【為什麼我們要挑選這篇文章】假設檢定(Hypothesis Testing)是科學研究、新藥開發等關鍵檢定技術,當 p 值小於一個數字(通常是 0.05 或 0.1),研究者就會推翻假設。然而有一些科學家連署,要求停止使用 p 值作為研究的判斷標準。
p 值是統計學的關鍵,也是科學研究的基礎,若停用,現在的科學研究方法就必須大改。p 值是什麼?反對的理由又是什麼?(責任編輯:郭家宏)
我們在日常生活中做決定時,總會在心裡打個小算盤——估算一下 p 值,研究者做某項檢測,根據 p 值,得出最終的結果;資本家做投資,根據以往數據的統計分佈,估算 p 值,得出最終的決策等等。p 值在潛移默化地影響著我們的生活,那麼有沒有想過我們所依賴的 p 值到底可靠嗎?
p 值的表面意義是,當原假設為真時,檢驗統計量出現某不應該值所需的機率;而實際意義則是,需要多小的機率就能出現拒絶原假設的檢驗統計值。
Nature 上的統計學家早就發現,p 值本身無法提供支持相關模式或假說之證據,p 值可能給我們每個人都上演了一場「楚門的世界」(意即不真實的世界),先附上 Nature 連結,看看他們怎麼說。
Nature 報告傳送門
不應該只因為 p 值超出顯著性水準,就認定實驗結果沒有差異或關聯
發佈這篇文章的三位統計學家,分別是瑞士巴塞爾大學的動物學教授 Valentin Amrhein,加州大學洛杉磯分校的流行病學的統計學教授 Sander Greenland,伊利諾伊州埃文斯頓西北大學的統計學方法學家和行銷學教授 Blake McShane。
他們提出:「我們永遠不應該僅僅因為 p 值大於 0.05 之類的閾值而得出『沒有差異』或『沒有關聯』,或者等價,因為信賴區間包括零。我們也不應該斷定兩項研究之間存在衝突,因為一項研究結果具有統計學意義,另一項則沒有。這些錯誤會浪費研究工作並誤導政策決策。」
(註: α 顯著性水準,是接受或拒絶原假設的機率分界點,如果 p<α,就認為在 1-α 的信賴水平下,樣本觀測值與總體假設值之間的差異是顯著的,因而不能接受原假設,即拒絶原假設。 大家對 0.05 的顯著性水準比較認可,把 p<0.05 作為了一種比較公認的判斷標準,因而符合 p<0.05 的研究結果就比較容易得到發表)
同時,文章指出,當區間估計包括嚴重的風險增加時,得出結論認為統計上不顯著的結果「無關聯」是荒謬的。聲稱這些結果與顯示相同觀察效果的早期結果形成對比同樣荒謬。然而,這些常見的做法表明,依賴統計顯著性閾值可能會誤導我們。(參見下圖)
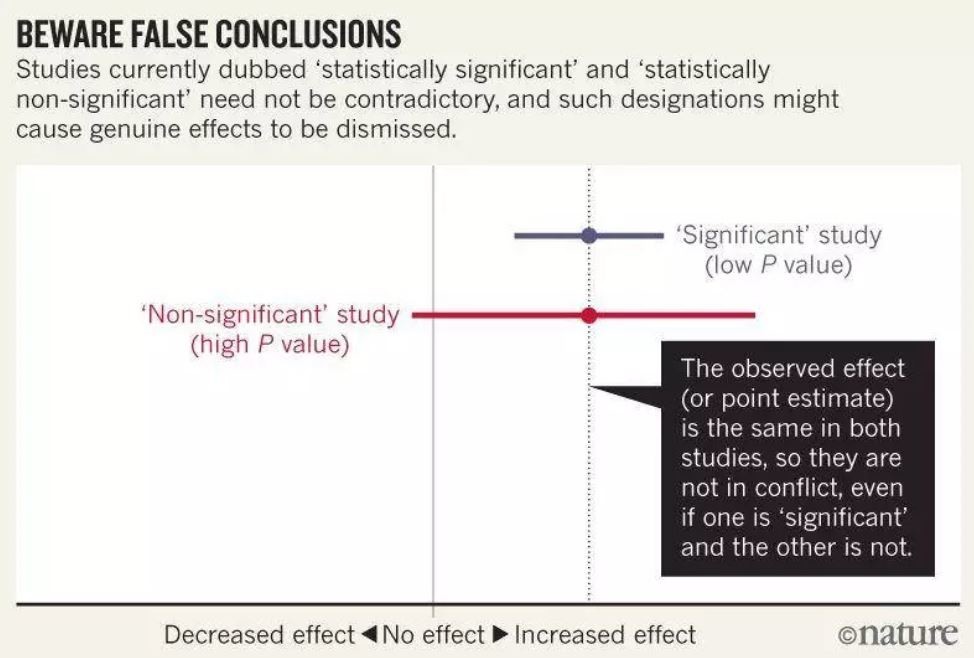
這些錯誤以及類似的錯誤普遍存在,對數百篇文章的調查發現,統計上不顯著的結果被解釋為「沒有差異」或「沒有影響」的約有一半。
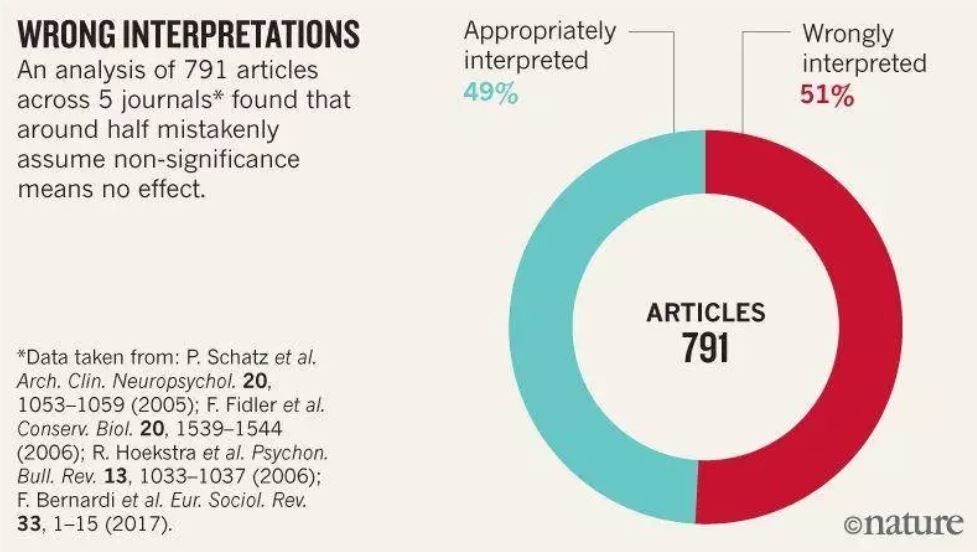
這個發現說明,我們所看到的文獻,都是所謂通過了顯著性檢驗的部分,或者說都是符合研究者意圖的部分,而對於那些沒有通過檢驗、不符合研究者意圖的研究到底是個什麼情況,我們就不得而知了。
例如研究者為了使研究結果符合自身意圖,事先透過樣本選擇、條件控制等手段對實驗設計進行了優化,選擇性地只報告符合意圖的變數,甚至選擇性地刪除、補充或修改數據,選擇性地擴大樣本容量等等。顯然,這種為了發表文章而人為地達到 p<0.05 要求的做法,是嚴重違背實事求是的科學精神和學術道德的,當然也嚴重損害了假設檢驗的聲譽。
那 p 值的真正含義是什麼?
或許,數據科學家 Admond Lee 會給我們答案,下文是他對於 p 值的探索經歷,可隨文摘菌(本文作者)一探究竟。(Admond Lee 是知名的數據科學家和顧問,憑藉其在數據科學和行業知識方面的極強的專業素養,幫助那些新創公司的創始人和各公司利用數據解決他們遇到的問題)
p 值到底是什麼?
猶記得當我作為暑期學生在歐洲核子研究中心進行第一次海外實習時(註:歐洲核子研究中心,法語為 Conseil Européenn pour la Recherche Nucléaire,簡稱 CERN,位於瑞士日內瓦西部接壤法國的邊境,是世界上最大的粒子物理學實驗室,同時也是全球資訊網的發祥地。最近以探測到「上帝粒子」—希格斯玻色子(Higgs boson)而為大眾所熟知),那時候大多數人還在談論著希格斯玻色子的發現,即使已經確認希格斯玻色子的發現滿足 5 個標準差閾值。(即 p 值為 0.0000003)
然而,那時候我對 p 值、假設檢驗甚至統計顯著性都一無所知。接下來的事你猜對了。我 google 了 p-value 這個詞,看了維基百科後我卻更困惑了……
在統計學的假設檢驗中,對一個給定的統計模型,p 值或機率值是一個特定的機率,即當原假設為真時,統計結果(例如兩個對照組中樣本均值差的絶對值)不小於實際觀測值的概率。
——維基百科
所以 p 值的真正含義是什麼呢?到了現在,尤其是當我進入數據科學領域之後,我才慢慢理解了 p 值的含義,以及它是如何在某些實驗成為決策制定工具的一部分的。
因此,我決定講清楚 p 值是什麼,以及如何將它們用於假設檢驗,以期有助於你更加直觀透徹地理解 p 值,顯然我們不能跳過對其他相關概念和 p 值定義的基本理解,但我保證會以一種直觀的方式進行解釋,而不是直接向你扔去一堆技術術語。
為你提供從建構假設檢驗到理解 p 值,我將從以下四個方面解釋我們的決策過程的全流程,我強烈建議你仔細地閲讀所有內容,從而對 p 值有一個詳細的理解:
1. 假設檢驗
2. 常態分佈
3. 什麼是 p 值?
4. 統計顯著性
假設檢驗:藉由 p 值決定是否接受虛無假設
在討論 p 值的含義之前,讓我們先理解假設檢驗吧。p 值是用於確定我們結果的統計顯著性的,而我們的最終目標就是要確定我們結果的統計顯著性。
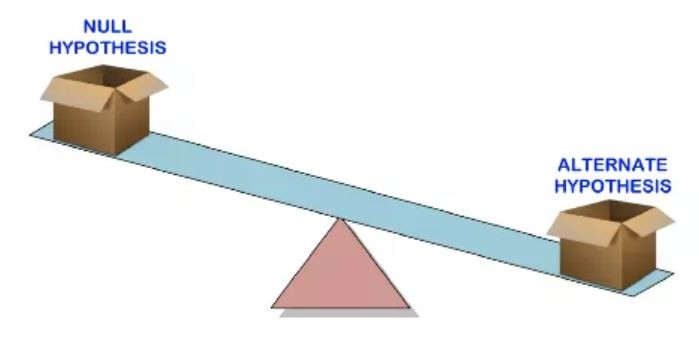
統計顯著性是建立在下面這三個簡單的概念上的:
假設檢驗
常態分佈
p 值
假設檢驗是用來檢驗利用樣本數據所得到的虛無假設(null hypothesis)是否符合總體特徵。對立假設(alternative hypothesis,也稱研究假設)則是當虛無假設被認為是錯誤的時候你需要接受的假設。
換句話說,我們首先要建立虛無假設,然後用樣本數據檢驗虛無假設是否成立。如果不成立,那我們就接受對立假設。就這麼簡單。
為了判斷虛無假設是否成立,我們需要用 p 值來衡量它的統計顯著性。如果數據更傾向於支持對立假設,那我們就拒絶虛無假設,接受對立假設。這將在後面的部分中進一步解釋。
讓我們用一個例子來加深對概念的理解,這個例子在之後介紹其它概念時也會用到。
範例:假設一家披薩店聲稱他們的配送時間不多於 30 分鐘,但你覺得他在說謊。於是你隨機抽取了一些配送時間,然後用假設檢驗的方法來驗證你的觀點:
虛無假設—平均配送時間不多於 30 分鐘
對立假設—平均配送時間大於 30 分鐘
我們需要確定的是樣本數據更傾向於支持哪一個假設。因為我們只關心平均配送時間是否大於 30 分鐘,所以我們這裡使用單側檢驗。因為我們只想知道配送時間大於 30分鐘的可能性,所以忽略配送時間不大於 30 分鐘這一方面的可能性。換句話說,我們只想知道披薩店是否撒謊了。
假設檢驗的常用方法之一是 z 檢驗。這裡我們只想知道結果的含義,所以對於該方法的底層理論就不做詳細介紹了。
常態分佈:可用 3σ 法則檢驗數據有效性
常態分佈是一個用來描述數據分佈特徵的機率密度函數,常態分佈有兩個參數:平均值 μ 和標準差 σ。平均值描述的是數據分佈的集中趨勢,它決定了常態分佈的峰值位置;標準差描述的是數據分佈的離散趨勢,它決定了這些值與平均值的距離。
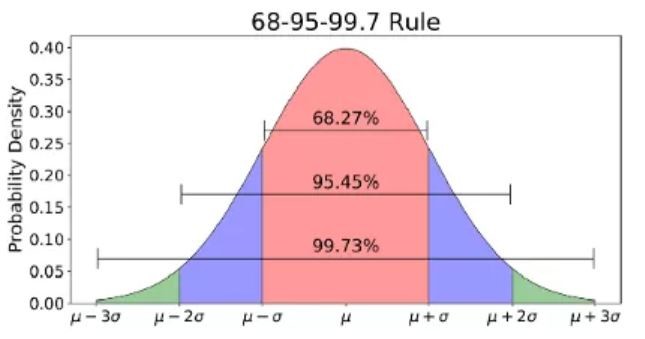
常態分佈通常與 68-95-99.7 法則(即 3σ 法則)聯繫在一起。(如上圖所示)
68% 的數據在平均值的 1 個標準差內
95% 的數據在平均值的 2 個標準差內
99.7% 的數據在平均值的 3 個標準差內
還記得我在開頭談到希格斯玻色子的發現時,提到的 5 個標準差的閾值嗎(”five sigma”threshold)?
5σ 是指 99.9999426696856% 的數據都能夠證實確實發現了希格斯玻色子。這是一個嚴格設置的閾值,以避免任何潛在的錯誤信號。
哇,好酷啊!現在你可能想知道,「那如何將常態分佈應用到以前所說的假設檢驗中呢?」
因為我們用 z 檢驗來做假設檢驗,那我們就要先計算 z 值(z-scores)。z 值是指一個數據點離平均值有多少個標準差的距離。在這個例子中,每個數據點就是我們收集的披薩配送時間。
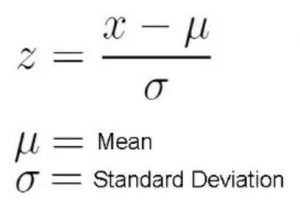
注意,當我們計算好了每個披薩配送時間的 z 值、並且繪製了如下的標準正態分佈曲線圖後,x 軸上的單位就由分鐘變成了標準差,這是因為我們通過將數據減去平均值後再除以標準差,從而對數據做了標準化處理(見上方公式)。
觀察標準常態分佈曲線圖很有用,因為我們可以將測試結果和經過標準化處理的「正常」總體進行比較。尤其是變數的量值不同時,標準化處理就十分有必要了。
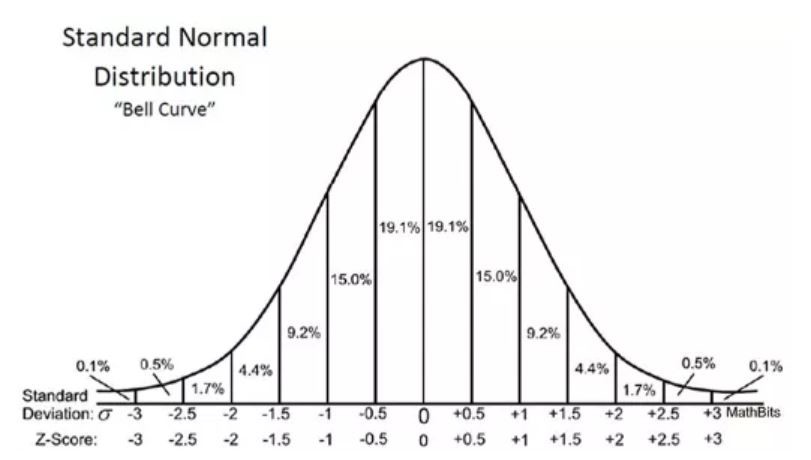
z 值可以告訴我們整體數據相對於平均值的位置。
我很喜歡 Will Koehrsen 的說法—— z 值越高或是越低,結果就越不可能是偶然發生的,結果也就越有意義,但是,z 得分究竟為多少時,才能確保我們的結果是有意義並且可以量化的呢?
敲黑板,劃重點,這時候就需要用到我們之前談到的 p 值了。透過和預先設置的顯著性水平進行比較,我們就可以判定結果是否具有統計顯著性。
p 值:數據是否支持虛無檢設的檢驗數字
終於說到了 p 值!之前的那些內容只是一個鋪陳,現在有請我們的主角— p 值登場!但是,為了理解這個神秘的 p 值,以及它是如何應用到假設檢驗中去的,你們還是不能把先前說到的那些還給我。
如果你還記得上面的內容,那麼恭喜你,接下來你讀到的會是這篇文章中最精采的部分。這裡,我們不用維基百科所給出的關於 p 值的定義,而是用我們之前提到過的披薩配送時間!
回想一下,我們曾為了檢驗平均配送時間是否大於 30 分鐘,而隨機抽取了一些披薩配送時間。如果最終結果支持披薩店的說法(即平均配送時間不多於 30 分鐘),我們就不推翻虛無假設;否則,就拒絶它。
在這裡 p 值就派上用場了:我手頭這些數據足以說明披薩配送時間不多於三十分鐘,即虛無假設是正確的嗎?而 p 值正是用機率回答了這一問題。p 值越小,證據看起來就越無力。相應地,虛無假設看起來就越荒謬。當我們認為虛無假設過於荒謬時應該怎麼辦呢?當然是拒絶它,轉投對立假設的懷抱啦!如果 p 值小於一個預先設置的顯著性水平(一般也稱為 α 值,我叫它荒謬閾值——不要問我為什麼,我只是覺得這樣更容易理解),就拒絶虛無假設。
現在我們終於理解 p 值的意義了。讓我們打鐵趁熱,應用到我們的例子中去吧。
披薩配送時間中的 p 值:既然我們已經收集了一些樣本時間,就可以計算一番了。我們發現,平均配送時間延長了 10 分鐘,相應的 p 值為 0.03。這意味著,由於隨機雜訊的干擾,我們有 3% 的可能性觀測到平均配送時間至少延長了十分鐘。p 值越低,結果就越有意義,它由雜訊引起偏差的可能性就越小。
在我們的例子中,大多數人對 p 值都有一個常見的誤解:p 值為 0.03 意味著結果中的 3% 情況是偶然出現的。這個想法是錯誤的。人們往往想得到一個明確答案(包括我),也正是因為這點,怎樣解釋 p 值困惑了我很長時間。
p 值說明不了任何事。它僅僅是以預期比較為基礎的一種方法,幫助我們做出一個相對合理的決策。
—— Cassie Kozyrkov
下面是如何用 0.03 的 p 值來幫助我們做出合理決策的方法:
想像一下,我們現在生活在一個披薩平均配送時間不多於 30 分鐘的世界,在分析了樣本數據之後,p 值為 0.03,低於顯著性水準 0.05(假定我們預設了該顯著性水準),那麼我們就可以說這個結果具有統計顯著性。我們堅信披薩店是不會欺騙我們的。可是,當具有統計顯著性的結果告訴我們事實並不是這樣時,我們就需要考慮下我們最初的信念是否還有意義。那我們又該怎麼做呢?首先,我們要想盡一切辦法來維護原假設。但是隨著披薩店得到的差評越來越多,並且還經常為不及時的配送尋找糟糕的藉口,以致於我們這些友軍也覺得繼續為披薩店進行辯護是十分荒謬的,因此,我們決定拒絶原假設!最後,我們做出了一項合理決策,就是再也不在這家店買披薩了。你應該早已意識到了,根據我們的例子來看,p 值不能用於證明任何東西。
我認為,p 值就是當結果具有統計顯著性時,一個用來挑戰我們初始信念(原假設)的工具。當我們覺得初始信念十分荒謬那一刻(假設 p 值顯示結果是統計顯著性的),我們就決定拋棄它(拒絶原假設),並做出一個合理的決定了。
統計顯著性:決定是否要推翻虛無假設
最後,我們將此前提到的所有內容放在一起,並檢測結果是否具有統計顯著性,只有 p 值是不夠的,我們還需要設置一個閾值(又叫做顯著性水平 α)。每次實驗之前都應該預先設置好 α 以防偏差。如果觀察到的 p 值小於 α 值,那麼我們就認為結果具有統計顯著性。通常我們將 α 值設定為 0.05 或 0.01(這個值的設定取決於你所要研究的問題)。
如前所述,假設實驗前我們就把 α 值設定為 0.05,因為 p 值為 0.03,低於 α 值,所以我們認為所得到的結果具有統計顯著性。
為了方便參考,下面列出整個實驗的基本步驟:
1. 陳述虛無假設
2. 陳述對立假設
3. 確定要使用的 α 值
4. 找到與你的 α 水平相關聯的 z 值
5. 使用該公式查詢測試統計資訊
6. 如果檢驗統計量的值小於 α 水平的 z 值(或者 p 值小於 α 值),就拒絶虛無假設,否則就不推翻虛無假設。
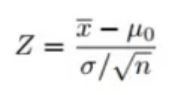
不可否認的是,p 值本來就讓很多人困惑不已。作為一名數據科學家,Admond Lee 也是花了很長時間才真正理解了 p 值的含義以及如何將它應用到決策過程中去。但是不要過度依賴 p 值,因為它只能幫助到我們整個決策中的一小部分而已。
原文傳送門
(本文經合作夥伴 大數據文摘 授權轉載,並同意 TechOrange 編寫導讀與修訂標題,原文標題為〈被Nature科学家封杀的P值,到底有什么意义?〉。首圖來源:Max Pixel CC Licensed)
更多關於統計學的文章
機器學習跟統計學差在哪?哈佛博士:機器學習重視預測結果,統計學在乎因果推理
統計學基礎遭質疑!p 值、信賴區間為何被 800 名科學家連署反對?
Google 首席工程師是這樣理解數據的!8 分鐘教會你什麼叫真正的「統計學」