计算机内部是如何处理汉字的输入输出和存储过程的?
5 个回答

要理解汉字是如何被计算机处理的,首先就要理解编码原理。
其实不光汉字;实质上,计算机内部的一切符号都要借助编码来输入输出。
千字文
作者:周興嗣 南梁
天地玄黃 宇宙洪荒 日月盈昃 辰宿列張 寒來暑往 秋收冬藏 閏餘成歲 律召調陽 雲騰致雨 露結爲霜 金生麗水 玉出崑岡 劍號巨闕 珠稱夜光 果珍李柰 菜重芥薑 海鹹河淡 鱗潛羽翔 龍師火帝 鳥官人皇 始制文字 乃服衣裳 推位讓國 有虞陶唐 弔民伐罪 周發殷湯 坐朝問道 垂拱平章 愛育黎首 臣伏戎羌 遐邇壹體 率賓歸王 鳴鳳在樹 白駒食場 化被草木 賴及萬方 蓋此身髮 四大五常 恭惟鞠養 豈敢毀傷 女慕貞絜 男效才良 知過必改 得能莫忘 罔談彼短 靡恃己長 信使可覆 器欲難量 墨悲絲淬 詩讚羔羊 景行維賢 克念作聖 德建名立 形端表正 空谷傳聲 虛堂習聽 禍因惡積 福緣善慶 尺璧非寶 寸陰是競 資父事君 曰嚴與敬 孝當竭力 忠則盡命 臨深履薄 夙興溫凊 似蘭斯馨 如松之盛 川流不息 淵澄取映 容止若思 言辭安定 篤初誠美 慎終宜令 榮業所基 籍甚無竟 學優登仕 攝職從政 存以甘棠 去而益詠 樂殊貴賤 禮別尊卑 上和下睦 夫唱婦隨 外受傅訓 入奉母儀 諸姑伯叔 猶子比兒 孔懷兄弟 同氣連枝 交友投分 切磨箴規 仁慈隱惻 造次弗離 節義廉退 顛沛匪虧 性靜情逸 心動神疲 守眞志滿 逐物意移 堅持雅操 好爵自縻 都邑華夏 東西二京 背邙面洛 浮渭據涇 宮殿盤鬱 樓觀飛驚 圖寫禽獸 畫彩仙靈 丙舍傍啟 甲帳對楹 肆筵設席 鼓瑟吹笙 升階納陛 弁轉疑星 右通廣內 左達承明 既集墳典 亦聚羣英 杜稾鍾隸 漆書壁經 府羅將相 路俠槐卿 戶封八縣 家給千兵 高冠陪輦 驅轂振纓 世祿侈富 車駕肥輕 策功茂實 勒碑刻銘 磻溪伊尹 佐時阿衡 奄宅曲阜 微旦孰營 桓公匡合 濟弱扶傾 綺迴漢惠 說感武丁 俊乂密勿 多士寔寧 晉楚更霸 趙魏困橫 假途滅虢 踐土會盟 何遵約法 韓弊煩刑 起翦頗牧 用軍最精 宣威沙漠 馳譽丹青 九州禹跡 百郡秦并 嶽宗恆岱 禪主云亭 雁門紫塞 雞田赤城 昆池碣石 鉅野洞庭 曠遠緜邈 巖岫杳冥 治本於農 務茲稼穡 俶載南畝 我藝黍稷 稅熟貢新 勸賞黜陟 孟軻敦素 史魚秉直 庶幾中庸 勞謙謹敕 聆音察理 鑑貌辨色 貽厥嘉猷 勉其祗植 省躬譏誡 寵增抗極 殆辱近恥 林皋幸即 兩疏見機 解組誰逼 索居閒處 沈默寂寥 求古尋論 散慮逍遙 欣奏累遣 慼謝歡招 渠荷的歷 園莽抽條 枇杷晚翠 梧桐早凋 陳根委翳 落葉飄颻 游鵾獨運 凌摩絳霄 耽讀翫市 寓目囊箱 易輶攸畏 屬耳垣牆 具膳餐飯 適口充腸 飽飫烹宰 飢厭糟糠 親戚故舊 老少異糧 妾御績紡 侍巾帷房 紈扇圓潔 銀燭煒煌 晝眠夕寐 籃筍象牀 弦歌酒讌 接杯舉觴 矯手頓足 悅豫且康 嫡後嗣續 祭祀烝嘗 稽顙再拜 悚懼恐惶 箋牒簡要 顧答審詳 骸垢想浴 執熱願涼 驢騾犢特 駭躍超驤 誅斬賊盜 捕獲叛亡 布射遼丸 嵇琴阮嘯 恬筆倫紙 鈞巧任釣 釋紛利俗 並皆佳妙 毛施淑姿 工顰妍笑 年矢每催 曦暉朗耀 琁璣懸斡 晦魄環照 指薪脩祜 永綏吉劭 矩步引領 俯仰廊廟 束帶矜莊 徘徊瞻眺 孤陋寡聞 愚蒙等誚 謂語助者 焉哉乎也
比如,我们可以用这篇千字文作为编码依据,写出数字1,就对应于天;写出数字2,就对应于地……那么,我们就可以用最多四位数字把所有这些字表示出来。
然后,如果咱组织个天地会的话,就可以用数字1 2作为接头暗号;或者,更中二一点——左手一个指头指天,右手两个指头指地……
更精细点的话,我们可以把每个手指的伸曲作为不同的编码;那么两只手10根手指就能编码1024个不同文字——左手伸一下拇指,收回;然后再伸一下食指……
接头人一看:哎呀同志!可算找到组织了!
咳咳。
总之,我们看到了,文字是可以用其它方式“曲折隐晦”的表达的。
既然手指的伸曲可以作为一个不同的状态、使得我们一双手伸20次就能吟咏完这首诗:
白日依山尽,黄河入海流。 欲穷千里目,更上一层楼。
那么,用10根电线的不同通电状态组合,是不是也能编码这篇千字文?
没错。这就是数字电路原理。
我们把电线有电叫做状态1,电线没电叫做状态0;于是,00000 00001就是一个状态,而00000 00010是另一个状态——规定每个位的电信号权值为2^n,其中n是第n条电线,从0开始编码:这就是二进制数字。
二进制拿来记录处理电路状态实在太方便了;因此,计算机里面习惯用二进制描述电路状态。比如,寄存器当前值是00000 11000、地址线收到一个信号00100 11011,等等。
请记住,这并不是说电路里神奇的出现了0和1,而是我们把电路断开(无电)叫0、电路闭合(有电)叫1,从而可以用0/1组成的数字串简洁的把“一把导线里面每根线的电压状态”表示出来。
如果不明白的话,请反复诵读这句话:00100 11011 应该读作 断断通断断 通通断通通。
二进制用起来还是不够方便。
事实上,按照每位的权值是2^N的规则(和十进制计数法每位权值是10^N一模一样),我们可以很容易的把它转换为十进制表示——注意只是表示。
比如,电路状态 断断通断断 通通断通通,对应的二进制表示为00100 11011,十进制表示为155,十六进制表示为98——表示成十进制、十六进制短了很多,方便记忆了;但却不再能直观的看出电路的通断状态:必须转换回2进制,才知道这个状态是 断断通断断 通通断通通。
但对我们要处理汉字的人来说,电路状态我们并不关心;只要能够区分它、从而把它和一个汉字对应起来就行了。因此我们一般直接用16进制(方便和二进制互换),不用二进制。
总之,这个状态是电路上实实在在的物理状态,拿万用表可以测出来。我们把这个东西叫做机内码。
所谓编码,就是把千字文、阿拉伯数字以及康熙大字典中的每一个字对应到机内码的过程。
比如,空格" "对应于十进制的32、十六进制的20以及二进制的00100000;阿拉伯数字"1"则对应于十进制的49、十六进制的31以及二进制的00110001……以此类推。
可以看出,这个编码可以是一个极其随意的过程。
比如,我很随意的用千字文编码;但发明计算机的美国佬却用ASCII码先编码了英文字母、阿拉伯数字以及!@$#^%之类符号 ;其它各国在引进计算机时,也会自说自话的搞出自己的编码方案、从而把本国语言文字输入计算机……
比如,我国就有GB2132、GBK、GB18030等汉字编码;但台湾、日本、韩国以及东南亚国家也用汉字,他们也搞了个另外的好多套编码……
那么,这一大堆编码方案,谁说了算?
不然的话,按你的编码,99 67 54是520,结果到法国佬那里成了250……你们还不要打起来啊?
所以,现在搞了一个全球统一的Unicode码,一网打尽全球所有语言。
编码完成之后,汉字就可以和罗马字母、法文字母、德文字母、俄文字母、英文字母一样,以电信号有无/磁化方向/光盘上的凹坑等等不同状态存储起来了。
其中,在光盘上时,它是一串凹坑的组合;在硬盘上,它是一组磁畴的磁化方向;在内存条里,它是场效应管的充电状态;在并行总线上,它是一把金属导线的电压高低组合;在串行通讯线缆上,它是高高低低的一组方波……
所有这些状态,都可以用二进制表示;所有这些二进制,都可以转换成更方便阅读和记忆的十进制/十六进制数字——但想要直观的理解电路状态,都必须还原到二进制。
我们知道,键盘上面只有26个英文字母以及十个数字和!@#$% 等特殊符号,以及tab、shift、enter等控制键(但也可以用来输入)……
你看,没有汉字啊?这怎么办?
事实上,键盘输入,归根结底也只是电信号而已。
既然我们已经用abcd、1234等等编码了这些电信号;那么,把这些电信号翻译回12345、然后直接用12345这些按键上的字符、拼凑出每个汉字的Unicode码——这,不就解决了输入问题吗?
这个自动把键盘敲的字母组合翻译成对应的汉字的程序,就是我们熟悉的输入法。
嗯。别急,别急。我知道你记不住。没人能记住超过六万个汉字的Unicode编码。所以并没有这样的输入法。
虽然这个办法的确行不通;但这个思路是成立的,对吧?
既然思路成立,那么不要急,一步一步来。先找出问题,再一步步解决它。
现在的问题在于,用这种方法敲汉字,我们第一记不住编码表,第二只能利用数字小键盘,输入效率太低。
怎么办呢?
没错。拼音。我们把二十六个英文字母当拼音,把每个汉字的读音敲进去,不就好了?
没那么简单。普通话一共才几百个音,汉字六万多……同音字实在太多了。这怎么输入?
没错。笔画输入。汉字归根结底有五种基本笔画,横竖撇捺折对应12345,妥了——比如王字怎么写?横横竖横,1121,哈哈搞定。
仍然不行。遇到工字和土字,你怎么办?
所以现在的问题是重码,对吧?
好办。把重码字列出来,给用户选择。这下妥了吧?
没错。解决了。
甚至于,拼音输入也能这样解决。
不仅如此,既然普通话只有几百个音,那没必要敲全eng、ang吧?
给eng/ang也来个编码,敲两下,一个音就进去了——哈哈,双拼!
但这样仍然不好用。每敲一个字都要在候选字里面找半天,这实在太慢了。
还得继续优化。
现在有两个思路。
一是王永民先生搞的五笔输入法,思路是从编码汉字的偏旁部首入手设计一套字根表,一方面减少了每次输入的击键次数,另一方面减少乃至杜绝了重码。以至于五笔高手可以轻易做到每分钟输入超过200个汉字。
但五笔输入法需要专门的训练。背字根表,反复练习直到形成肌肉记忆……
因此,另一条思路获得了更多支持,以致于现在只有专业录入人员才会学习五笔。
这个思路就是:继续使用拼音输入法;但尽量让用户一次输入一个词、一句话;那么借助软件强大的分析能力,就可以“猜”出他最可能想说什么。
打个比方的话,你说“lin”,没人知道是哪个字;但你说“树林”“林黛玉”“临安”“临颍”“淋雨”,这个字就唯一确定了。
当然,单字仍然无法确定;有些词也有同音。但无论如何,这个策略使得重码少了很多。尤其借助概率论的马尔科夫链理论,整句输入可以得到极高的准确率,几乎不用选字,从而使得熟练的拼音使用者也能一分钟输入一百字以上。
总之,汉字的输入是一个编码的嵌套过程:先是击键产生一个键盘码,键盘码被键盘内置的CPU转换成对应的ASCII机内码(并行线路是通断错落的一组电平,串行线路是一组方波);然后这些ASCII码的组合(比如ABCD)又被转换到汉字机内码(Unicode或者GB2312/GBK/GB18030)——最终,这些机内码被保存到磁盘/光碟等存储介质,汉字从输入到储存这一条龙过程就算走完了。
注意这里面反复进行了多次编码和解码;但编码/解码过程各自独立,互不影响。
比如,你可以用拼音或者五笔编码汉字、然后以这个编码输入;然后输入法解码你敲入的键盘字符序列,再自动帮你编码到Unicode或者GB系列。
从哪个途径转换我们不需要关心。只要最终得到的Unicode正确。
编码和存储搞定了,怎么输出呢?
比如,见了12354这串数字,你怎么知道它应该是哪个汉字?这个汉字该怎么写?
在回答这个问题前,我们应该先想一想:屏幕上是如何显示汉字的?

我们知道,屏幕是由一个个像素构成的。正如我对着自己显示器拍的这张照片,像素的不同取值就构成了汉字的笔画,最终组成我们见到的汉字。
那么,像素的黑白,岂不是也可以用0和1编码吗?
没错,这就是点阵字体:
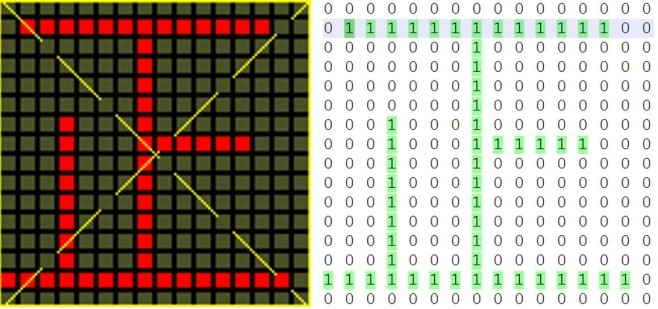

正字的Unicode编码是十六进制的6B63,而6B63这个机内码关联到一副bitmap(位图),这张位图也可以用二进制编码,就是上图右侧那那一堆数字——按顺序存下来,就是正字的16位点阵。
类似的,还可以搞32位或更大的点阵,从而把字体显示的更精确一些。
总之,六万多汉字就对应着6万张不同的点阵图片。
我们知道,汉字有不同的字体。比如楷书、隶书、宋体、仿宋,等等。这些就对应着不同的小图片。
因此,每个不同字体又对应着不同的六万张小图片,你装了100种字体,电脑里就有了六百万张不同的图片。
将来,当需要显示汉字时,从Unicode找到对应的图片(也就是那一堆二进制串),再按照指示给显示器不同的像素通电/断电,于是显示器上就黑白分明的显示了不同汉字。
当然,显示器的显示原理也各不相同。比如,CRT是电子束轰击荧光粉,没有电子轰击的地方就不发光;而LCD呢,哪里通电“搅乱”的液晶,哪里就混浊不透光;LED,哪个发光管通电哪个发光……
因此,具体显示时,显示器也还需要“翻译”一下。比如CRT遇到0就改变电子枪栅极电压,不让电子飞出去;而LCD遇到0就切断对应像素的电压输出,让液晶恢复透明……
不仅如此。
不同显示屏尺寸不同、每英寸像素数也大相径庭。32点阵的汉字,在某些屏幕上占地太大,一屏显示不了几个;但在视网膜屏上又显得太小,拿放大镜才看得见……
怎么办呢?
的确可以通过插值的方式缩放;但这样效果并不好(插值是一种通过算法自动添加像素的方式,比如正字放大一倍显示时,就要把横从一排像素改成两排;但如果缩放不是整数倍、或者笔画弯折处就很难确定该不该插入像素)。
另一种方式是,不记录像素,记录“写字过程”。比如线条从哪里起始、在哪里转折、到哪里结束,以及哪里下笔重、哪里下笔轻,等等。
这就是所谓的“矢量字体”,它记录的是笔画线条以及转折、粗细等信息,因此可以非常方便的缩放。
不仅如此。你可能注意到,我拍摄的实际屏幕照片里,“评论”二字笔画边缘颜色有些发暗。
这是clear type处理后的结果。经过这个处理后,字体看起来笔画更光滑、更锐利、更美观。
换句话说,字符输出并不像想象那么简单。它可能需要矢量图缩放、点阵图转换、cleartype/truetype之类技术处理点阵图(注意这里是彩色点阵,这种点阵里,每个像素又分为红绿蓝三个分量,每个分量又有256级亮度),然后才能照图施工、把文字输出到屏幕上。
这就是汉字输入输出的全过程。

据我所知,计算机处理汉字主要有两个问题,第一是编码问题,第二是字体渲染问题。
中文的特点是字符多、字符轮廓复杂。但严格来说,都不算特别特殊,很多国家的文字都有特殊性。下面介绍一些相关的知识,仅供参考。
1、汉卡(专门处理汉字的硬件设备)
上世纪80~90年代前期,由于计算机内存非常小、运算速度也较慢,保存中文字符会占用大量内存,且显示中文也会增大CPU负担。所以出现了专门处理汉字的硬件设备——汉卡。


之后,随着计算机软硬件的进步,汉字存储和显示问题逐渐不再是问题了。
硬件方面:随着486 PC的普及,电脑内存和速度有了长足发展,仅用软件足以解决汉字的存储和显示问题。专用的汉卡也逐步退出了历史舞台。
软件方面:人们在不断改进渲染字体的算法,能够用越来越少的存储空间、越来越快的速度渲染文字。汉字渲染不再需要特别的关注。
2、汉字编码
各种计算机字符标准里,是用一个一个的数字代表一个一个的字符。比如英文大小写字母、数字、英文标点符号一共只有几十上百个,所以表示英文常用字符只需要1个字节就足够了。一个字节最多容纳256个字符(实际上仅使用128个就够用)。
由于汉字较多,常用字就有几千个,所以一个字节必然不够。现在仍然在使用的国标编码( GBK、GB2312等编码)一般用2个字节表示汉字,理论能容纳几万个汉字,足够常规使用。
而随着Unicode的普及,世界上所有的文字包括汉字已经被统一编码,汉字与其它所有文字一样,都不再是特殊的。在Unicode体系中,绝大多数汉字占用3个字节(UTF-8)或2个字节(UTF-16)。
当前互联网时代的汉字编码,是以Unicode为主,GB字符集并存的状态。长远来看还是全世界都统一为Unicode比较好。
3. 汉字字库
早年的计算机系统比较朴素,能够正常显示就够了,没有那么多花哨的字体。那时候的字体主要是“点阵字”,就是逐像素保存的字体。


点阵字的主要缺点是不能随意放大缩小,字体死板、有锯齿。现在点阵字还应用于家电、广告牌、公交车报站屏幕等地方。大部分有电脑手机的地方都不再使用点阵字技术了。
现在广泛使用的TrueType、OpenType等新一代字体技术,能够以矢量方式存储字体,占用空间小、渲染快、显示效果清晰锐利。各种字体应用范围也很广,所以字体的制作、授权和使用也是一个很大的产业链。
由于中文常用字非常多,导致中文字体的制作成本非常高,相比英文字库购买费用、授权费用也很高。我们在工作中千万要注意字体授权,不要在商业产品中随意选用字体,务必注意版权问题。
例如,Windows系统自带的“雅黑”字体就不能任意使用。


4、老一辈字体设计师
说到中文字体,不得不提一下老一代的字体设计师前辈们,他们用铅笔、白纸、尺子制作出了第一代的印刷用中文字体。


回顾那段历史的视频《逐个画出来的印刷字》:逐个画出来的印刷字 - oooooohmygosh_哔哩哔哩_bilibili
虽然印刷字与计算机字体还有很多区别,但中文字体确实是在一代又一代人不断继承、创新中发展的。
总的来说,计算机发展历史中,汉字的存储、显示曾今遇到过困难。
但随着计算机整体的进步,显示汉字已经不再是一个特殊的问题。
当然,文字存储、渲染、打印的技术仍然会继续进步,汉字与其它所有文字都会在技术进步中获益。