如何理解 95% 置信区间?
136 个回答

很多答案当中用关于真值的概率描述来解释置信区间是不准确的。我们平常使用的频率学派(frequentist)95% 置信区间的意思并不是真值在这个区间内的概率是 95%。真值要么在,要么不在。由于在频率学派当中,真值是一个常数,而非随机变量(后者是贝叶斯学派) ,所以我们不对真值做概率描述。对于这个问题来说,理解的关键是我们是对这个构造置信区间的方法做概率描述,而非真值,也非我们算得的这个区间本身。
换言之,我们可以说,如果我们重复取样,每次取样后都用这个方法构造置信区间,有 95% 的置信区间会包含真值 (*)。然而(在频率学派当中)我们无法讨论其中某一个置信区间包含真值的概率。
实际上,在特定的情形中 (^) 我们甚至可以直接断定一个参数不在一个 95% 置信区间中,即使我们构造这个区间的方法完全正确。这更说明我们不能说参数在某一个区间内的概率是多少。
只有贝叶斯学派才会说某个特定的区间包含真值的概率是多少,但这需要我们为真值假设一个先验概率分布(prior distribution)。这不适用于我们平常使用的基于频率学派的置信区间构造方法。
更多的解释可以参考:
https://en.wikipedia.org/wiki/Confidence_interval#Misunderstandings评论里的补充解释:
换种方法说,假设我们还没有取样,但已经制定好取样后构造 95% 置信区间的方法。我们可以说取样一次以后,获得的那个置信区间(现在还不知道)包含真值的概率是 95%。然而在取样并得到具体的一个区间之后,在频率学派框架下就无法讨论这个区间包含真值的概率了。
取样前能讨论,取样后却无法讨论,这可能让很多人感到很不自然。扩大来说,传统频率学派对已经发生,但我们不知道结果的事件的讨论存在困难。虽然这个问题通常在应用上无伤大雅,但确实有不少学者因此寻求对概率的不同解释。
______________________
* 也许你会说这么描述就相当于说某个置信区间包含真值的概率是 95%。那我只能说你必须寻求频率学派以外的对概率的解释。这是一个很深奥的哲学问题:)
^ 参见
http://stats.stackexchange.com/questions/26450/why-does-a-95-ci-not-imply-a-95-chance-of-containing-the-mean中的回答

置信区间,就是一种区间估计。
先来看看什么是点估计,什么是区间估计。
1 点估计与区间估计
以前很流行一种刮刮卡:

游戏规则是(假设只有一个大奖):
- 大奖事先就固定好了,一定印在某一张刮刮卡上
- 买了刮刮卡之后,刮开就知道自己是否中奖
那么我们起码有两种策略来刮奖:
- 点估计:买一张,这就相当于你猜测这一张会中奖
- 区间估计:买一盒,这就相当于你猜测这一盒里面会有某一张中奖
很显然区间估计的命中率会更高(当然费用会更高,因为风险降低了)。
接下来,我们看看置信区间是如何进行区间估计的。
2 置信区间
我们通过对人类身高的估计来讲解什么是置信区间。
2.1 上帝视角
对于人类真实的平均身高,我们是没有办法知道的,因为几乎不可能把每个人都统计到。
但这个数据肯定是真实存在的,我们可以说,上帝知道。
在这里我们引入了上帝视角,即上帝看到的人类身高的真实分布。
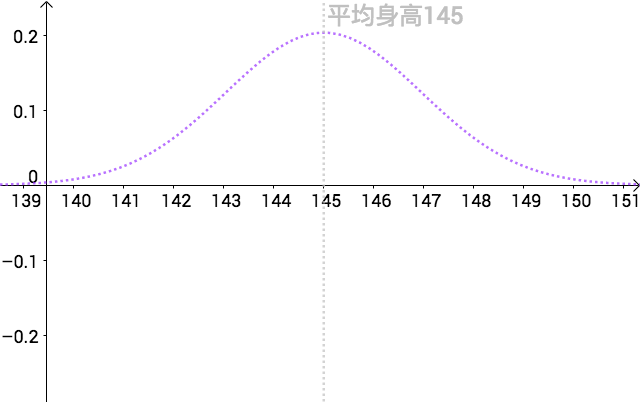
假设人类的身高分布服从如下正态分布( \mu =145,\sigma =1.4 ):
X \sim N(145, 1.4^2)\\
也就是说全体人类的平均身高为145cm,为了表示只有上帝可以看到,我把真实分布用虚线来表示:

2.2 点估计
作为愚蠢的人类,我们只能在人群中抽样统计:

比如下面是一次抽样数据,我把算出来的样本均值(记作 \hat{\mu } )画在图上(蓝色的点):
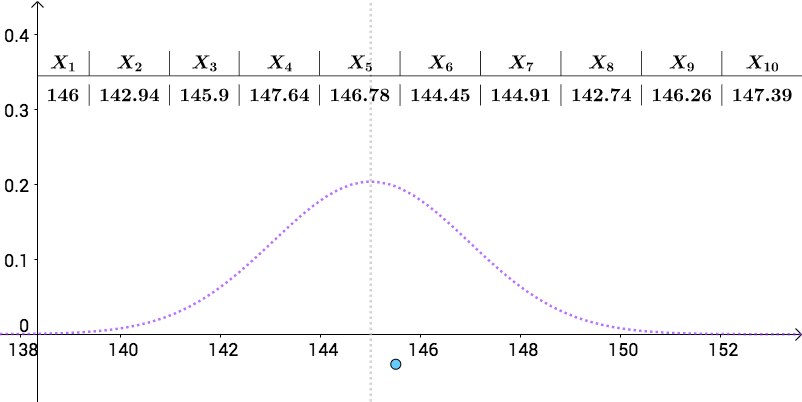

\hat{\mu } 就是对真实的 \mu 的一次点估计。
通过一次次的抽样,我们可以算出不同的身高均值的点估计:
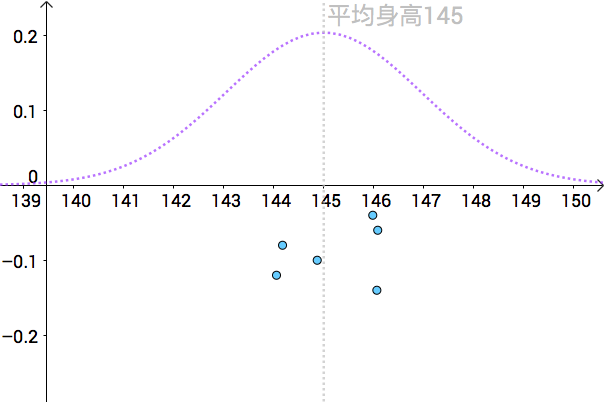

如果我们关闭上帝视角,我们分辨不出哪个点估计更好:
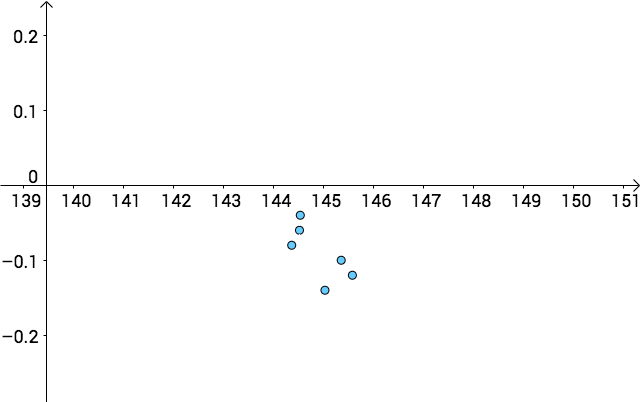

区间估计可以改进此问题。
2.3 置信区间
置信区间,提供了一种区间估计的方法。
下面采用 95\% 置信区间来构造区间估计(什么是 95\% 置信区间,这个我们后面解释):
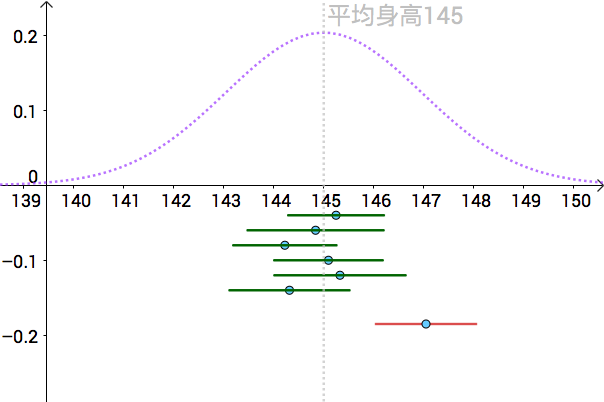

通过 95\% 置信区间构造出来的区间,我们可以看到,基本上都包含了真实的 \mu ,除了红色的那根。
关闭上帝视角,我们仍然不知道哪一个区间估计更好:
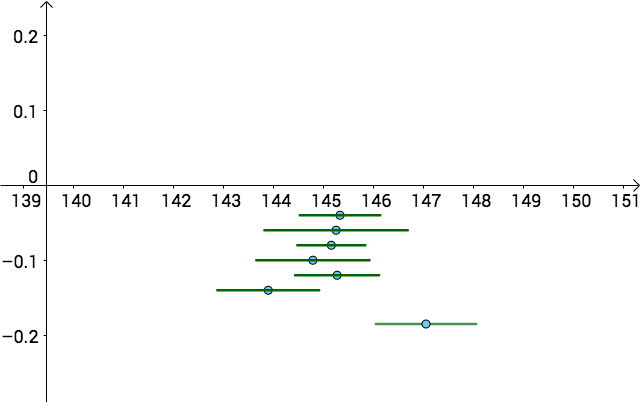

但是,和点估计比较:
- 点估计和区间估计,都不知道哪个点或者哪个区间更好
- 但是,按照 95\% 置信区间构造出来的区间,如果我构造出100个这样的区间,其中大约有95个会包含 \mu
这就好像用渔网捞鱼,我知道一百次网下去,可能会有95次网到我想要的鱼,但是我并不知道是不是现在这一网:

剩下的问题就是 95\% 置信区间是如何构造的。
3 95\% 置信区间
假设人群的身高服从:
X \sim N(\mu , \sigma ^2)\\
其中 \mu 未知, \sigma 已知。
我们不断对人群进行采样,样本的大小为 n ,样本的均值:
M=\frac{X_1+X_2+\cdots +X_ n}{n}\\
根据大数定律和中心极限定律, M 服从:
M \sim N(\mu , \frac{\sigma ^2}{n})\\
我们可以算出以 \mu 为中心,面积为0.95的区间,如下图:
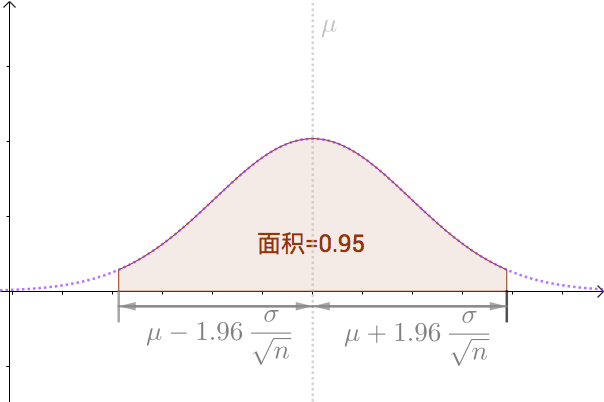

即:
P(\mu -1.96\frac{\sigma }{\sqrt{n}}\leq M\leq \mu +1.96\frac{\sigma }{\sqrt{n}})=0.95\\
也就是, M 有 95\% 的几率落入此区间:
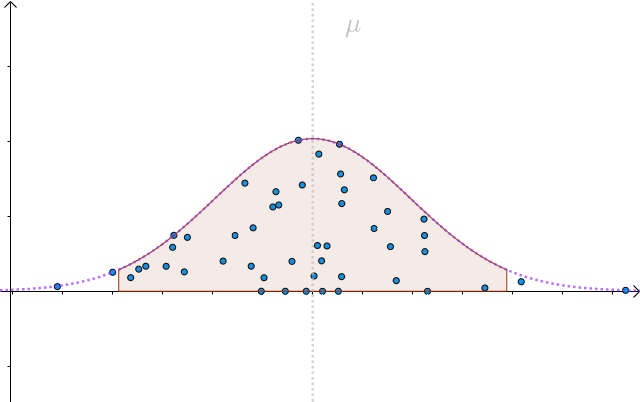

我们以 1.96\frac{\sigma }{\sqrt{n}} 为半径做区间,就构造出了 95\% 置信区间。按这样去构造的100个区间,其中大约会有95个会包含 \mu :
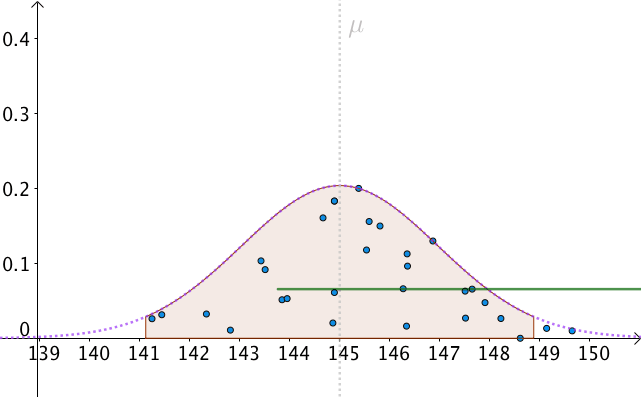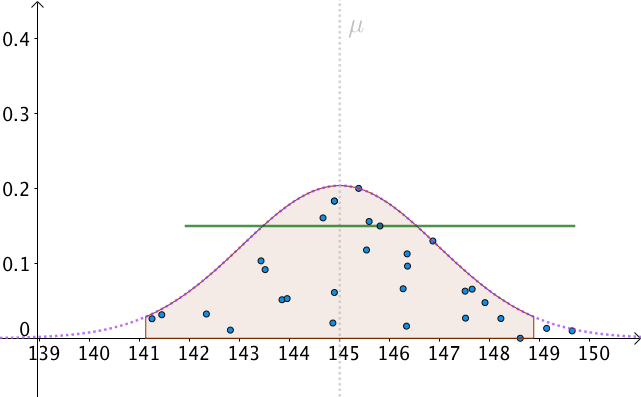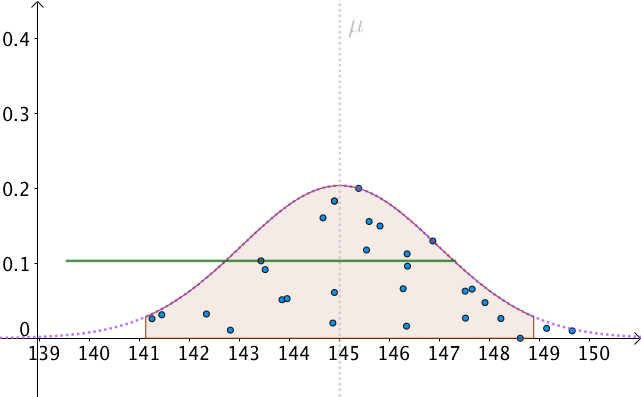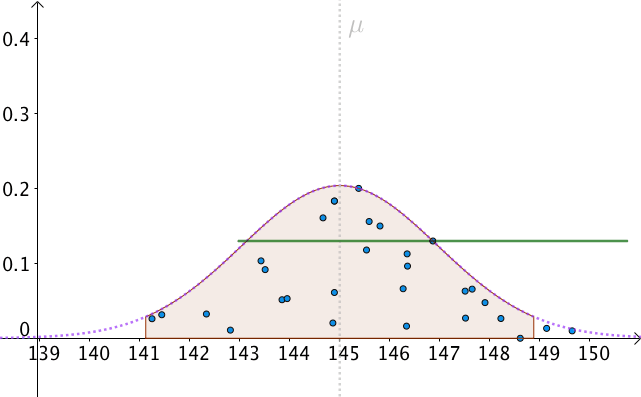

那么,只有一个问题了,我们不知道、并且永远都不会知道真实的 \mu 是多少。
我们就只有用 \hat{\mu } 来代替 \mu :
P(\hat{\mu }-1.96\frac{\sigma }{\sqrt{n}}\leq M\leq \hat{\mu }+1.96\frac{\sigma }{\sqrt{n}})\approx 0.95\\
4 总结
总结一下:
- 置信区间要求估计量是个常数
- 95\% 也被称为置信水平,是统计中的一个习惯,可以根据应用进行调整
更多内容推荐马同学图解数学系列教程