哪里有标准的机器学习术语(翻译)对照表?
2 个回答

在网络上收集了到了2个资料,对比了它们对Pooling的翻译,其中来自机器之心翻译为汇聚,似乎更能体会在CNN中的物理含义,更好理解。
1、机器之心
其致谢中提到了,主要由国内的机器学习大神们参与校对,翻译工作。权威,值得参考:
- Aston Zhang 博士,《动手学深度学习》作者
- 李航博士,《统计学习方法》作者
- 李沐博士,《动手学深度学习》作者
- 邱锡鹏教授,《神经网络与深度学习》作者
- 周志华教授,《机器学习》作者
2、机器学习课程术语表
链接:机器学习课程术语表
涉及24个分类,非常全,也值得参考。由于是网页版本,大家可以直接使用(文中未贴出明细)
| 序号 类别 1 机器学习基础 2 机器学习理论 3 Applied Math 4 SVM 5 Ensemble 6 DNN 7 Regularization 8 Matrix Factorization 9 Optimization 10 CNN 11 Auto Encoder 12 RNN 13 Representation 14 Network Embedding 15 GAN 16 Adversarial Learning 17 Online Learning 18 Reinforcement Learning 19 AutoML 20 Graphic Model 21 Topic Model 22 MCMC 23 Mean-Field 24 non-parametric models |
|---|
摘取了机器之心术语,供大家参考:
详情请参考:GitHub链接
| 序号 英文术语 中文翻译 常用缩写 1 0-1 Loss Function 0-1损失函数 2 Accept-Reject Sampling Method 接受-拒绝抽样法/接受-拒绝采样法 3 Accumulated Error Backpropagation 累积误差反向传播 4 Accuracy 精度 5 Acquisition Function 采集函数 6 Action 动作 7 Activation Function 激活函数 8 Active Learning 主动学习 9 Adaptive Bitrate Algorithm 自适应比特率算法 ABR 10 Adaptive Boosting AdaBoost 11 Adaptive Gradient Algorithm AdaGrad 12 Adaptive Moment Estimation Algorithm Adam算法 Adam 13 Adaptive Resonance Theory 自适应谐振理论 ART 14 Additive Model 加性模型 15 Affinity Matrix 亲和矩阵 16 Agent 智能体 17 Algorithm 算法 18 Alpha-Beta Pruning α-β修剪法 19 Anomaly Detection 异常检测 20 Approximate Inference 近似推断 21 Area Under ROC Curve AUC AUC 22 Artificial Intelligence 人工智能 AI 23 Artificial Neural Network 人工神经网络 ANN 24 Artificial Neuron 人工神经元 25 Attention 注意力 26 Attention Mechanism 注意力机制 27 Attribute 属性 28 Attribute Space 属性空间 29 Autoencoder 自编码器 AE 30 Automatic Differentiation 自动微分 AD 31 Autoregressive Model 自回归模型 AR 32 Back Propagation 反向传播 BP 33 Back Propagation Algorithm 反向传播算法 34 Back Propagation Through Time 随时间反向传播 BPTT 35 Backward Induction 反向归纳 36 Backward Search 反向搜索 37 Bag of Words 词袋 BOW 38 Bandit 赌博机/老虎机 39 Base Learner 基学习器 40 Base Learning Algorithm 基学习算法 41 Baseline 基准 42 Batch 批量 43 Batch Normalization 批量规范化 BN 44 Bayes Decision Rule 贝叶斯决策准则 45 Bayes Model Averaging 贝叶斯模型平均 BMA 46 Bayes Optimal Classifier 贝叶斯最优分类器 47 Bayes' Theorem 贝叶斯定理 48 Bayesian Decision Theory 贝叶斯决策理论 49 Bayesian Inference 贝叶斯推断 50 Bayesian Learning 贝叶斯学习 51 Bayesian Network 贝叶斯网/贝叶斯网络 52 Bayesian Optimization 贝叶斯优化 53 Beam Search 束搜索 54 Benchmark 基准 55 Belief Network 信念网/信念网络 BN 56 Belief Propagation 信念传播 BP 57 Bellman Equation 贝尔曼方程 58 Bernoulli Distribution 伯努利分布 59 Beta Distribution 贝塔分布 60 Between-Class Scatter Matrix 类间散度矩阵 61 BFGS BFGS 62 Bias 偏差/偏置 63 Bias In Affine Function 偏置 64 Bias In Statistics 偏差 65 Bias Shift 偏置偏移 66 Bias-Variance Decomposition 偏差 - 方差分解 67 Bias-Variance Dilemma 偏差 - 方差困境 68 Bidirectional Recurrent Neural Network 双向循环神经网络 Bi-RNN 69 Bigram 二元语法 70 Bilingual Evaluation Understudy BLEU 71 Binary Classification 二分类 72 Binomial Distribution 二项分布 73 Binomial Test 二项检验 74 Boltzmann Distribution 玻尔兹曼分布 75 Boltzmann Machine 玻尔兹曼机 76 Boosting Boosting 77 Bootstrap Aggregating Bagging 78 Bootstrap Sampling 自助采样法 79 Bootstrapping 自助法/自举法 80 Break-Event Point 平衡点 BEP 81 Bucketing 分桶 82 Calculus of Variations 变分法 83 Cascade-Correlation 级联相关 84 Catastrophic Forgetting 灾难性遗忘 85 Categorical Distribution 类别分布 86 Cell 单元 87 Chain Rule 链式法则 88 Chebyshev Distance 切比雪夫距离 89 Class 类别 90 Class-Imbalance 类别不平衡 91 Classification 分类 92 Classification And Regression Tree 分类与回归树 CART 93 Classifier 分类器 94 Clique 团 95 Cluster 簇 96 Cluster Assumption 聚类假设 97 Clustering 聚类 98 Clustering Ensemble 聚类集成 99 Co-Training 协同训练 100 Coding Matrix 编码矩阵 101 Collaborative Filtering 协同过滤 102 Competitive Learning 竞争型学习 103 Comprehensibility 可解释性 104 Computation Graph 计算图 105 Computational Learning Theory 计算学习理论 106 Conditional Entropy 条件熵 107 Conditional Probability 条件概率 108 Conditional Probability Distribution 条件概率分布 109 Conditional Random Field 条件随机场 CRF 110 Conditional Risk 条件风险 111 Confidence 置信度 112 Confusion Matrix 混淆矩阵 113 Conjugate Distribution 共轭分布 114 Connection Weight 连接权 115 Connectionism 连接主义 116 Consistency 一致性 117 Constrained Optimization 约束优化 118 Context Variable 上下文变量 119 Context Vector 上下文向量 120 Context Window 上下文窗口 121 Context Word 上下文词 122 Contextual Bandit 上下文赌博机/上下文老虎机 123 Contingency Table 列联表 124 Continuous Attribute 连续属性 125 Contrastive Divergence 对比散度 126 Convergence 收敛 127 Convex Optimization 凸优化 128 Convex Quadratic Programming 凸二次规划 129 Convolution 卷积 130 Convolutional Kernel 卷积核 131 Convolutional Neural Network 卷积神经网络 CNN 132 Coordinate Descent 坐标下降 133 Corpus 语料库 134 Correlation Coefficient 相关系数 135 Cosine Similarity 余弦相似度 136 Cost 代价 137 Cost Curve 代价曲线 138 Cost Function 代价函数 139 Cost Matrix 代价矩阵 140 Cost-Sensitive 代价敏感 141 Covariance 协方差 142 Covariance Matrix 协方差矩阵 143 Critical Point 临界点 144 Cross Entropy 交叉熵 145 Cross Validation 交叉验证 146 Curse of Dimensionality 维数灾难 147 Cutting Plane Algorithm 割平面法 148 Data Mining 数据挖掘 149 Data Set 数据集 150 Davidon-Fletcher-Powell DFP 151 Decision Boundary 决策边界 152 Decision Function 决策函数 153 Decision Stump 决策树桩 154 Decision Tree 决策树 155 Decoder 解码器 156 Decoding 解码 157 Deconvolution 反卷积 158 Deconvolutional Network 反卷积网络 159 Deduction 演绎 160 Deep Belief Network 深度信念网络 DBN 161 Deep Boltzmann Machine 深度玻尔兹曼机 DBM 162 Deep Convolutional Generative Adversarial Network 深度卷积生成对抗网络 DCGAN 163 Deep Learning 深度学习 DL 164 Deep Neural Network 深度神经网络 DNN 165 Deep Q-Network 深度Q网络 DQN 166 Delta-Bar-Delta Delta-Bar-Delta 167 Denoising 去噪 168 Denoising Autoencoder 去噪自编码器 169 Denoising Score Matching 去躁分数匹配 170 Density Estimation 密度估计 171 Density-Based Clustering 密度聚类 172 Derivative 导数 173 Determinant 行列式 174 Diagonal Matrix 对角矩阵 175 Dictionary Learning 字典学习 176 Dimension Reduction 降维 177 Directed Edge 有向边 178 Directed Graphical Model 有向图模型 179 Directed Separation 有向分离 180 Dirichlet Distribution 狄利克雷分布 181 Discriminative Model 判别式模型 182 Discriminator 判别器 183 Discriminator Network 判别网络 184 Distance Measure 距离度量 185 Distance Metric Learning 距离度量学习 186 Distributed Representation 分布式表示 187 Diverge 发散 188 Divergence 散度 189 Diversity 多样性 190 Diversity Measure 多样性度量/差异性度量 191 Domain Adaptation 领域自适应 192 Dominant Strategy 主特征值 193 Dominant Strategy 占优策略 194 Down Sampling 下采样 195 Dropout 暂退法 196 Dropout Boosting 暂退Boosting 197 Dropout Method 暂退法 198 Dual Problem 对偶问题 199 Dummy Node 哑结点 200 Dynamic Bayesian Network 动态贝叶斯网络 201 Dynamic Programming 动态规划 202 Early Stopping 早停 203 Eigendecomposition 特征分解 204 Eigenvalue 特征值 205 Element-Wise Product 逐元素积 206 Embedding 嵌入 207 Empirical Conditional Entropy 经验条件熵 208 Empirical Distribution 经验分布 209 Empirical Entropy 经验熵 210 Empirical Error 经验误差 211 Empirical Risk 经验风险 212 Empirical Risk Minimization 经验风险最小化 ERM 213 Encoder 编码器 214 Encoding 编码 215 End-To-End 端到端 216 Energy Function 能量函数 217 Energy-Based Model 基于能量的模型 218 Ensemble Learning 集成学习 219 Ensemble Pruning 集成修剪 220 Entropy 熵 221 Episode 回合 222 Epoch 轮 223 Error 误差 224 Error Backpropagation Algorithm 误差反向传播算法 225 Error Backpropagation 误差反向传播 226 Error Correcting Output Codes 纠错输出编码 ECOC 227 Error Rate 错误率 228 Error-Ambiguity Decomposition 误差-分歧分解 229 Estimator 估计/估计量 230 Euclidean Distance 欧氏距离 231 Evidence 证据 232 Evidence Lower Bound 证据下界 ELBO 233 Exact Inference 精确推断 234 Example 样例 235 Expectation 期望 236 Expectation Maximization 期望最大化 EM 237 Expected Loss 期望损失 238 Expert System 专家系统 239 Exploding Gradient 梯度爆炸 240 Exponential Loss Function 指数损失函数 241 Factor 因子 242 Factorization 因子分解 243 Feature 特征 244 Feature Engineering 特征工程 245 Feature Map 特征图 246 Feature Selection 特征选择 247 Feature Vector 特征向量 248 Featured Learning 特征学习 249 Feedforward 前馈 250 Feedforward Neural Network 前馈神经网络 FNN 251 Few-Shot Learning 少试学习 252 Filter 滤波器 253 Fine-Tuning 微调 254 Fluctuation 振荡 255 Forget Gate 遗忘门 256 Forward Propagation 前向传播/正向传播 257 Forward Stagewise Algorithm 前向分步算法 258 Fractionally Strided Convolution 微步卷积 259 Frobenius Norm Frobenius 范数 260 Full Padding 全填充 261 Functional 泛函 262 Functional Neuron 功能神经元 263 Gated Recurrent Unit 门控循环单元 GRU 264 Gated RNN 门控RNN 265 Gaussian Distribution 高斯分布 266 Gaussian Kernel 高斯核 267 Gaussian Kernel Function 高斯核函数 268 Gaussian Mixture Model 高斯混合模型 GMM 269 Gaussian Process 高斯过程 270 Generalization Ability 泛化能力 271 Generalization Error 泛化误差 272 Generalization Error Bound 泛化误差上界 273 Generalize 泛化 274 Generalized Lagrange Function 广义拉格朗日函数 275 Generalized Linear Model 广义线性模型 276 Generalized Rayleigh Quotient 广义瑞利商 277 Generative Adversarial Network 生成对抗网络 278 Generative Model 生成式模型 279 Generator 生成器 280 Generator Network 生成器网络 281 Genetic Algorithm 遗传算法 GA 282 Gibbs Distribution 吉布斯分布 283 Gibbs Sampling 吉布斯采样/吉布斯抽样 284 Gini Index 基尼指数 285 Global Markov Property 全局马尔可夫性 286 Global Minimum 全局最小 287 Gradient 梯度 288 Gradient Clipping 梯度截断 289 Gradient Descent 梯度下降 290 Gradient Descent Method 梯度下降法 291 Gradient Exploding Problem 梯度爆炸问题 292 Gram Matrix Gram 矩阵 293 Graph Convolutional Network 图卷积神经网络/图卷积网络 GCN 294 Graph Neural Network 图神经网络 GNN 295 Graphical Model 图模型 GM 296 Grid Search 网格搜索 297 Ground Truth 真实值 298 Hadamard Product Hadamard积 299 Hamming Distance 汉明距离 300 Hard Margin 硬间隔 301 Hebbian Rule 赫布法则 302 Hidden Layer 隐藏层 303 Hidden Markov Model 隐马尔可夫模型 HMM 304 Hidden Variable 隐变量 305 Hierarchical Clustering 层次聚类 306 Hilbert Space 希尔伯特空间 307 Hinge Loss Function 合页损失函数/Hinge损失函数 308 Hold-Out 留出法 309 Hyperparameter 超参数 310 Hyperparameter Optimization 超参数优化 311 Hypothesis 假设 312 Hypothesis Space 假设空间 313 Hypothesis Test 假设检验 314 Identity Matrix 单位矩阵 315 Imitation Learning 模仿学习 316 Importance Sampling 重要性采样 317 Improved Iterative Scaling 改进的迭代尺度法 IIS 318 Incremental Learning 增量学习 319 Independent and Identically Distributed 独立同分布 I.I.D. 320 Indicator Function 指示函数 321 Individual Learner 个体学习器 322 Induction 归纳 323 Inductive Bias 归纳偏好 324 Inductive Learning 归纳学习 325 Inductive Logic Programming 归纳逻辑程序设计 ILP 326 Inference 推断 327 Information Entropy 信息熵 328 Information Gain 信息增益 329 Inner Product 内积 330 Instance 示例 331 Internal Covariate Shift 内部协变量偏移 332 Inverse Matrix 逆矩阵 333 Inverse Resolution 逆归结 334 Isometric Mapping 等度量映射 Isomap 335 Jacobian Matrix 雅可比矩阵 336 Jensen Inequality Jensen不等式 337 Joint Probability Distribution 联合概率分布 338 K-Armed Bandit Problem k-摇臂老虎机 339 K-Fold Cross Validation k 折交叉验证 340 Karush-Kuhn-Tucker Condition KKT条件 341 Karush–Kuhn–Tucker Karush–Kuhn–Tucker 342 Kernel Function 核函数 343 Kernel Method 核方法 344 Kernel Trick 核技巧 345 Kernelized Linear Discriminant Analysis 核线性判别分析 KLDA 346 KL Divergence KL散度 347 L-BFGS L-BFGS 348 Label 标签/标记 349 Label Space 标记空间 350 Lagrange Duality 拉格朗日对偶性 351 Lagrange Multiplier 拉格朗日乘子 352 Language Model 语言模型 353 Laplace Smoothing 拉普拉斯平滑 354 Laplacian Correction 拉普拉斯修正 355 Latent Dirichlet Allocation 潜在狄利克雷分配 LDA 356 Latent Semantic Analysis 潜在语义分析 LSA 357 Latent Variable 潜变量/隐变量 358 Law of Large Numbers 大数定律 359 Layer Normalization 层规范化 360 Lazy Learning 懒惰学习 361 Leaky Relu 泄漏修正线性单元/泄漏整流线性单元 362 Learner 学习器 363 Learning 学习 364 Learning By Analogy 类比学习 365 Learning Rate 学习率 366 Learning Vector Quantization 学习向量量化 LVQ 367 Least Square Method 最小二乘法 LSM 368 Least Squares Regression Tree 最小二乘回归树 369 Left Singular Vector 左奇异向量 370 Likelihood 似然 371 Linear Chain Conditional Random Field 线性链条件随机场 372 Linear Classification Model 线性分类模型 373 Linear Classifier 线性分类器 374 Linear Dependence 线性相关 375 Linear Discriminant Analysis 线性判别分析 LDA 376 Linear Model 线性模型 377 Linear Regression 线性回归 378 Link Function 联系函数 379 Local Markov Property 局部马尔可夫性 380 Local Minima 局部极小 381 Local Minimum 局部极小 382 Local Representation 局部式表示/局部式表征 383 Log Likelihood 对数似然函数 384 Log Linear Model 对数线性模型 385 Log-Likelihood 对数似然 386 Log-Linear Regression 对数线性回归 387 Logistic Function 对数几率函数 388 Logistic Regression 对数几率回归 LR 389 Logit 对数几率 390 Long Short Term Memory 长短期记忆 LSTM 391 Long Short-Term Memory Network 长短期记忆网络 LSTM 392 Loopy Belief Propagation 环状信念传播 LBP 393 Loss Function 损失函数 394 Low Rank Matrix Approximation 低秩矩阵近似 395 Machine Learning 机器学习 ML 396 Macron-R 宏查全率 397 Manhattan Distance 曼哈顿距离 398 Manifold 流形 399 Manifold Assumption 流形假设 400 Manifold Learning 流形学习 401 Margin 间隔 402 Marginal Distribution 边缘分布 403 Marginal Independence 边缘独立性 404 Marginalization 边缘化 405 Markov Chain 马尔可夫链 406 Markov Chain Monte Carlo 马尔可夫链蒙特卡罗 MCMC 407 Markov Decision Process 马尔可夫决策过程 MDP 408 Markov Network 马尔可夫网络 409 Markov Process 马尔可夫过程 410 Markov Random Field 马尔可夫随机场 MRF 411 Mask 掩码 412 Matrix 矩阵 413 Matrix Inversion 逆矩阵 414 Max Pooling 最大汇聚 415 Maximal Clique 最大团 416 Maximum Entropy Model 最大熵模型 417 Maximum Likelihood Estimation 极大似然估计 MLE 418 Maximum Margin 最大间隔 419 Mean Filed 平均场 420 Mean Pooling 平均汇聚 421 Mean Squared Error 均方误差 422 Mean-Field 平均场 423 Memory Network 记忆网络 MN 424 Message Passing 消息传递 425 Metric Learning 度量学习 426 Micro-R 微查全率 427 Minibatch 小批量 428 Minimal Description Length 最小描述长度 MDL 429 Minimax Game 极小极大博弈 430 Minkowski Distance 闵可夫斯基距离 431 Mixture of Experts 混合专家模型 432 Mixture-of-Gaussian 高斯混合 433 Model 模型 434 Model Selection 模型选择 435 Momentum Method 动量法 436 Monte Carlo Method 蒙特卡罗方法 437 Moral Graph 端正图/道德图 438 Moralization 道德化 439 Multi-Class Classification 多分类 440 Multi-Head Attention 多头注意力 441 Multi-Head Self-Attention 多头自注意力 442 Multi-Kernel Learning 多核学习 443 Multi-Label Learning 多标记学习 444 Multi-Layer Feedforward Neural Networks 多层前馈神经网络 445 Multi-Layer Perceptron 多层感知机 MLP 446 Multinomial Distribution 多项分布 447 Multiple Dimensional Scaling 多维缩放 448 Multiple Linear Regression 多元线性回归 449 Multitask Learning 多任务学习 450 Multivariate Normal Distribution 多元正态分布 451 Mutual Information 互信息 452 N-Gram Model N元模型 453 Naive Bayes Classifier 朴素贝叶斯分类器 454 Naive Bayes 朴素贝叶斯 NB 455 Nearest Neighbor Classifier 最近邻分类器 456 Negative Log Likelihood 负对数似然函数 457 Neighbourhood Component Analysis 近邻成分分析 NCA 458 Net Input 净输入 459 Neural Network 神经网络 NN 460 Neural Turing Machine 神经图灵机 NTM 461 Neuron 神经元 462 Newton Method 牛顿法 463 No Free Lunch Theorem 没有免费午餐定理 NFL 464 Noise-Contrastive Estimation 噪声对比估计 NCE 465 Nominal Attribute 列名属性 466 Non-Convex Optimization 非凸优化 467 Non-Metric Distance 非度量距离 468 Non-Negative Matrix Factorization 非负矩阵分解 NMF 469 Non-Ordinal Attribute 无序属性 470 Norm 范数 471 Normal Distribution 正态分布 472 Normalization 规范化 473 Nuclear Norm 核范数 474 Number of Epochs 轮数 475 Numerical Attribute 数值属性 476 Object Detection 目标检测 477 Oblique Decision Tree 斜决策树 478 Occam's Razor 奥卡姆剃刀 479 Odds 几率 480 Off-Policy 异策略 481 On-Policy 同策略 482 One-Dependent Estimator 独依赖估计 ODE 483 One-Hot 独热 484 Online Learning 在线学习 485 Optimizer 优化器 486 Ordinal Attribute 有序属性 487 Orthogonal 正交 488 Orthogonal Matrix 正交矩阵 489 Out-Of-Bag Estimate 包外估计 490 Outlier 异常点 491 Over-Parameterized 过度参数化 492 Overfitting 过拟合 493 Oversampling 过采样 494 Pac-Learnable PAC可学习 495 Padding 填充 496 Pairwise Markov Property 成对马尔可夫性 497 Parallel Distributed Processing 分布式并行处理 PDP 498 Parameter 参数 499 Parameter Estimation 参数估计 500 Parameter Space 参数空间 501 Parameter Tuning 调参 502 Parametric ReLU 参数化修正线性单元/参数化整流线性单元 PReLU 503 Part-Of-Speech Tagging 词性标注 504 Partial Derivative 偏导数 505 Partially Observable Markov Decision Processes 部分可观测马尔可夫决策过程 POMDP 506 Partition Function 配分函数 507 Perceptron 感知机 508 Performance Measure 性能度量 509 Perplexity 困惑度 510 Pointer Network 指针网络 511 Policy 策略 512 Policy Gradient 策略梯度 513 Policy Iteration 策略迭代 514 Polynomial Kernel Function 多项式核函数 515 Pooling 汇聚 516 Pooling Layer 汇聚层 517 Positive Definite Matrix 正定矩阵 518 Post-Pruning 后剪枝 519 Potential Function 势函数 520 Power Method 幂法 521 Pre-Training 预训练 522 Precision 查准率/准确率 523 Prepruning 预剪枝 524 Primal Problem 主问题 525 Primary Visual Cortex 初级视觉皮层 526 Principal Component Analysis 主成分分析 PCA 527 Prior 先验 528 Probabilistic Context-Free Grammar 概率上下文无关文法 529 Probabilistic Graphical Model 概率图模型 PGM 530 Probabilistic Model 概率模型 531 Probability Density Function 概率密度函数 PDF 532 Probability Distribution 概率分布 533 Probably Approximately Correct 概率近似正确 PAC 534 Proposal Distribution 提议分布 535 Prototype-Based Clustering 原型聚类 536 Proximal Gradient Descent 近端梯度下降 PGD 537 Pruning 剪枝 538 Quadratic Loss Function 平方损失函数 539 Quadratic Programming 二次规划 540 Quasi Newton Method 拟牛顿法 541 Radial Basis Function 径向基函数 RBF 542 Random Forest 随机森林 RF 543 Random Sampling 随机采样 544 Random Search 随机搜索 545 Random Variable 随机变量 546 Random Walk 随机游走 547 Recall 查全率/召回率 548 Receptive Field 感受野 549 Reconstruction Error 重构误差 550 Rectified Linear Unit 修正线性单元/整流线性单元 ReLU 551 Recurrent Neural Network 循环神经网络 RNN 552 Recursive Neural Network 递归神经网络 RecNN 553 Regression 回归 554 Regularization 正则化 555 Regularizer 正则化项 556 Reinforcement Learning 强化学习 RL 557 Relative Entropy 相对熵 558 Reparameterization 再参数化/重参数化 559 Representation 表示 560 Representation Learning 表示学习 561 Representer Theorem 表示定理 562 Reproducing Kernel Hilbert Space 再生核希尔伯特空间 RKHS 563 Rescaling 再缩放 564 Reset Gate 重置门 565 Residual Connection 残差连接 566 Residual Network 残差网络 ResNet 567 Restricted Boltzmann Machine 受限玻尔兹曼机 RBM 568 Reward 奖励 569 Ridge Regression 岭回归 570 Right Singular Vector 右奇异向量 571 Risk 风险 572 Robustness 稳健性 573 Root Node 根结点 574 Rule Learning 规则学习 575 Saddle Point 鞍点 576 Sample 样本 577 Sample Complexity 样本复杂度 578 Sample Space 样本空间 579 Scalar 标量 580 Selective Ensemble 选择性集成 581 Self Information 自信息 582 Self-Attention 自注意力 583 Self-Organizing Map 自组织映射网 SOM 584 Self-Training 自训练 585 Semi-Definite Programming 半正定规划 586 Semi-Naive Bayes Classifiers 半朴素贝叶斯分类器 587 Semi-Restricted Boltzmann Machine 半受限玻尔兹曼机 588 Semi-Supervised Clustering 半监督聚类 589 Semi-Supervised Learning 半监督学习 590 Semi-Supervised Support Vector Machine 半监督支持向量机 S3VM 591 Sentiment Analysis 情感分析 592 Separating Hyperplane 分离超平面 593 Sequential Covering 序贯覆盖 594 Sigmoid Belief Network Sigmoid信念网络 SBN 595 Sigmoid Function Sigmoid函数 596 Signed Distance 带符号距离 597 Similarity Measure 相似度度量 598 Simulated Annealing 模拟退火 599 Simultaneous Localization And Mapping 即时定位与地图构建 SLAM 600 Singular Value 奇异值 601 Singular Value Decomposition 奇异值分解 SVD 602 Skip-Gram Model 跳元模型 603 Smoothing 平滑 604 Soft Margin 软间隔 605 Soft Margin Maximization 软间隔最大化 606 Softmax Softmax/软最大化 607 Softmax Function Softmax函数/软最大化函数 608 Softmax Regression Softmax回归/软最大化回归 609 Softplus Function Softplus函数 610 Span 张成子空间 611 Sparse Coding 稀疏编码 612 Sparse Representation 稀疏表示 613 Sparsity 稀疏性 614 Specialization 特化 615 Splitting Variable 切分变量 616 Squashing Function 挤压函数 617 Standard Normal Distribution 标准正态分布 618 State 状态 619 State Value Function 状态值函数 620 State-Action Value Function 状态-动作值函数 621 Stationary Distribution 平稳分布 622 Stationary Point 驻点 623 Statistical Learning 统计学习 624 Steepest Descent 最速下降法 625 Stochastic Gradient Descent 随机梯度下降 626 Stochastic Matrix 随机矩阵 627 Stochastic Process 随机过程 628 Stratified Sampling 分层采样 629 Stride 步幅 630 Structural Risk 结构风险 631 Structural Risk Minimization 结构风险最小化 SRM 632 Subsample 子采样 633 Subsampling 下采样 634 Subset Search 子集搜索 635 Subspace 子空间 636 Supervised Learning 监督学习 637 Support Vector 支持向量 638 Support Vector Expansion 支持向量展式 639 Support Vector Machine 支持向量机 SVM 640 Surrogat Loss 替代损失 641 Surrogate Function 替代函数 642 Surrogate Loss Function 代理损失函数 643 Symbolism 符号主义 644 Tangent Propagation 正切传播 645 Teacher Forcing 强制教学 646 Temporal-Difference Learning 时序差分学习 647 Tensor 张量 648 Test Error 测试误差 649 Test Sample 测试样本 650 Test Set 测试集 651 Threshold 阈值 652 Threshold Logic Unit 阈值逻辑单元 653 Threshold-Moving 阈值移动 654 Tied Weight 捆绑权重 655 Tikhonov Regularization Tikhonov正则化 656 Time Delay Neural Network 时延神经网络 TDNN 657 Time Homogenous Markov Chain 时间齐次马尔可夫链 658 Time Step 时间步 659 Token 词元 660 Token 词元 661 Tokenization 词元化 662 Tokenizer 词元分析器 663 Topic Model 话题模型 664 Topic Modeling 话题分析 665 Trace 迹 666 Training 训练 667 Training Error 训练误差 668 Training Sample 训练样本 669 Training Set 训练集 670 Transductive Learning 直推学习 671 Transductive Transfer Learning 直推迁移学习 672 Transfer Learning 迁移学习 673 Transformer Transformer 674 Transformer Model Transformer模型 675 Transpose 转置 676 Transposed Convolution 转置卷积 677 Trial And Error 试错 678 Trigram 三元语法 679 Turing Machine 图灵机 680 Underfitting 欠拟合 681 Undersampling 欠采样 682 Undirected Graphical Model 无向图模型 683 Uniform Distribution 均匀分布 684 Unigram 一元语法 685 Unit 单元 686 Universal Approximation Theorem 通用近似定理 687 Universal Approximator 通用近似器 688 Universal Function Approximator 通用函数近似器 689 Unknown Token 未知词元 690 Unsupervised Layer-Wise Training 无监督逐层训练 691 Unsupervised Learning 无监督学习 UL 692 Update Gate 更新门 693 Upsampling 上采样 694 V-Structure V型结构 695 Validation Set 验证集 696 Validity Index 有效性指标 697 Value Function Approximation 值函数近似 698 Value Iteration 值迭代 699 Vanishing Gradient Problem 梯度消失问题 700 Vapnik-Chervonenkis Dimension VC维 701 Variable Elimination 变量消去 702 Variance 方差 703 Variational Autoencoder 变分自编码器 VAE 704 Variational Inference 变分推断 705 Vector 向量 706 Vector Space Model 向量空间模型 VSM 707 Version Space 版本空间 708 Viterbi Algorithm 维特比算法 709 Vocabulary 词表 710 Warp 线程束 711 Weak Learner 弱学习器 712 Weakly Supervised Learning 弱监督学习 713 Weight 权重 714 Weight Decay 权重衰减 715 Weight Sharing 权共享 716 Weighted Voting 加权投票 717 Whitening 白化 718 Winner-Take-All 胜者通吃 719 Within-Class Scatter Matrix 类内散度矩阵 720 Word Embedding 词嵌入 721 Word Sense Disambiguation 词义消歧 722 Word Vector 词向量 723 Zero Padding 零填充 724 Zero-Shot Learning 零试学习 725 Zipf's Law 齐普夫定律 |
|---|

来源:比特小组
Google 官方出品的机器学习中英文术语对照表,列出了一般的机器学习术语和 TensorFlow 专用术语的定义。版权归谷歌。
A
- A/B 测试 (A/B testing)
一种统计方法,用于将两种或多种技术进行比较,通常是将当前采用的技术与新技术进行比较。A/B 测试不仅旨在确定哪种技术的效果更好,而且还有助于了解相应差异是否具有显著的统计意义。A/B 测试通常是采用一种衡量方式对两种技术进行比较,但也适用于任意有限数量的技术和衡量方式。
- 准确率 (Accuracy)
分类模型的正确预测所占的比例。在多类别分类中,准确率的定义如下:


准确率正确的预测数样本总数在二元分类中,准确率的定义如下:


- 激活函数 (Activation Function)
一种函数(例如 ReLU 或 S 型函数),用于对上一层的所有输入求加权和,然后生成一个输出值(通常为非线性值),并将其传递给下一层。
- AdaGrad
一种先进的梯度下降法,用于重新调整每个参数的梯度,以便有效地为每个参数指定独立的学习速率。如需查看完整的解释,请参阅这篇论文[1]。
- ROC 曲线下面积 (AUC, Area under the ROC Curve)
一种会考虑所有可能分类阈值的评估指标。ROC 曲线下面积是,对于随机选择的正类别样本确实为正类别,以及随机选择的负类别样本为正类别,分类器更确信前者的概率。
B
- 反向传播算法 (Back Propagation)
在神经网络上执行梯度下降法的主要算法。该算法会先按前向传播方式计算(并缓存)每个节点的输出值,然后再按反向传播遍历图的方式计算损失函数值相对于每个参数的偏导数[2]。
- 基准 (Baseline)
一种简单的模型或启发法,用作比较模型效果时的参考点。基准有助于模型开发者针对特定问题量化最低预期效果。
- 批次 (Batch)
模型训练的一次迭代(即一次梯度更新)中使用的样本集。另请参阅批次大小。
- 批次大小 (Batch Size)
一个批次中的样本数。例如,SGD 的批次大小为 1,而小批次的大小通常介于 10 到 1000 之间。批次大小在训练和推断期间通常是固定的;不过,TensorFlow 允许使用动态批次大小。
- 偏差 (Bias)
距离原点的截距或偏移。偏差(也称为偏差项)在机器学习模型中用 b 或 w_0 表示。例如,在下面的公式中,偏差为 b :
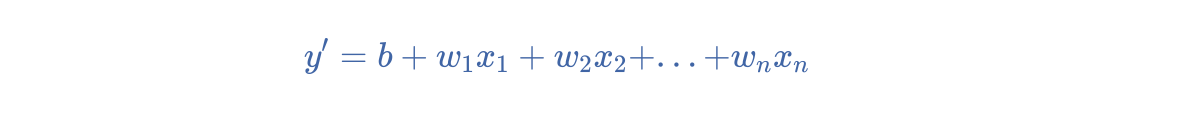

- 二元分类 (Binary Classification)
一种分类任务,可输出两种互斥类别之一。例如,对电子邮件进行评估并输出"垃圾邮件"或"非垃圾邮件"的机器学习模型就是一个二元分类器。
C
- 候选采样 (Candidate Sampling)
一种训练时进行的优化,会使用某种函数(例如 softmax)针对所有正类别标签计算概率,但对于负类别标签,则仅针对其随机样本计算概率。例如,如果某个样本的标签为"小猎犬"和"狗",则候选采样将针对"小猎犬"和"狗"类别输出以及其他类别(猫、棒棒糖、栅栏)的随机子集计算预测概率和相应的损失项。这种采样基于的想法是,只要正类别始终得到适当的正增强,负类别就可以从频率较低的负增强中进行学习,这确实是在实际中观察到的情况。候选采样的目的是,通过不针对所有负类别计算预测结果来提高计算效率。
- 分类数据 (Categorical Data)
一种特征,拥有一组离散的可能值。以某个名为 house style 的分类特征为例,该特征拥有一组离散的可能值(共三个),即 Tudor、 ranch、 colonial。通过将 house style 表示成分类数据,相应模型可以学习 Tudor、ranch 和 colonial 分别对房价的影响。有时,离散集中的值是互斥的,只能将其中一个值应用于指定样本。例如 car maker分类特征可能只允许一个样本有一个值 (Toyota)。在其他情况下,则可以应用多个值。一辆车可能会被喷涂多种不同的颜色,因此,car color分类特征可能会允许单个样本具有多个值(例如 red 和 white)。
分类特征有时称为离散特征,与数值数据相对。
- 形心 (Centroid)
聚类的中心,由 k-means 或 k-median算法决定。例如,如果 k 为 3,则 k-means 或 k-median 算法会找出 3 个形心。
- 检查点 (Checkpoint)
一种数据,用于捕获模型变量在特定时间的状态。借助检查点,可以导出模型权重,跨多个会话执行训练,以及使训练在发生错误之后得以继续(例如作业抢占)。请注意,图本身不包含在检查点中。
- 类别 (Class)
为标签枚举的一组目标值中的一个。例如,在检测垃圾邮件的二元分类模型中,两种类别分别是"垃圾邮件"和"非垃圾邮件"。在识别狗品种的多类别分类模型中,类别可以是"贵宾犬"、"小猎犬"、"哈巴犬"等等。
- 分类不平衡的数据集 (Class-Imbalanced Dataset)
一种二元分类问题,在此类问题中,两种类别的标签在出现频率方面具有很大的差距。例如,在某个疾病数据集中,0.0001 的样本具有正类别标签,0.9999 的样本具有负类别标签,这就属于分类不平衡问题;但在某个足球比赛预测器中,0.51 的样本的标签为其中一个球队赢,0.49 的样本的标签为另一个球队赢,这就不属于分类不平衡问题。
- 分类模型 (Classification Model)
一种机器学习模型,用于区分两种或多种离散类别。例如,某个自然语言处理分类模型可以确定输入的句子是法语、西班牙语还是意大利语。请与回归模型进行比较。
- 分类阈值 (Classification Threshold)
一种标量值条件,应用于模型预测的得分,旨在将正类别与负类别区分开。将逻辑回归结果映射到二元分类时使用。以某个逻辑回归模型为例,该模型用于确定指定电子邮件是垃圾邮件的概率。如果分类阈值为 0.9,那么逻辑回归值高于 0.9 的电子邮件将被归类为"垃圾邮件",低于 0.9 的则被归类为"非垃圾邮件"。
- 聚类 (Clustering)
将关联的样本分成一组,一般用于非监督式学习。在所有样本均分组完毕后,相关人员便可选择性地为每个聚类赋予含义。聚类算法有很多。例如,k-means算法会基于样本与形心的接近程度聚类样本,如下图所示:
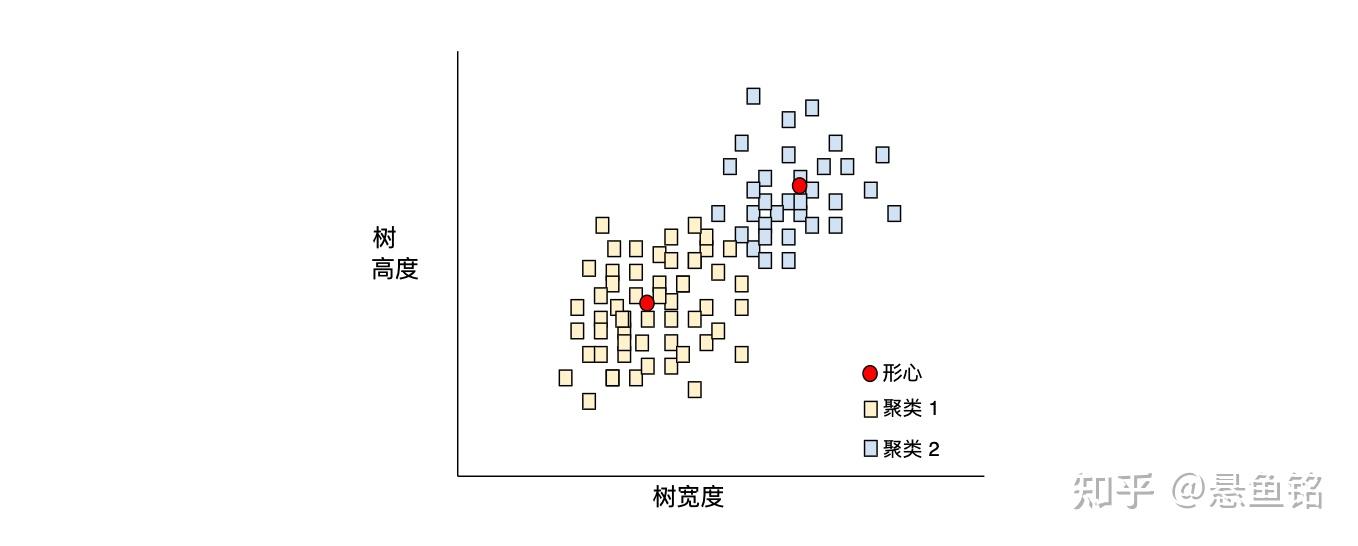
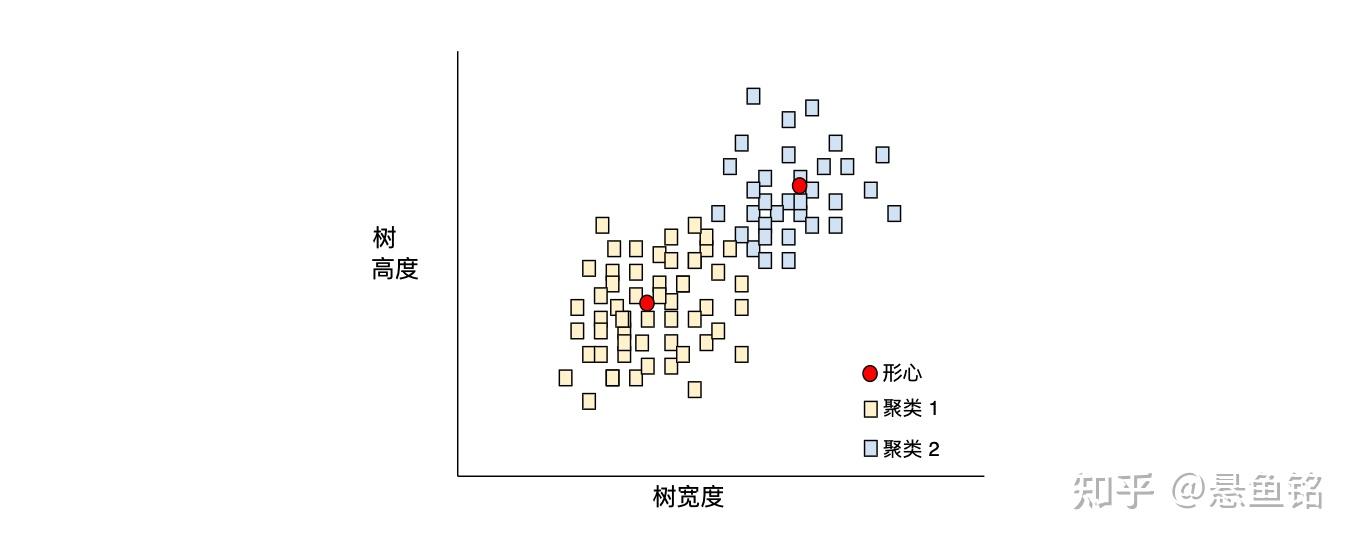
之后,研究人员便可查看这些聚类并进行其他操作,例如,将聚类 1 标记为"矮型树",将聚类 2 标记为"全尺寸树"。
再举一个例子,例如基于样本与中心点距离的聚类算法,如下所示:
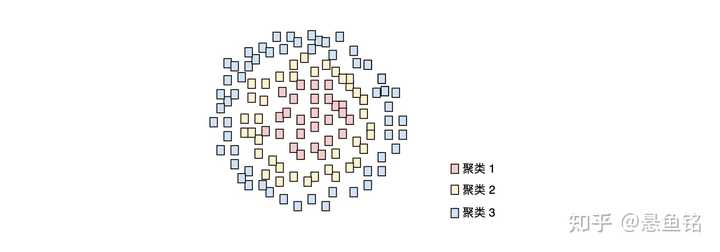

- 协同过滤 (Collaborative Filtering)
根据很多其他用户的兴趣来预测某位用户的兴趣。协同过滤通常用在推荐系统中。
- 混淆矩阵 (Confusion atrix)
一种 NxN 表格,用于总结分类模型的预测效果;即标签和模型预测的分类之间的关联。在混淆矩阵中,一个轴表示模型预测的标签,另一个轴表示实际标签。N 表示类别个数。在二元分类问题中,N=2。例如,下面显示了一个二元分类问题的混淆矩阵示例:
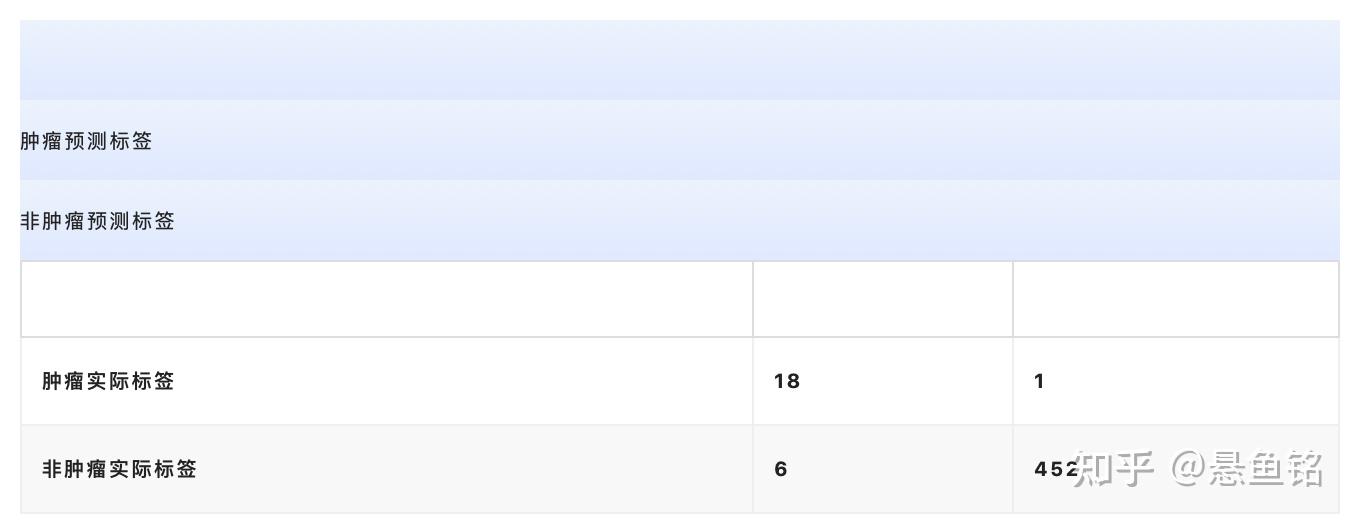

上面的混淆矩阵显示,在 19 个实际有肿瘤的样本中,该模型正确地将 18 个归类为有肿瘤(18 个正例),错误地将 1 个归类为没有肿瘤(1 个假负例)。同样,在 458 个实际没有肿瘤的样本中,模型归类正确的有 452 个(452 个负例),归类错误的有 6 个(6 个假正例)。
多类别分类问题的混淆矩阵有助于确定出错模式。例如,某个混淆矩阵可以揭示,某个经过训练以识别手写数字的模型往往会将 4 错误地预测为 9,将 7 错误地预测为 1。
混淆矩阵包含计算各种效果指标(包括精确率和召回率)所需的充足信息。
- 连续特征 (Continuous Feature)
一种浮点特征,可能值的区间不受限制,与离散特征相对。
- 收敛 (Convergence)
通俗来说,收敛通常是指在训练期间达到的一种状态,即经过一定次数的迭代之后,训练损失和验证损失在每次迭代中的变化都非常小或根本没有变化。也就是说,如果采用当前数据进行额外的训练将无法改进模型,模型即达到收敛状态。在深度学习中,损失值有时会在最终下降之前的多次迭代中保持不变或几乎保持不变,暂时形成收敛的假象。
另请参阅早停法。
另请参阅 Boyd 和 Vandenberghe 合著的 Convex Optimization(《凸优化》)。
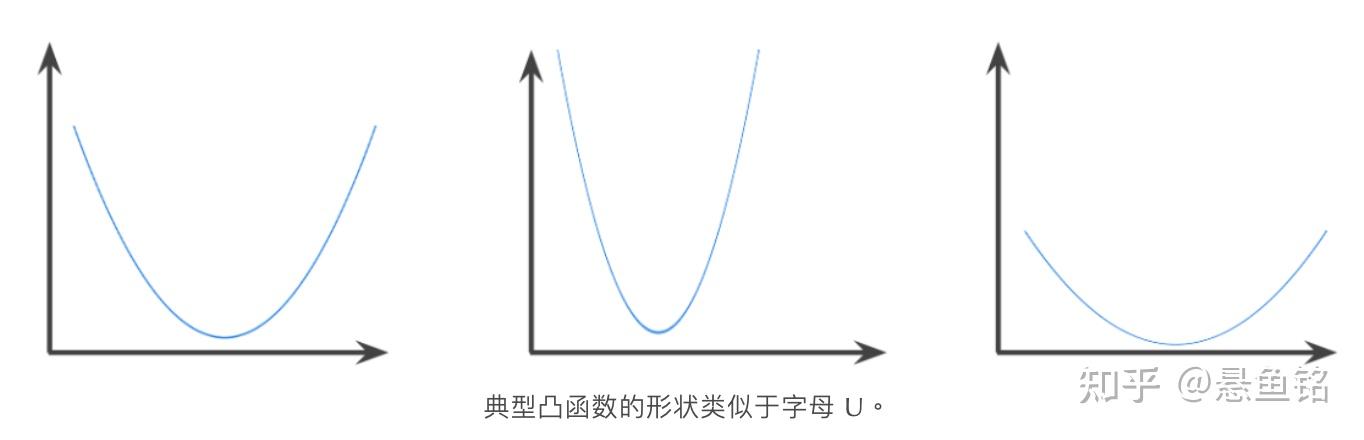
- 凸函数 (Convex Function)
一种函数,函数图像以上的区域为凸集。典型凸函数的形状类似于字母U。例如,以下都是凸函数:

相反,以下函数则不是凸函数。请注意图像上方的区域如何不是凸集:
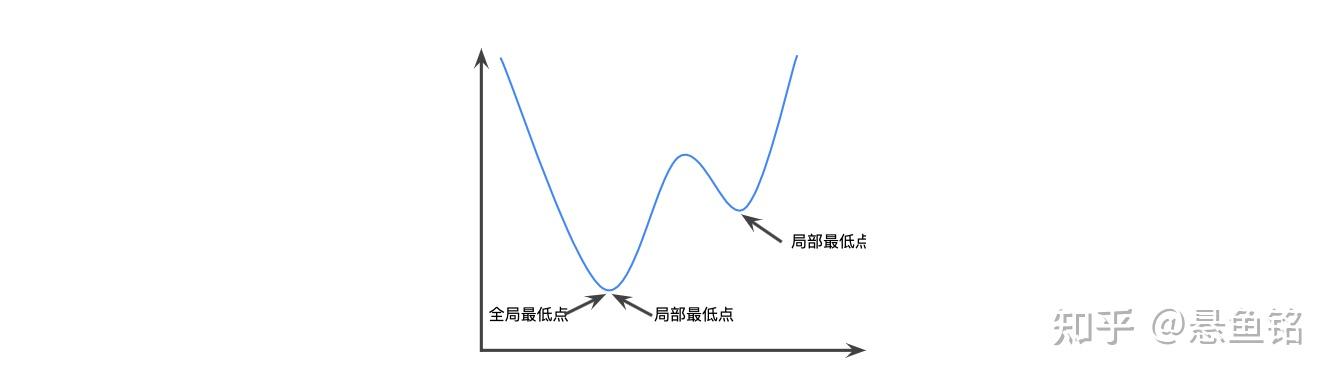

严格凸函数只有一个局部最低点,该点也是全局最低点。经典的 U 形函数都是严格凸函数。不过,有些凸函数(例如直线)则不是这样。
很多常见的损失函数(包括下列函数)都是凸函数:
- L_2 损失函数
- 对数损失函数
- L_1 正则化
- L_2 正则化
梯度下降法的很多变体都一定能找到一个接近严格凸函数最小值的点。同样,随机梯度下降法的很多变体都有很高的可能性能够找到接近严格凸函数最小值的点(但并非一定能找到)。
两个凸函数的和(例如 L_2 损失函数 + L_1 正则化)也是凸函数。
深度模型绝不会是凸函数。值得注意的是,专门针对凸优化设计的算法往往总能在深度网络上找到非常好的解决方案,虽然这些解决方案并不一定对应于全局最小值。
- 凸优化 (Convex Optimization)
使用数学方法(例如梯度下降法)寻找凸函数最小值的过程。机器学习方面的大量研究都是专注于如何通过公式将各种问题表示成凸优化问题,以及如何更高效地解决这些问题。
如需完整的详细信息,请参阅 Boyd 和 Vandenberghe 合著的 Convex Optimization(《凸优化》)。
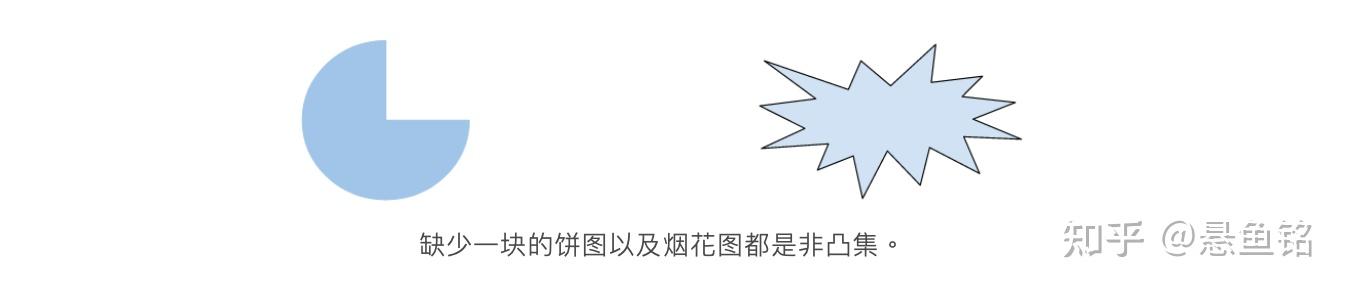
- 凸集 (Convex Set)
欧几里得空间的一个子集,其中任意两点之间的连线仍完全落在该子集内。例如,下面的两个图形都是凸集:


相反,下面的两个图形都不是凸集:

- 卷积 (Convolution)
简单来说,卷积在数学中指两个函数的组合。在机器学习中,卷积结合使用卷积过滤器和输入矩阵来训练权重。
机器学习中的"卷积"一词通常是卷积运算或卷积层的简称。
如果没有卷积,机器学习算法就需要学习大张量中每个单元格各自的权重。例如,用 2K x 2K 图像训练的机器学习算法将被迫找出 400 万个单独的权重。而使用卷积,机器学习算法只需在卷积过滤器中找出每个单元格的权重,大大减少了训练模型所需的内存。在应用卷积过滤器后,它只需跨单元格进行复制,每个单元格都会与过滤器相乘。
- 卷积过滤器 (Convolutional filter)
卷积运算中的两个参与方之一。(另一个参与方是输入矩阵切片)卷积过滤器是一种矩阵,其等级与输入矩阵相同,但形状小一些。以 28×28 的输入矩阵为例,过滤器可以是小于 28×28 的任何二维矩阵。
在图形操作中,卷积过滤器中的所有单元格通常按照固定模式设置为 1 和 0。在机器学习中,卷积过滤器通常先选择随机数字,然后由网络训练出理想值。
- 卷积层 (Convolutional layer)
深度神经网络的一个层,卷积过滤器会在其中传递输入矩阵。以下面的 3x3 卷积过滤器为例:
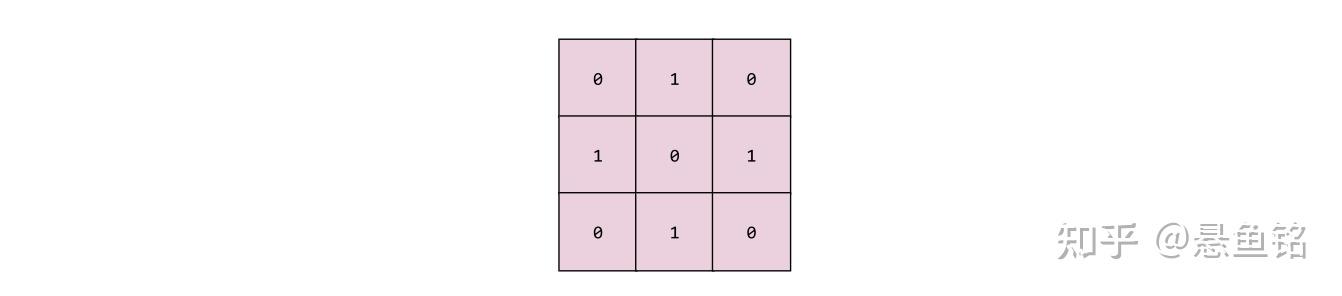

下面的动画显示了一个由 9 个卷积运算(涉及 5x5 输入矩阵)组成的卷积层。请注意,每个卷积运算都涉及一个不同的 3x3 输入矩阵切片。由此产生的 3×3 矩阵(右侧)就包含 9 个卷积运算的结果:

- 卷积神经网络 (Convolutional Neural Network)
一种神经网络,其中至少有一层为卷积层。典型的卷积神经网络包含以下几层的组合:
- 卷积层
- 池化层
- 密集层
卷积神经网络在解决某些类型的问题(如图像识别)上取得了巨大成功。
- 卷积运算 (Convolutional Operation)
如下所示的两步数学运算:
- 对卷积过滤器和输入矩阵切片执行元素级乘法。(输入矩阵切片与卷积过滤器具有相同的等级和大小。)
- 对生成的积矩阵中的所有值求和。
以下面的 5x5 输入矩阵为例:
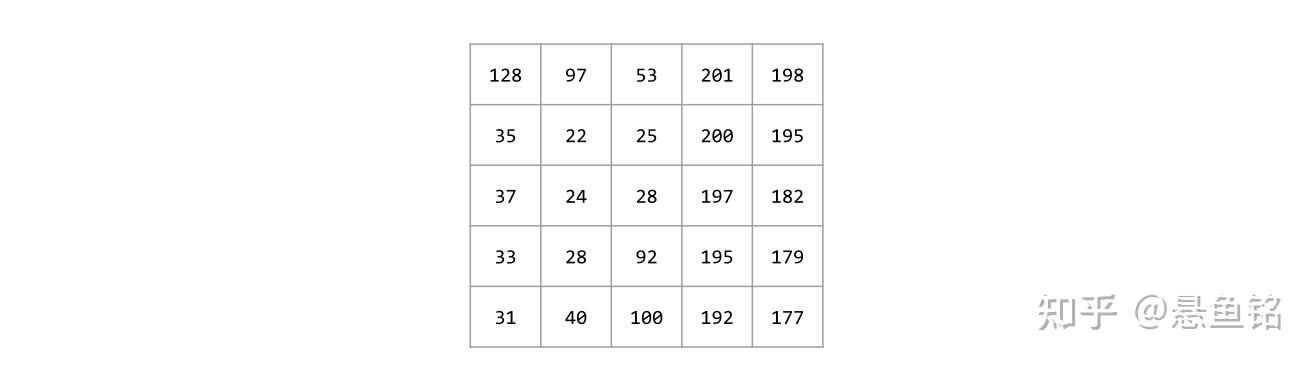

现在,以下面这个 2x2 卷积过滤器为例:


每个卷积运算都涉及一个 2x2 输入矩阵切片。例如,假设我们使用输入矩阵左上角的 2x2 切片。这样一来,对此切片进行卷积运算将如下所示:
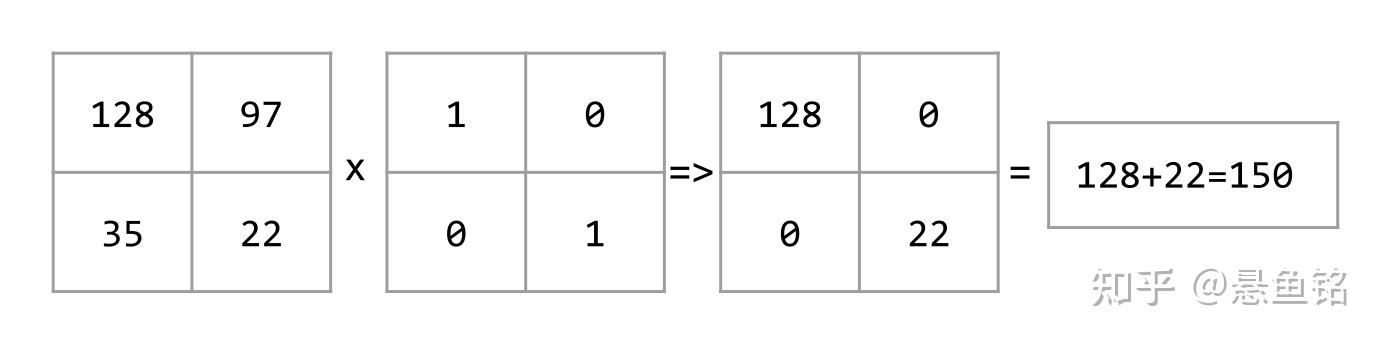

卷积层由一系列卷积运算组成,每个卷积运算都针对不同的输入矩阵切片。
- 成本 (Cost)
与损失的含义相同。
- 交叉熵 (Cross-entropy)
对数损失函数向多类别分类问题的一种泛化。交叉熵可以量化两种概率分布之间的差异。另请参阅困惑度。
D
- 数据分析 (Data Analysis)
根据样本、测量结果和可视化内容来理解数据。数据分析在首次收到数据集、构建第一个模型之前特别有用。此外,数据分析在理解实验和调试系统问题方面也至关重要。
- DataFrame
一种热门的数据类型,用于表示 Pandas 中的数据集。DataFrame 类似于表格。DataFrame 的每一列都有一个名称(标题),每一行都由一个数字标识。
- 数据集 (Data set)
一组样本的集合。
- Dataset API (tf.data)
一种高级别的 TensorFlow API,用于读取数据并将其转换为机器学习算法所需的格式。tf.data.Dataset对象表示一系列元素,其中每个元素都包含一个或多个张量。tf.data.Iterator对象可获取 Dataset 中的元素。如需详细了解 Dataset API,请参阅《TensorFlow 编程人员指南》中的导入数据[4]。
- 决策边界 (Decision Boundary)
在二元分类或多类别分类问题中,模型学到的类别之间的分界线。例如,在以下表示某个二元分类问题的图片中,决策边界是橙色类别和蓝色类别之间的分界线:

- 密集层 (Dense Layer)
与全连接层的含义相同。
- 深度模型 (Deep Model)
一种神经网络,其中包含多个隐藏层。深度模型依赖于可训练的非线性关系。与宽度模型相对。
- 密集特征 (Dense Feature)
一种大部分值是非零值的特征,通常是浮点值张量。与稀疏特征相对。
- 设备 (Device)
一类可运行 TensorFlow 会话的硬件,包括 CPU、GPU 和 TPU。
- 离散特征 (Discrete Feature)
一种特征,包含有限个可能值。例如,某个值只能是"动物"、"蔬菜"或"矿物"的特征便是一个离散特征(或分类特征)。与连续特征相对。
- 丢弃正则化 (Dropout Regularization)
正则化的一种形式,在训练神经网络方面非常有用。丢弃正则化的运作机制是,在一个梯度步长中移除从神经网络层中随机选择的固定数量的单元。丢弃的单元越多,正则化效果就越强。这类似于训练神经网络以模拟较小网络的指数级规模集成学习。如需完整的详细信息,请参阅 Dropout: A Simple Way to Prevent Neural Networks from Overfitting(《丢弃:一种防止神经网络过拟合的简单方法》)。
- 动态模型 (Dynamic Model)
一种模型,以持续更新的方式在线接受训练。也就是说,数据会源源不断地进入这种模型。
E
- 早停法 (Early Stopping)
一种正则化方法,是指在训练损失仍可以继续降低之前结束模型训练。使用早停法时,您会在验证数据集的损失开始增大(也就是泛化效果变差)时结束模型训练。
- 嵌套 (Embeddings)
一种分类特征,以连续值特征表示。通常,嵌套是指将高维度向量映射到低维度的空间。例如,您可以采用以下两种方式之一来表示英文句子中的单词:
- 表示成包含百万个元素(高维度)的稀疏向量,其中所有元素都是整数。向量中的每个单元格都表示一个单独的英文单词,单元格中的值表示相应单词在句子中出现的次数。由于单个英文句子包含的单词不太可能超过 50 个,因此向量中几乎每个单元格都包含 0。少数非 0 的单元格中将包含一个非常小的整数(通常为 1),该整数表示相应单词在句子中出现的次数。
- 表示成包含数百个元素(低维度)的密集向量,其中每个元素都存储一个介于 0 到 1 之间的浮点值。这就是一种嵌套。
在 TensorFlow 中,会按反向传播损失训练嵌套,和训练神经网络中的任何其他参数一样。
- 经验风险最小化 (ERM, empirical risk minimization)
用于选择可以将基于训练集的损失降至最低的函数。与结构风险最小化相对。
- 集成学习 (Ensemble)
多个模型的预测结果的并集。您可以通过以下一项或多项来创建集成学习:
- 不同的初始化
- 不同的超参数
- 不同的整体结构
深度模型和宽度模型[5]属于一种集成学习。
- 周期 (Epoch)
在训练时,整个数据集的一次完整遍历,以便不漏掉任何一个样本。因此,一个周期表示(N/批次大小)次训练迭代,其中N 是样本总数。
- 样本 (Example)
数据集的一行。一个样本包含一个或多个特征,此外还可能包含一个标签。另请参阅有标签样本和无标签样本。
F
- 假负例 (FN, false negative)
被模型错误地预测为负类别的样本。例如,模型推断出某封电子邮件不是垃圾邮件(负类别),但该电子邮件其实是垃圾邮件。
- 假正例 (FP, false positive)
被模型错误地预测为正类别的样本。例如,模型推断出某封电子邮件是垃圾邮件(正类别),但该电子邮件其实不是垃圾邮件。
- 假正例率(false positive rate, 简称 FP 率)
ROC 曲线中的 x 轴。FP 率的定义如下:


- 特征列 (tf.feature_column)
指定模型应该如何解读特定特征的一种函数。此类函数的输出结果是所有Estimators 构造函数的必需参数。
借助 tf.feature_column函数,模型可对输入特征的不同表示法轻松进行实验。有关详情,请参阅《TensorFlow 编程人员指南》中的特征列[7]一章。
"特征列"是 Google 专用的术语。特征列在 Yahoo/Microsoft 使用的VW[8]系统中称为"命名空间",也称为场[9]。
- 特征工程 (Feature Engineering)
指以下过程:确定哪些特征可能在训练模型方面非常有用,然后将日志文件及其他来源的原始数据转换为所需的特征。在 TensorFlow 中,特征工程通常是指将原始日志文件条目转换为tf.Example 协议缓冲区。另请参阅tf.Transform[10]。特征工程有时称为特征提取。
- 特征集 (Feature Set)
训练机器学习模型时采用的一组特征。例如,对于某个用于预测房价的模型,邮政编码、房屋面积以及房屋状况可以组成一个简单的特征集。
- 全连接层 (Fully Connected Layer)
一种隐藏层,其中的每个节点均与下一个隐藏层中的每个节点相连。全连接层又称为密集层。
G
- 泛化 (Generalization)
指的是模型依据训练时采用的数据,针对以前未见过的新数据做出正确预测的能力。
- 广义线性模型 (generalized linear model)
最小二乘回归模型(基于高斯噪声[11])向其他类型的模型(基于其他类型的噪声,例如泊松噪声[12]或分类噪声)进行的一种泛化。广义线性模型的示例包括:
- 逻辑回归
- 多类别回归
- 最小二乘回归
可以通过凸优化[13]找到广义线性模型的参数。广义线性模型具有以下特性:
- 最优的最小二乘回归模型的平均预测结果等于训练数据的平均标签。
- 最优的逻辑回归模型预测的平均概率等于训练数据的平均标签。
广义线性模型的功能受其特征的限制。与深度模型不同,广义线性模型无法"学习新特征"。
- 梯度 (Gradient)
偏导数相对于所有自变量的向量。在机器学习中,梯度是模型函数偏导数的向量。梯度指向最高速上升的方向。
- 梯度裁剪 (Gradient Clipping)
在应用梯度值之前先设置其上限。梯度裁剪有助于确保数值稳定性以及防止梯度爆炸[14]。
- 梯度下降法 (Gradient Descent)
一种通过计算并且减小梯度将损失降至最低的技术,它以训练数据为条件,来计算损失相对于模型参数的梯度。通俗来说,梯度下降法以迭代方式调整参数,逐渐找到权重和偏差的最佳组合,从而将损失降至最低。
- 图 (Graph)
TensorFlow 中的一种计算规范。图中的节点表示操作。边缘具有方向,表示将某项操作的结果(一个张量[15])作为一个操作数传递给另一项操作。可以使用TensorBoard 直观呈现图。
H
- 启发法 (heuristic)
一种非最优但实用的问题解决方案,足以用于进行改进或从中学习。
- 隐藏层 (hidden layer)
神经网络中的合成层,介于输入层(即特征)和输出层(即预测)之间。神经网络包含一个或多个隐藏层。
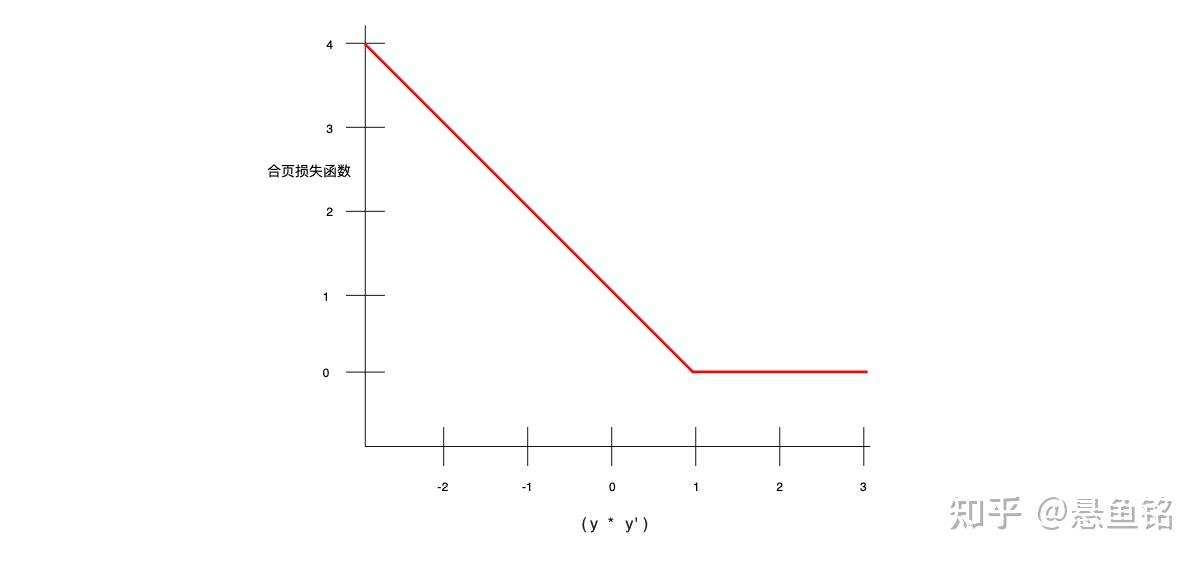
- 合页损失函数 (hinge loss)
一系列用于分类的损失函数,旨在找到距离每个训练样本都尽可能远的决策边界,从而使样本和边界之间的裕度最大化。KSVM使用合页损失函数(或相关函数,例如平方合页损失函数)。对于二元分类,合页损失函数的定义如下:
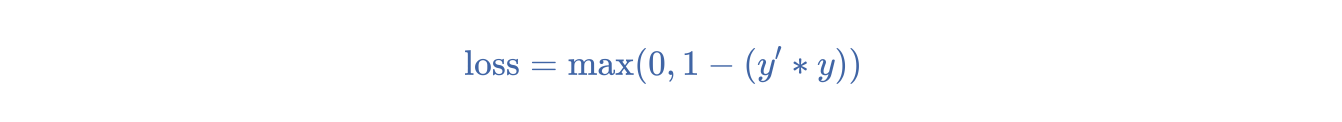

其中 y' 表示分类器模型的原始输出:
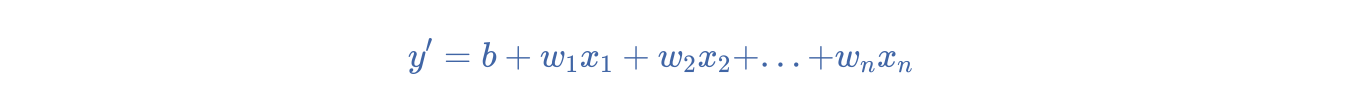

y 表示真标签,值为 -1 或 +1。
因此,合页损失与 ( y*y' ) 的关系图如下所示:

- 超参数 (hyperparameter)
在模型训练的连续过程中,您调节的"旋钮"。例如,学习速率就是一种超参数。与参数相对。
- 超平面 (hyperplane)
将一个空间划分为两个子空间的边界。例如,在二维空间中,直线就是一个超平面,在三维空间中,平面则是一个超平面。在机器学习中更典型的是:超平面是分隔高维度空间的边界。核支持向量机利用超平面将正类别和负类别区分开来(通常是在极高维度空间中)。
- 独立同等分布 (i.i.d, independently and identically distributed)
从不会改变的分布中提取的数据,其中提取的每个值都不依赖于之前提取的值。i.i.d. 是机器学习的理想气体[16] - 一种实用的数学结构,但在现实世界中几乎从未发现过。例如,某个网页的访问者在短时间内的分布可能为 i.i.d.,即分布在该短时间内没有变化,且一位用户的访问行为通常与另一位用户的访问行为无关。不过,如果将时间窗口扩大,网页访问者的分布可能呈现出季节性变化。
- 推断 (inference)
在机器学习中,推断通常指以下过程:通过将训练过的模型应用于无标签样本来做出预测。在统计学中,推断是指在某些观测数据条件下拟合分布参数的过程。(请参阅维基百科中有关统计学推断的文章[17]。)
- 输入函数 (input function)
在 TensorFlow 中,用于将输入数据返回到 Estimator的训练、评估或预测方法的函数。例如,训练输入函数会返回训练集中的一批特征和标签。
- 输入层 (input layer)
神经网络中的第一层(接收输入数据的层)。
- 实例 (instance)
与样本的含义相同。
- 可解释性 (interpretability)
模型的预测可解释的难易程度。深度模型通常不可解释,也就是说,很难对深度模型的不同层进行解释。相比之下,线性回归模型和宽度模型的可解释性通常要好得多。
- 迭代 (iteration)
模型的权重在训练期间的一次更新。迭代包含计算参数在单批次数据上的梯度损失。
K
- k-means
一种热门的聚类算法,用于对非监督式学习中的样本进行分组。k-means 算法基本上会执行以下操作:
- 以迭代方式确定最佳的 k 中心点(称为形心)。
- 将每个样本分配到最近的形心。与同一个形心距离最近的样本属于同一个组。
k-means 算法会挑选形心位置,以最大限度地减小每个样本与其最接近形心之间的距离的累积平方。以下面的小狗高度与小狗宽度的关系图为例:

如果 k=3,则 k-means 算法会确定三个形心。每个样本都被分配到与其最接近的形心,最终产生三个组:
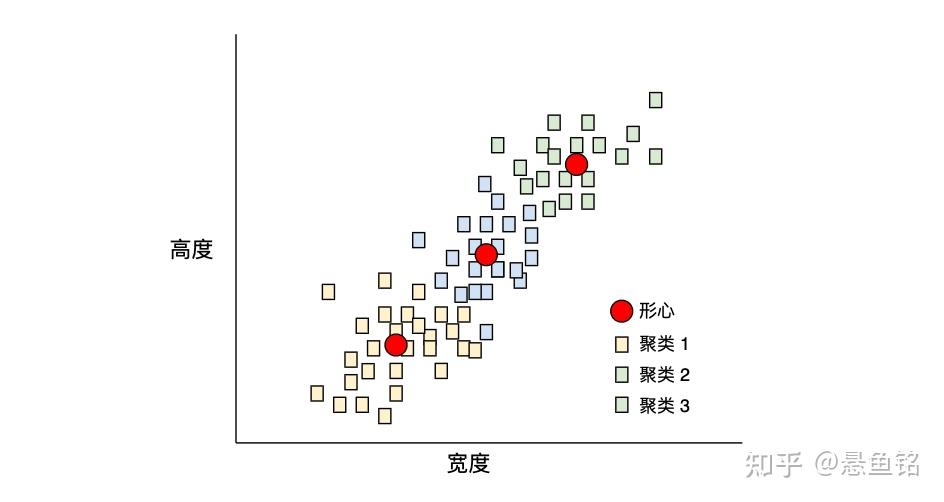

假设制造商想要确定小、中和大号狗毛衣的理想尺寸。在该聚类中,三个形心用于标识每只狗的平均高度和平均宽度。因此,制造商可能应该根据这三个形心确定毛衣尺寸。请注意,聚类的形心通常不是聚类中的样本。
上图显示了 k-means 应用于仅具有两个特征(高度和宽度)的样本。请注意,k-means 可以跨多个特征为样本分组。
- k-median
与 k-means 紧密相关的聚类算法。两者的实际区别如下:
- 对于 k-means,确定形心的方法是,最大限度地减小候选形心与它的每个样本之间的距离平方和。
- 对于 k-median,确定形心的方法是,最大限度地减小候选形心与它的每个样本之间的距离总和。
请注意,距离的定义也有所不同:
- k-means 采用从形心到样本的欧几里得距离[18]。(在二维空间中,欧几里得距离即使用勾股定理来计算斜边。)例如,(2,2) 与 (5,-2) 之间的 k-means 距离为:
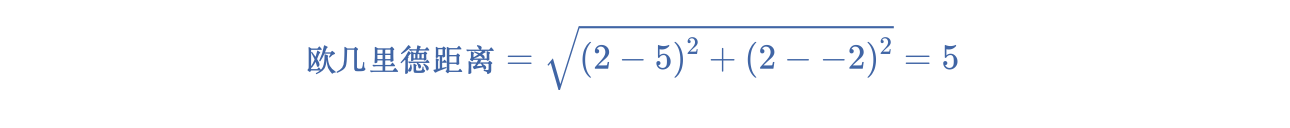

- k-median 采用从形心到样本的曼哈顿距离[19]。这个距离是每个维度中绝对差异值的总和。例如,(2,2) 与 (5,-2) 之间的 k-median 距离为:
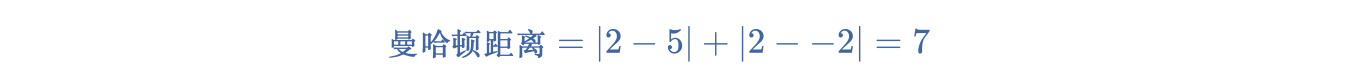

- Keras
一种热门的 Python 机器学习 API。Keras[20]能够在多种深度学习框架上运行,其中包括 TensorFlow(在该框架上,Keras 作为tf.keras[21]提供)。
L
- 损失 (Loss)
一种衡量指标,用于衡量模型的预测偏离其标签的程度。或者更悲观地说是衡量模型有多差。要确定此值,模型必须定义损失函数。例如,线性回归模型通常将均方误差用作损失函数,而逻辑回归模型则使用对数损失函数。
- L_1 损失函数 ( L_1 Loss)
一种损失函数,基于模型预测的值与标签的实际值之差的绝对值。与 L_2 损失函数相比, 损失函数对离群值的敏感性弱一些。
- L_1正则化 ( L_1Regularization)
一种正则化,根据权重的绝对值的总和来惩罚权重。在依赖稀疏特征的模型中, L_1正则化有助于使不相关或几乎不相关的特征的权重正好为 0,从而将这些特征从模型中移除。与 L_2正则化相对。
- L_2损失函数 (L_2 Loss)
请参阅平方损失函数。
- L_2正则化 ( L_2 Regularization)
一种正则化,根据权重的平方和来惩罚权重。 L_2 正则化有助于使离群值(具有较大正值或较小负值)权重接近于 0,但又不正好为 0。(与 L1 正则化相对。)在线性模型中, L_2正则化始终可以改进泛化。
- 标签 (Label)
在监督式学习中,标签指样本的"答案"或"结果"部分。有标签数据集中的每个样本都包含一个或多个特征以及一个标签。例如,在房屋数据集中,特征可能包括卧室数、卫生间数以及房龄,而标签则可能是房价。在垃圾邮件检测数据集中,特征可能包括主题行、发件人以及电子邮件本身,而标签则可能是"垃圾邮件"或"非垃圾邮件"。
- 有标签样本 (Labeled Example)
包含特征和标签的样本。在监督式训练中,模型从有标签样本中学习规律。
- 层 (Layer)
神经网络中的一组神经元,负责处理一组输入特征,或一组神经元的输出。此外还指 TensorFlow 中的抽象层。层是 Python 函数,以张量和配置选项作为输入,然后生成其他张量作为输出。当必要的张量组合起来后,用户便可以通过模型函数将结果转换为Estimator。
- Layers API (tf.layers)
一种 TensorFlow API,用于以层组合的方式构建深度神经网络。通过 Layers API,您可以构建不同类型的层,例如:
- 通过 tf.layers.Dense 构建全连接层。
- 通过 tf.layers.Conv2D 构建卷积层。
在编写自定义 Estimator时,您可以编写"层"对象来定义所有隐藏层的特征。Layers API 遵循 Keras layers API 规范。也就是说,除了前缀不同以外,Layers API 中的所有函数均与 Keras layers API 中的对应函数具有相同的名称。
- 学习速率 (Learning Rate)
在训练模型时用于梯度下降的一个标量。在每次迭代期间,梯度下降法都会将学习速率与梯度相乘。得出的乘积称为梯度步长。学习速率是一个重要的超参数。
- 最小二乘回归 (Least Squares Regression)
一种通过最小化 损失训练出的线性回归模型。
- 线性回归 (Linear Regression)
一种回归模型,通过将输入特征进行线性组合输出连续值。
- 逻辑回归 (Logistic Regression)
一种模型,通过将 S 型函数应用于线性预测,生成分类问题中每个可能的离散标签值的概率。虽然逻辑回归经常用于二元分类问题,但也可用于多类别分类问题(其叫法变为多类别逻辑回归或多项回归)。
M
- 机器学习 (Machine Learning)
一种程序或系统,用于根据输入数据构建(训练)预测模型。这种系统会利用学到的模型根据从分布(训练该模型时使用的同一分布)中提取的新数据(以前从未见过的数据)进行实用的预测。机器学习还指与这些程序或系统相关的研究领域。
- ML
机器学习的缩写。
- 模型 (Model)
机器学习系统从训练数据学到的内容的表示形式。多含义术语,可以理解为下列两种相关含义之一:
- 一种 TensorFlow 图,用于表示预测的计算结构。
- 该 TensorFlow 图的特定权重和偏差,通过训练决定。
- 模型训练 (model training)
确定最佳模型的过程。
- 均方误差 (MSE, Mean Squared Error)
每个样本的平均平方损失。MSE 的计算方法是平方损失除以样本数。TensorFlow Playground显示的"训练损失"值和"测试损失"值都是 MSE。
- 指标 (Metric)
您关心的一个数值。可能可以也可能不可以直接在机器学习系统中得到优化。您的系统尝试优化的指标称为目标。
- Metrics API (tf.metrics)
一种用于评估模型的 TensorFlow API。例如,tf.metrics.accuracy用于确定模型的预测与标签匹配的频率。在编写自定义 Estimator 时,您可以调用 Metrics API 函数来指定应如何评估您的模型。
- 小批次 (Mini-Batch)
从整批样本内随机选择并在训练或推断过程的一次迭代中一起运行的一小部分样本。小批次的批次大小通常介于 10 到 1000 之间。与基于完整的训练数据计算损失相比,基于小批次数据计算损失要高效得多。
- 小批次随机梯度下降法 (SGD, mini-batch stochastic gradient descent)
一种采用小批次样本的梯度下降法。也就是说,小批次 SGD 会根据一小部分训练数据来估算梯度。Vanilla SGD使用的小批次的大小为 1。
- 动量 (Momentum)
一种先进的梯度下降法,其中学习步长不仅取决于当前步长的导数,还取决于之前一步或多步的步长的导数。动量涉及计算梯度随时间而变化的指数级加权移动平均值,与物理学中的动量类似。动量有时可以防止学习过程被卡在局部最小的情况。
- 多类别分类 (Multi-Class Classification)
区分两种以上类别的分类问题。例如,枫树大约有 128 种,因此,确定枫树种类的模型就属于多类别模型。反之,仅将电子邮件分为两类("垃圾邮件"和"非垃圾邮件")的模型属于二元分类模型。
N
- 负类别 (Negative Class)
在二元分类中,一种类别称为正类别,另一种类别称为负类别。正类别是我们要寻找的类别,负类别则是另一种可能性。例如,在医学检查中,负类别可以是"非肿瘤"。在电子邮件分类器中,负类别可以是"非垃圾邮件"。另请参阅正类别。
- 神经网络 (Neural Network)
一种模型,灵感来源于脑部结构,由多个层构成(至少有一个是隐藏层),每个层都包含简单相连的单元或神经元(具有非线性关系)。
- 神经元 (Neuron)
神经网络中的节点,通常会接收多个输入值并生成一个输出值。神经元通过将激活函数(非线性转换)应用于输入值的加权和来计算输出值。
- 节点 (Node)
多含义术语,可以理解为下列两种含义之一:
- 隐藏层中的神经元。
- TensorFlow 图中的操作。
- 标准化 (normalization)
将实际的值区间转换为标准的值区间(通常为 -1 到 +1 或 0 到 1)的过程。例如,假设某个特征的自然区间是 800 到 6000。通过减法和除法运算,您可以将这些值标准化为位于 -1 到 +1 区间内。
另请参阅缩放。
- 数值数据 (Numerical Data)
用整数或实数表示的特征。例如,在房地产模型中,您可能会用数值数据表示房子大小(以平方英尺或平方米为单位)。如果用数值数据表示特征,则可以表明特征的值相互之间具有数学关系,并且与标签可能也有数学关系。例如,如果用数值数据表示房子大小,则可以表明面积为 200 平方米的房子是面积为 100 平方米的房子的两倍。此外,房子面积的平方米数可能与房价存在一定的数学关系。
并非所有整数数据都应表示成数值数据。例如,世界上某些地区的邮政编码是整数,但在模型中,不应将整数邮政编码表示成数值数据。这是因为邮政编码20000 在效力上并不是邮政编码 10000 的两倍(或一半)。此外,虽然不同的邮政编码确实与不同的房地产价值有关,但我们也不能假设邮政编码为 20000 的房地产在价值上是邮政编码为 10000 的房地产的两倍。邮政编码应表示成分类数据。
数值特征有时称为连续特征。
- Numpy
一个开放源代码数学库[24],在 Python 中提供高效的数组操作。Pandas 建立在 Numpy 之上。
O
- 目标 (objective)
算法尝试优化的指标。
- 独热编码 (one-hot encoding)
一种稀疏向量,其中:
- 一个元素设为 1。
- 所有其他元素均设为 0。
独热编码常用于表示拥有有限个可能值的字符串或标识符。例如,假设某个指定的植物学数据集记录了 15000 个不同的物种,其中每个物种都用独一无二的字符串标识符来表示。在特征工程过程中,您可能需要将这些字符串标识符编码为独热向量,向量的大小为 15000。
- 单样本学习(one-shot learning,通常用于对象分类)
一种机器学习方法,通常用于对象分类,旨在通过单个训练样本学习有效的分类器。另请参阅少量样本学习。
- 一对多 (one-vs.-all)
假设某个分类问题有 N 种可能的解决方案,一对多解决方案将包含 N 个单独的二元分类器 - 一个二元分类器对应一种可能的结果。例如,假设某个模型用于区分样本属于动物、蔬菜还是矿物,一对多解决方案将提供下列三个单独的二元分类器:
- 动物和非动物
- 蔬菜和非蔬菜
- 矿物和非矿物
- 操作 (op, Operation)
TensorFlow 图中的节点。在 TensorFlow 中,任何创建、操纵或销毁张量的过程都属于操作。例如,矩阵相乘就是一种操作,该操作以两个张量作为输入,并生成一个张量作为输出。
- 优化器 (optimizer)
梯度下降法的一种具体实现。TensorFlow 的优化器基类是tf.train.Optimizer[25]。不同的优化器可能会利用以下一个或多个概念来增强梯度下降法在指定训练集中的效果:
- 动量[26](Momentum)
- 更新频率(AdaGrad[27]= ADAptive GRADient descent;Adam[28]= ADAptive with Momentum;RMSProp)
- 稀疏性/正则化 (Ftrl[29])
- 更复杂的数学方法(Proximal[30],等等)
甚至还包括 NN 驱动的优化器[31]。
- 离群值 (outlier)
与大多数其他值差别很大的值。在机器学习中,下列所有值都是离群值。
- 绝对值很高的权重。
- 与实际值相差很大的预测值。
- 值比平均值高大约 3 个标准偏差的输入数据。
离群值常常会导致模型训练出现问题。
- 过拟合 (overfitting)
创建的模型与训练数据过于匹配,以致于模型无法根据新数据做出正确的预测。
P
- Pandas
面向列的数据分析 API。很多机器学习框架(包括 TensorFlow)都支持将 Pandas 数据结构作为输入。请参阅 Pandas 文档[32]。
- 参数 (parameter)
机器学习系统自行训练的模型的变量。例如,权重就是一种参数,它们的值是机器学习系统通过连续的训练迭代逐渐学习到的。与超参数相对。
- 参数更新 (parameter update)
在训练期间(通常是在梯度下降法的单次迭代中)调整模型参数的操作。
- 偏导数 (partial derivative)
一种导数,除一个变量之外的所有变量都被视为常量。例如, 对 的偏导数就是 的导数(即,使 保持恒定)。 对 的偏导数仅关注 如何变化,而忽略公式中的所有其他变量。
- 性能 (performance)
多含义术语,具有以下含义:
- 在软件工程中的传统含义。即:相应软件的运行速度有多快(或有多高效)?
- 在机器学习中的含义。在机器学习领域,性能旨在回答以下问题:相应模型的准确度有多高?即模型在预测方面的表现有多好?
- 困惑度 (perplexity)
一种衡量指标,用于衡量模型能够多好地完成任务。例如,假设任务是读取用户使用智能手机键盘输入字词时输入的前几个字母,然后列出一组可能的完整字词。此任务的困惑度 (P) 是:为了使列出的字词中包含用户尝试输入的实际字词,您需要提供的猜测项的个数。困惑度与交叉熵的关系如下:
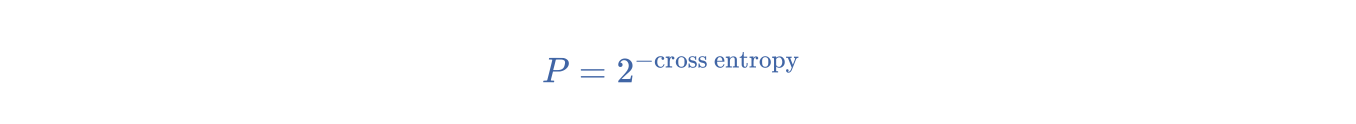

- 流水线 (pipeline)
机器学习算法的基础架构。流水线包括收集数据、将数据放入训练数据文件、训练一个或多个模型,以及将模型导出到生产环境。
- 池化 (pooling)
将一个或多个由前趋的卷积层创建的矩阵压缩为较小的矩阵。池化通常是取整个池化区域的最大值或平均值。以下面的 3x3 矩阵为例:


池化运算与卷积运算类似:将矩阵分割为多个切片,然后按步长逐个运行卷积运算。例如,假设池化运算按 1x1 步长将卷积矩阵分割为 2x2 个切片。如下图所示,进行了四个池化运算。假设每个池化运算都选择该切片中四个值的最大值:
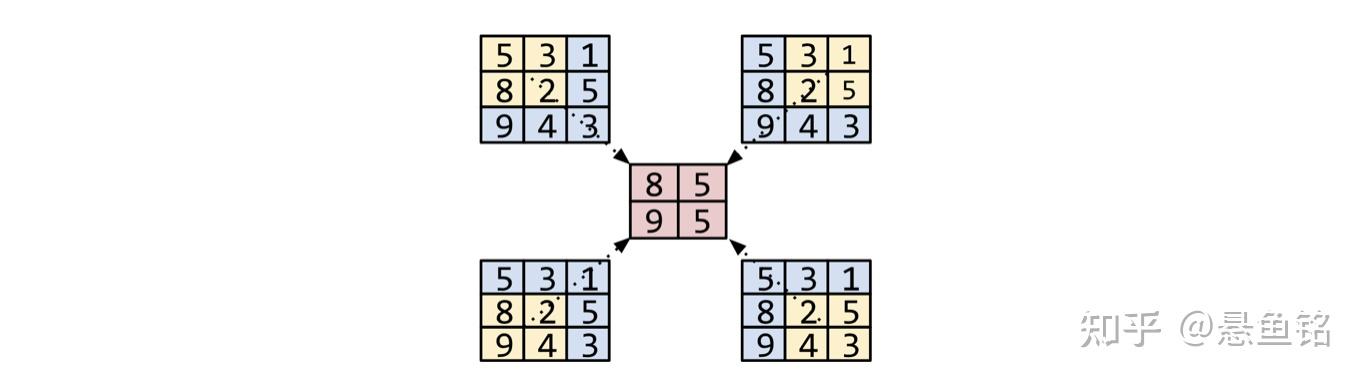

池化有助于在输入矩阵中实现平移不变性。对于视觉应用来说,池化的更正式名称为空间池化。时间序列应用通常将池化称为时序池化。按照不太正式的说法,池化通常称为下采样或降采样。
- 正类别 (positive class)
在二元分类中,两种可能的类别分别被标记为正类别和负类别。正类别结果是我们要测试的对象。(不可否认的是,我们会同时测试这两种结果,但只关注正类别结果。)例如,在医学检查中,正类别可以是"肿瘤"。在电子邮件分类器中,正类别可以是"垃圾邮件"。与负类别相对。
- 精确率 (precision)


- 预测偏差 (prediction bias)
一种值,用于表明预测平均值与数据集中标签的平均值相差有多大。
- 预训练模型 (pre-trained model)
已经过训练的模型或模型组件(例如嵌套)。有时,您需要将预训练的嵌套馈送到神经网络。在其他时候,您的模型将自行训练嵌套,而不依赖于预训练的嵌套。
R
- 召回率 (recall)
一种分类模型指标,用于回答以下问题:在所有可能的正类别标签中,模型正确地识别出了多少个?即:


- 修正线性单元 (ReLU, Rectified Linear Unit)
一种激活函数,其规则如下:
- 如果输入为负数或 0,则输出 0。
- 如果输入为正数,则输出等于输入。
- 回归模型 (regression model)
一种模型,能够输出连续的值(通常为浮点值)。请与分类模型进行比较,分类模型会输出离散值,例如"黄花菜"或"虎皮百合"。
- 正则化 (regularization)
对模型复杂度的惩罚。正则化有助于防止出现过拟合,包含以下类型:
- L_1 正则化
- L_2 正则化
- 丢弃正则化
- 早停法(这不是正式的正则化方法,但可以有效限制过拟合)
- 均方根误差 (RMSE, Root Mean Squared Error)
均方误差的平方根。
- 旋转不变性 (rotational invariance)
在图像分类问题中,即使图像的方向发生变化,算法也能成功地对图像进行分类。例如,无论网球拍朝上、侧向还是朝下放置,该算法仍然可以识别它。请注意,并非总是希望旋转不变;例如,倒置的"9"不应分类为"9"。
另请参阅平移不变性和大小不变性。
S
- SavedModel
保存和恢复 TensorFlow 模型时建议使用的格式。SavedModel 是一种独立于语言且可恢复的序列化格式,使较高级别的系统和工具可以创建、使用和转换 TensorFlow 模型。
如需完整的详细信息,请参阅《TensorFlow 编程人员指南》中的保存和恢复[34]。
- 缩放 (scaling)
特征工程中的一种常用做法,是指对某个特征的值区间进行调整,使之与数据集中其他特征的值区间一致。例如,假设您希望数据集中所有浮点特征的值都位于 0 到 1 区间内,如果某个特征的值位于 0 到 500 区间内,您就可以通过将每个值除以 500 来缩放该特征。另请参阅标准化。
- scikit-learn
一个热门的开放源代码机器学习平台。请访问http://www.scikit-learn.org[35]。
- 半监督式学习 (semi-supervised learning)
训练模型时采用的数据中,某些训练样本有标签,而其他样本则没有标签。半监督式学习采用的一种技术是推断无标签样本的标签,然后使用推断出的标签进行训练,以创建新模型。如果获得有标签样本需要高昂的成本,而无标签样本则有很多,那么半监督式学习将非常有用。
- 序列模型 (sequence model)
一种模型,其输入具有序列依赖性。例如,根据之前观看过的一系列视频对观看的下一个视频进行预测。
- S 型函数 (sigmoid function)
一种函数,可将逻辑回归输出或多项回归输出(对数几率)映射到概率,以返回介于 0 到 1 之间的值。S 型函数的公式如下:
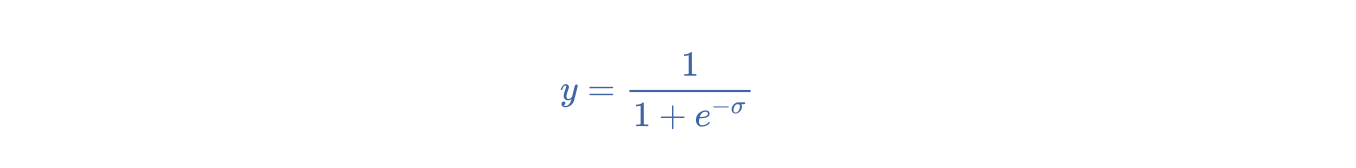

在逻辑回归问题中, \sigma 非常简单:
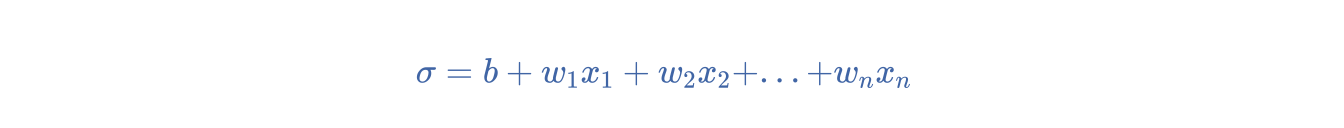

换句话说,S 型函数可将 \sigma转换为介于 0 到 1 之间的概率。在某些神经网络中,S 型函数可作为激活函数使用。
- 大小不变性 (size invariance)
在图像分类问题中,即使图像的大小发生变化,算法也能成功地对图像进行分类。例如,无论一只猫以 200 万像素还是 20 万像素呈现,该算法仍然可以识别它。请注意,即使是最好的图像分类算法,在大小不变性方面仍然会存在切实的限制。例如,对于仅以 20 像素呈现的猫图像,算法(或人)不可能正确对其进行分类。
另请参阅平移不变性和旋转不变性。
- softmax
一种函数,可提供多类别分类模型中每个可能类别的概率。这些概率的总和正好为 1.0。例如,softmax 可能会得出某个图像是狗、猫和马的概率分别是 0.9、0.08 和 0.02。(也称为完整 softmax。)与候选采样相对。
- 稀疏特征 (sparse feature)
一种特征向量,其中的大多数值都为 0 或为空。例如,某个向量包含一个为 1 的值和一百万个为 0 的值,则该向量就属于稀疏向量。再举一个例子,搜索查询中的单词也可能属于稀疏特征
- 在某种指定语言中有很多可能的单词,但在某个指定的查询中仅包含其中几个。
与密集特征相对。
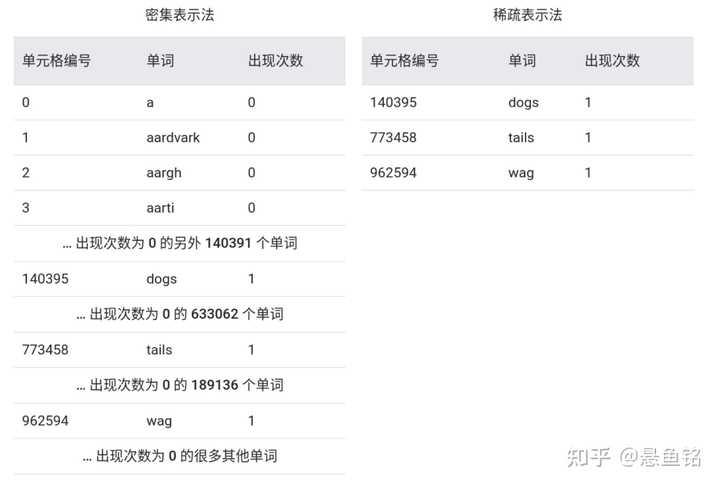
- 稀疏表示法 (sparse representation)
一种张量表示法,仅存储非零元素。例如,英语中包含约一百万个单词。表示一个英语句子中所用单词的数量,考虑以下两种方式:
- 要采用密集表示法来表示此句子,则必须为所有一百万个单元格设置一个整数,然后在大部分单元格中放入 0,在少数单元格中放入一个非常小的整数。
- 要采用稀疏表示法来表示此句子,则仅存储象征句子中实际存在的单词的单元格。因此,如果句子只包含 20 个独一无二的单词,那么该句子的稀疏表示法将仅在 20 个单元格中存储一个整数。
例如,假设以两种方式来表示句子"Dogs wag tails."。如下表所示,密集表示法将使用约一百万个单元格;稀疏表示法则只使用 3 个单元格:

- 平方损失函数 (squared loss)
在线性回归中使用的损失函数(也称为 L_2 损失函数)。该函数可计算模型为有标签样本预测的值和标签的实际值之差的平方。由于取平方值,因此该损失函数会放大不佳预测的影响。也就是说,与 L_1 损失函数相比,平方损失函数对离群值的反应更强烈。
- 步长 (step size)
与学习速率的含义相同。
- 随机梯度下降法 (SGD, stochastic gradient descent)
批次大小为 1 的一种梯度下降法。换句话说,SGD 依赖于从数据集中随机均匀选择的单个样本来计算每步的梯度估算值。
- 步长 (stride)
在卷积运算或池化中,下一个系列的输入切片的每个维度中的增量。例如,下面的动画演示了卷积运算过程中的一个 (1,1) 步长。因此,下一个输入切片是从上一个输入切片向右移动一个步长的位置开始。当运算到达右侧边缘时,下一个切片将回到最左边,但是下移一个位置。

前面的示例演示了一个二维步长。如果输入矩阵为三维,那么步长也将是三维。
- 监督式机器学习 (supervised machine learning)
根据输入数据及其对应的标签来训练模型。监督式机器学习类似于学生通过研究一系列问题及其对应的答案来学习某个主题。在掌握了问题和答案之间的对应关系后,学生便可以回答关于同一主题的新问题(以前从未见过的问题)。请与非监督式机器学习进行比较。
T
- 张量 (Tensor)
TensorFlow 程序中的主要数据结构。张量是 N 维(其中 N 可能非常大)数据结构,最常见的是标量、向量或矩阵。张量的元素可以包含整数值、浮点值或字符串值。
- 张量处理单元 (TPU, Tensor Processing Unit)
一种 ASIC(应用专用集成电路),用于优化 TensorFlow 程序的性能。
- 测试集 (test set)
数据集的子集,用于在模型经由验证集的初步验证之后测试模型。与训练集和验证集相对。
- 训练集 (training set)
数据集的子集,用于训练模型。与验证集和测试集相对。
- 迁移学习 (transfer learning)
将信息从一个机器学习任务迁移到另一个机器学习任务。例如,在多任务学习中,一个模型可以完成多项任务,例如针对不同任务具有不同输出节点的深度模型。迁移学习可能涉及将知识从较简单任务的解决方案迁移到较复杂的任务,或者将知识从数据较多的任务迁移到数据较少的任务。大多数机器学习系统都只能完成一项任务。迁移学习是迈向人工智能的一小步;在人工智能中,单个程序可以完成多项任务。
- 平移不变性 (translational invariance)
在图像分类问题中,即使图像中对象的位置发生变化,算法也能成功对图像进行分类。例如,无论一只狗位于画面正中央还是画面左侧,该算法仍然可以识别它。另请参阅大小不变性和旋转不变性。
- 负例 (TN, true negative)
被模型正确地预测为负类别的样本。例如,模型推断出某封电子邮件不是垃圾邮件,而该电子邮件确实不是垃圾邮件。
- 正例 (TP, true positive)
被模型正确地预测为正类别的样本。例如,模型推断出某封电子邮件是垃圾邮件,而该电子邮件确实是垃圾邮件。
- 时间序列分析 (time series analysis)
机器学习和统计学的一个子领域,旨在分析时态数据。很多类型的机器学习问题都需要时间序列分析,其中包括分类、聚类、预测和异常检测。例如,您可以利用时间序列分析根据历史销量数据预测未来每月的冬外套销量。
U
- 无标签样本 (unlabeled example)
包含特征但没有标签的样本。无标签样本是用于进行推断的输入内容。在半监督式和非监督式学习中,在训练期间会使用无标签样本。
- 非监督式机器学习 (unsupervised machine learning)
训练模型,以找出数据集(通常是无标签数据集)中的规律。非监督式机器学习最常见的用途是将数据分为不同的聚类,使相似的样本位于同一组中。例如,非监督式机器学习算法可以根据音乐的各种属性将歌曲分为不同的聚类。所得聚类可以作为其他机器学习算法(例如音乐推荐服务)的输入。在很难获取真标签的领域,聚类可能会非常有用。例如,在反滥用和反欺诈等领域,聚类有助于人们更好地了解相关数据。非监督式机器学习的另一个例子是主成分分析 (PCA)。例如,通过对包含数百万购物车中物品的数据集进行主成分分析,可能会发现有柠檬的购物车中往往也有抗酸药。请与监督式机器学习进行比较。
V
- 验证集 (validation set)
数据集的一个子集,从训练集分离而来,用于调整超参数。与训练集和测试集相对。
W
- 权重 (weight)
线性模型中特征的系数,或深度网络中的边。训练线性模型的目标是确定每个特征的理想权重。如果权重为 0,则相应的特征对模型来说没有任何贡献。
参考资料
[1]学习速率: http://www.jmlr.org/papers/volume12/duchi11a/duchi11a.pdf
[2]偏导数: https://en.wikipedia.org/wiki/Partial_derivative
[3]自定义 estimator 说明: https://www.tensorflow.org/extend/estimators?hl=zh-CN
[4]导入数据: https://www.tensorflow.org/programmers_guide/datasets?hl=zh-CN
[5]深度模型和宽度模型: https://www.tensorflow.org/tutorials/wide_and_deep?hl=zh-CN
[6]自定义 estimator 说明: https://www.tensorflow.org/extend/estimators?hl=zh-CN
[7]特征列: https://www.tensorflow.org/get_started/feature_columns?hl=zh-CN
[8]VW: https://en.wikipedia.org/wiki/Vowpal_Wabbit
[9]场: https://www.csie.ntu.edu.tw/~cjlin/libffm/
[10]tf.Transform: https://github.com/tensorflow/transform
[11]高斯噪声: https://en.wikipedia.org/wiki/Gaussian_noise
[12]泊松噪声: https://en.wikipedia.org/wiki/Shot_noise
[13]凸优化: https://en.wikipedia.org/wiki/Convex_optimization
[15]张量: https://www.tensorflow.org/api_docs/python/tf/Tensor?hl=zh-CN
[16]理想气体: https://en.wikipedia.org/wiki/Ideal_gas
[17]统计学推断: https://en.wikipedia.org/wiki/Statistical_inference
[18]欧几里得距离: https://en.wikipedia.org/wiki/Euclidean_distance
[19]曼哈顿距离: https://en.wikipedia.org/wiki/Taxicab_geometry
[20]Keras: https://keras.io
[21]tf.keras: https://www.tensorflow.org/api_docs/python/tf/keras?hl=zh-CN
[22]sigmoid cross entropy: https://www.tensorflow.org/api_docs/python/tf/nn/sigmoid_cross_entropy_with_logits?hl=zh-CN
[23]NaN: https://en.wikipedia.org/wiki/NaN
[24]开放源代码数学库: http://www.numpy.org/
[25]tf.train.Optimizer: https://www.tensorflow.org/api_docs/python/tf/train/Optimizer?hl=zh-CN
[26]动量: https://www.tensorflow.org/api_docs/python/tf/train/MomentumOptimizer?hl=zh-CN
[27]AdaGrad: https://www.tensorflow.org/api_docs/python/tf/train/AdagradOptimizer?hl=zh-CN
[28]Adam: https://www.tensorflow.org/api_docs/python/tf/train/AdamOptimizer?hl=zh-CN
[29]Ftrl: https://www.tensorflow.org/api_docs/python/tf/train/FtrlOptimizer?hl=zh-CN
[30]Proximal: https://www.tensorflow.org/api_docs/python/tf/train/ProximalGradientDescentOptimizer?hl=zh-CN
[31]NN 驱动的优化器: https://arxiv.org/abs/1606.04474
[32]Pandas 文档: http://pandas.pydata.org/
[33]自定义Estimator说明: https://www.tensorflow.org/extend/estimators?hl=zh-CN
[34]保存和恢复: https://www.tensorflow.org/programmers_guide/saved_model?hl=zh-CN
[35]www.scikit-learn.org: http://www.scikit-learn.org/
[36]http://playground.tensorflow.org: http://playground.tensorflow.org?hl=zh-CN
[37]协议缓冲区: https://developers.google.com/protocol-buffers/?hl=zh-CN
[38]原文链接: https://developers.google.com/machine-learning/glossary/?hl=zh-CN