回归(regression)问题是否比分类(classification)问题更难用神经网络模型学好?
15 个回答

這個我應該在行,我來分享吧ʅ(‾◡◝)ʃ
因為我這陣子就用神經網路在幹這個呀 (╯°Д°)╯┻━┻
為了方便,我會叫神經網路作NN
這個取決於兩個因素
0.你有幾少個"好"的data point
1.做什麼樣的回歸
緊記緊記,0是非常非常重要的,沒有0我們談不下去(╯°Д°)╯┻━┻
而且比起傳統的回歸(Lagrangian interpolation?) ,NN要很多很多的labelsssssssssssssssssssssssssss
沒有labelsssssss,NN是幹不下去的
那麼NN可以做什麼樣的回歸呢?舉個很適合NN的栗子
假設有一個大型房地產商,想估算香港一座屋子的價格( 香港交易大多數不是屋子吧,只買得起單位(╯°Д°)╯┻━┻ ),這就是一個典型的回歸問題
那可以估計價格的,就有幾個以下幾個參數
1.地段 (中環? 旺角?)
2. 房屋大小 (50 m^2? 100 m^2?)
3. 廁所數目 (0? 1?)
4.等等.....
首先,那個地產商的資料庫一定要非常大,保守估計沒有幾千個是不行的,其次就是labels分佈一定要夠全夠廣夠平均,不能有幾千個中環data 但只有幾十個旺角 data的情況
#####################################################################
而NN做回歸的數學描述非常簡單,就是:
價格=F(參數)
F 就是你的NN function了,我們終於說到點子上了,可以起行了
那麼回歸的NN要怎麼設置呢?
z) 跟普通deep learning一樣,都分training 及testing,這個大有學問,十分針對你想做回歸的類型而不同,普遍使用random抽取的型式居多
a) feature pre proccessing
為了加快訓練,所有參數(feature) 最好作pre processioning ,平常就是Standardization就夠了,保證你的feature range 是 [0,1] 或者 [-1, 1] 就可以,這樣做的原因可以參考一下deeplearning.ai 對此做法的簡介(簡單來說就是在gradient descant 前拉闊過窄的參數維度,那麼下降就會加快)
b) 架構
非常簡單,就是平常CNN 最後幾層的FC 拿出來就是了
input layer 數目是你參數的數目,output layer 是你要求回歸的維度數目
c) neurons 數目
跟傳統Deep learning 一樣,越多越好,最好兩層以上,就是訓練會慢一點
d) cost function
一定是M.S.E ,效果非凡,個人練丹經驗,不除平均訓練會快一點
其他: Mean Absolute Error,這個太易進入到不好的local minimum中,應免則免
e) activation function
用過很多種
i) tanh, sigmoid :都是差不多,可以直接拿來用
ii) relu : 這個會令回歸出來的東西不太smooth,典型例子看看下面莫煩大神的教程圖片

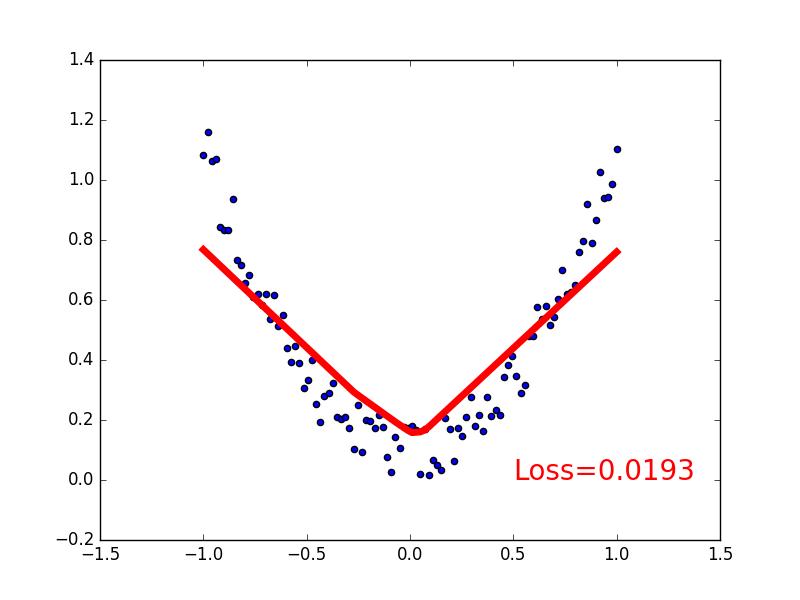
relu 的問題就是圖片中部,回歸的function "起角"不夠smooth,而且非常容易在訓練當中死亡,所以就不要用了
iii) softplus : 這個不容易過飽和,效果也不錯。
以上各function 的output layer 都要設置成linear layer (y= mx+C那個),那才能令你的NN function output range 達至 (-infinite,infinite)
f ) overfitting
i)dropout: 不單在CNN 在regression 對overfitting 也是神器,代價是準確度只能下降到某個數字(如1%)就停了
ii) L1 L2 : 可以用,但會令function的non linear特性有所減低 ,最極端就像下圖中underfit那樣失去曲的特性


#########################################################################
準確度及難度
個人經驗,NN fit 出來的function特性跟Lagrangian interpolation有點像,下圖就是Lagrangian interpolation的例子


- data point 與data point 中間會出現上突/下突的情況 (圖片左右兩邊) ,這個就是為何data point 要多的原因,因為data point 越多越密,突起的情況就會被減輕,同時用dropout也是為了減輕突起的問題
- 不要幻想extrapolation,你覺得問香港地產經紀北京的樓價靠譜嗎?┬─┬ ノ( ' - 'ノ),後果就是左右兩邊的橙線( ͡° ͜ʖ ͡°)
除了這一些,準確度還是不錯的,我個人做的NN regression 誤差普遍在0.5%~2%之間,準確度與data point 密度有關,而同一項目我用gradient boosting (XGB) 做了幾天都做不了這麼準。但說到底都是deep learning,比起其他回歸的method只用幾~幾十分鍾,在NN底下你沒GPU 跟十多個小時的training time 是吃不消的
#########################################################################
懶人總結:
用NN做regression的前題:
data 分佈夠多夠廣
用NN 做regression的好處:
在data point 密的地方比其他method奇準
用NN 做regression的問題:
台上一分鐘,練丹十年功,多買幾張顯示卡為佳
--------------------------------------------------完----------------------------------------------------

个人经验,确实很难。
- 样本不均衡问题。在分类问题中,样本不均衡指的是,其中一个或多个类的样本数量远远少于其他类,导致模型无法很好的学习这些类的信息,进而使模型更倾向于预测样本多的类。这类问题的研究很多,比如CV里一个常用的方法是augmentation,旋转平移啥的多来几次,就均衡了。但回归问题可了不得,不仅仅是不均衡,而是出现“断片”的现象。比如,一个问题的值域是[0,10],精度是0.01,但在区间[1.3, 2.7]中是没有样本的。硬要插值是行不通的,完全是在往里加脏数据。
- 回归问题相当于超多个类别的分类问题。承接第1条中的例子,如果我对模型的期望是每个样本的absolute error都低于0.1的,这意味着每个值为中心左右0.1范围内的区间相当于一个“类别”。假设值域更大,要求精度更高,那么“类别”则是成百上千万的。要知道,CIFAR100的准确率还没到顶呢。
- 值域可能是正负无穷的。有些问题,值域是无上限或者无下限的,而样本所对应的区间仅仅是很小一部分。那当新样本的真实label不在训练样本对应的值域中时,模型给出的预测值会严重偏离实际。而分类问题,至少还有个top-n用来挽回面子。
研究生阶段的课题恰好就是一个回归问题,上面三点则我比较关注的。比较可惜的是,我并不是纯研究回归问题的,而是做应用类的。课题性质的原因,idea必须需要围绕业务。加之导师不做基础研究,并强调使用已经公认可行的方法,所以很多尝试,比如分类后面接回归等,其实就当做tricks了。