怎么用通俗的语言解释断点回归?它与DID的区别是什么
5 个回答

RD的目的是选取其他特征相似的组,考察临界值区间上下不同
例如,考察进入清华与否对于收入的影响。 考试成绩为687的人无法上清华大学,而考试分数为689的人课可以进去。仅仅2分之差,这两类人的基本能力其实没什么差别。 两组人,围绕着688分的分界线,对于研究工资差异都具有较高的内部效度,因为两者之间的唯一区别是是否进入清华。其他一切都是不变的。
把这个理念延伸一下 控制其他变量,数据分为1)688以下, 2)688以上两组。 回归拟合线应该斜率相近, 但是截距有明显差别,截距项可以理解为入学带来收入差异。
DID的目的是比较两组存在差异的群体,但是该差异的影响必须是随着时间变化是恒定的。
比如处理前A2010 ,处理后A2020; 处理前 B2010,处理后 B2020.
所以(A2010 - B2010 )=m 就是所谓的first difference. 这里m就是A和B组预先存在的差别。 然后( A2020 - B2020)=n , 这里就是second difference, 其中n包含了处理的效应Treatment 和预先差别m,最后, n-m= treatment效果。 这就是difference in difference.
RD需要数据更少,主要是考虑临界值附近的影响。 DID需要panel data面板数据,并且更容易广泛使用。

RD
在 RD 方法中,所有单位都拥有一个 “得分”,并且得分值高于某个断点的个体接受处理。这一设计的最大特点在于接受处理的概率在门槛值处急剧变化。具体来看,RD 的特征如下:
- RD 具有三个明显的特征:得分、断点和处理;
- RD 的主要特征是处理分组在断点处为得分的分段函数,这一条件是可以直接验证的,除此之外,还有很多证伪检验和相关经验来提高可信度;
- 除了上述特征,一般的解释、估计和推断也需要一些额外的假设。首先,我们需要定义参数及其识别条件;其次,必须施加假设以保证参数可估计,主要的框架有两类,分别是连续性假设和局部随机化假设。
精确断点回归设计
在 RD 中,每个个体拥有一个得分 (或称为驱动变量 running variable, 或指标 index),并且处理取决于得分是否高于断点。
引入一些符号,假设有 n 个个体,使用 i=1,2,3, \cdots, n 标注,每个个体的得分表示为 X_{i}, c 是一个已知的断点。当 X_{i} \geq c 时, 个体接受处理,否则不接受处理。处理状态可以表示为 T_{i}=\mathbb{I}\left(X_{i} \geq c\right), 该形式为示性函数。因此, 知道 个体得分,就知道个体处理状态,即处理的概率是得分的函数。
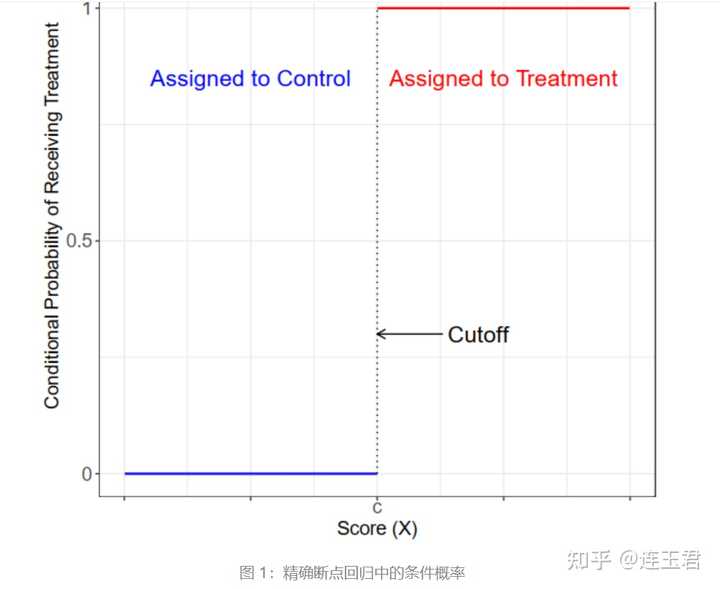
但是满足处理条件并不意味着实际受到了处理。当处理条件与实际受到处理的情形一致时,我们称之为精确断点回归 (Sharp RD) 设计,否则称之为模糊断点回归 (Fuzzy RD)。图 1 描述了精确断点回归设计的处理规则,即在断点附近, 受到 处理的概率从零跳跃至 1 。

DID
DID 使用了面板数据,估计面板数据的最常用的模型是双向固定效应模型,对于面板模型的设定。在双向固定效应模型的基础上, 传统 DID 模型加入了处理组虛拟变量 (treat \left._{i}\right) 与处 理期虛拟变量 (post _{t} ) 的交乘项,模型设定如下:
y_{i, t}=\alpha+\mu_{i}+\lambda_{t}+\theta \text { treat }_{i} \times \text { post }_{t}+\beta \mathbf{x}_{\mathbf{i}, \mathrm{t}}+\epsilon_{i, t}(1) \\
其中, y_{i, t} 为因变量; i(i=1, \cdots, N) 表示个体; t(t=1, \cdots, T) 表示时间; \mu_{i} 表示个体固定效应; \lambda_{t} 表示时间固定效 应; \mathbf{x}_{\mathbf{i}, \mathrm{t}} 表示随时间和个体变化的控制变量; \beta 是控制变量的系数; \epsilon_{i, t} 为模型误差项。
treat _{i} 为处理组虛拟变量,若个体 i 属于受到政策冲击 (这里以估计政策实施效果为例进行说明) 的"处理组",则取值为 1; 若个体 i 属于未受到政策冲击的"控制组",取值为 0 。 post _{t} 为处理期虛拟变量,处理组的个体也只有到了处理期才会 受到政策冲击 (之前未受到冲击),若个体 i 进入处理期取值为 1 ; 否则, 取值为 0。
值得注意的是,模型中不需要加入处理组虛拟变量 \operatorname{treat}_{i}, 是因为模型中加入了个体固定效应 \mu_{i}, \mu_{i} 包含更多信息,是 控制了个体层面不随时间变化的特征, 而 treat _{i} 仅控制了组别层面不随时间变化的特征,若二者同时加入会产生多重共线 性问题。同样的,模型中也不需要加入处理期虛拟变量 post _{t}, 因为模型中加入了时间固定效应 \lambda_{t}, \lambda_{t} 包含更多的信息, 是控制了每一期的时间效应, 而 p o s t_{t} 仅控制了处理期前后的时间效应, 若二者同时加入会产生多重共线性问题.
参见连享会推文:
相关推文
Note:产生如下推文列表的 Stata 命令为:. lianxh RD DID. songbl RD DID
安装最新版lianxh/songbl命令:. ssc install lianxh, replace. ssc install songbl, replace
- 专题:断点回归 RDD
- RDD 断点回归:多个断点多个分配变量如何处理
- Stata+R:一文读懂精确断点回归-RDD
- RDD:离散变量可以作为断点回归的分配变量吗?
- rddensity, lpdensity 无法安装?那就手动安装
- RDD:断点回归可以加入控制变量吗?
- 断点回归 RDD:样本少时如何做?
- Stata:断点回归分析-RDD-文献和命令
- Stata:两本断点回归分析-RDD-易懂教程
- Stata:RDD-中可以加入控制变量
- Stata:时间断点回归 RDD 的几个要点
- Stata:断点回归分析-(RDD)-文献和命令
- Stata:断点回归 RDD 简明教程
- RDD:断点回归的非参数估计及 Stata 实现
- Stata: 两本断点回归分析 (RDD) 易懂教程
- Stata: 断点回归 (RDD) 中的平滑性检验
- Stata 新命令:多断点 RDD 分析 - rdmc
- RDD 最新进展:多断点 RDD、多分配变量 RDD
- 专题:内生性-因果推断
- 专题:Stata命令
- 专题:倍分法DID
- 倍分法:交错DID与Stata操作
- Stata倍分法新趋势:did2s-两阶段双重差分模型
- Stata倍分法:全国一刀切的DID
- Stata-DID:不同处理时点不同持久期的倍分法(flexpaneldid)
- 队列DID:以知识青年“上山下乡”为例-T401
- DID功效计算中的序列相关问题-T407
- 多期DID文献解读:含铅汽油与死亡率和社会成本-L113
- DID陷阱解析-L111
- 面板PSM+DID如何做匹配?
- 倍分法:DID是否需要随机分组?
- Fuzzy DID:模糊倍分法
- DID:仅有几个实验组样本的倍分法 (双重差分)
- 考虑溢出效应的倍分法:spillover-robust DID
- tfdiff:多期DID的估计及图示
- 倍分法DID:一组参考文献
- Stata:双重差分的固定效应模型-(DID)
- 倍分法(DID)的标准误:不能忽略空间相关性
- 多期DID之安慰剂检验、平行趋势检验
- DID边际分析:让政策评价结果更加丰满
- Big Bad Banks:多期 DID 经典论文介绍
- 多期DID:平行趋势检验图示
- Stata:多期倍分法 (DID) 详解及其图示
- 倍分法DID详解 (一):传统 DID
- 倍分法DID详解 (三):多时点 DID (渐进DID) 的进一步分析