怎样用 MATLAB 识别图片上的文字?
13 个回答

首先题主我不知道你是直接想要快速对文字进行识别呢,还是想自己写一个东西来实现对文字的识别分类。对于前者,现有的工具其实已经很成熟了。一般来说用的都是OCR,也就是
光学字符识别_百度百科,我之前用的是他的python接口——pytesser,想用的话直接百度即可。当然这个东西MATLAB里面不知道有没有。。。
==============================
当然,看到题主说是自己想用EM来进行分类。那我就当做你是想写一个文字识别包了。最近正巧我也在做类似的工作。现在就来简述一下工作步骤。
1、图片获取
由于我所做的是验证码识别,因此首先要获得网站验证码。这个不管你用什么方法,直接把图片爬下来统一命名就好。比如说我就是用python爬取的本校教务系统的验证码,爬虫原理什么的在此就不赘述了,随便一百度到处都是。然后把爬下来的图片导入工作路径,我们再进行进一步处理。
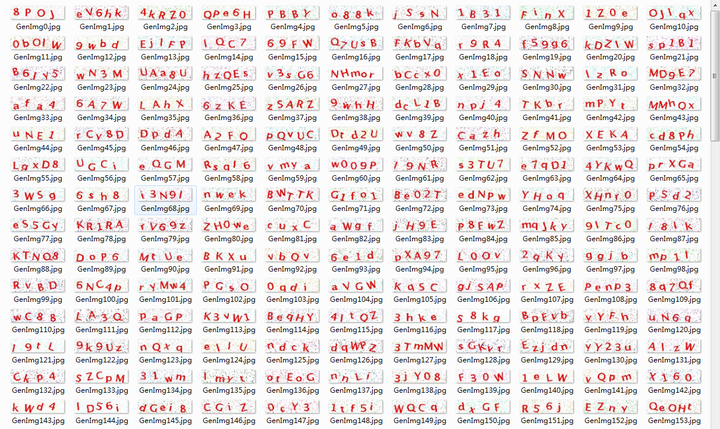

如图是我爬下来的验证码,为了充实训练集,建议还是多爬一些。
2、图片处理
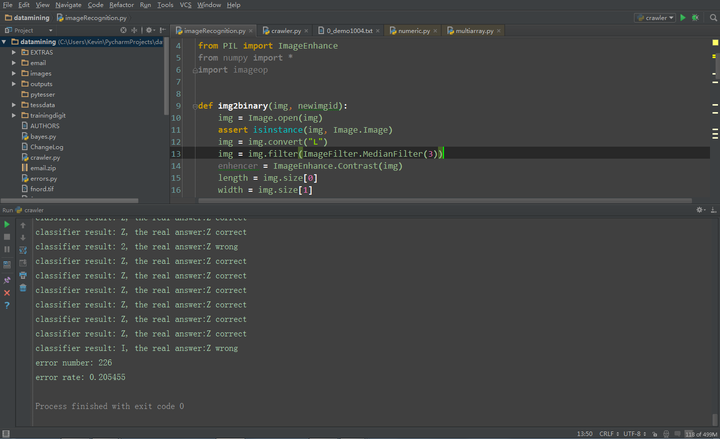
因为爬下来的验证码中包含很多噪点,首先我们要对其进行去噪工作,这个在MATLAB中就很好实现了,matlab的image processing toolbox有很多函数可以调用,经过试验,我发现中值滤波可以起到很好的去噪效果。当然控制得好的话开闭运算跟高斯阈值分割估计能起到更好地去噪效果。如果你图片中的文字足够清晰且背景没有噪点,那么这一步可以省略。有一点需要强调的是,对于非灰度图的图片,建议上来还是先转化成灰度图以方便计算。这些在MATLAB中都有相应的函数,题主自己找一下吧(原谅我是用Python做的。。。MATLAB好久没用函数名都忘得差不多了)
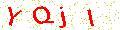
处理前的验证码
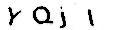
处理后的验证码
清晰了很多吧:)
3、图片切割
对于连续的英文单词,我们需要对其进行切割建立字模。由于我们之前已经将背景置白,因此我们可以创建一个counter变量来对每个字母边界进行判断。counter用于统计每一列黑色像素点的数量(经过观察,我这里的黑色定义为灰度值<=110),如果counter == 0就算是遇到了边界。这样我们就能很轻松的切割出每个字模了。当然,在之后的切割中我发现,我们仍需要对采集到的字模进行进一步处理。原因有二,一方面是因为有的噪点因为没有被完全去除导致我们可能切割出空白区域,另一方面可能有的字母之间会连在一起,因此出现了一个字模中有两个字母的情况。对于这两种情况,我们可以根据字模所包含的列数来进行筛选。在我这里当字模的列数在2-24之间的时候基本上每个字模内都是单个字母。
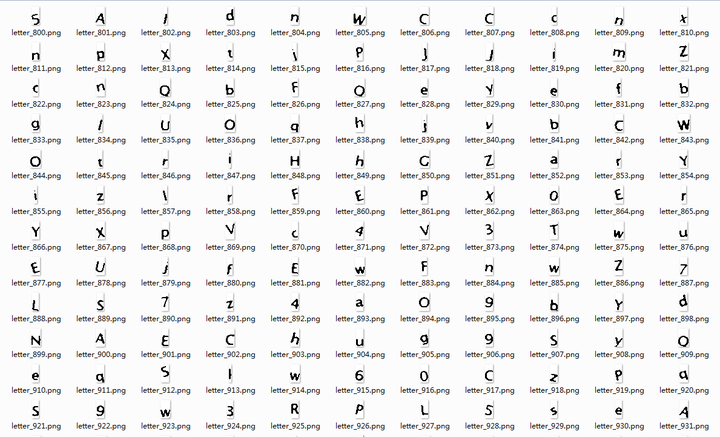

切下来的字模
4、图片二值化
这也许是所有步骤中最重要的一步,这一步之后意味着我们将可以直接对图片进行分类了。记住我们未来对所有文字进行识别的时候,所有的步骤都是先切割,再二值化,最后进行分类。因此未来我们二值化的是字模而非届时的整个图片。(这不都是废话吗衰。。。)对于字模的二值化也很简单,首先我们对每张图片的每个像素进行遍历,黑的置1白的置0,这个黑白的界定跟前面一样,用灰度值大小进行判断就好了。当然为了优化程序性能,我在之前的判断的时候就已经将图片二值化了。二值化后将数据写好到txt文档中就好了。值得强调的一点是,因为我们事后要先对所有数据进行人工分类,那个01010101的排布实在是像打了马赛克。。。。所以还是用原来的图片进行人工分类比较好。为了关联好每个字模图片和txt文件,我们可以建立一个fileid变量,对于相对应的图片和txt文档用相同的fileid当做文件名。这样在后面人工识别后进行重命名的时候就很方便了。
好了下面进入打码时间

z

v

k
说实话其实还是挺好认的。。
但是看多了就。。。。。
开始拿着这些给别人帮我认字他们说要吃了我。。。
好了言归正传
接下来就是人工认字来给这些鬼分个类了。
当然如果你的字够正够标准的话可以考虑直接用OCR分类。由于本校的验证码是歪的,喂给OCR后它实在是表示识别不能。。。。各种2认成z,s认成5,0O不分,最扯淡的还是特么还是好多x给我认成k。。。。。一怒之下我找了几个童鞋十几分钟认完了1000+字模(对!就是这么高效!)
接下来改文件名,那都是小case,飕飕几秒搞定。

最后分好类的数据
5、分类
这个就不用我多说了吧,很多算法都可以拿来尝试。SVM,NN,EM,KNN.......随你挑嘛。具体的怎么数据归一化用什么数据结构我就不多说了,这些算法MATLAB貌似都有好像?嘛,那就更好办了嘛。
最后上个结果

识别率大概在80%左右
还不错吧:)

去年自己做的一个小东西,现在看起来觉得没那么难,而且完成了这个小项目之后,又学深入学习了一阵子,等有空再继续改改。
去年做的小项目大概是这样的:因为学校的教务管理系统查分数比较麻烦,需要自己时不时登录去“轮询”,比较麻烦。那时会一点爬虫,刚好学了一些机器学习的算法。想着训练出一个神经网络识别教务系统的验证码,然后让代码帮我隔5分钟查一下成绩,有新的成绩出了就发邮件给我。于是我开始了。
1、 验证码预处理
我们学校的教务系统验证码长这个样,4个字符(英文小写字母加数字),左右倾斜,背景加了一些噪声:

第一步想到的是滤波,验证码的噪声不像椒盐噪声,更像高斯噪声。我自己也写了个均值滤波器,效果也很不错,对付这种比较简单的噪声污染没有太大问题。
在实际中,我直接调用了matlab的自带滤波器,维纳滤波。进行灰度处理后直接交给维纳滤波:

滤除噪声的效果不错。
为了接下来的操作速度快一点,我直接进行了二值化操作,调整好阈值,二值化后得到:

2、Character Segmentation(Partition)
在实际的photo OCR当中,字符分割是很难的,在NG的machine learning中提到了一点,可以用sliding window的方法去实现,在这里,我观察了验证码的特点,其实验证码当中的字符都相对固定,所以我用最简单的方法分割图像,当然有时会偏差比较大。这也是可以改善的一点。我个人认为利用图论算法中的minimum cuts可以找到连接最弱的部分,然后进行切割,这也是可行的。
切割后的效果:
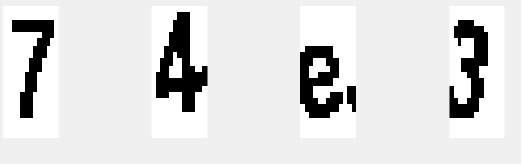

3、 神经网络
当时只能说是入门了神经网络,学的是NG的课。直接用了一个全连接的前馈神经网络,一共4层,input layer一共是260个神经元,两层hidden layer都是200个神经元,output layer是36.
虽然方法很笨,一开始训练样本也不多,我抓了100张验证码,并手动标签了,训练了一个初步的模型。然后我就直接用这个模型去识别,把正确识别的验证码和对应的字符保存起来;把识别错误的保存到另外一个文件夹。针对识别错误的验证码,我手动标签,然后训练,重复这个过程。后面验证码已经接近1000张了。
虽然方法很笨,但是效果很不错。经过我几次改进之后,在线识别100张,正确识别率基本在90%以上(90%~93%左右)
其实,利用CNN效果会更好。先抓取大量为标签的验证码,先进行预训练,再进行监督训练,效果也会好很多。
当时就是这样,利用全连接网络+L2 weight penalty,利用full-batch method 加 conjugate gradient训练了这个网络。
之后我学了Geoffrey E. Hinton的课程之后,进一步了解了神经网络,可以做的花样就很多了。
总结
这就是训练集的一部分:

标签:

我租了腾讯云的服务器,学生优惠,1元1个月。
在考试月的时候完成了全部代码,先在matlab完成了前期工作,然后用Python写了一遍,加上了爬虫的那一部分。 最后每次有成绩都第一时间通知我:

附上github传送门
[matlab版] mepeichun/Matlab_checkcode_verification
[java版] mepeichun/Java_checkcode_verification
[Python版] mepeichun/check_score_system
写得很乱,因为那段时间参加了好几个比赛。。有空再改