如何通过Python提取网页实时汇率
我是一名新西兰大学生,第一年学了Python很感兴趣,想通过爬虫抓取网页并且把纽币汇率存在txt文档中,但是苦于学校知识并不涉及爬虫技术,哪位能告诉我…
关注者
11被浏览
9,6441 个回答

IT爱好者
嘿嘿~不请自来,这种小爬虫不劳烦大神们出手了
我就先说第一个吧~
------------------------割----------------------------
汇率网址:
中国银行_金融市场_外汇牌价中国银行发布的汇率,可靠性高
(不太懂汇率方面,不知道为啥它一天要发送三次汇率,0点 、5点半、 10点半)
步骤:
- 获取网页源码
- 取得汇率数值
- 将汇率数值写到txt里面去
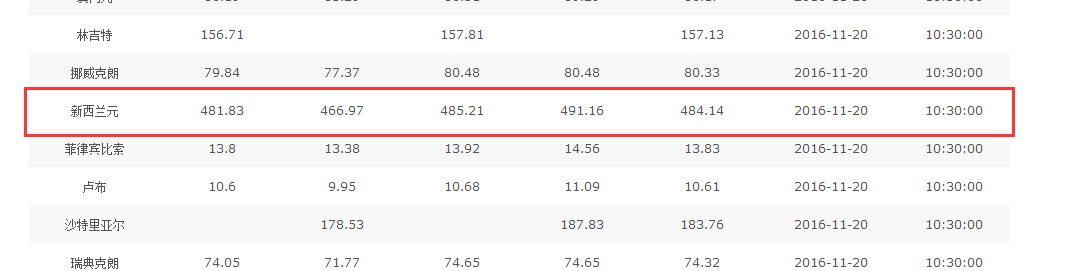

首页是10点30发布的汇率
上代码:
# -*- coding:utf-8 -*-
import re
from lxml import etree
import requests
url = 'http://www.boc.cn/sourcedb/whpj/index.html' # 网址
html = requests.get(url).content.decode('utf8') # 获取网页源码(中间涉及到编码问题,这是个大坑,你得自己摸索)
# 方式一:正则匹配
a = html.index('<td>新西兰元</td>') # 取得“新西兰元”当前位置
s = html[a:a + 300] # 截取新西兰元汇率那部分内容(从a到a+300位置)
result = re.findall('<td>(.*?)</td>', s) # 正则获取
# 方式二:lxml获取
# result=etree.HTML(html).xpath('//table[@cellpadding="0"]/tr[18]/td/text()')
#写入txt
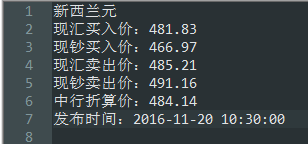
with open('汇率.txt', 'w+') as f:
f.write(result[0] + '\n')
f.write('现汇买入价:' + result[1] + '\n')
f.write('现钞买入价:' + result[2] + '\n')
f.write('现汇卖出价:' + result[3] + '\n')
f.write('现钞卖出价:' + result[4] + '\n')
f.write('中行折算价:' + result[5] + '\n')
f.write('发布时间:' + result[6] + result[7] + '\n')
方式一&方式二 各有优缺点
- 代码写三行和写一行的区别...
- 万一发布的顺序不对(比如新西兰的汇率跑第一行去了),方式二就得重新写了
最后txt文件内容: