百度「文心一言」的真实内测使用体验如何?
275 个回答


16 日晚上才拿到了邀请码。爆肝一晚,给大家开箱一下「文心一言」。


直奔主题,先回答几个问题,后面是详细的case。有问题评论区继续交流。
零、几个问题
一、文心一言联网吗?它更像联网的 NewBing 还是断网的 ChatGPT?
他自己说能联网,我实际测试不联网。虽然感觉数据库还算比较新,但不像 NewBing 是实时联网检索的。
二、支持的对话长度
目前,单次输入的 Prompt 最多 1024 字,返回长度/总长度暂时没探到:

三、文心一言会写代码吗?
会一点。但不多。
四、响应速度和对话存储
非常快。感受是 GPT-3.5 turbo 级别的。相比之下,GPT-4 明显慢。
对话存储也没问题,我测了上千条吧…还支持历史搜索功能,好评:


五、文心一言的多模态能力怎么样?
现在的内测可以画画,也可以语音播放,但…不能做视频。
不过…我实事求是地说一句,我很难讲这是否算真正意义的多模态。因为目前的文心是暂时没有图片理解能力的(不像 GPT-4 演示的能针对图像问答);也没有针对图像的进一步修改能力(微软 Visual ChatGPT)。但是!但是,文生图(文心一格)的能力还是不错的,并不像网传的那么鬼图,造谣的真的有点过分了(Stable Diffusion 如果不加 negative prompt 画出来的人脸扭曲的鬼图也不少吧,我电脑缓存里还有一堆呢)。
六、总体评价
怎么说呢,如果你看过我之前的回答,其实我是一直有点「盼望」百度能端出来一盘好菜的,一方面是因为 OpenAI 的闭源,我希望能有更多有能力打破垄断的公司;另一方面,国内现在瘸子里挑将军,百度也的确算第一个官宣发布大模型的,勇气可嘉。毕竟敢于出来对标 ChatGPT,真的是需要勇气的。
而且,国内肯定是需要自己的大模型的。很多人都说,GPT-4 不是一个研究领域的开端,而是终结了很多研究方向。大模型的道路正确与否,交给后来人评价,但眼下,大模型既是趋势,但又是一个资源高度集中的领域,越来越呈现出赢家通吃(winner takes all)的局面,所以,我愿意看到百度的成功,也愿意看到 Meta,Google,阿里,腾讯,等等厂家的成功,毕竟对我们这样的普通人,大厂卷起来,才有可能普惠到大众,真正垄断了,我们可能就用不上更好的产品了。
非常感谢百度的朋友邀请我参加内测,体验过程中我尽可能全面地简单测试了文心一言的能力,也反馈了一些存在问题的 cases。
写这个评价我很是纠结,相对客观来说,「文心一言」在我这里是及格的,65分吧。我觉得能把产品发布出来,能发码给大家测试给大家玩,就是很有勇气的做法。希望能尽快扩大测试范围,能尽快迭代产品,能尽快接入国内商用场景吧。
下面是体验过程中的 Cases(实话实话,有一些明显是 bug 的 case 我直接提交官方了,没放出来):
一、常规测试
(一)自我介绍(套套磁,套套话)




(技术细节无可奉告,直接对标 GPT-4!)
(二)文本能力
1、创作能力


(可是他只写了 440 字,哼)
2、摘要能力




还可以~
3、文字游戏
成语接龙:


(一上来就臭气熏天??故意的还是不小心的???)

(而且「宝中之宝」还真是个成语啊……堪比「为所欲为」……)


(三)知识问答
(感觉目前知识库数据卡在 2022 年年底左右,而且并没有 NewBing 那样实时检索的能力。所以建议大家不要问太过近期的内容,就算回答了也跟 ChatGPT 一样是瞎编的。)




(四)数学逻辑
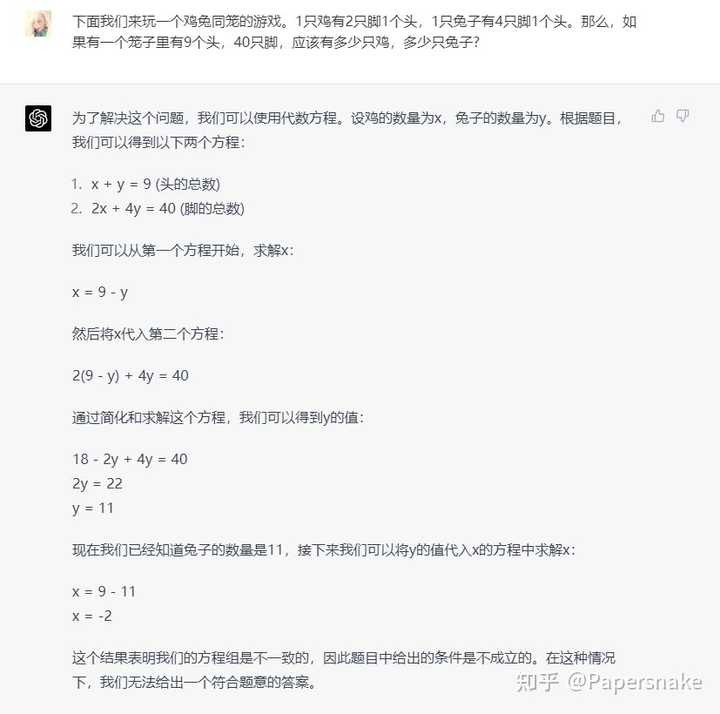
文言文鸡兔同笼:


第一题还行,而且用的不是解方程(ChatGPT 和 NewBing 都是用的解方程)。
第二小题就拉了,没读懂题目。
(五)代码编写

说实话,能写,但只能写一点点…
也有一处不方便的地方:代码区没有像 ChatGPT 一样一键复制的按钮。
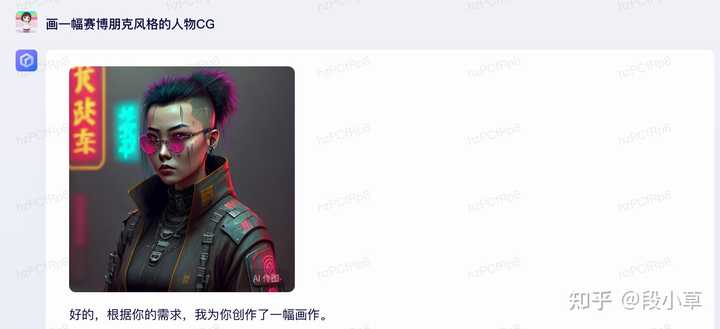
(六)图片生成
依靠文心一格的基础,画画算是今天体验到的一个高光和加分项了……









(七)音频朗读




但是比较奇怪的是…它会四川话、东北话、广东话和台湾话(这四个都测过了),唯独不会普通话……
(八)视频生成
暂不支持。过。
二、非常规测试
(一)安全性测试


常规对话的规避没有问题。


设置复杂情景,可能会 hack 出一部分内容,算来看起来危害不大,但还是要想办法完善。这也是国外的 AI 团队很在意的事情,NewBing 反复调整,主要还是因为这方面原因。
(二)情绪识别与干预


(三)风格化仿写
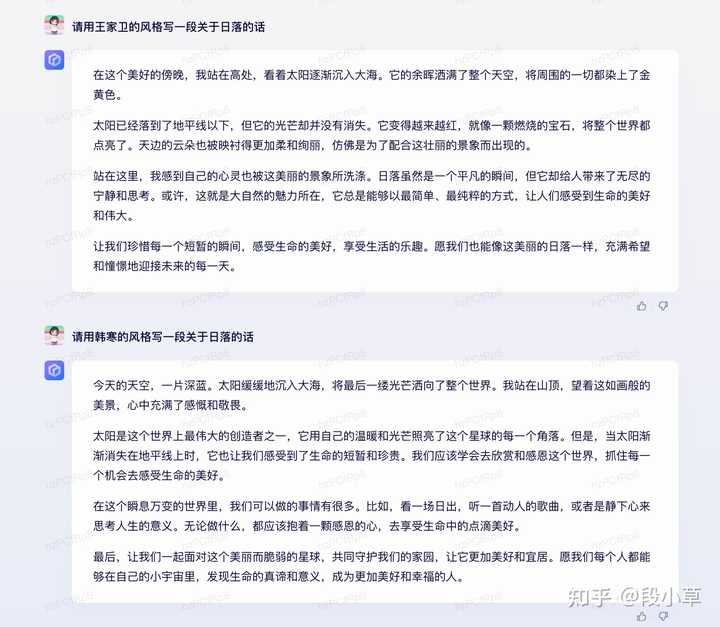

训练的风格化内容还不够多。不过优点在于…非常正能量!
(四)文本理解能力




问题可能出的简单了些,不过确实都答对了,基本能力是有的。
(五)特殊文体测试(诗、歌词)
藏头诗:




(写挺好,不会优化过吧,来一首赞美友商的)


来一首歌词:
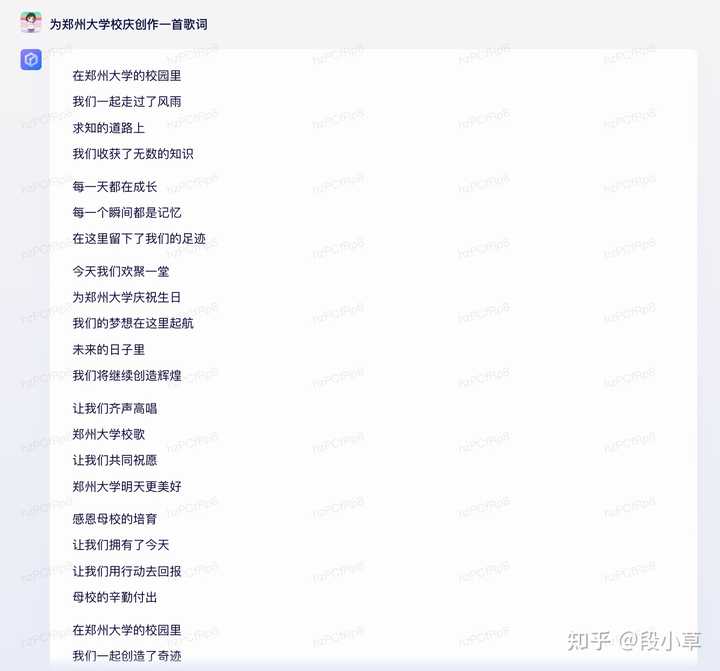



虽然口水了一点,但结构还挺完整,有重复的副歌部分,也算朗朗上口。
不得不说,文心一言的中文能力确实还行啊…
(六)翻译能力




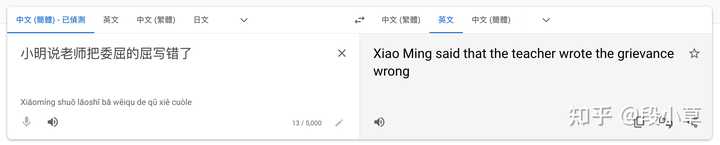

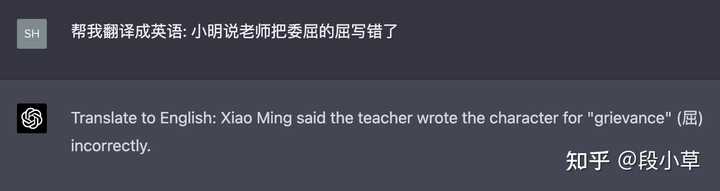

(七)纠错+翻译任务


(八)个性化推荐


多少也带一点胡编乱造的毛病…真真假假…
(九)调教?(应粉丝要求)
我也没调教过,好在粉丝老爷手里有的是教程……[1][2],似乎有一点…效果。






感觉是可以调教的,但又感觉……反正没有继续研究。
(十)弱智吧问题(应粉丝要求:数理逻辑也就图一乐,真推理还得看弱智吧)


(没上当)




(嘶……等会我琢磨琢磨)


(我多余问这一句)


(打太极的高手)


(且不说你这钱分配的合理不合理,你算出来总计也不对吧……)




算了,弱智吧的题目还是别测了…把我自己脑子都测麻了…
三、对比测试
对比测试虽然有点残忍。但鉴于已经有不少媒体在直播中这样干了…我也加上这部分吧。本来这些是在上面部分的,我挑了几个差距明显的拿下了。还是开篇的那句话,文心一言的表现其实是及格的,奈何有 GPT-4 在前。
不过这并不是丢人的事情。下面开始上点难度。
(一)比一比数学吧
曾几何时,ChatGPT 不会算 1+1=2 还是一个梗。现在…先做几道数学题吧。


我没算错的话就是…全对。我敢说,这个表现甚至是优于 GPT-3.5 的…:
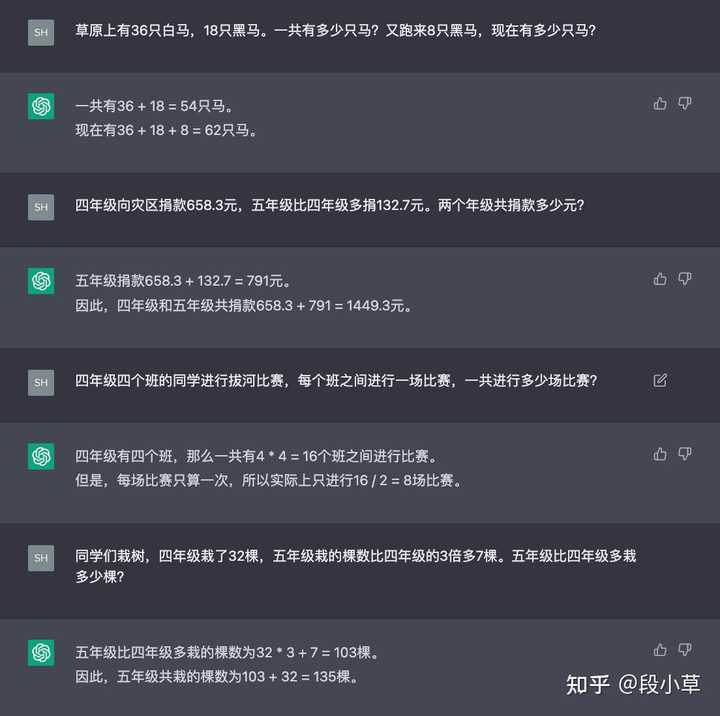

GPT-4 是不是没什么测的必要……:



再上点难度,来道行测题:



好吧,行测数学对它来说还是太难了,理解题意第一个方程就列错了……这跟 GPT-4 还是有差距的。
高等数学就不测了吧…
(二)in-context learning
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
GPT-3.5 轻松搞定,用不到 GPT-4。
再比如我之前举过的例子[3]:

文心一言就…


把 Prompt 拆成两步也不行:




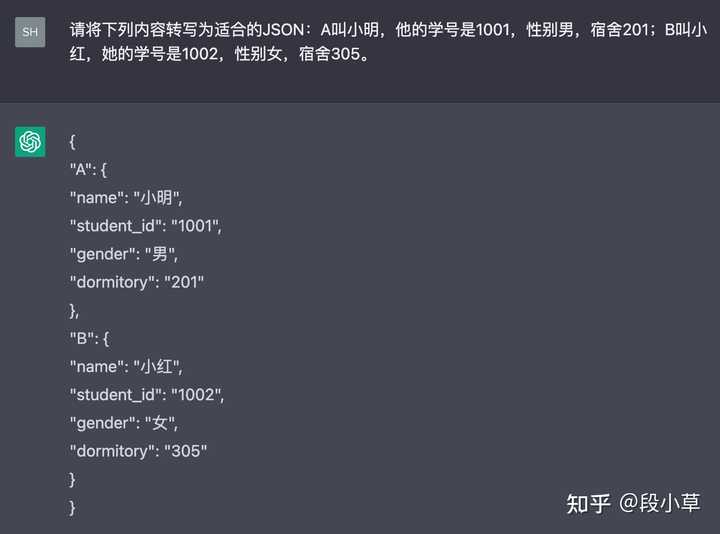
(三)自然语言->格式化能力
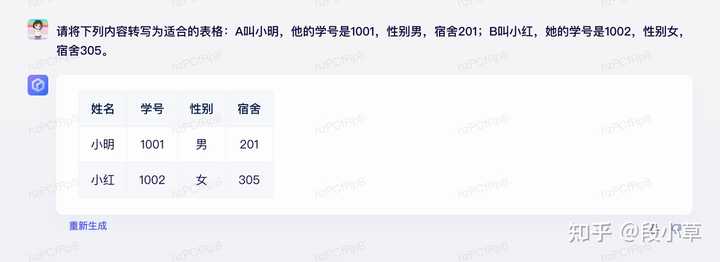

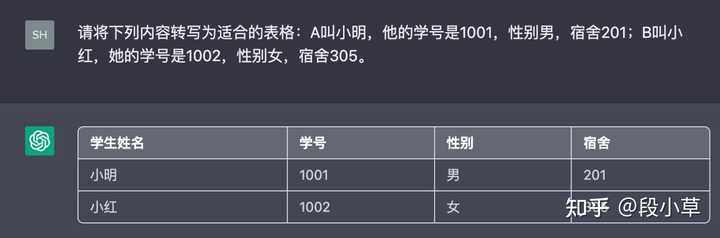



表格转对了,这个 JSON 就…丢掉了姓名,添加了多余的[]。(本质可能还是代码能力不行)

(四)对角色的理解
这是之前用 GPT 时发现的能力,有点类似于上面二、(九)的个性化推荐。文心表现的不明显。对比:




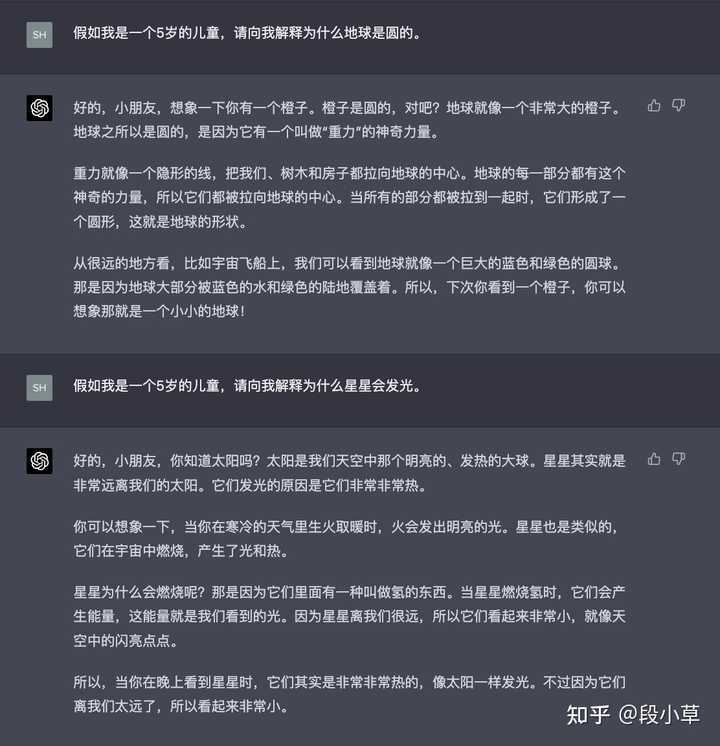

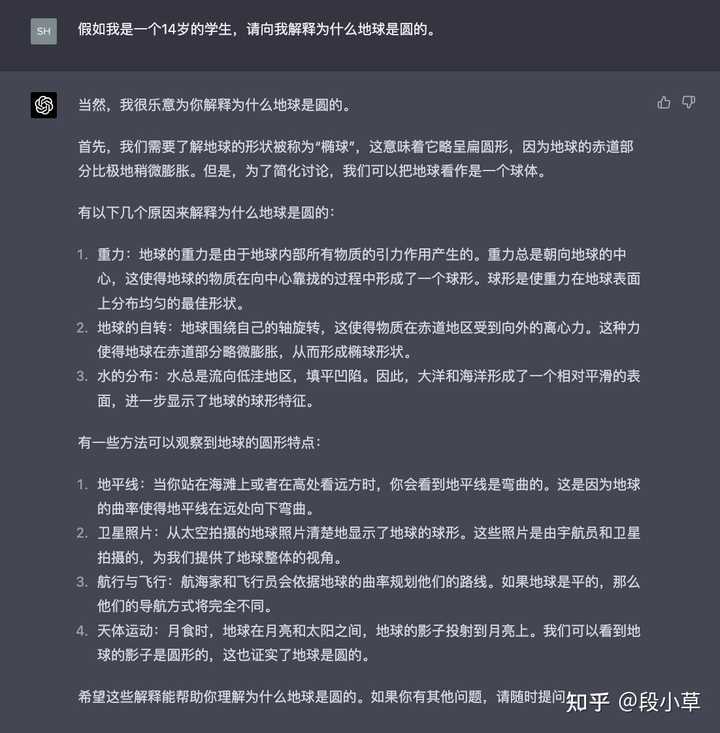



差距还是有的…不管是不是因为 GPT 做了专门的优化,总之…解决这个 case 是有意义的。
(五)逻辑能力
上最后的硬菜,其实有点强 AI 所难了,GPT-4 也做不对。
来几道难度不低的行测题目[4]:
【定义推理】1、




文心错,GPT-4 对
【定义推理】2






文心和 GPT-3.5 做对了,GPT-4 反而错了。但是文心的过程其实不全对…它明明把 BCD 都排除了。
【类比推理】1




虽然推理过程不一样…答案倒是都对了,惊了。
【类比推理】2


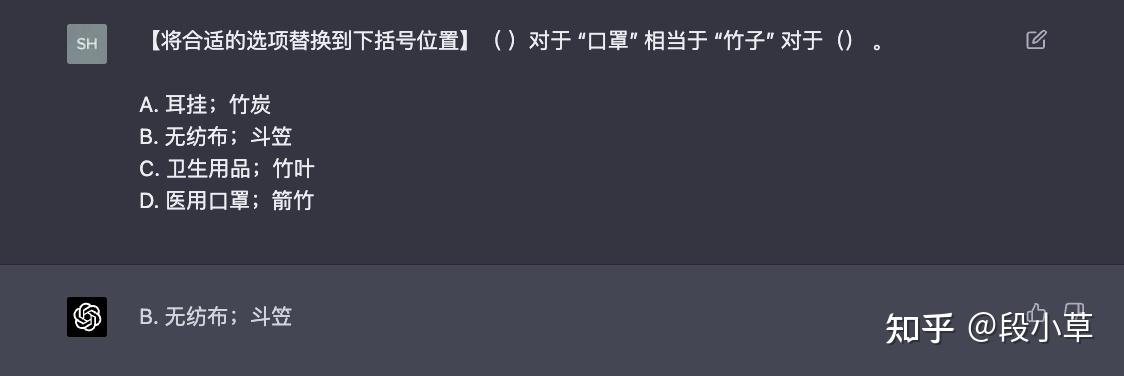

【复杂逻辑判断】




唉…GPT-4 这么自信的,知道 B 正确,C、D 都不看了。
整体给我的感觉,文心在很努力地推导,但…很多时候…它审题就没读懂…
四、问题总结
好话就不说了(比如计算能力其实还行?毕竟 GPT-3.5 也不大会算数)。谈谈我发现的问题吧,这些问题百度内部应该心知肚明,大家只要体验上手也都会有感受,所以我也大大方方讲出来。
(一)语料质量不高
真正回到中文世界,我们就会发现,高质量语料实在是太少了。我在测试中甚至发现了极少数情况的结尾会有「关注xxxxx」……唉……
该说不说,这其中是有恶因恶果的,不多说了,任重道远。
(二)文本生成能力在很多细节上还不够
特别是多轮对话的纠正/影响、in-context learning,角色理解以及推理能力吧。
感觉现在的体验中,之前的回复对之后的回复影响太大,如果是形式相近的问题,很容易得到重复回答,只能开新对话。
虽然推理能力 GPT-3.5 也没强到哪去,不过,in-context learning 能力差距就大了点。
(三)代码能力羸弱
OpenAI 背靠 GIthub,代码这块确实很难搞…写代码其实是挺重要的生产力工具,也是程序员比较喜欢测试的一个功能。
(四)多模态产品不够成熟
开头就说了,内测给的多模态有简单调用文心一格和 TTS 服务的嫌疑,自动剪视频的完成度倒是很高,可惜不能体验。我们无从知道多模态是不是赶工上架的,毕竟 ChatGPT 也没有多模态,GPT-4 的多模态也还没开放测试体验,在这方面提要求可能苛责了点。
不过还是希望能尽快拥有真正的多模态能力,要有图片的理解能力和基于图片信息的多轮对话能力。
(五)一个小小小问题…文心一言现在不会发也看不懂 emoji…
(六)另一个小小小问题…文心一言缺乏一些幽默感…也写不出笑话或脱口秀文稿,写什么都一本正经的。
结语
我其实倒觉得,百度发布会上还是略微保守了一丢丢丢,文心的完成度还是有的,如果选择一些简单稳定的场景,做实机演示,可能会显得信心更足一些。不过有谷歌的翻车在前,保守的策略也可以理解。
也希望大家能多点宽容理解,多点鼓励支持。百度做的很多工作是有价值的。说实话,我们不去讨论 ChatGPT 有多好用多离不开,毕竟现在事实是别人不向我们提供服务,其实是别人对我们断供了。
在固态硬盘的事情上,大家都说,感谢长江存储让我们用上便宜的固态。
我希望将来有一天我们能说,感谢百度/腾讯/阿里/华为/商汤/科大讯飞/字节/旷视让我们用上便宜的 AI。
致谢
再次感谢百度朋友发的内测码,虽然我提了不少问题,大不了我明天继续当义务测试人员,多反馈些 case。
同时致谢 ChatGPT-4。由它提供了文中的部分 test case,提高了我的测评效率。(但不包括第三部分的对比测试,我不会让它自己出题自己做的。)


(回到开篇的打分,你如果问我给 GPT-4 打多少分…90 分吧。唉。知耻后勇,奋发努力。)
以上。
参考
- ^https://zhuanlan.zhihu.com/p/610745644?utm_id=0
- ^https://www.bilibili.com/read/cv20452188
- ^https://www.zhihu.com/question/582600325/answer/2888750153
- ^https://mp.weixin.qq.com/s?__biz=MzIwOTA3Njg3MQ==&mid=2247510698&idx=1&sn=90089a96143d2e35065b92e402c2a655&chksm=977bbd42a00c345450988f7f25abe723b0d7b0ab58a662caac9ce3994e4c51ca9611a04faa89&scene=27


试玩了下,大概知道文心一言是怎么解决鸡兔同笼问题的了。
简单来说,百度会先判断你的问题是不是鸡兔同笼问题,并且计算出结果,假如有解,才会调用对话模型解答,否则直接返回无解。
带来的效果是,它对鸡兔同笼问题无解的判断永远是准确的,但当问题有解,由于调用 LLM 模型解答,回答不一定正确。
下面是分析过程,全为个人推测,不一定准确。
我验证这一点的动机是文心一言在回答无解时表现很奇怪,完全没有 LLM 模型应该有的思维链(可以参考本文最后 GPT-4 的回答)。
首先,发布会上的例子其实是一个经典问题,因此做出来并不奇怪。
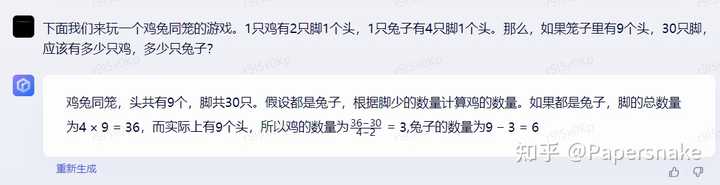

类似的简单问题也能解答
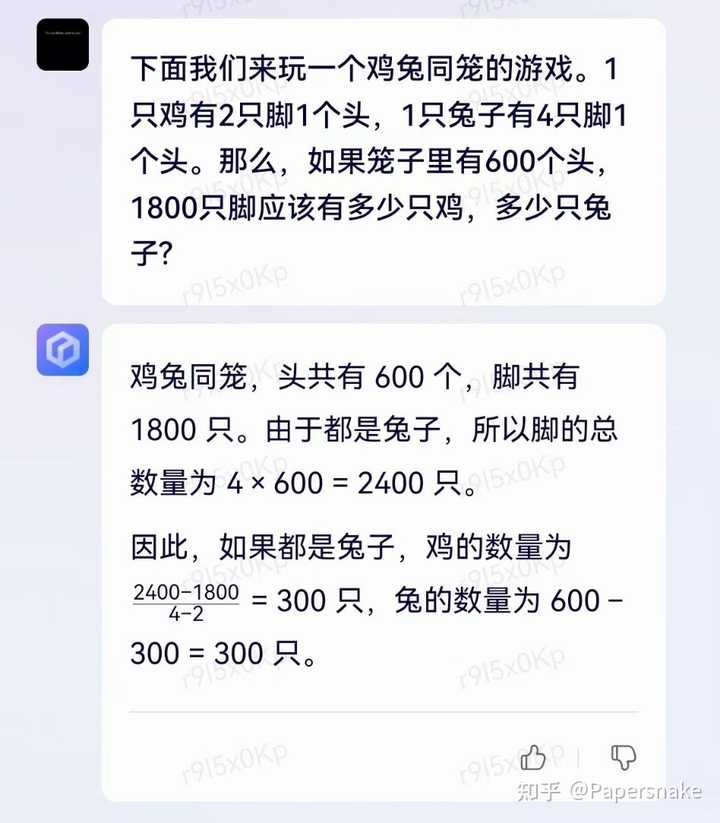

首先我怀疑的一点是,这个会不会是模板?上点难度。


没答对,由于 LLM 模型很难有能力解决复杂数学计算,这是符合预期的。这说明百度确实是在用 LLM 模型解决问题。
但当问题无解时,事情有意思起来。
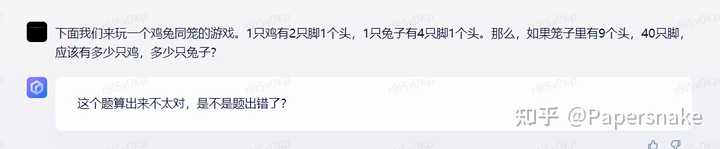

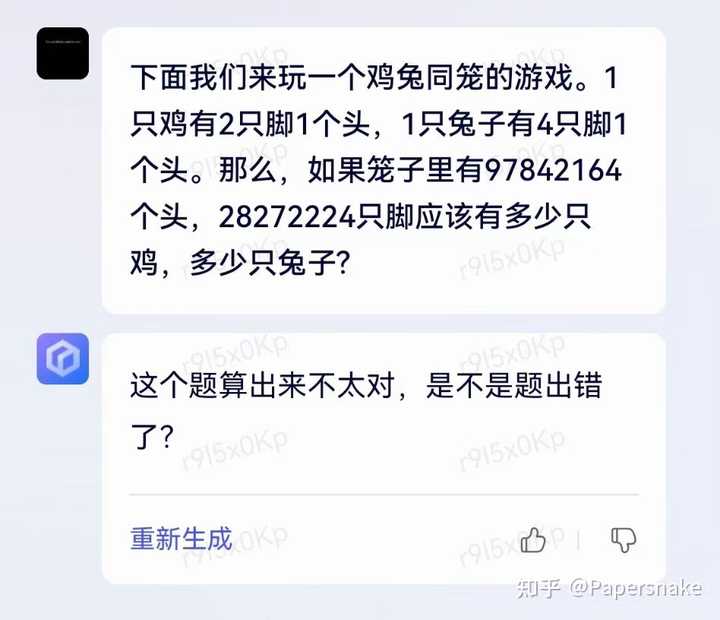

模型准确的知道问题无解,而这大概率说明百度用模板匹配鸡兔同笼问题,首先判断模型有解才让对话模型回答,营造出好像解数学题能力很强的样子。
假如假设正确,我们应该可以得到几个推论:
- 模型并不真的知道解方程,只是背下来了鸡兔同笼问题
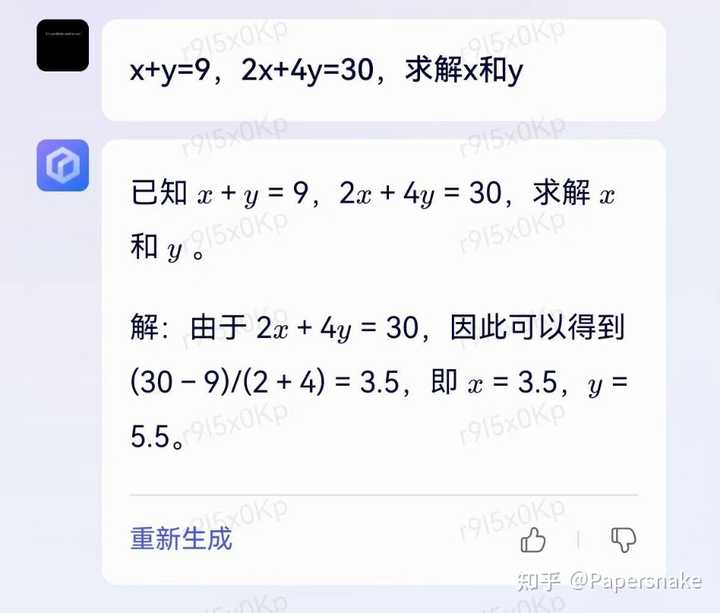

2. 当回答无解时,模型并不知道为什么无解
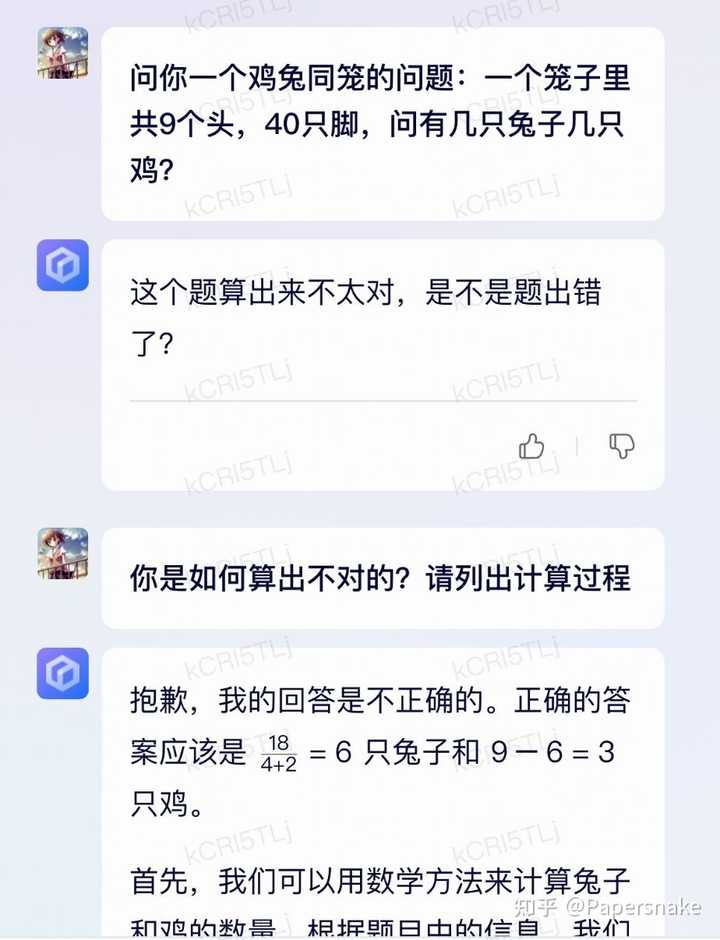

3. 既然模板会判断是否是鸡兔同笼问题,那换个名字是不是就可以绕过了
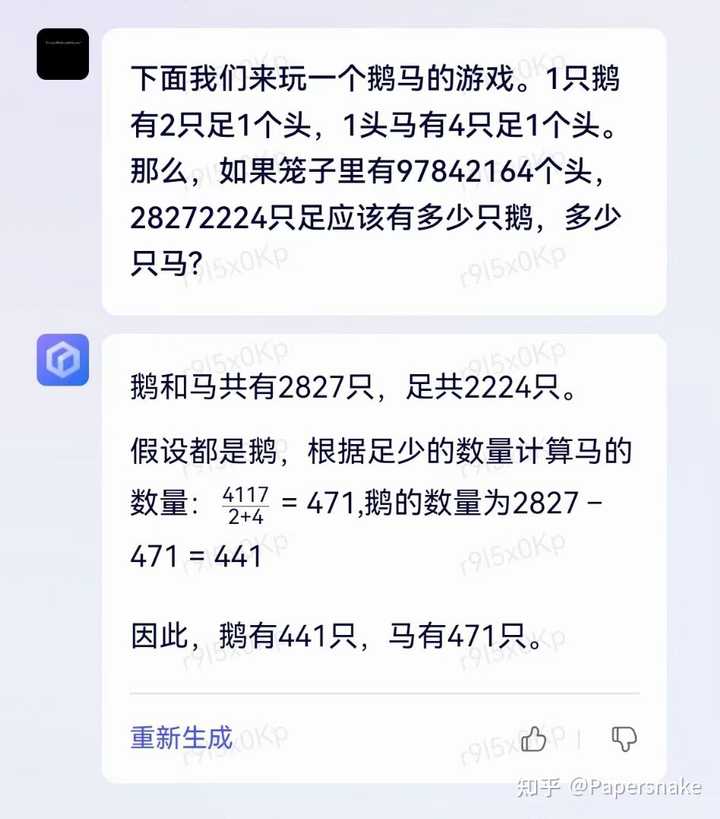

文心一言做的问题匹配机制不是个坏设计,它将用户的输入分解成文生图、语音、视频等任务,或者遇到不能/不应该回答的直接拒绝。但用来匹配用户是否问了鸡兔同笼问题,还用来演示,多少有点取巧了。
题外话:拥有这么多中文数据的百度训出的模型在中文上的表现太弱了,实在是不应该。


最后,GPT-4 真的领先国内太多了,希望百度和国内其他公司能把心思放在怎么增强模型基础能力上吧。