SAM出了之后,研一刚确定遥感图像语义分割方向的小白还有得做吗?可以往哪方面靠啊?
4 个回答

[toc]
1. 简介
- Segment Anything使用了11 million images and 1.1 billion masks 来进行训练
- segment anything.com/dataset/index.html

- SAM与传统单纯的语义分割方式不同,加入了Prompt机制,可以将文字、坐标点、坐标框等作为辅助信息优化分割结果,
- 下载model checkpoint
2. 可选的模型类型
## default or vit_h: ViT-H SAM model.
vit_l: ViT-L SAM model.
vit_b: ViT-B SAM model.3. 导入模型
## from segment_anything import sam_model_registry
sam = sam_model_registry["vit_h"](checkpoint="models/sam_vit_h_4b8939.pth")- 这里需要注意,模型的名称需要用小写才行
4. demo
代码
### import numpy as np
import torch
import matplotlib.pyplot as plt
import cv2
import sys
# sys.path.append("..")
from segment_anything import sam_model_registry, SamPredictor
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels == 1]
neg_points = coords[labels == 0]
ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white',
linewidth=1.25)
ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white',
linewidth=1.25)
def show_box(box, ax):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0, 0, 0, 0), lw=2))
image = cv2.imread('notebooks/images/truck.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(10,10))
plt.imshow(image)
plt.axis('on')
plt.show()
sam_checkpoint = "models/sam_vit_b_01ec64.pth"
model_type = "vit_b"
device = "cuda"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
predictor = SamPredictor(sam)
input_point = np.array([[500, 375]])
input_label = np.array([1])
plt.figure(figsize=(10,10))
plt.imshow(image)
show_points(input_point, input_label, plt.gca())
plt.axis('on')
plt.show()
predictor.set_image(image) # 设置要分割的图像
masks, scores, logits = predictor.predict(
point_coords=input_point,
point_labels=input_label,
multimask_output=True,
)
for i, (mask, score) in enumerate(zip(masks, scores)):
plt.figure(figsize=(10, 10))
plt.imshow(image)
show_mask(mask, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.title(f"Mask {i + 1}, Score: {score:.3f}", fontsize=18)
plt.axis('off')
plt.show()





论文信息:
GeoSAM: Fine-tuning SAM with Sparse and Dense Visual Prompting for Automated Segmentation of Mobility Infrastructure [Paper]
摘要:
The Segment Anything Model (SAM) has shown impressive performance when applied to natural image segmentation. However, it struggles with geographical images like aerial and satellite imagery, especially when segmenting mobility infrastructure including roads, sidewalks, and crosswalks. This inferior performance stems from the narrow features of these objects, their textures blending into the surroundings, and interference from objects like trees, buildings, vehicles, and pedestrians - all of which can disorient the model to produce inaccurate segmentation maps. To address these challenges, we propose Geographical SAM (GeoSAM), a novel SAM-based framework that implements a fine-tuning strategy using the dense visual prompt from zero-shot learning, and the sparse visual prompt from a pre-trained CNN segmentation model. The proposed GeoSAM outperforms existing approaches for geographical image segmentation, specifically by 20%, 14.29%, and 17.65% for road infrastructure, pedestrian infrastructure, and on average, respectively, representing a momentous leap in leveraging foundation models to segment mobility infrastructure including both road and pedestrian infrastructure in geographical images.
SAM(Segment Anything Model)在自然图像分割方面表现出色,但在处理地理图像(如航拍和卫星图像)时却遇到困难,特别是在分割道路、人行道和斑马线等移动性基础设施时。这种性能不佳的原因在于这些对象的特征狭窄,它们的纹理与周围环境融合,以及树木、建筑物、车辆和行人等物体的干扰——所有这些都可能使模型产生不准确的分割图。为了解决这些挑战,我们提出了GeoSAM,这是一个基于SAM的新框架,它实现了一种微调策略,使用来自零样本学习的密集视觉提示和来自预训练CNN分割模型的稀疏视觉提示。我们提出的GeoSAM在地理图像分割方面优于现有方法,特别是在道路基础设施、行人基础设施和平均水平上分别提高了20%、14.29%和17.65%,这代表了在利用基础模型分割地理图像中的道路和行人基础设施方面的重大进步。
贡献点:
- 我们率先将基础模型SAM适用于使用地理图像的移动性基础设施分割,无需任何人工干预,克服了零样本SAM的局限性overcome the limitations of zero-shot SAM。
- 我们开发了针对地理图像的SAM微调和提示技术,通过利用稀疏和密集提示,使SAM获得了特定于领域的知识。
- 我们设计并实施了一个新颖的自动化的pipeline,以生成来自零样本学习的密集提示和来自预训练CNN编码器的稀疏提示,以提高SAM在表现不佳的移动性基础设施分割任务上的有效性和效率。
方法:
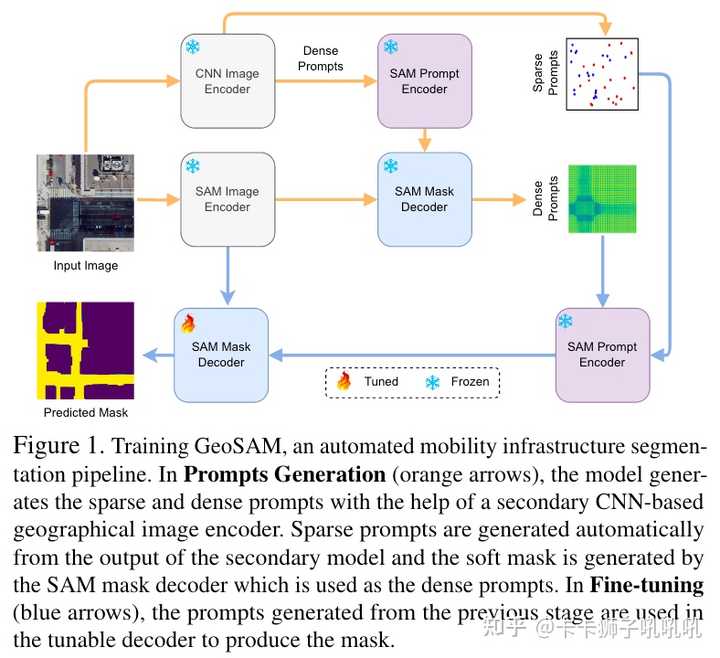
- Prompts Generation:
- 以SAM为框架的,利用了SAM-Image Encoder/Mask Decoder,以及SAM-Sparse和Dense Prompts(提供上下文信息contextual information);
- Sparse Prompts Generation:利用pre-trained model Tile2Net,随机选取,foreground:background=2:1
- Dense Prompts Generation:整个过程中产生了两次Dense Prompts,一次是利用pre-trained model Tile2Net产生一个与(64,64,256)等大的map,输出到SAM Mask Decoder里面,再产生一个非阈值的概率图unthresholded prediction;
- Fine-Tuning:Dice Loss + Focal Loss,全调Decoder,mIou评价指标
- Inference Pipeline:Finetune后的Decoder+自动获取的Prompts

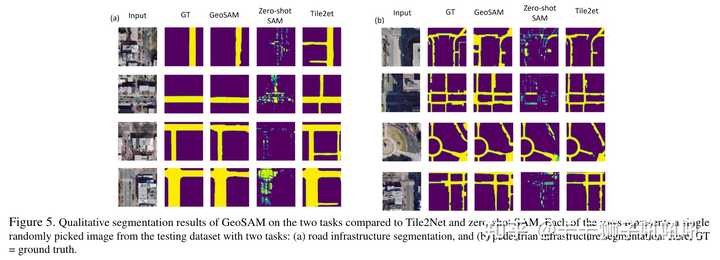
实验效果