能不能只要训练集和测试集,不要验证集呢?
30 个回答

初学者对于训练集(train set)、测试集(test set)、验证集(validation set)这三个概念和应用非常容易搞混,这里我结合各种博文和书籍上的讲解进行总结:
训练集
参与训练,模型从训练集中学习经验,从而不断减小训练误差。这个最容易理解,一般没什么疑惑。
验证集
不参与训练,用于在训练过程中检验模型的状态,收敛情况。验证集通常用于调整超参数,根据几组模型验证集上的表现决定哪组超参数拥有最好的性能。
同时验证集在训练过程中还可以用来监控模型是否发生过拟合,一般来说验证集表现稳定后,若继续训练,训练集表现还会继续上升,但是验证集会出现不升反降的情况,这样一般就发生了过拟合。所以验证集也用来判断何时停止训练。
测试集
不参与训练,用于在训练结束后对模型进行测试,评估其泛化能力。在之前模型使用【验证集】确定了【超参数】,使用【训练集】调整了【可训练参数】,最后使用一个从没有见过的数据集来判断这个模型的好坏。 需要十分注意的是:测试集仅用于最终评价模型的好坏,在测试集上得到的指标可以用来和别人训练的模型做对比,或者用来向别人报告你的模型效果如何。切记千万不能根据模型在测试集上的指标调整模型超参数(这是验证集应该干的事情),这会导致模型对测试集过拟合,使得测试集失去其测试效果的客观性和准确性。
三者区别
为了方便理解,人们常常把这三种数据集类比成学生的课本、作业和期末考:
- 训练集——课本,学生根据课本里的内容来掌握知识
- 验证集——作业,通过作业可以知道不同学生实时的学习情况、进步的速度快慢
- 测试集——考试,考的题是平常都没有见过,考察学生举一反三的能力
交叉验证
这里摘自:https://ph0en1xgseek.github.io/2018/04/01/cross_validation/
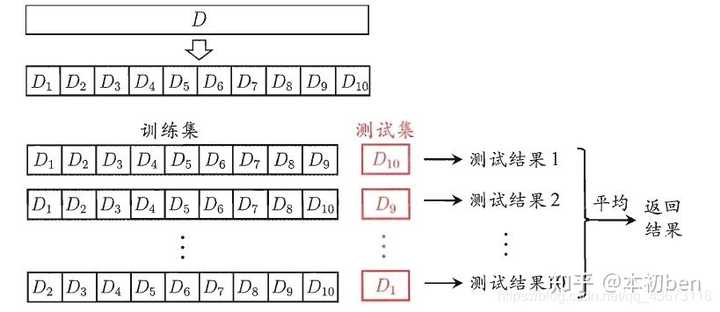
以上将数据集随机地划分成训练集、验证集、测试集三部分对于有足够多数据的情况下是有效的,数据量较小时可以采用交叉验证的方法。 交叉验证法的作用就是尝试利用不同的训练集/测试集划分来对模型做多组不同的训练/测试,来应对单次测试结果过于片面以及训练数据不足的问题。
交叉验证的做法就是将数据集粗略地分为比较均等不相交的k份,即

然后取其中的一份进行测试,另外的k-1份进行训练,然后求得error的平均值作为最终的评价,具体算法流程西瓜书中的插图如下:

以上,如果有总结的不到位的地方欢迎指出。
一些清晰的总结和体会
最近看了sklearn用户指南里的交叉验证:评估估计器性能,有一些更明确的体会记录在这,或许能帮助一些看完上面部分内容仍然有些懵懂的同学更好地理解。
我们都知道用相同的数据集训练和测试模型存在方法论的错误——一个模型只会重复它刚刚看到的样本的标签,会获得完美的分数,但无法很好地预测它没见过的数据,这就是过拟合。 于是人们将数据集划分成完全独立的两部分——训练集和测试集。在训练集上训练,通常会多次调整模型超参数然后进行训练,得到多个训练后的模型,然后用测试集评估这些模型,并根据评估结果选择“最优”的模型。但是要注意,当我们根据测试集的评估效果去选择模型时,实质上是我们人类主观上想让模型对测试集也更好地拟合,这就导致了测试集发生“数据泄露”,即模型在测试集上也有一定程度的过拟合,虽然这种过拟合可能并没有在训练数据上的过拟合严重。但这是我们用我们人工选出来的测试集上的最优评估指标已经不能再客观地评价模型地好坏了,那这个指标来跟别人的模型做对比显然是不合适的了。
于是人们又将数据划分成三部分——训练集、验证集、测试集。用这里的验证集代替上面所说的“测试集”来选择最优模型,然后再用测试集评估选择出来的模型,得到一个客观的评价指标。
然后再讲讲交叉验证(此处以最常用的N折交叉验证为例):当我们的数据很少时,假如一共只有20个数据,这时我们按照6:2:2划分训练集、验证集、测试集的话,三个数据集的数据量分别只有12、4、4。这种情况下我们20个数据里只有12个可以用来训练模型了,让本不富裕的家庭雪上加霜,同时测试集和验证集分别也只有4个,用他们来选择和评估模型显然是不怎么可信的——因为可能存在很大的偶然因素。这种情况下采用交叉验证的方式就可以一定程度上解决上面这种窘境,充分地利用我们的数据集。交叉验证不需要验证集,只有训练集和测试集。(以上是对N折交叉验证的一种片面理解,想要更全面地掌握N折交叉验证地作用,推荐阅读这篇文章:王亮:N折交叉验证的作用(如何使用交叉验证)。)
