DL/ML 模型如何部署到生产环境中?
16 个回答

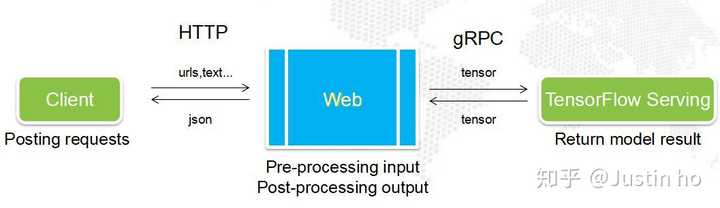
是时候给出我的文章了,如果你使用的神经网络框架是TensorFlow,那么TensorFlow Serving是你非常好的选择。目前本人用的是TensorFlow Serving + Docker + Tornado的组合,Docker非常易于部署任何模型,而Tornado负责处理高并发请求。

详细教程请移步查看我的文章:
如果你觉得有用,请先点赞再收藏。
另外,如果你使用的是其它神经网络框架,例如caffe、pytorch,我会推荐Nvidia的TensorRT Inference Server,它支持所有模型的部署,包括TF系、ONNX系、mxnet等等,TRT会先对你的网络进行融合,合并可以同步计算的层,然后量化计算子图,让你的模型以float16、int8等精度进行推理,大大加速推理速度,而你只需要增加几行简单的代码就能实现。而且TRT Inference Server能够处理负载均衡,让你的GPU保持高利用率。
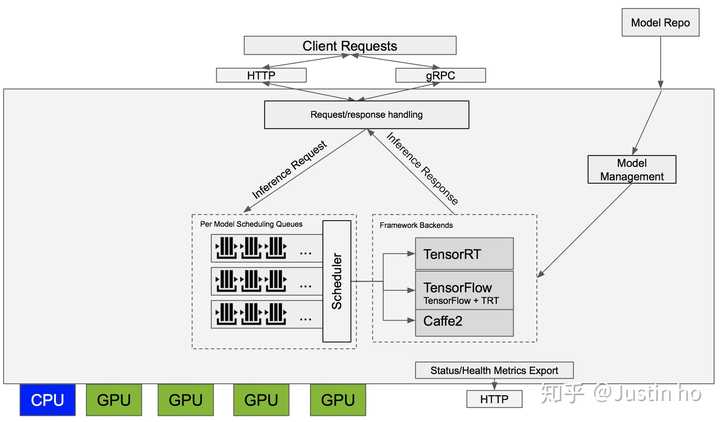

日后有机会再写一篇TRT Inference Server的教程,这里先挖个坑,大家可以保持关注。
模型部署的方式越来越简单,许多大团队已经帮在帮我们简化部署的流程,以及提高部署的性能,我们只需要学会怎么用起来,剩下的就是写一些业务逻辑了,这为我们省下了大量的时间,专注于算法的研究。
--------19.1.27更新--------
现在又写了篇Mxnet Model Server的部署教程,大家可以参考学习:

现在网上有很多关于机器学习或深度学习的文章,像数据收集、数据清洗、算法或模型选择、模型训练和验证等这些方面的资料数不胜数。但当前在数据科学领域的一项很有挑战性的难题,就是将训练好的模型面向以消费者为中心的企业和个人进行生产部署,他们往往希望借助机器学习模型将自家产品服务触及更广范围的用户,而关于部署机器/深度学习模型的文章却比较少见,因此分享一篇机器/深度学习模型部署指南。
大多数时候,我们都把大部分时间和资源花费在模型训练上,尽力获取理想的效果,因而再额外花时间和精力确定合适的计算资源和架构,试图在不同的生产环境下大规模复现模型并实现相同的效果,是一件很困难的任务。总之,这是个非常漫长的过程,甚至从决定利用深度学习技术到部署模型会耗费数月时间。
本文旨在全面概述从头部署机器/深度学习模型的整个过程,为大家部署模型提供一些指导。
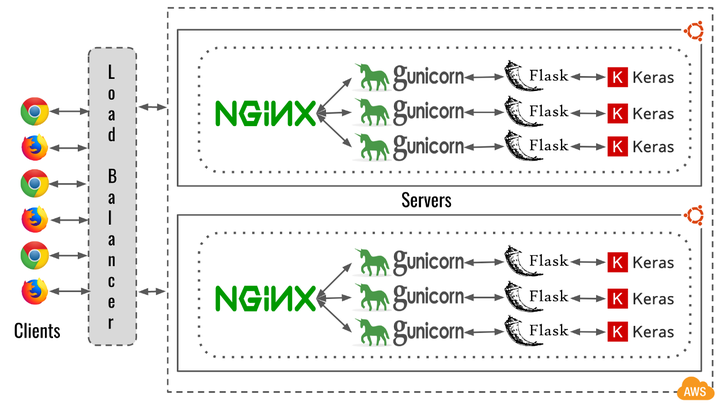

图:工作流(从客户端API到服务器预测响应)图解
注意:上图仅为一种可能的模型部署图解,主要用于学习目的。
组成部分
我们将上面描述整个 API 工作流的图解进行分解,理解每个部分。
客户端:工作流中的客户端可以是任何设备或第三方应用,用于向托管用于模型预测的架构的服务器发送请求。比如:Facebook 会在新上传的图像中尝试标记出你的脸部。
负载均衡器:负载均衡器用于通过集群中的多个服务器或实例将工作负载(请求)进行分布,目的是避免任何单一资源发生过载,进而将响应时间最小化、程序吞吐量最大化。在上图中,负载均衡器是面向公众的实体,会将来自客户端的所有请求分布到集群中的多台 Ubuntu 服务器上。
Nginx:Nginx 是一个开源网络服务器,但也可以用作负载均衡器,其以高性能和很小的内存占用而著称。它可以大量生成工作进程,每个进程能处理数千个网络连接,因而在极重的网络负载下也能高效工作。在上图中,Nginx 是某个服务器或实例的本地均衡器,用于处理来自公共负载均衡器的所有请求。我们也可以用 Apache HTTP Server 代替 Nginx。
Gunicorn:这是一个 Python WSGI HTTP 服务器,移植自 Ruby 的 Unicorn 项目。它是 pre-fork worker 模式,意味着一个主线程会创建多个称为 worker 的子进程来处理请求。由于 Python 并非多线程,所以我们尝试创建多个 gunicorn worker,它们为单独进程且有各自的内存配置,以此来实现并行处理请求。Gunicorn 适用多种 Python 框架,我们也可以用 uWSGI 代替它。
Flask:一款用 Python 编写的微型 web 框架,可以帮我们开发响应请求的 API 或 web 应用。 Flask 还有些可替代工具,比如 Django、Pyramid 和 web2py。此外,Flask-RESTful 提供了一个 Flask 扩展功能,支持快速创建 REST API。
Keras:由 Python 编写的开源神经网络库,能够在 TensorFlow、CNTK 或 MXNet 上运行。Keras 也有一些替代选择:TensorFlow、Caffe、CNTK、PyTorch、MXNet、Chainer 和 Theano。
云平台:如果存在一种平台能将上面所说的所有部分连接在一起,那就是云平台了。像计算机视觉、自然语言处理、机器学习、机器翻译、机器人等人工智能领域的迅速发展,云平台起到了莫大的作用。云平台让更多的人以很低的成本获取计算资源。目前一些著名的云平台有 AWS,Google Cloud 和 Azure。
架构设置
现在你应该已经熟悉了前一部分提到的各个部分,在接下来这一部分中,我们会从 API 角度来理解架构设置,因为这组成了 web 应用的基础部分。
注意:该架构设置基于 Python。
开发设置
训练模型:第一步是根据实际用途使用 Keras 或 TensorFlow 或 PyTorch 训练模型。确保你在虚拟环境下完成这一步,因为这有助于隔离多个 Python 环境,也能将多个必需的依赖打包入一个单独文件内。
创建API:等模型可以打包入 API 时,就可以根据需求用 Flask 或 Django 创建 API、理想状态下,你必须创建 REST 式的 API,因为这样有助于分离客户端和服务器,也能优化可见性、可靠性和可扩展性。要做一个全面的测试,确保模型响应 API 的正确预测。
Web服务器:现在是时候为你创建的 API 测试 web 服务器了。如果你是用 Flask 创建的 API,Gunicorn 是个不错的选择。下面是运行 Gunicorn web 服务器的命令示例:
gunicorn --workers 1 --timeout 300 --bind 0.0.0.0:8000 api:app
- workers (INT): The number of worker processes for handling requests.
- timeout (INT): Workers silent for more than this many seconds are killed and restarted.
- bind (ADDRESS): The socket to bind. [['127.0.0.1:8000']]
- api: The main Python file containing the Flask application.
- app: An instance of the Flask class in the main Python file 'api.py'.负载均衡器:你可以配置 Nginx 处理所有 Gunicorn 进程上的全部测试请求,每个进程都有其自己的 API 和深度学习模型。可以参考这篇文章深入理解 Nginx 和 Gunicorn 之间的配置。
加载/性能测试:看看 Apache Jmeter,这是一款开源应用,专门设计用于加载测试和衡量性能。这会有助于你理解 Nginx 加载分布。一个可替代选择是 Locust。
生产设置
云平台:在选择好云平台后,从标准的 Ubuntu 镜像中设置机器或实例。选择 CPU 机器要根据实际的深度学习模型和用途。待机器运行后,设置 Nginx、Python 虚拟环境,安装所有的依赖,拷贝 API。最后,尝试运行 API 和模型(根据定义的 Gunicorn 进程数量,加载完所有的模型可能会花费一段时间)。
自定义API镜像:确保 API 能够顺畅工作,然后捕捉实例的快照来创建包含 API 和模型的自定义镜像。快照会保存该应用的所有设置。参考教程:
Google Cloud:
https://cloud.google.com/compute/docs/images/create-delete-deprecate-private-images
Azure:
https://docs.microsoft.com/en-us/azure/virtual-machines/linux/tutorial-custom-images
负载均衡器:从云平台上创建一个负载均衡器,根据需求可以是公用也可以是专用。
参考教程:
AWS:
https://docs.aws.amazon.com/zh_cn/elasticloadbalancing/latest/classic/elb-getting-started.html
Google Cloud:
https://cloud.google.com/load-balancing/
Azure:
https://docs.microsoft.com/en-us/azure/load-balancer/quickstart-create-basic-load-balancer-portal
实例集群:使用之前创建的自定义 API 镜像来启动一个实例集群。
参考教程:
AWS:
https://aws.amazon.com/cn/premiumsupport/knowledge-center/launch-instance-custom-ami/
Google Cloud:
https://cloud.google.com/compute/docs/instances/creating-instance-with-custom-machine-type
Azure:
https://docs.microsoft.com/en-us/azure/virtual-machines/windows/create-vm-generalized-managed
集群的负载均衡器:现在,将实例集群连接到负载均衡器,这会确保负载均衡器在所有实例中平等分布工作量。
参考教程:
AWS:
Google Cloud:
https://cloud.google.com/load-balancing/docs/backend-service
Azure:
https://docs.microsoft.com/en-us/azure/load-balancer/quickstart-create-basic-load-balancer-portal
加载/性能测试:和开发中的加载/性能测试相同,在生产中遵循同样的流程,只是这里要处理数百万条请求。可以试着将架构分解,检查其稳定性和可靠性。
封装:最后,如果一切顺利,符合预期,你就有了一款能服务数百万条请求的生产级深度架构。
附加设置
除了常用设置外,还需要考虑其它一些事情,让系统能长期自我维持。
自动伸缩(Auto Scaling):这是云服务的一项功能,可以根据收到的请求数量扩展应用的实例。当请求数量激增时,我们就可以进行扩展,下降时可以缩小。
参考教程:
AWS:
https://docs.aws.amazon.com/zh_cn/autoscaling/ec2/userguide/what-is-amazon-ec2-auto-scaling.html
Google Cloud:
https://cloud.google.com/compute/docs/autoscaler/
Azure:
https://docs.microsoft.com/en-us/azure/architecture/best-practices/auto-scaling
应用更新:有时你需要更新应用,使用最新的深度学习模型,或者更新应用的功能,但是在不影响生产中应用行为的情况下,怎样更新所有实例?云服务提供了一种方法,能以多种方式完成这项工作,不过各个云平台的工作方式有所不同。
参考教程:
AWS:
https://aws.amazon.com/cn/premiumsupport/knowledge-center/auto-scaling-group-rolling-updates/
Google Cloud:
https://cloud.google.com/compute/docs/instance-groups/updating-managed-instance-groups
Azure:
https://azure.microsoft.com/en-in/updates/auto-os-upgrades/
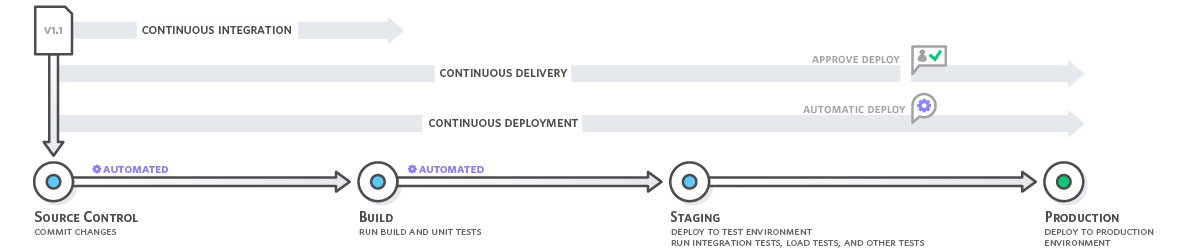
持续集成:它是指将软件发布过程中的创建和单元测试阶段。每个提交的修订版会触发自动创建和测试,可用于将最新版的模型部署到生产环境中。

可选平台
另外还有一些系统能够以结构化方式在生产环境中部署和伺服模型,比如:
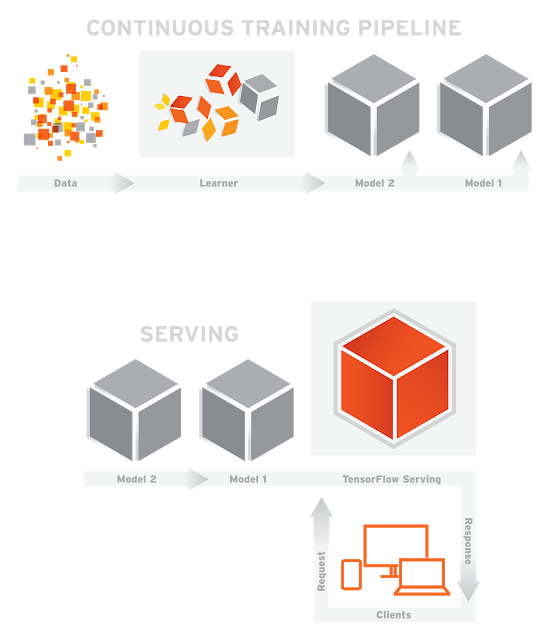
TensorFlow Serving:一款开源平台软件库,可以将训练好的机器学习模型部署到线上。而且有一系列用于 TensorFlow 模型的开箱即用支持软件。

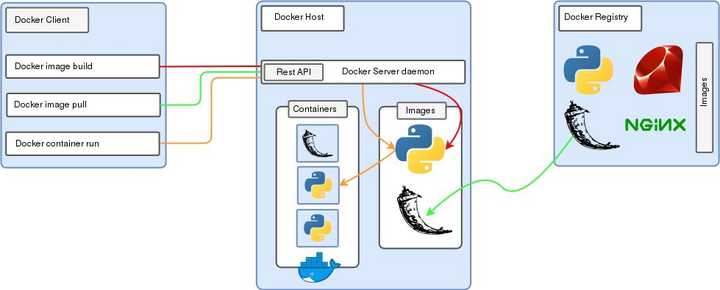
Docker:一种容器虚拟化技术,作用相当于一个轻量级虚拟机。其能够有效地隔离应用和应用在后期操作系统中的环境依赖。运行在同一实例中的不同应用会有多个 Docker 镜像,但不共享相同的资源。

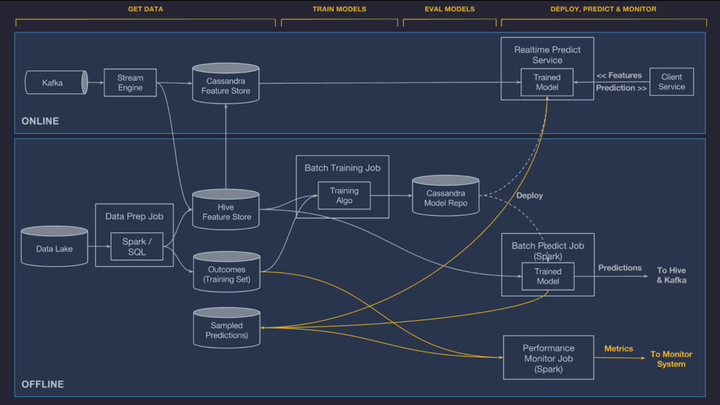
Michelangelo:Uber 推出的一个机器学习平台,包含创建、部署和运行机器学习解决方案。

希望本文能帮大家理解将深度/机器学习模型从开发环境部署到生产环境的过程概览。后面会具体分享如何用 Flask 部署 Keras 深度学习模型,附有操作步骤和代码,欢迎关注我们。
参考资料:
https://medium.com/@maheshkkumar/a-guide-to-deploying-machine-deep-learning-model-s-in-production-e497fd4b734a