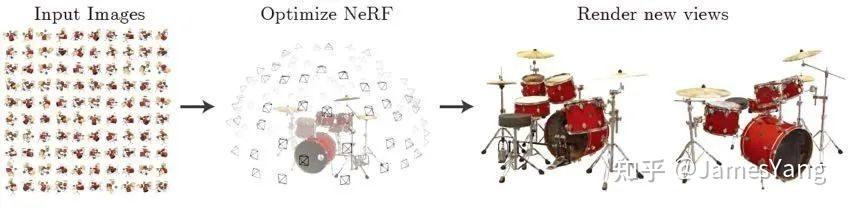

显然,这个技术很对特斯拉胃⼝。
特斯拉考虑将⼀些功能整合到占⽤⽹络训练中。
这是他们做的⼀个演示案例,⽬的是为了给⾃动驾驶呈现呈现3D 世界。


不过要做到这点并不容易,特斯拉在这个地⽅继续邀请⼤⽜们加⼊特斯拉⾃动驾驶团队。
有了强⼤模型,下⼀步就是要训练它。这就需要海量可⽤学习的数据视频。
看到这张图了吗?这并不是故障或者是雪花,⽽是视频。⼤概1.4 亿帧。


这个量⾮常巨⼤。如果⽤10 万个GPU 进⾏训练,需要1 个⼩时,如果你有1 块GPU,需要10 万⼩时。
这个时间⾮常⻓,⽽特斯拉想要更快的训练速度。
这也是为什么特斯拉要建造⾃⼰的超级计算机的原因。
特斯拉有3 个超级计算机,共计14000 个GPU,其中1 万个⽤于训练, 另外4 千块⽤于⾃动标注。
所有的视频都存在容量在30PB 的分布式视频缓存设施中。
这些数据集并⾮⼀尘不变,⽽是处于变化,每天有⼤概有50 个视频在集群中替换流动,系统每秒跟踪40 万个视频实例。
⽽在优化视频模型训练上,特斯拉也是做了很多⼯作:
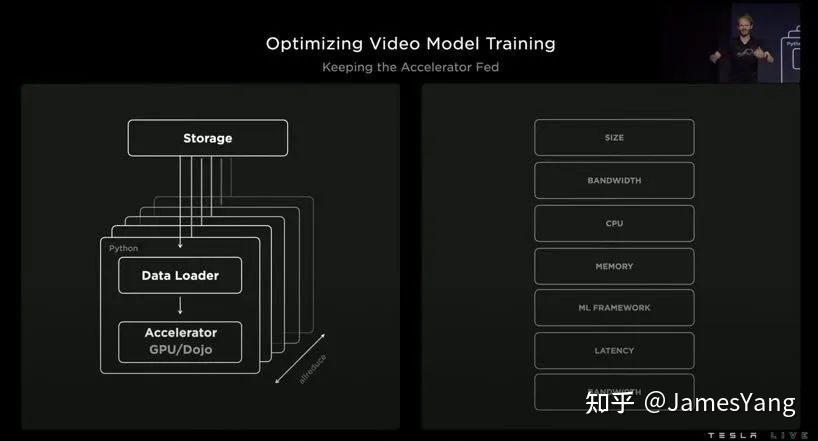

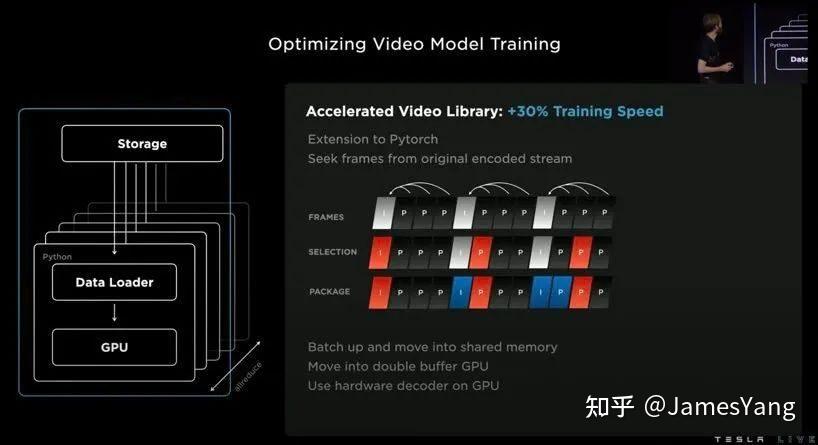

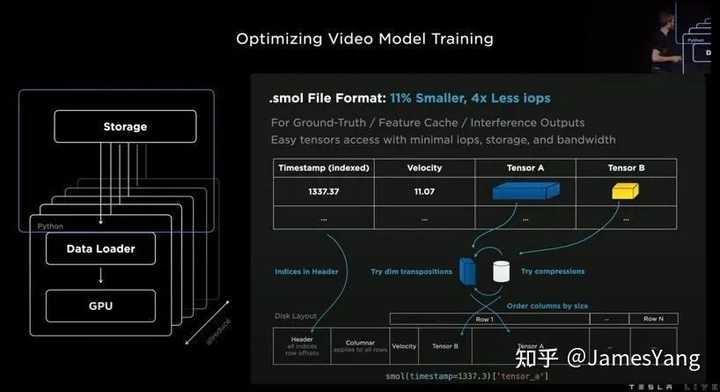

结果就是:通过这些积累和优化,特斯拉现在训练占⽤⽹络的速度提升了2.3 倍。
05
车道检测&周围物体未来行为预测
早期特斯拉是在2D 图像空间进⾏实例分割,同时神经⽹络也很简单,只能识别为数不同的⼏种类型的道路。
这种⽐较简单的道路建模适合在⾼度结构化的道路上。
现在,特斯拉要做的是⼀个系统,可以适⽤在更复杂的路况,不仅仅要⽣成全套⻋道实例还有它们之间的连接。
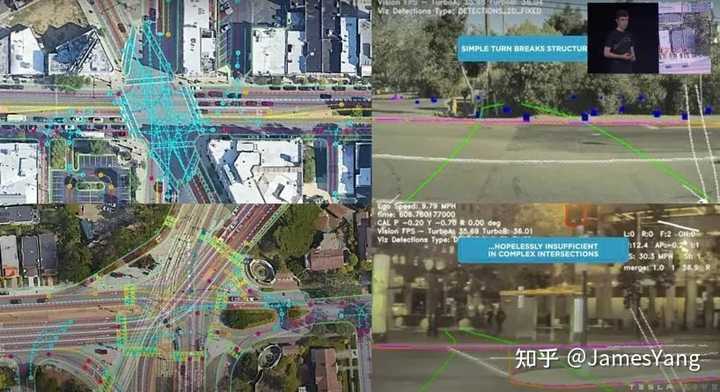

路⼝通⾏是⼀个很好的案例。
⽬前辅助驾驶⻋辆的⼀个⽐较⼤的通病在于:有⻋道线道路⾏驶正常,⽆⻋道线引导⽅⼨⼤乱。
特斯拉要做的就是提升辅助驾驶在这⼀块的表现。所以特斯拉⾃⼰做了⻋道神经⽹络。
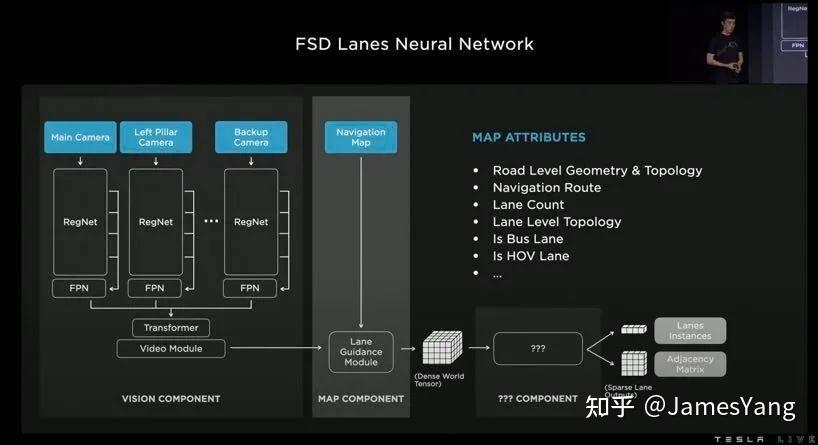

由三个组件构成:
1、视觉组件:有⼀组卷积层、注意层和其他神经⽹络层,处理来⾃⼋个摄像头的视频数据并进⾏编码,并产⽣丰富的视觉表征;
2、⻋道引导模块:⽤道路级别的地图数据增强这种表征。并引⼊⼀组额外的神经⽹络层进⾏编码。
虽然只是普通地图,虽然不是⾼精地图,但提供了很多基础属性信息,
⽐如⻋道拓扑结构、⻋道数、导航路线等信息。
这⾥引申出的⼀个信息是:特斯拉FSD 有⽤到地图,但是是普通的导航地图,⽽不是⾼精地图。
所以不要再问特斯拉⾃动驾驶到底⽤不⽤地图这件事了。
3、语⾔组件:前两个组件产⽣了⼀个密集的张量,可以对世界进⾏编码。不过特斯拉的诉求是将这个密集张量转换为智能⻋道集还有它们的连通上。
输⼊的是这个密集张量,输出⽂本则被预测为特斯拉⾃⼰开发的特殊语⾔,姑且称之为道路语⾔(Language of Lanes)吧,特斯拉⽤它来编码⻋道的连接关系。
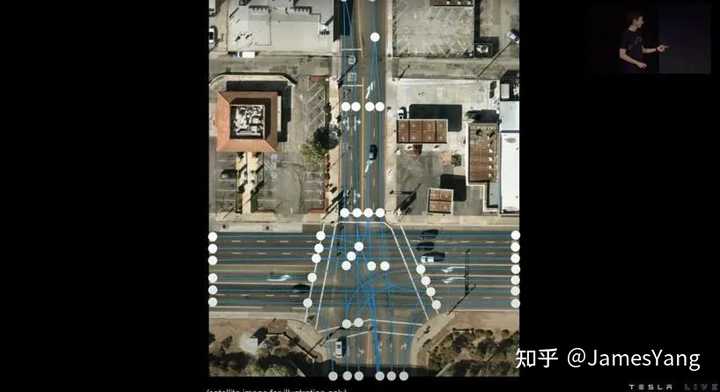

具体咋做呢?看图:




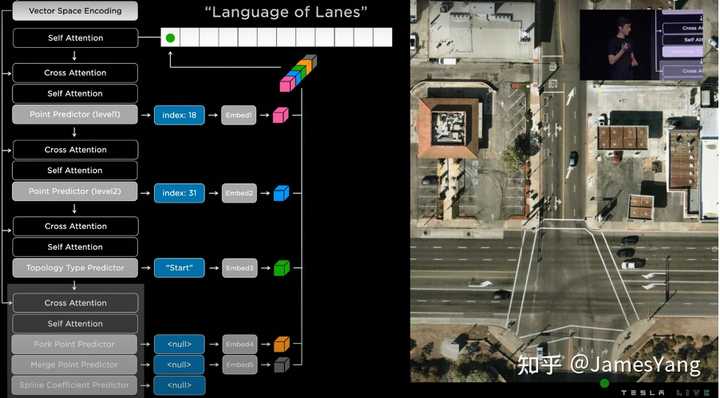

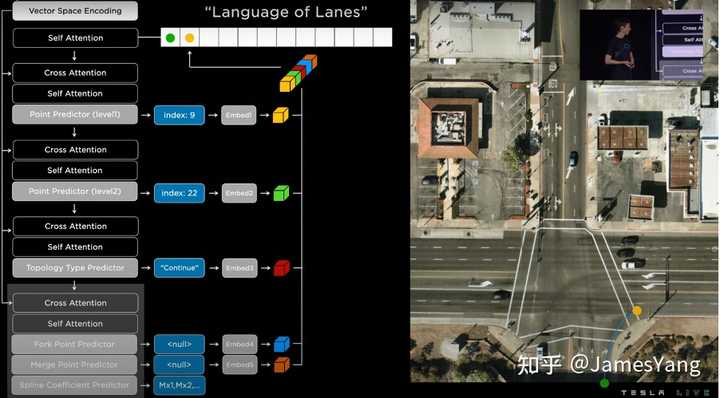

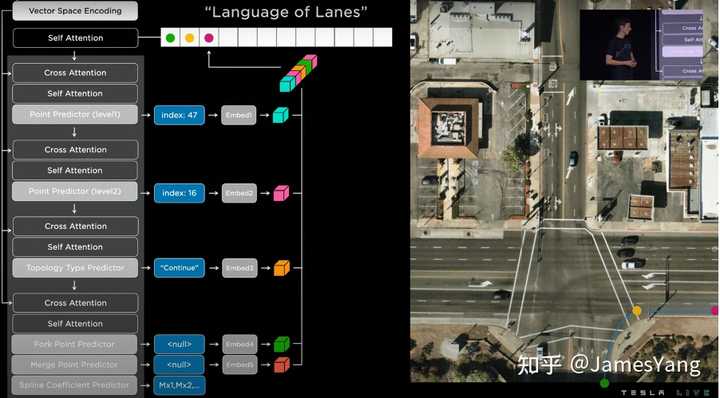

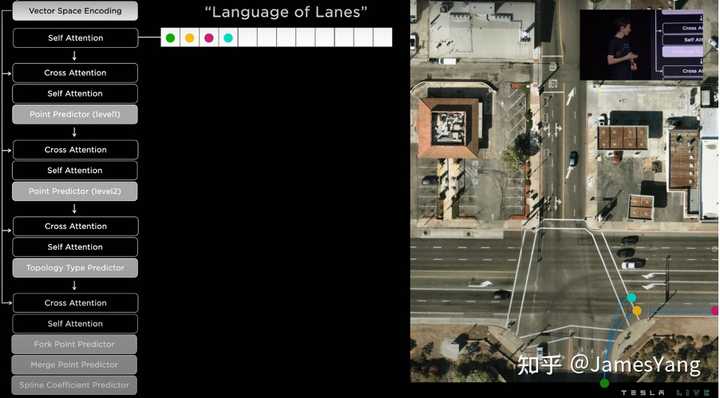

这就是最终⻋道⽹络:


简⾔之,这让特斯拉在没有⾼精地图以及激光雷达的情况下,拥有了⾼清晰度的空间定位以及更远的可视范围。
周围物体未来⾏为预测&路径规划
这个⾏为其实很好理解。
代⼊到我们⼈类驾驶员,其实我们⾃⼰在开⻋的时候,其实下意识的也会去做类似的预判,关注周围不同交通参与者(⽐如⾏⼈、⾃⾏⻋、⻋辆等)的动向,然后做出下⼀步的⻋辆控制(加速、减速、停⻋)。
这⾥特斯拉提到了两个个⾮常好的案例,可以让我们更好的理解特斯拉在这⼀块所做的⼯作。
第⼀个:
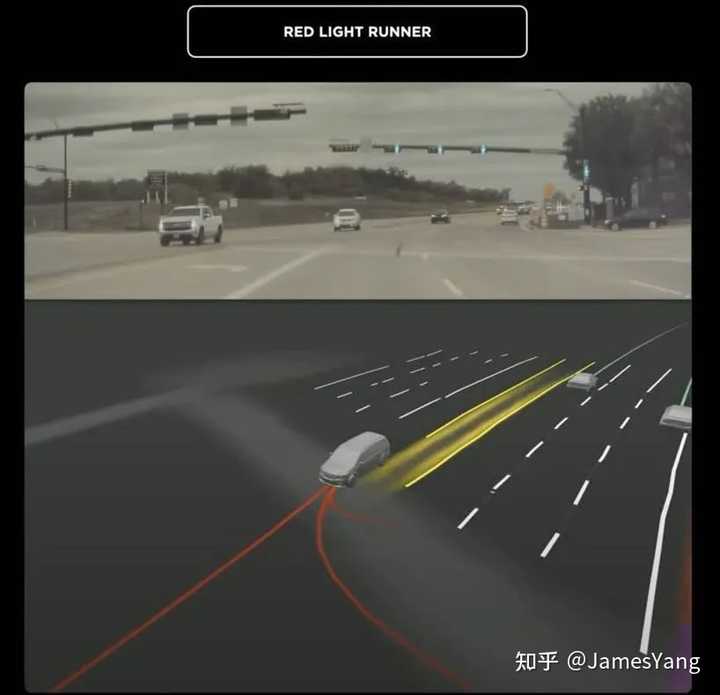

特斯拉正常⾏驶,遇到⼀辆⻋闯了红⻋并左转。
在这个过程中,特斯拉已经预测了这台⻋可能会做的所有动作,⽽后根据这台⻋接下来会做的不同动作,来决定⻋辆到底要采取怎样的动作。
第⼆个:
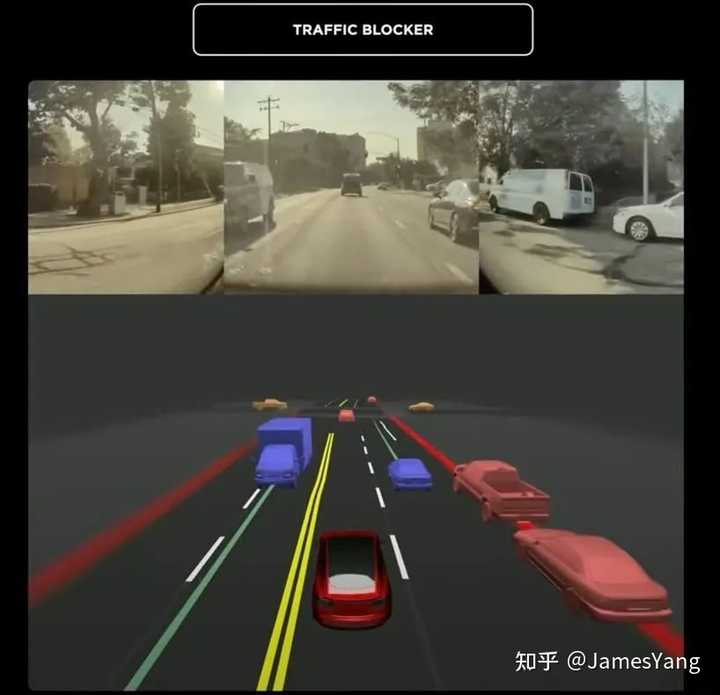



虽然前⽅都是红灯,但是本⻋道这台⻋不知道为何距离很远就停⻋了。
特斯拉并没有⾮常机械的停在该⻋后⾯,⽽是提前变道,转到了另⼀条⻋道上。
这个操作真的很细节,特斯拉FSD 在变得更⼈性化,给个好评。
特斯拉在试图建⽴⼀个实时系统,所以就需要最⼤限度地提⾼对象部分堆栈的帧速率,以便Autopilot 能够对不断变化的环境做出快速反应。在这⾥,每⼀毫秒都⾮常重要,以尽量减少推理的延迟。
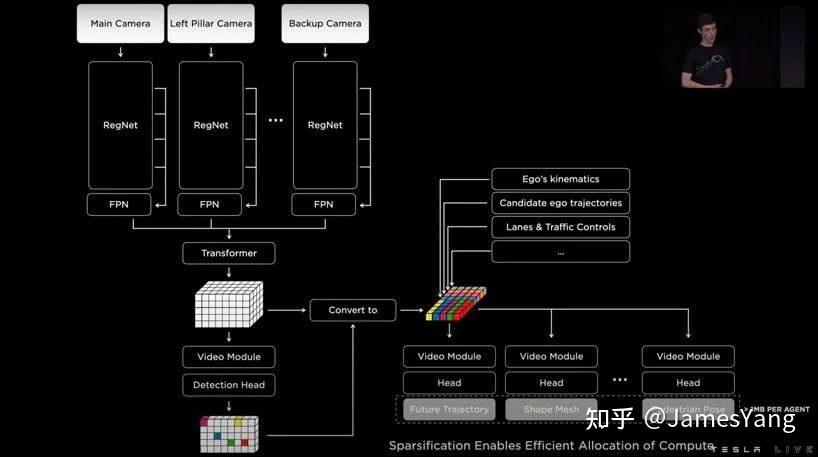

在这⾥,特斯拉神经⽹络运作分为两个阶段:第⼀阶段,确定三维空间中存在的物体的位置;第⼆阶段,在这些三维位置拉出张量,附加上⻋辆上的其他数据,然后再进⾏其余的处理。


这样,可以让神经⽹络将计算集中在最重要的区域上,从⽽以⼀⼩部分延迟成本提供更好的性能。
把它们放在⼀起,特斯拉的Autopilot 视觉堆栈不仅可以预测⼏何和运动,同时可以预测各种语义,让驾驶更安全。
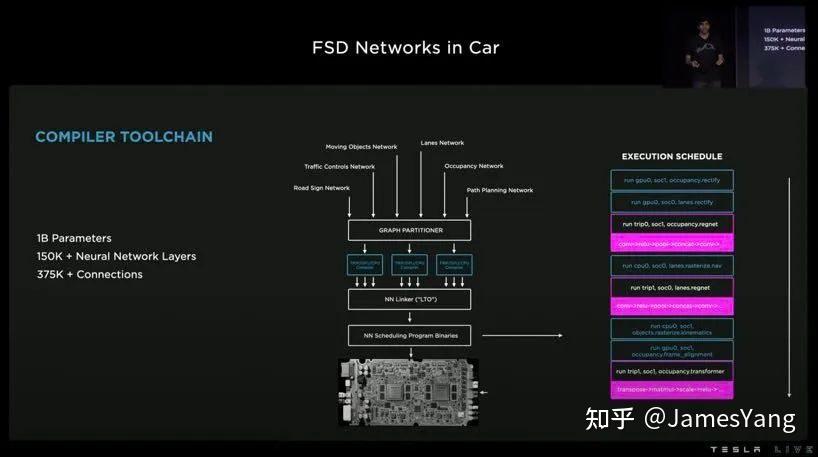
现在,FSD 道路⽹络已经在⻋上运⾏,同时特斯拉也做了很多⼯作:
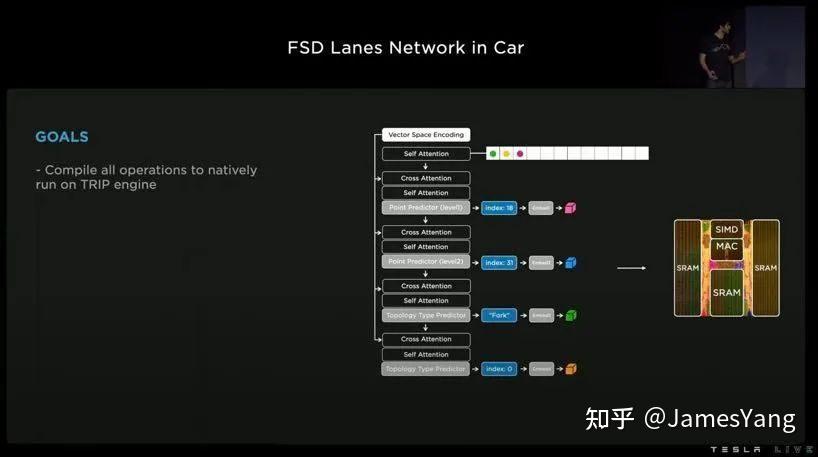

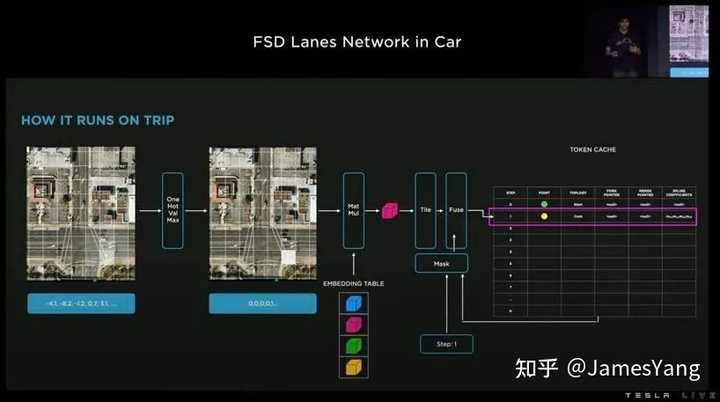



⽽且,现在在⻋上运⾏的不⽌有⻋道⽹络,还有移动物⽹络、占⽤⽹络、交通控制和路标⽹络、路径规划⽹络…..
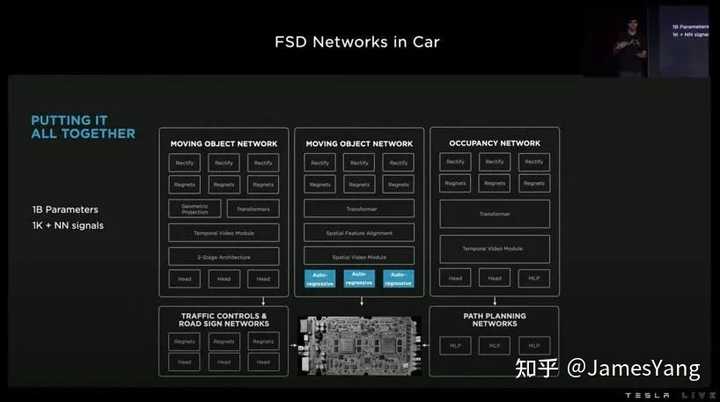

可能后续还会加⼊更多新的⽹络。
下⾯这张图就是在特斯拉⻋内的神经⽹络的可视化:


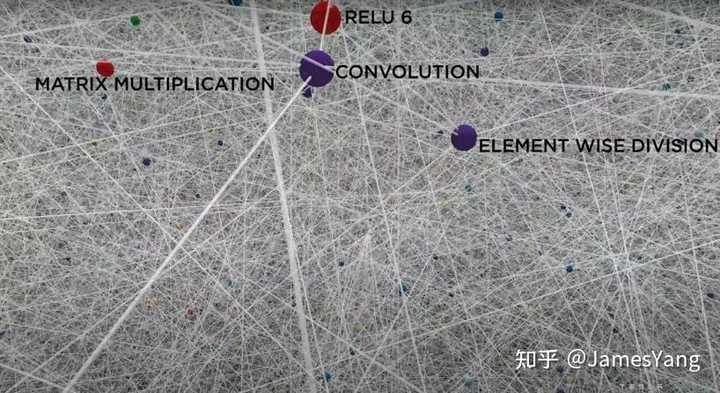

看着⾮常震撼。
特斯拉的这套东⻄,才算是真正的⾃动驾驶数字⼤脑。
与此同时,特斯拉也在优化延迟上做了不少⼯作:

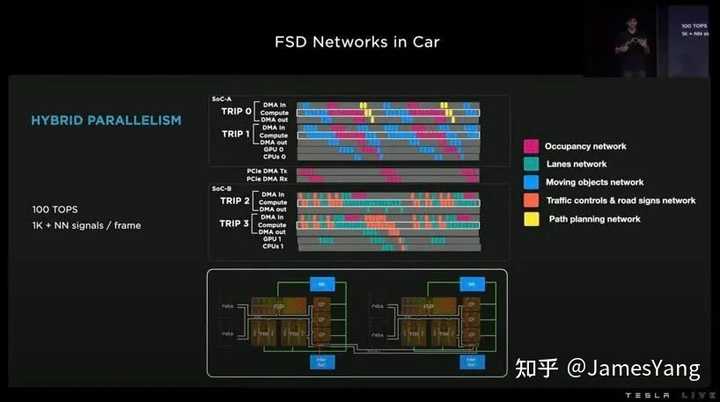

有了数量如此多的神经⽹络,就需要巨量的数据喂养。接下来且看看特斯拉在⾃动标注数据⽅⾯的进展。
06
自动标注
特斯拉有⼏种所有的标注框架来⽀持各种类型的⽹络。
以⻋道⽹为例,为了成功地训练和普及这个⽹络到各个地⽅,需要100万甚⾄更多交叉⼝出⾏数千万次的数据量。
不过,数据对于特斯拉来说不是问题,毕竟⻋源众多。但是⼀个新的挑战就是将所有这些数据转换成训练表格。
这⼏年,特斯拉尝试过多种数据标注⽅式:
如今,特斯拉在⽤的是新的⾃动标注技术,效率提升⾮常多。
此前10000 次⾥程标注,如果换⼿⼯贴标,需要500 万⼩时,现在只需要12 个⼩时就能搞定。
具体怎么做的呢?我们再再再次展开。主要分为三个步骤:
第⼀步,通过⻋身摄像头、视觉惯性测距法进⾏⾼精度的轨迹和结构恢复。所有的特征,包括地⾯都是通过神经⽹络从视频中推断出来的,然后在向量空间中进⾏跟踪和重建。


第⼆步:多重⾏程重构。这也是最核⼼部分。可以看到之前显示的⾏程是如何重建的,并与其他⾏程对⻬,⽽后实现重建。
然后,⼈类分析师进来并最终确定标签,每个步骤都已经在集群上完全并⾏化。所以整个过程通常只需要⼏个⼩时。


最后⼀步:⾃动标注新⾏程。只是在预先建⽴的重构和每个新⾏程之间,使⽤相同的多⾏程对⻬引擎。
因此,这⽐完全重建所有的⽚段要简单得多。
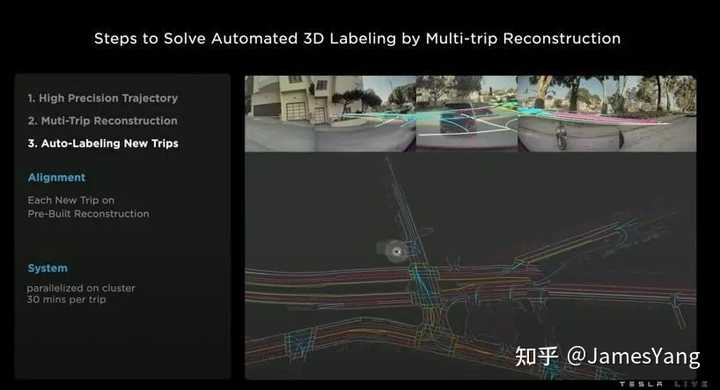

这也是这台机器可扩展性的关键。只要有可⽤的计算和⾏程数据,这台机器就能轻松扩展。
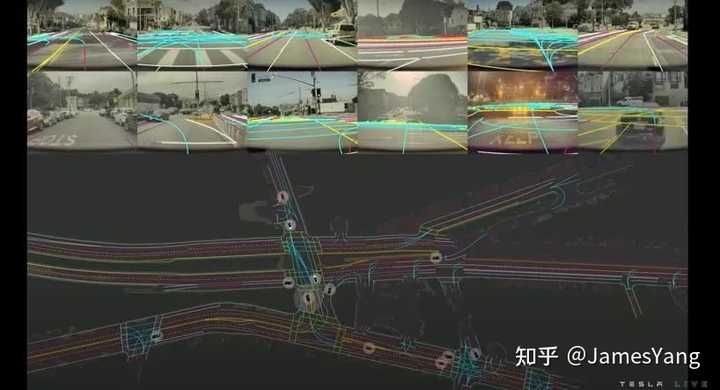

当然,⾃动标注不仅⽤在⻋道,还有规划、占⽤⽹络等,很多都是⾃动标注的。
07
仿真
对于⾃动驾驶来说,路测很重要,因为能接触到真实场景。
但是同样的,模拟仿真也是⾃动驾驶数据获得的重要途径和来源之⼀, 可以提供很多难以获得的数据。
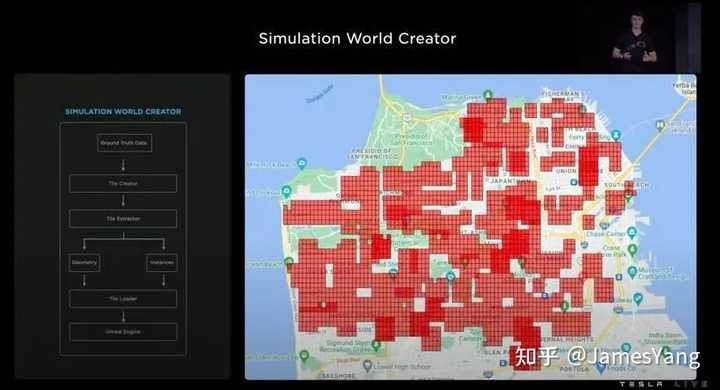
但是,3D 场景的制作是出了名的慢。以这个模拟场景为例,渲染师需要两周来构建,但是有了新的⼯具后,使得特斯拉可以在5 分钟内就完成类似场景的搭建,⽐之快了1000 倍。


⾸先,特斯拉会把⾃动化的地⾯真实标签输送到模拟世界创建⼯具中:


随后,⽣成道路⽹格,并⽤⻋道标签对其进⾏重新拓扑填充,其中包括各种重要道路信息,⽐如⼗字路⼝的坡度、材料等:




在路⾯上创造⻋道线:


然后是填充细节,⽣成植物以及楼房,与此同时,带来的还有由植物楼房等带来的视觉遮挡效果:


然后是交通信号的引⼊:
然后是路标以及⻋道指引线:


接下来加⼊⻋辆、⾏⼈等交通参与者:


只需要动动⼿指,特斯拉可以创造各种想要的仿真环境:






现在,特斯拉可以很容易地⽣成⼤部分的旧⾦⼭城市街道仿真:

08
写在最后
来个⼩结吧。
特斯拉在FSD 上今年展示了很多内容。
感知、规划、决策、控制以及仿真每⼀块都有不同进展和突破。

这次AI Day 让我们看到了特斯拉在替代激光雷达以及⾼精地图上所做的⼯作。
同时,随着新神经⽹络的加⼊,特斯拉FSD变得更聪明,同时驾驶上也更⼈性化。
⻢斯克表示:「⽬前FSD软件已经可以适⽤于全球各个地区的路况,如果地⽅监管政策允许,我们可以在今年年底⾯向全球推出FSD Beta 版本软件。」


10⽉5⽇,特斯拉宣布了「Tesla Vision」的新动向:取消超声波传感器。


两年前,特斯拉拿掉了毫⽶波雷达,现在,特斯拉对超声波传感器下⼿。
这样⼀来,特斯拉真就在纯视觉⾃动驾驶⼀条路⾛到⿊了。
特斯拉的纯视觉⾃动驾驶正在按着既定的⽬标逐渐推进。
最后⼀个问题:特斯拉能不能⽤纯视觉实现⾃动驾驶?这个问题我暂时⽆法回答。
我只能给你⼀个我看到的现状:当绝⼤部份的⻋企都转向激光雷达阵营,⽽特斯拉仍在纯视觉路线上做⼀个孤勇者和开拓者,为⾃动驾驶的实现提供更多的参考思路。


不是谁都敢赌上⾃⼰的前程去博⼀个不确定的明天,但是特斯拉敢。这份开拓创新的勇⽓,让⼈敬佩。
OK,以上就是这次特斯拉AI Day 关于FSD 的进展。
如果你觉得内容不错,欢迎⼀键三连,这对我的创作有很⼤的帮助。