用户操作日志模块如何开发?
17 个回答

首先,实名反对各答非所问和调侃的回答。
题主的提问非常详细,认真。实名赞扬题主提问。
事实上,这是一个非常不错的题目。该题目涉及软件架构设计与开发的多个方面,具有很强的通用性。研究好这个问题对于开发能力的提升很大。
今天有时间,我来解答一下这个问题。并且,最后还会附上实现代码。
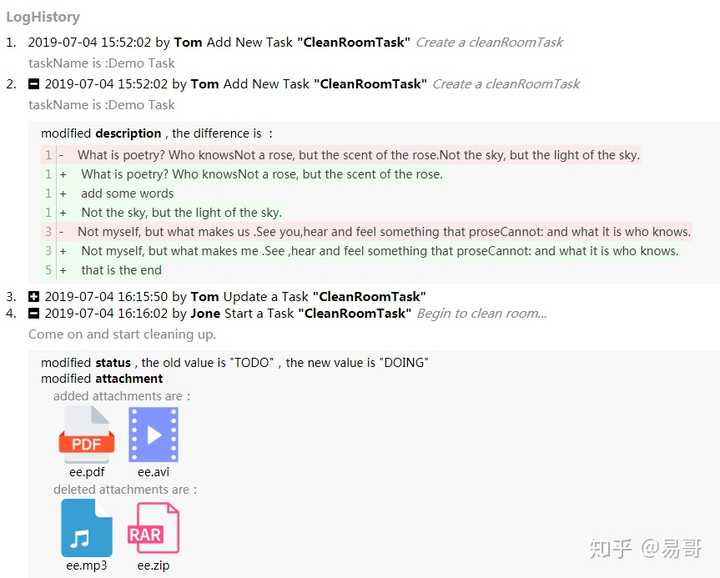
最终实现的效果如下所示:
实现的效果如下,这是实际截取的图:

我用尽可能用深入浅出的解答和实实在在的代码,支持每一个真诚的提问者。
整个回答不仅包含实现,还包括架构设计过程,会比较长。建议大家读完。
如果有不清楚的地方,大家可以在评论区提问。
整个解答包括问题定义、模型设计、方案设计、最终实现等多个环节。展现了系统架构设计的全部流程。
目录如下:
1 功能定义
2 模型设计
2.1 上层切面
2.2 下层切面
2.3 混合切面
3 对象属性对比功能实现
4 对象属性处理
4.1 普通属性
4.2 特殊属性
4.3 业务属性
5 易用性注解
6 存储设计
7 方案总结
8 系统实现

1 功能定义
在开发一个系统之前,我们先要对系统进行明确的定义。
在一个软件系统中,通常存在增删改查四类操作。对于日志系统而已,这四类操作的处理难度不同。
查询操作往往不需要记录日志,增加和删除操作涉及一个对象状态,编辑操作涉及对象编辑前和编辑后的两个状态。
编辑操作是整个日志模块中最难处理的。只要掌握了编辑操作,则新增操作、删除操作、查询操作都很简单了。因为,新增操作可以理解为null到新对象的编辑,删除操作可以理解为旧对象到null的编辑,查询操作可以理解为旧对象到旧对象的编辑。
因此,本文主要以编辑操作为例进行介绍。
为了便于描述,我们假设一个学校卫生大扫除系统。
这个系统中包含很多方法,例如分配大扫除工作的assignTask方法,开始某个具体工作的startTask方法,验收某个具体工作的checkTask方法,增加新的人员的addUser方法等。每个方法都有不同的参数,涉及不同的对象。
以startTask方法为例,开始一个任务需要在任务中记录开始时间、责任人、使用的工具,整个方法如下:
public String startTask(String taskId, Integer userId, Date startTime, Tool tool) {
// 业务代码
} 最简单的记录日志的方法便是在代码中直接根据业务逻辑写入日志操作语句,例如:
public String startTask(String taskId, Integer userId, Date startTime, Tool tool) {
// 业务代码
log.add("操作类型:开始任务。任务编号:" + taskId + ";责任人:" + userId ……);
// 业务代码
}如果你真的打算使用上述的方法记录日志,那已经没有什么可以教你的了。


你要做的就是提升自己Ctrl + C和Ctrl +V的速度,努力成为一个真正的CV大神直到顶级CRUD工程师。
而如果你想要设计一个较为专业、通用、易用的日志模块,那请继续向下阅读。我们必须从模型设计开始慢慢展开。
2 模型设计
设计系统的第一部是抽象,抽象出一个简单的便于处理的模型。
我们可以把用户操作抽象为下面的模型,即用户通过业务逻辑修改了持久层中的数据。
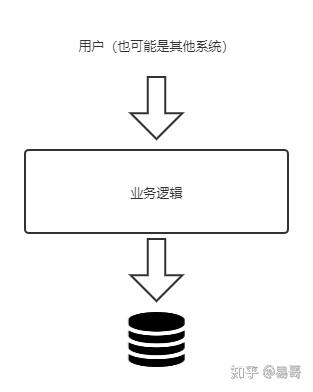

要想记录日志,那我们需要在整个流程中设置一道切面,用以获取和记录操作的影响。
而这一道切面的位置十分关键,我们下面探讨这一点。本章节的探讨与讨论一个问题:单一切面能否实现用户操作日志的记录。
- 如果使用单一的切面能实现日志记录功能,那就太好了。这意味着我们只要在系统中定义一个日志切面,则所有的用户操作都会被记录。
- 而如果单一的切面无法做到,那我们的日志操作就需要侵入业务逻辑。
在展开讨论之前要注意,这里只是模型设计,请忽略一些细节。例如,参数是英文变量名,不便于表意;某些参数是id,与系统强耦合等。这些都不是模型层需要考虑的,我们会在后续的设计中解决这些问题。
2.1 上层切面
首先,我们考虑在整个业务逻辑的最上层设置切面如下图所示:
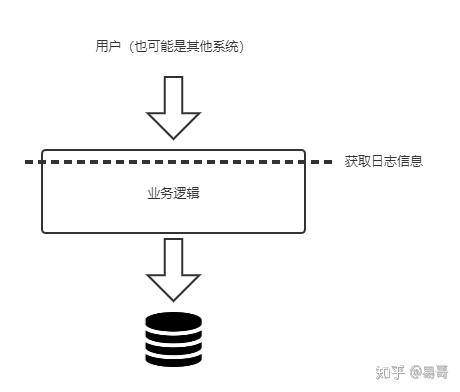

这一层其实就是业务逻辑入口处,以下面的方法为例:
public String startTask(String taskId, Integer userId, Date startTime, Tool tool) {
// 业务代码
} 我们可以得到的日志信息有:
startTask:方法的名称
- taskId:方法的参数名,及其对应的参数值,例如15
- userId:方法的参数名,及其对应的参数值,例如3
- startTime:方法的参数名,及其对应的参数值,例如 2019-12-21 15:15
- tool:方法的参数名,及其对应的参数值,例如14可见这些信息的特点是贴近业务逻辑。因为startTask表明了我们要进行的业务逻辑的操作类型,而后面的操作参数则表明了业务逻辑的参数。
然而缺点也很明显:
- 首先,无法获得编辑前的旧对象。即我们不知道startTask执行前task对象的状态。
- 其次,它不能反映真正的数据变动。这一点是致命的。
好,我们接下来说明一下第二点。
因为我们是上层切面,从入参处获取信息。但是,入参的信息却不一定是最终持久化的信息。假设方法中存在下面的业务逻辑:
public String startTask(String taskId, Integer userId, Date startTime, Tool tool) {
// 其他业务代码
while(taskBusiness.queryByTaskId(taskId).isFinished()) {
taskId++;
}
if(userBusiness.queryByUserId().isLeave()) {
return "任务启动失败";
}
// 其他业务代码
}则上层切面获得的taskId信息可能是无效的,甚至,整个操作都是无效的。
因此,上层切面的特点是:贴近业务逻辑、不能反映真实数据变动。
因此,上层切面无法直接采用。
2.2 下层切面
下层切面就是在业务逻辑的最下层设置切面,如下图所示:
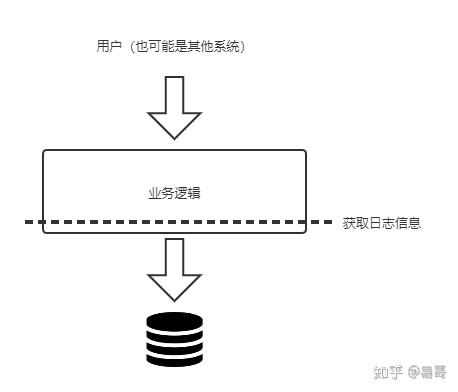

这一层其实就是在持久层获取日志信息。
startTask方法可能在持久层对应了下面的update操作:
updateTask(TaskModel taskModel); // 该方法对应了MyBatis等工具中的SQL语句通过这个方法可以得到的日志信息有:
updateTask:
- taskId
- userId
- startTime
- toolId
- taskName
- taskDescription首先,以上信息是准确的。因为这些信息是从写入持久层的操作中获取的,例如从SQL语句的前一步获取。这里面的taskId、userId等值可能和入参的值不一样,但一定是准确的。
但是,它仍然存在两个问题:
- 首先,无法获得编辑前的旧对象。同上。
- 其次,它脱离业务逻辑。
我们还是主要说明一下第二点,例如,日志信息中的updateTask反应了这是一次任务编辑操作,但是任务编辑操作是很多的:assignTask、startTask、checkTask、changeTaskName等不同的业务操作可能都会映射为一次SQL操作中的update操作。在这里,我们无法区分了。
并且,编辑操作一般写的大而全,例如常写为下面的形式:
<update id="updateTask">
UPDATE task
<set>
<if test="userId!=null">userId= #{userId},</if>
<if test="startTime!=null">startTime= #{startTime},</if>
<if test="toolId!=null">toolId= #{toolId},</if>
<if test="taskName!=null">taskName= #{taskName},</if>
<if test="taskDescription!=null">taskDescription= #{taskDescription},</if>
</set>
where taskId= #{taskId}
</update>当我们调用updateTask方法时,task对象的各个属性都会被传入。但是这些属性中,有很多并没有发生变动,是没有必要被日志系统记录的。
可见,下层切面的特点是:反映真实数据变动,脱离业务逻辑。
因此,下层切面无法直接采用。
2.3 混合切面
上层切面和下层切面都不能单独使用,这意味着我们不可能使用一个简单的切面完成日志操作。
我想,这也是题主提问的原因,如果是一个切面能够解决的问题,就不用这样来提问了。
那最终怎么解决呢?
使用混合“切面”,即吸收下层切面的准确性、整合上层切面的业务逻辑信息,并顺便解决旧对象的获取问题。对“切面”加引号是因为这不是一个绝对纯粹的切面,它对业务逻辑存在一定的侵入性。但这是没有办法的。
我们需要在业务逻辑中增加一行类似下面的代码:
logClient.logXXX(params...); 至于这行代码如何写,后面的逻辑如何,我们后面细化。但是我们知道,这行代码中传入的参数要既包含上层信息也包含下层信息。
以下层信息为主(因为它准确),以上层信息为辅(因为它包含业务信息)。如下图所示。
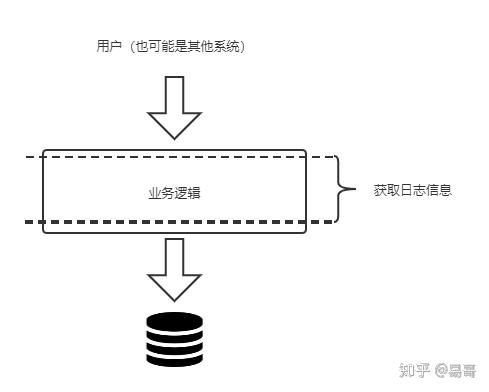

接下来我们会一步一步介绍其实现。
3 对象属性对比功能实现
我们说道在下面方法中,获得的信息以下层信息为主,以上层信息为辅。
那我们先说下层信息,显然就是数据库中的老对象和修改后的新对象,因此,其入参形式如下:
logClient.logObject(oldObject,newObject); 而在处理日志的第一步,就是找出新对象和老对象之间属性的不同。
假设tool对象的属性如下:
- toolId:编号
- toolName:工具名称
- price:价格
- position:存放位置
要想把新旧两个tool对象的属性不同找出来,可以使用类似下面的代码。
// 对比工具的名称toolName
if(!oldTool.getToolName().equals(newTool.getToolName())) {
log.add("toolName",diff(oldTool.getToolName(),newTool.getToolName()));
}
// 对比工具的价格price
if(!oldTool.getPrice().equals(newTool.getPrice())) {
log.add("toolPrice",diff(oldTool.getPrice(),newTool.getPrice()));
}
// 依次对比工具的各个其他属性这种代码可以实现功能,但是……仅仅适用于tool对象。
如果换成了task对象,则又要重新写一套。假设task对象的属性如下:
- taskId:编号
- userId:责任人编号
- startTime:开始时间
- toolId:需要的工具的编号
- taskName:任务名
- taskDescription:任务描述
那是不是只能根据task对象的属性再写一套if……
如果你真的就是打算使用上述的方法记录日志,那我已经没有什么可以教你的了。


你要做的就是提升自己Ctrl + C和Ctrl +V的速度,努力成为一个真正的CV大神直到顶级CRUD工程师。
日志模块的使用场景不同,要处理的对象(即oldObject和newObject)千奇百怪。因此,上面的这种代码显然也是不可取的。
所以说,我们要自动分析对象的属性不同,然后记录。即将对象拆解开来,逐一对比两个对象(来自同一个类)的各个属性,然后将不同的记录下来。
显然,要用反射。
那这个问题就解决了,如果对反射不了解的,可以学习反射相关知识。这些比较基本,我就不赘述了。
使用反射之后,我们要记录新老对象的变动则只需要如下调用:
logClient.logObject(oldObj,newObj); 然后在这个方法中采用反射找出对象的各个属性,然后依次进行比对。其实现代码如下:
/**
* 比较两个任意对象的属性不同
* @param oldObj 第一个对象
* @param newObj 第二个对象
* @return 两个对象的属性不同
*/
public static Map<String, String> diffObj(Object oldObj, Object newObj) {
Map<String, String> diffMap = new HashMap<>();
try {
// 获取对象的类
Class oldObjClazz = oldObj.getClass();
Class newObjClazz = newObj.getClass();
// 判断两个对象是否属于同一个类
if (oldObjClazz.equals(newObjClazz)) {
// 获取对象的所有属性
Field[] fields = oldObjClazz.getDeclaredFields();
// 对每个属性逐一判断
for (Field field : fields) {
// 使得属性可以被反射访问
field.setAccessible(true);
// 拿到当前属性的值
Object oldValue = field.get(oldObj);
Object newValue = field.get(newObj);
// 如果某个属性的值在两个对象中不同,则进行记录
if ((oldValue == null && newValue != null) || oldValue != null && !oldValue.equals(newValue)) {
diffMap.put(field.getName(), "from " + oldValue + " to " + newValue);
}
}
}
} catch (Exception ex) {
ex.printStackTrace();
}
return diffMap;
}这样,下层的新老对象信息就处理完成了。
我们可以在方法中通过参数补充一些上层业务信息。因此,上述方法可以修改为:
logClient.logObject("操作方法", "操作方法别名","触发该操作的用户 等其他信息", oldObj, newObj); logObject方法就是我们要实现的方法,其核心操作逻辑就是分析对比新对象和旧对象的不同,将不同记录下来,作为此次操作引发的变动。
4 对象属性处理
我们已经介绍了实现新旧对象属性比对的基本实现逻辑,但是一切并没有这么简单。因为,对象的属性本身就非常复杂。
例如,有些属性(例如userId)是对其他对象的引用,把它们写入日志会让人觉着摸不着头脑(例如应该换成用户姓名或工号);有些属性(例如富文本)则十分复杂,在写入日志前需要进行特殊的处理。
在这一节,我们将介绍这些特殊的属性处理逻辑。
4.1 普通属性
当我们比较出新老对象的属性时,有一些属性可以直接计入日志。
直接记录为“从{oldValue}修改为{newValue}”的形式即可。
例如,tool对象的价格,可以计入为:
price:从47修改为51其中47是属性的旧值,51是属性的新值。
4.2 特殊属性
但是有一些属性不可以,例如长文本。我们采用新值旧值的形式记录其变动是不合理的。例如:
description:从“今天天气好\n真好\n哈哈嘿嘿哈哈”修改为“今天天气好\n哈哈嘿嘿哈哈” 这种形式显然很难看、很难懂。
我们想要的结果应该是:
description:删除了第2行“真好” 这时,我们可以设置一种机制,对复杂文本的属性进行特殊的处理。最终得到下面的结果。
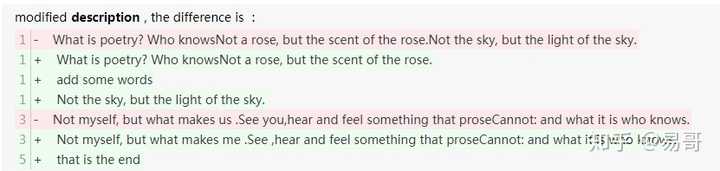

这样一来,效果是不是好多了。
在具体实现上,我们可以使用注解来标明一个属性的值需要特殊处理的类型,如下:
@LogTag(innerType = InnerType.FullText)
private String description; 这样,我们在日志模块设计机制,识别出InnerType.FullText的属性后使用富文本处理方式对其进行新旧值的比对处理。
当然,这种机制不仅仅适用于富文本,还有一些其他的属性,例如图片。我们可以引用新旧图片的地址进行展示。
4.3 业务属性
还有一种属性,更为特殊。task对象中的责任人。我们采用下面的方式记录显然不太友好:
userId:从4修改为5在task对象的userId属性中存放的是用户编号, 4、5都是用户编号。但在日志中我们更希望看到人员姓名。
可是用户编号到姓名信息日志模块是没有的。
因此,这时候我们需要业务模块实现日志模块提供的接口,来完成上述映射。得到如下结果:
userId:从“王二丫”修改为“李大笨”不只是userId,还有toolId等各种业务属性也适用这种处理方式。
这样处理还带了一个优点:解耦。
当一个日志系统记录下某个日志时,例如,记录下“小明删除了文件A”时,即使业务系统将小明的userId和小李的userId互换,则日志系统也不能将日志变为“小李删除了文件A”。因此,日志系统中的数据应该是一经落库立刻封存。
在具体实现上,我们可以使用注解来标明一个属性的值需要由业务系统辅助处理,如下:
@LogTag(extendedType = "userIdType")
private int userId; 这样,我们在日志模块设计机制,识别出userId属性后使用userIdType处理方式调用业务模块提供的接口对其进行新旧值的比对处理。
5 易用性注解
经过上面的处理,我们已经能够拿到类似下面的日志结果:
userId:从“王二丫”修改为“李大笨”
description:删除了第2行“真好”
price:从47修改为51其形式已经不错了。
但是这里的userId、description、price是一个属性名,当给用户展示时,用户并不知道其确切含义。
因此,我们需要提升其易用性。
在具体实现上,我们可以使用注解来标明一个属性的值需要由业务系统辅助处理,如下:
@LogTag(alias = "责任人", extendedType = "userIdType")
private int userId;
@LogTag(alias = "说明",innerType = InnerType.FullText)
private String description;
@LogTag(alias = "价格")
private double price; 然后在日志模块中,我们对注解进行处理,可以得到下面形式的日志信息:
责任人:从“王二丫”修改为“李大笨”
说明:删除了第2行“真好”
价格:从47修改为51这样,整个日志的输出形式就比较友好了。
6 存储设计
获取了对象的不同之后,我们应该将其存储起来。显然,最简单的:
CREATE TABLE `log` (
`objectId` varchar(500) NOT NULL DEFAULT '',
`operationName` varchar(500) NOT NULL,
`diff` varchar(5000) DEFAULT NULL
);这样就记录了objectId的对象因为operationName操作发生了diff的变动。
然后把下面的文字作为一个完整的字符串存入diff字段中。
责任人:从“王二丫”修改为“李大笨”
说明:删除了一行“真好”
价格:从47修改为51如果你真的打算使用上述的方法记录日志,那我已经没有什么可以教你的了。
没,开玩笑。这个不至于,因为这个只是考虑不全面导致的个小问题。
我们不能使用diff就简简单单地将各个属性杂糅在一起,将原本结构化的数据变为了非结构化的数据。
我们可以采用操作表+属性表的形式来存储。一次操作会操作一个对象,这些都记录到操作表中;这次操作会变更多个属性,这些都记录到属性表中。
进一步,我们可以在操作表中记录被操作对象的类型,这样,防止不同对象具有相同的id而混淆。而且,我们还可以设置一个appName字段,从而使得这个日志模块可以供多个应用共用,成为一个独立的日志应用。我们也可以在记录操作名“startTask”的同时记录下其别名“开始任务”,等等。从而全面提升日志模块的功能性、易用性。
同样的,属性表中我们可以记录各个属性的类型,便于我们进行分别的展示。记录属性的旧值、新值、前后变化等。
不多说了,我直接给出两个表的DDL:
-- ----------------------------
-- Table structure for operation
-- ----------------------------
DROP TABLE IF EXISTS `operation`;
CREATE TABLE `operation` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`appName` varchar(500) DEFAULT NULL,
`objectName` varchar(500) NOT NULL DEFAULT '',
`objectId` varchar(500) NOT NULL DEFAULT '',
`operator` varchar(500) NOT NULL,
`operationName` varchar(500) NOT NULL DEFAULT '',
`operationAlias` varchar(500) NOT NULL DEFAULT '',
`extraWords` varchar(5000) DEFAULT NULL,
`comment` mediumtext,
`operationTime` datetime NOT NULL,
PRIMARY KEY (`id`),
KEY `appName` (`appName`) USING HASH,
KEY `objectName` (`objectName`) USING HASH,
KEY `objectId` (`objectId`) USING BTREE
);
-- ----------------------------
-- Table structure for attribute
-- ----------------------------
DROP TABLE IF EXISTS `attribute`;
CREATE TABLE `attribute` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`operationId` bigint(20) unsigned NOT NULL,
`attributeType` varchar(500) NOT NULL DEFAULT '',
`attributeName` varchar(500) NOT NULL DEFAULT '',
`attributeAlias` varchar(500) NOT NULL DEFAULT '',
`oldValue` mediumtext,
`newValue` mediumtext,
`diffValue` mediumtext,
PRIMARY KEY (`id`),
KEY `operationId` (`operationId`) USING BTREE
);这样,可以完整地保存日志操作及这次操作引发的属性变动。
7 方案总结
整个日志模块的概要设计就完成了。
我直接画了一个简化的处理流程图:
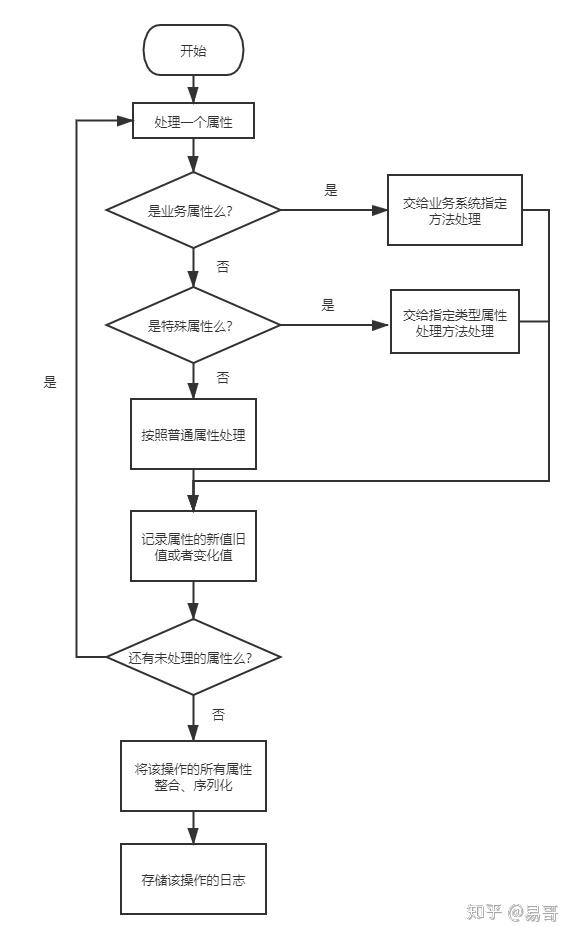

不过,篇幅所限,有一些细节没能涉及到,包括注解的处理、业务操作接口的预留、日志的序列化与反序列化等。这都是小问题。大的设计概要有了,这些小问题不难解决。
8 系统实现
为了支持题主,也为了表明我不只是扯。
也为了更清晰地表达没能在设计方案中介绍的注解的处理、业务操作接口的预留、日志的序列化与反序列化等问题。
虽然比较忙,但是说到做到。实现了上文设计的日志模块。


而且!!!
还开源了!!!
地址如下,大家自行取用阅读:
供大家参考。
感谢老铁!
有开发者在我的日志模块基础上开发了React的前端组件!并独立出了一个开源前端项目!
可以和我写的日志模块无缝衔接做日志展示!
实现的效果如下:
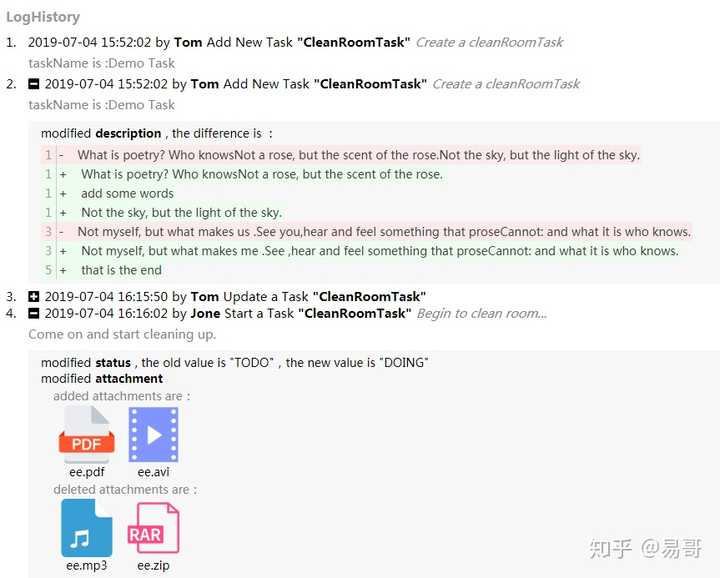

真有才!真漂亮。
具体实现代码、使用配置,大家去这个项目的README看吧,我好好维护,尽量写的全面一点。
大家有什么意见建议也可以去开源项目页面提issue。
最后,这是个好题目。
不过相比于我的其他回答,这个干货回答反而点赞少。
点赞少,我也会一直维护和更新。
也可以关注我,比较忙,但是我会偶尔出没解答架构设计和编程问题。

耦合程度较低的方案:
- 通过DB的操作日志采集,如MySQL的binlog,用maxwell或者阿里开源的组件采集,然后logstash处理一下发送到es;如果有事务的话,maxwell会输出事务的id;
- 如果系统中除了db,还用了redis之类的存储,可以使用应用层日志采集。类似微服务里面常用的trace方案,每个用户的请求有个唯一id作为标识,然后在各微服务之间传递。然后分别把用户请求、造成的影响通过结构化日志(一般是json)打印出来。然后通过EFK/loki存起来,就可以了。或者用OpenTelemetry/skywalking这种实时传输的方案(尤其是java/python这种可以自动注入的语言),效果更好,不过会有一些性能影响。
并不建议在应用层直接处理日志,除非应用规模很小,比如简单的web服务;也不建议在DB里面直接存储用户操作日志,稍微有点用户规模,数据膨胀的速度就让DB无法承受。