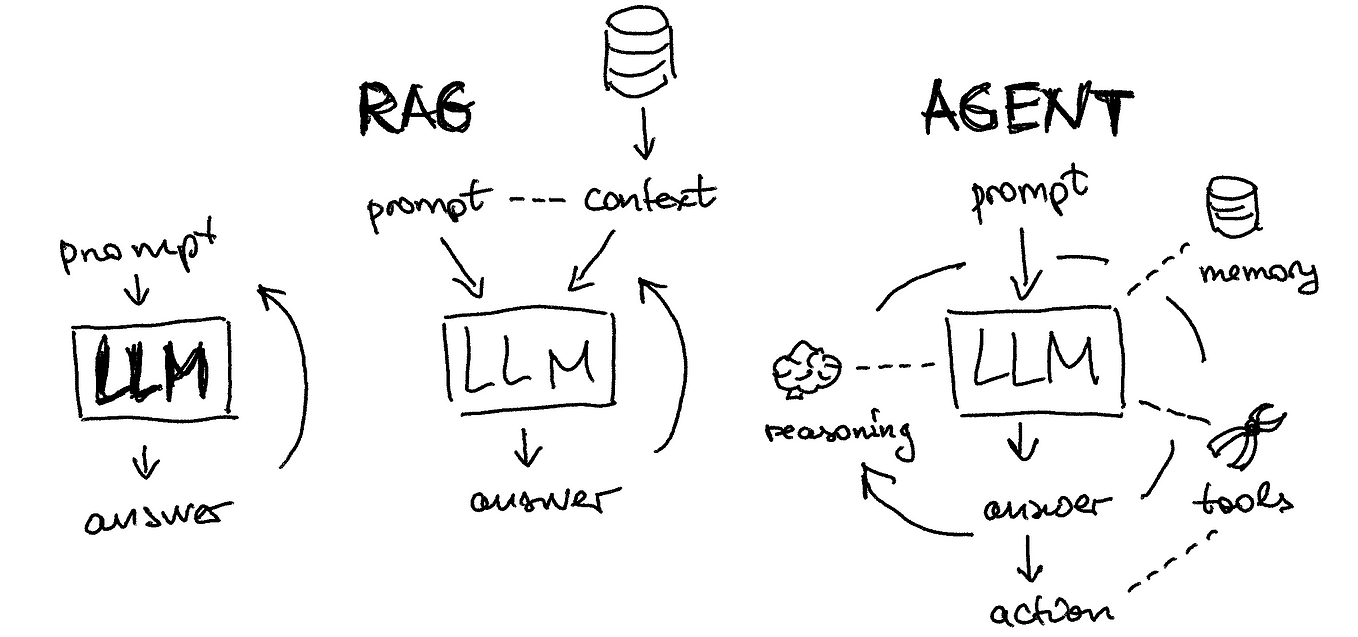
Understanding Neural Machine Translation: Encoder-Decoder Architecture
The state of the art for machine translation has utilized Recurrent Neural Networks (RNNs) using an encoder-attention-decoder model. Here I will try to cover how it all works from a high level view.
Language Translation: Components
We can break translation into two components: the individual units and the grammar:

We need to encode sequences of words into vector spaces in order to perform computations in a neural net. Because the words also have meaningful sequences, a recurrent neural network is suitable for this task:

The problem
This encoder-decoder architecture, however, breaks down after about 20+ word sentences:

Why? Longer sentences illustrate the limitations of a single-directional encoder-decoder architecture.
Because language consists of tokens and grammar, the problem with this model is it does not entirely address the complexity of the grammar.
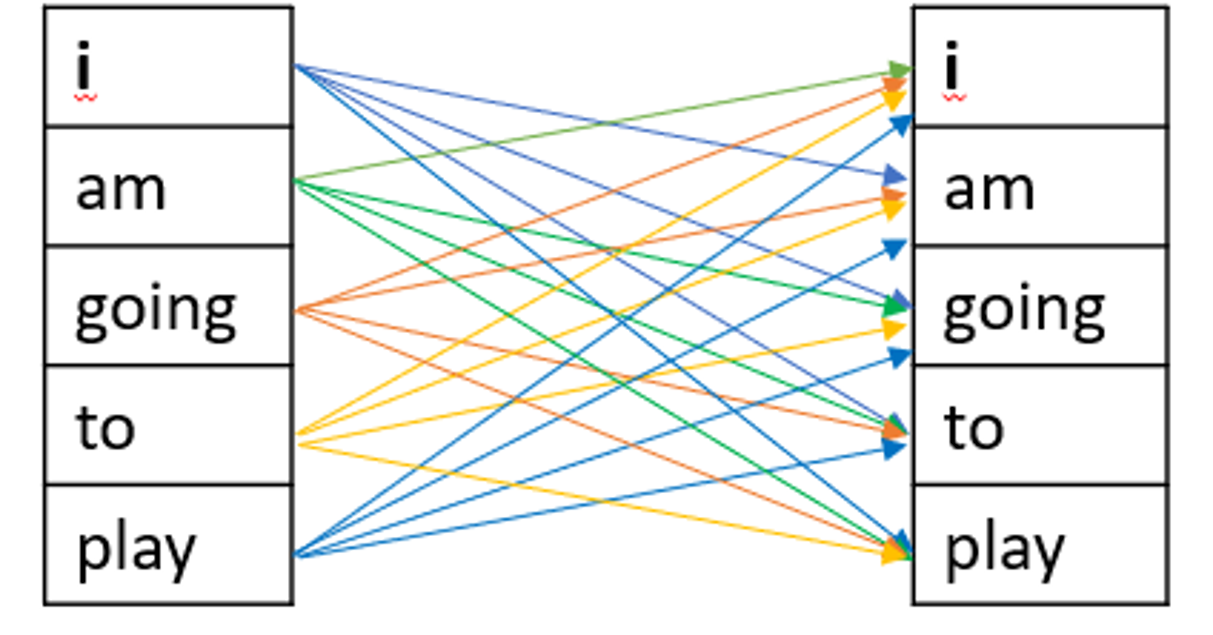
Specifically, when translating the nth word in the source language, the RNN was considering only the 1st n-word in the source sentence, but grammatically, the meaning of a word depends on both the sequence of words before and after it in a sentence:

A solution: The bi-directional LSTM model
If we use a bi-directional model, it allows us to input the context of both past and future words to create an accurate encoder output vector:

But then, the challenge then becomes, which word do we need to focus on in a sequence?
In 2016, Bahdanau et. al. came out with a paper that shows we can learn which words in the source language to focus on by storing the previous outputs of the LSTM cells, then ranking them by the relevancy of each, and picking the word with the highest score:

Below, you can see how this looks in the graphs: the resulting architecture then embeds this Attention mechanism in between the Encoder and Decoder:

You can see there is a performance upgrade over the previous Encoder-Decoder architecture:

This is it in a nutshell, and it is also how Google Translate’s NMT works, albeit scaled up with a larger number of layers for the encoder LSTMs.
That’s it in a nutshell, to recap:
- The encoder takes each word in the source language and encodes it into vector space
- These vector representations of words are then passed into an attention mechanism which determines which source words to focus on while generating some output for the desired language.
- This output is passed through a decoder that turns the vector representations into the target language
Illustrations from CS Dojo Community