Intuitive explanation of Neural Machine Translation
A simple explanation of Sequence to Sequence model for Neural Machine Translation(NMT)
What is Neural Machine Translation?
Neural machine translation is a technique to translate one language to another language. An example could be converting English language to Hindi language. Let’s consider if you were in an Indian village where most of the people do not understand English. You intend to communicate effortlessly with the villagers. In such a scenario you can use neural machine translation.
Neural Machine Translation is the task of converting a sequence of words from a source language, like English, to a sequence of words to a target language like Hindi or Spanish using deep neural networks.
What are the characteristic required for neural machine translation?
- Ability to persist sequential data over several time steps
NMT uses sequential data which needs to be persisted over several time steps. Artificial neural network(ANN) does not persists the data over several time steps. Recurrent Neural network(RNN) like LSTM(Long Short Term Memory) or GRU(Gated Recurrent Unit) are capable of persisting data over several time steps
- Ability to handle input and output vectors of variable lengths
ANN and CNN’s need a fixed input vector to which you apply an function to produce a fix sized output. Translating one language to another language consists of sequence of words of variable length both from source language as well as target language.

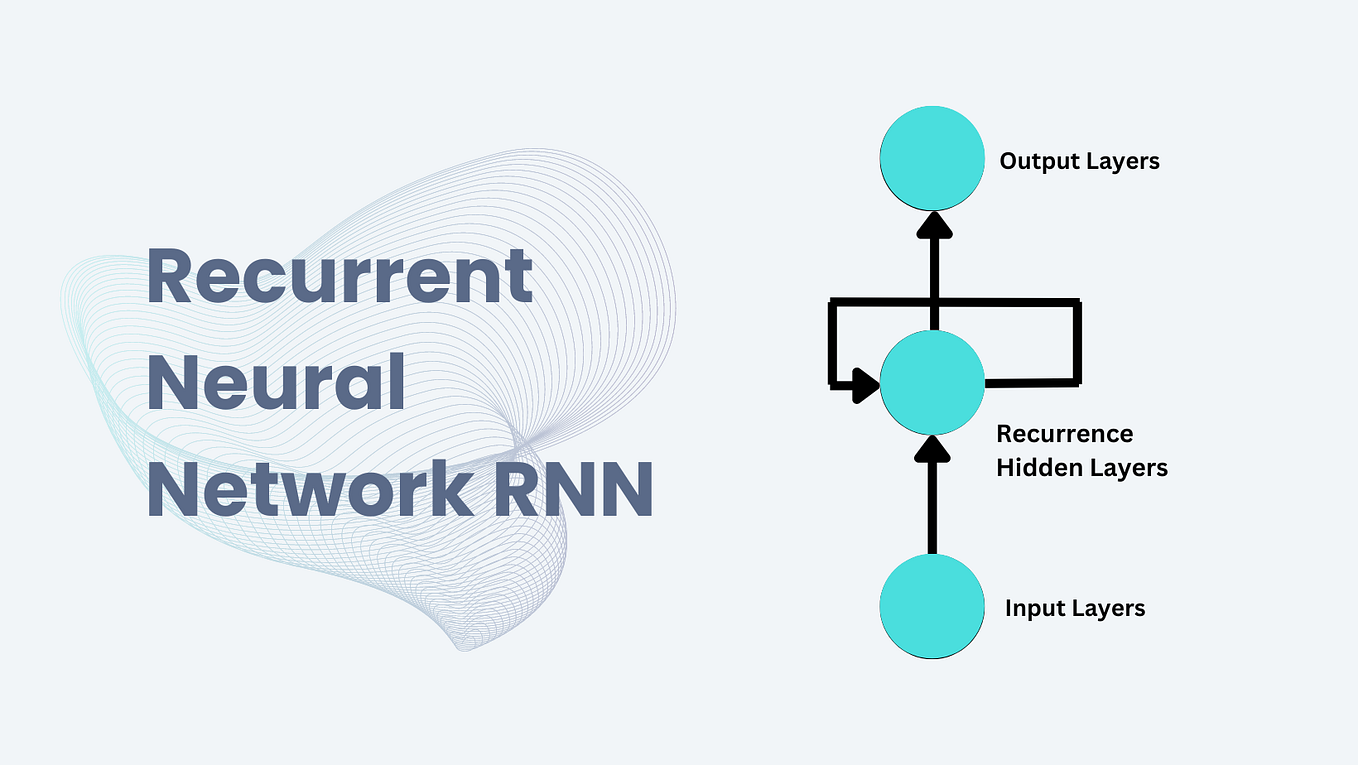
How does RNN’s like LSTM or GRU help with sequential data processing?
RNN’s are neural networks with loops to persist information. They perform the same task for every element in the sequence and the output elements are dependent on previous elements or states. This is exactly what we need to process sequential data
RNN’s can have one or more inputs as well as one or more outputs. This is another requirement for processing sequential data i.e. variable inputs and variable outputs

Why we cannot use RNN for neural machine translation?
In ANN we do not share weights among different layers of the network, hence, we do not need to sum the gradients. RNN’s share weights and we need to sum up the gradients for W at each step in time as shown below.
Computing gradient of h at time step, t =0 involves many factors of W as we need to back propagate through each of the RNN cells. Even if we forget the weight matrix and multiply the same scalar value again and again for let’s say 100 time steps this presents a challenge.
If the largest singular value is greater than 1, then the gradient would explode, called as Exploding gradient.
If the largest singular value is less than 1, then the gradient would vanish, called as Vanishing gradient.

Exploding gradient is solved by using Gradient Clipping, In gradient clipping we set a threshold value for the gradient. If the gradient value is greater than the threshold value we clip it.
Vanishing gradient issue is resolved by using LSTM(Long Short Term Memory) or Gated Recurrent Unit(GRU).
What is LSTM and GRU ?
LSTM is Long Short Term Memory and GRU is Gated Recurrent Unit. They are capable of learning long term dependencies quickly. LSTM can learn to bridge time intervals in excess of 1000 steps. This is achieved by an efficient gradient based algorithm that uses constant error flow through the internal states.
LSTM and GRU remember information over a long time steps. They do this by deciding what to remember and what to forget.
LSTM uses 4 gates to decide if we need to remember the previous state. Cell states play a key role in LSTM. LSTM can decide if they want to add or remove information from a cell state using the 4 regulated gates. These gate acts like faucets to determine how much information should flow through.

GRU is simpler variant of LSTM to solve vanishing gradient problem
It uses two gates: reset gate and an update gate unlike the three steps in LSTM. GRU does not have an internal memory
Reset gate decides how to combine the new input with the previous time steps’s memory. Update gate decides how much of the previous memory should be kept.
GRU have fewer parameters so they are computationally more efficient and need less data to generalize than LSTM
How do we use LSTM or GRU for neural machine translation?
We create a Seq2Seq model using an encoder and decoder framework with LSTM or GRU as the basic blocks
Sequence to Sequence model maps a source sequence to target sequence. Source sequence is input language to the machine translation system and target sequence is the output language.
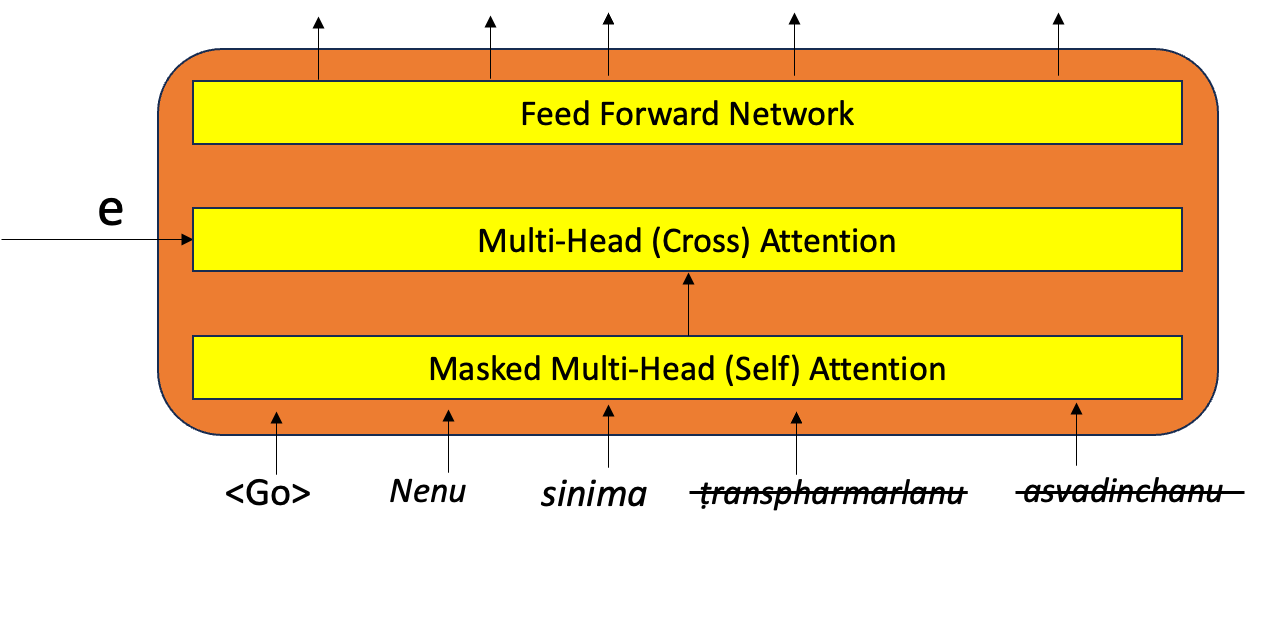
Encoder : reads the input sequence of words from source language and encodes that information into a real valued vectors also known as the hidden state or thought vector or context vector. Thought vector encodes the “meaning” of the input sequence into a single vector. The encoder outputs are discarded and only the hidden or internal states are passed as initial inputs to the decoder
Decoder: takes the thought vector from the encoder as an input along with the start-of-string <START> token as the initial input to produce an output sequence.
Encoder reads the input sequence word by word, similarly the Decoder generates the output sequence word by word.
Decoder works differently during training and inference phase where as encoder works the same during training and inference phase
Training Phase of the decoder

We use Teacher Forcing for faster and efficient training of the decoder.
Teacher forcing is like a teacher correcting a student as the student gets trained on a new concept. As the right input is given by the teacher to the student during training, student will learn the new concept faster and efficiently.
Teacher forcing algorithm trains decoder by supplying actual output of the previous timestamp instead of the predicted output from the previous time as inputs during training.
we add a token <START>to signal the start of the target sequence and a token <END> as the last word of the target sequence. The <END>token is later used during Inference phase as stop condition to denote the end of the output sequence.
Inference phase of the decoder

During the inference or prediction phase we do not have the actual output sequences or word. During the inference phase, we pass the predicted output from the previous time step as the input to the decoder along with the hidden states.
The first time step in the prediction phase of the decoder will have the final states from the encoder and the <START> tag as input.
For subsequent time steps, the input to the decoder will the hidden states from the previous decoder as well as the the output from the previous decoder.
The prediction phase stops when we hit the max target sequence length or the <END> token.
Note: This is just an intuitive explanation of Seq2Seq. we create word embeddings for the input language words and target language words. Embedding provides a dense representation of words and their relative meanings.
How can we improve the performance of the seq2seq model?
- Large training data set
- Hyperparamater tuning
- Attention mechanism
What is Attention mechanism?
Encoder passes the context vector or thought vector to the decoder. Thought or context vector is a single vector that summarizes the entire input sequence. There might be input words that may need a more attention due to their impact on the translation.
The basic idea of attention mechanism is avoid attempting to learn a single vector representation for each sentence. Attention mechanism pays attention to certain input vectors of the input sequence based on the attention weights. This allows the decoder network to “focus” on a different part of the encoder’s outputs. It does this for every step of the decoder’s own outputs using a set of attention weights.
We will get into the details of Attention mechanism, Beam search and BLEU score in the next post
References:
Neural Machine Translation and Sequence-to-sequence Models: A Tutorial Graham Neubig