



Big Data Cogn. Comput. 2024, 8(4), 42; https://doi.org/10.3390/bdcc8040042 - 07 Apr 2024
Abstract
The advent of autonomous vehicles has heralded a transformative era in transportation, reshaping the landscape of mobility through cutting-edge technologies. Central to this evolution is the integration of artificial intelligence (AI), propelling vehicles into realms of unprecedented autonomy. Commencing with an overview of
[...] Read more.
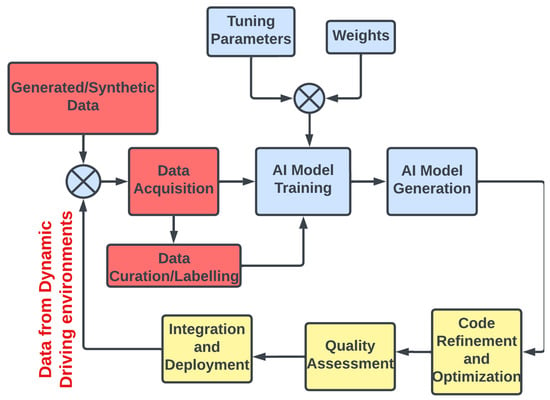
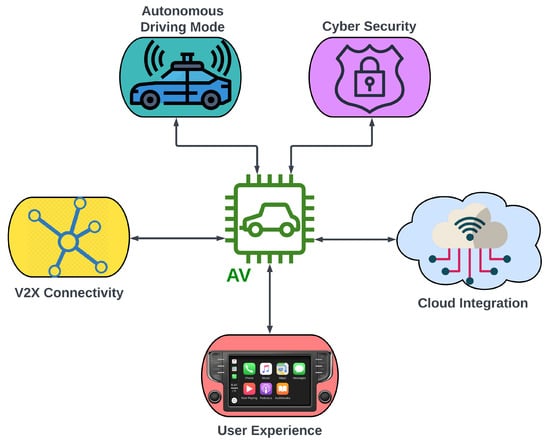
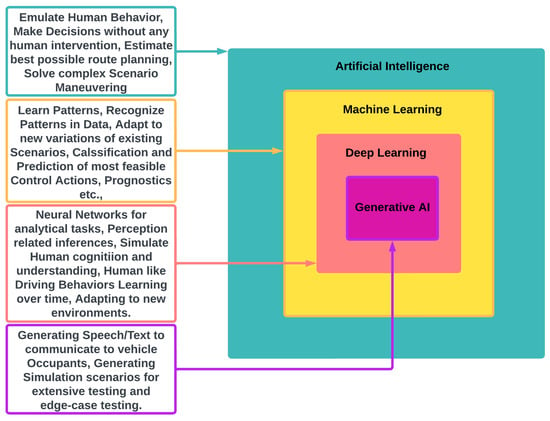
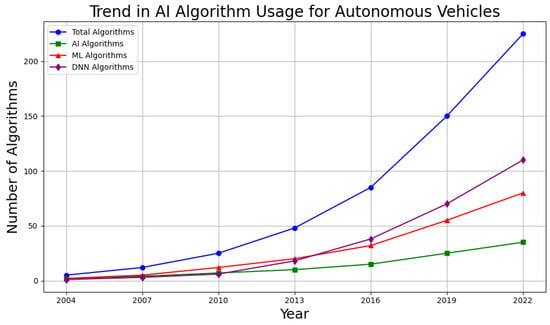
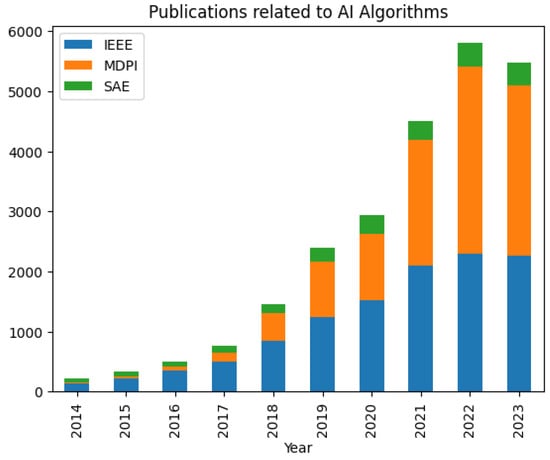
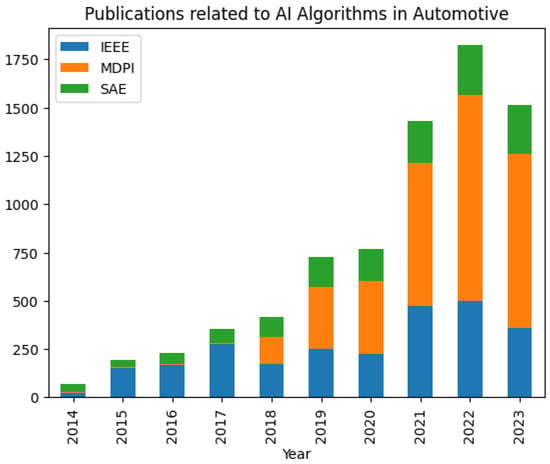
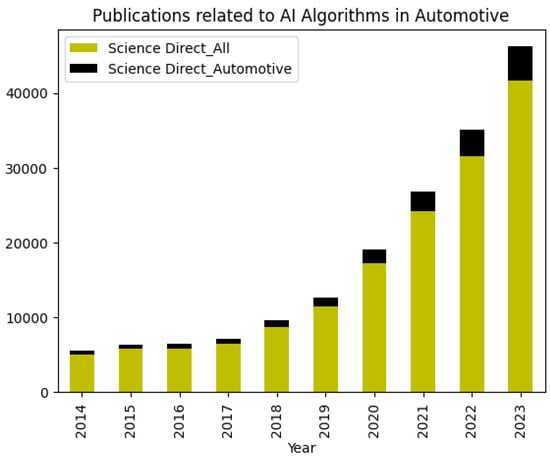
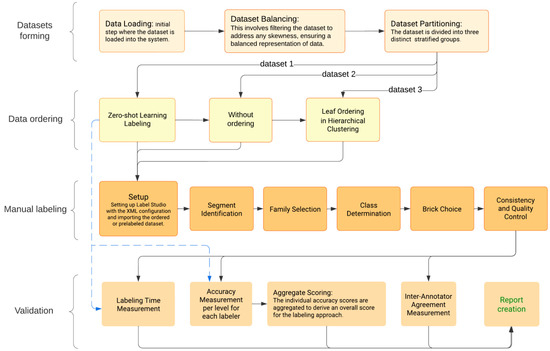
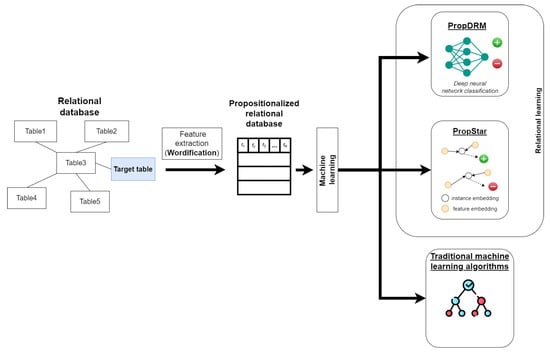
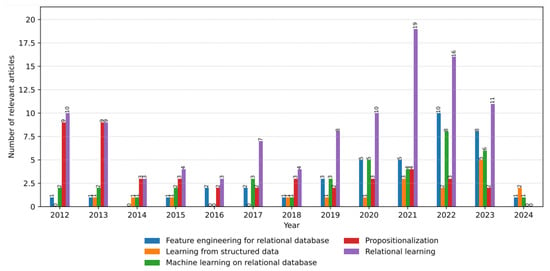
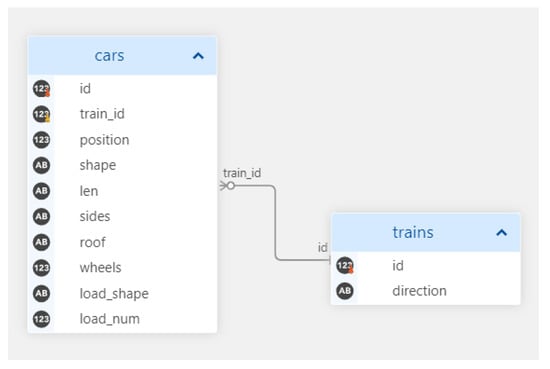
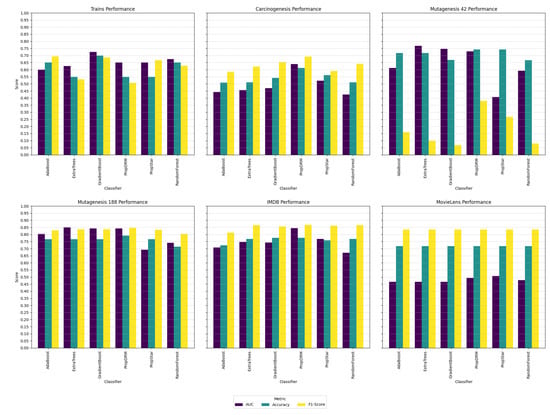
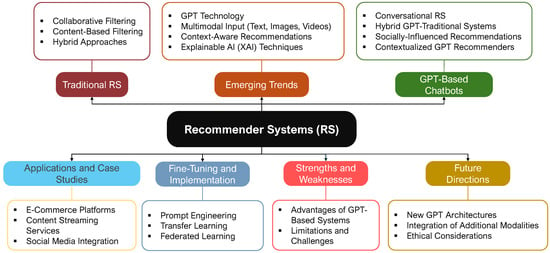
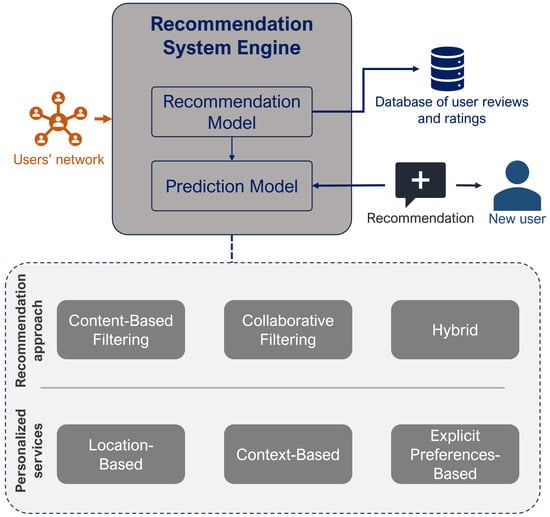
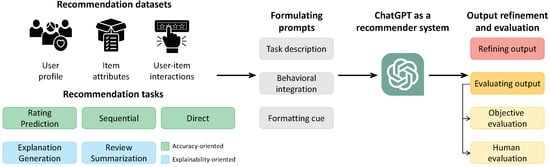
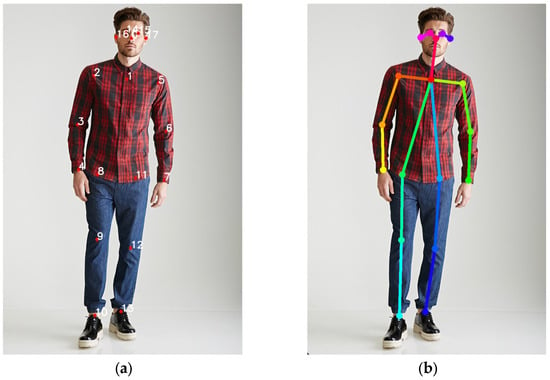
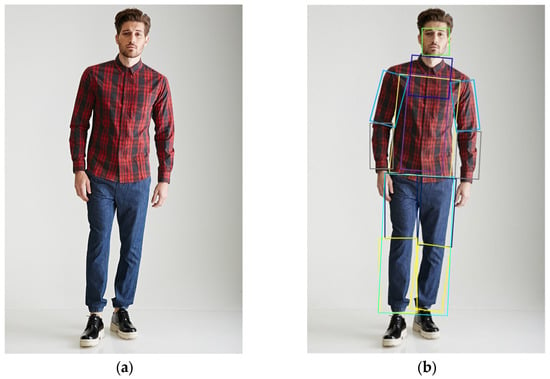
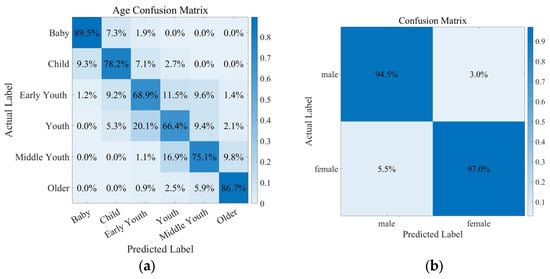
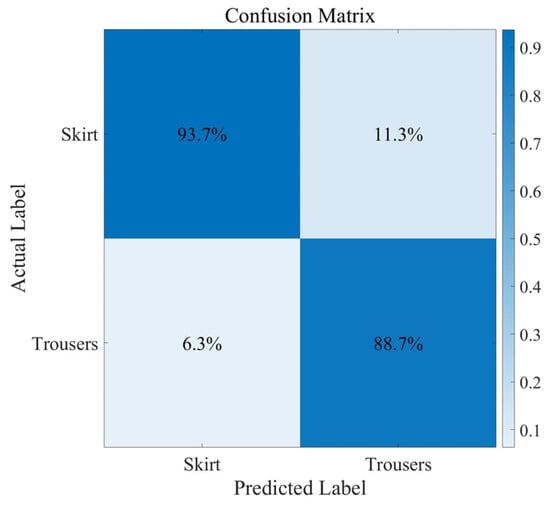
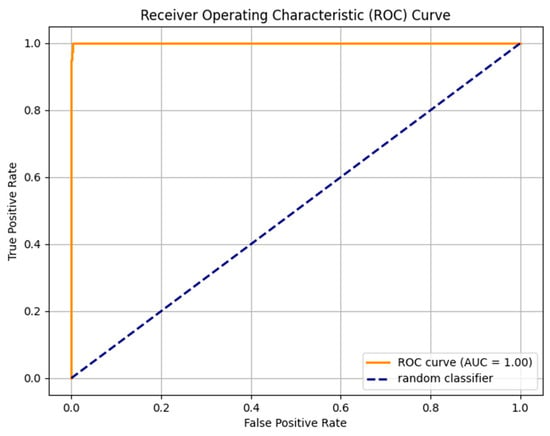
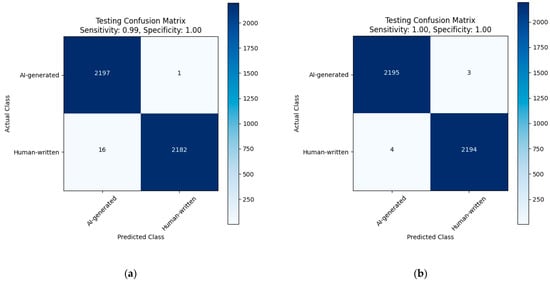
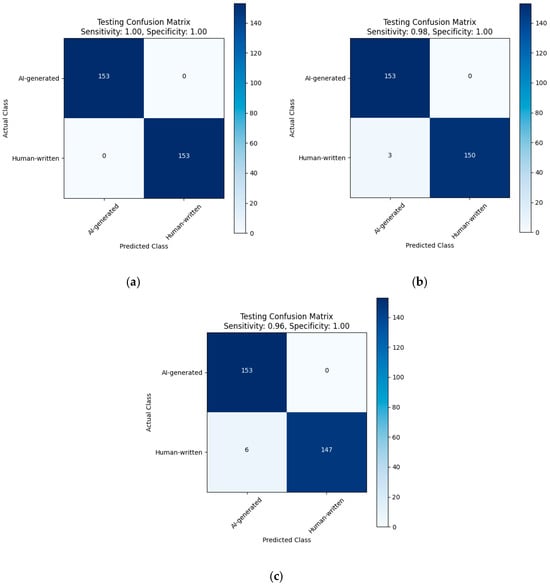
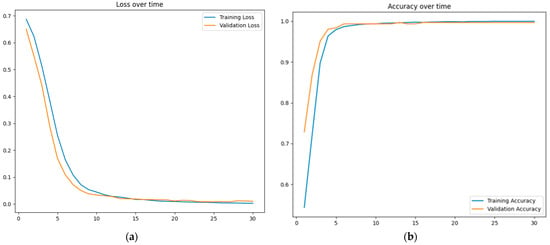
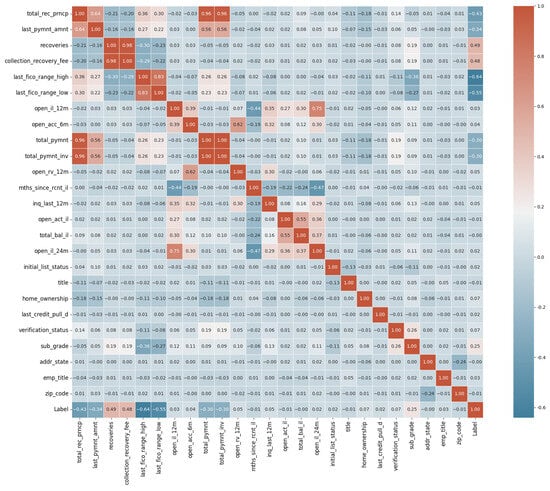
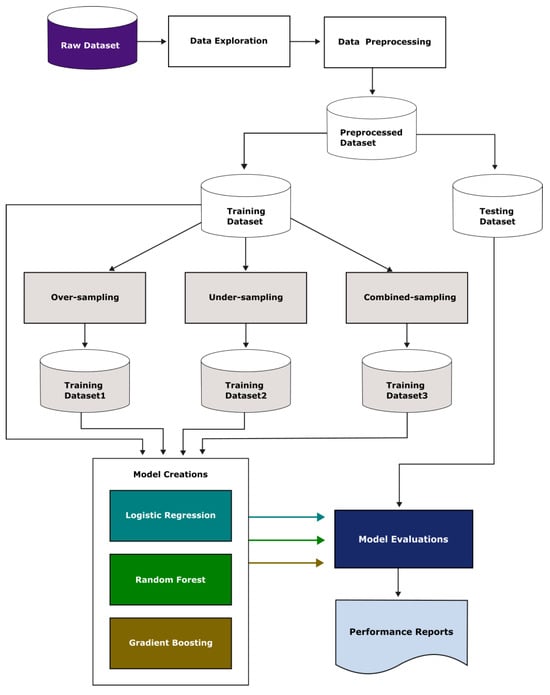
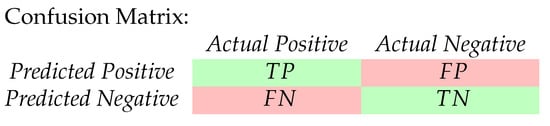
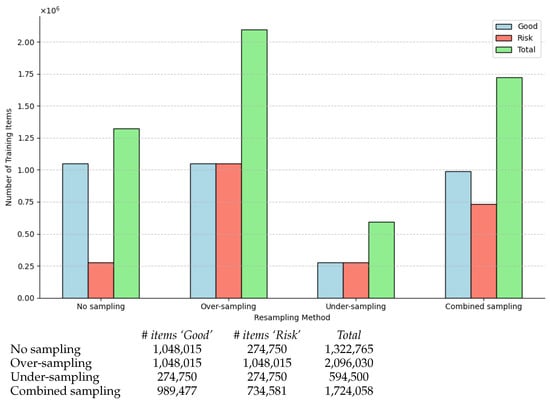
The advent of autonomous vehicles has heralded a transformative era in transportation, reshaping the landscape of mobility through cutting-edge technologies. Central to this evolution is the integration of artificial intelligence (AI), propelling vehicles into realms of unprecedented autonomy. Commencing with an overview of the current industry landscape with respect to Operational Design Domain (ODD), this paper delves into the fundamental role of AI in shaping the autonomous decision-making capabilities of vehicles. It elucidates the steps involved in the AI-powered development life cycle in vehicles, addressing various challenges such as safety, security, privacy, and ethical considerations in AI-driven software development for autonomous vehicles. The study presents statistical insights into the usage and types of AI algorithms over the years, showcasing the evolving research landscape within the automotive industry. Furthermore, the paper highlights the pivotal role of parameters in refining algorithms for both trucks and cars, facilitating vehicles to adapt, learn, and improve performance over time. It concludes by outlining different levels of autonomy, elucidating the nuanced usage of AI algorithms, and discussing the automation of key tasks and the software package size at each level. Overall, the paper provides a comprehensive analysis of the current industry landscape, focusing on several critical aspects.
Full article
(This article belongs to the Special Issue Deep Network Learning and Its Applications)
►
Show Figures
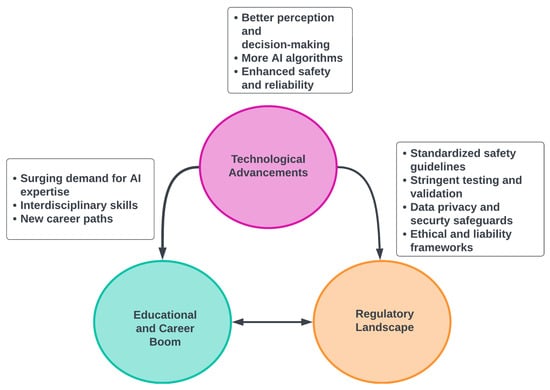
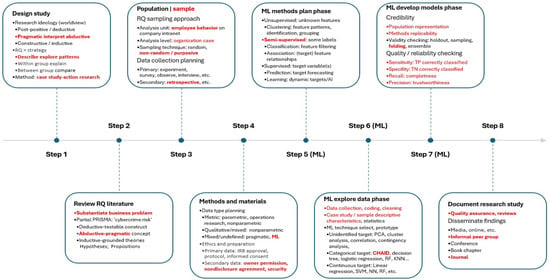
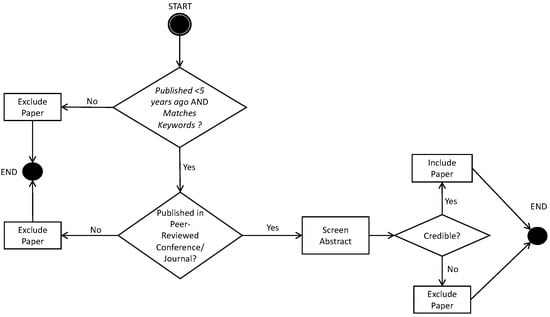
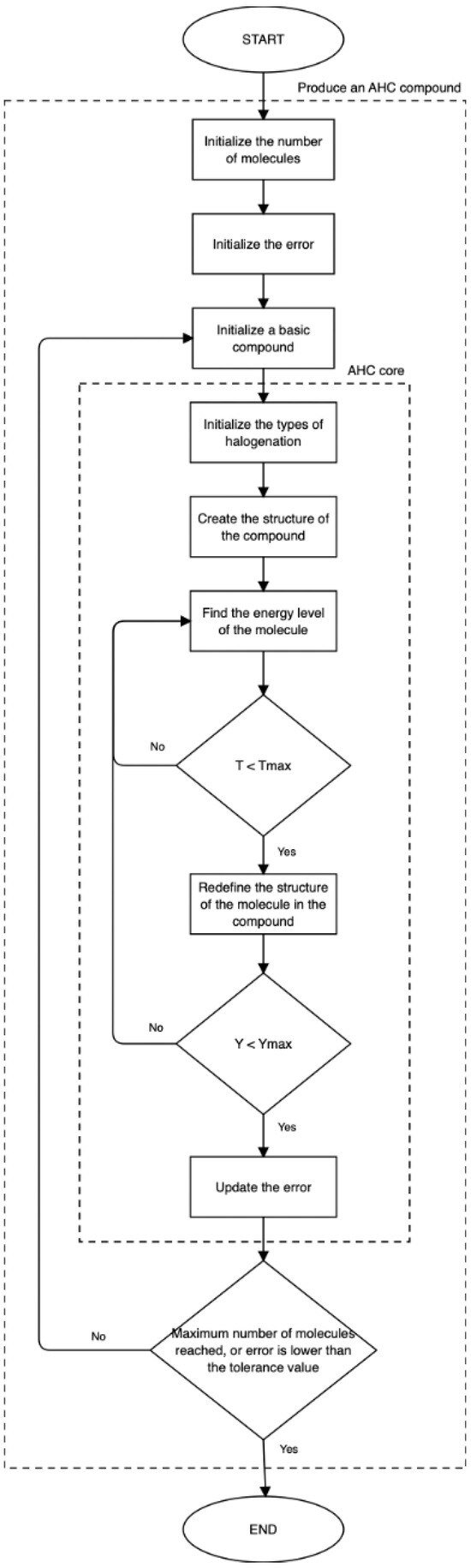
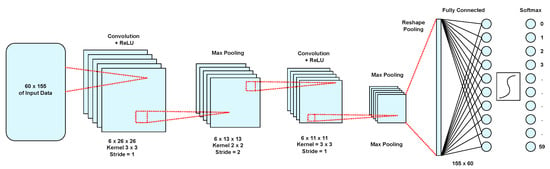
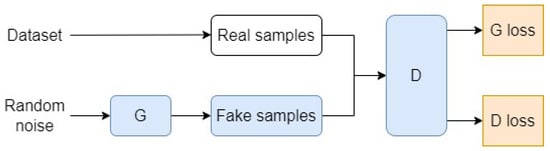
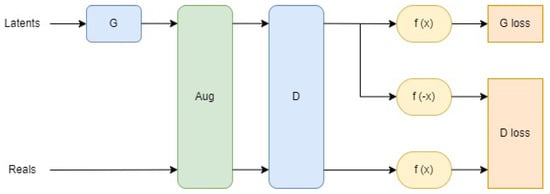
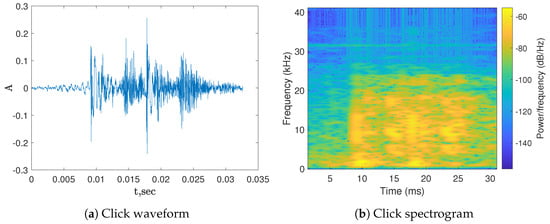
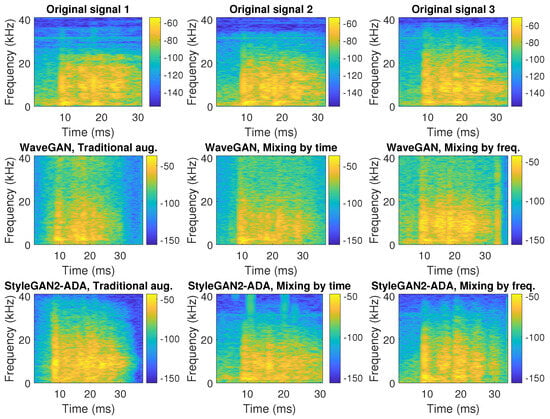
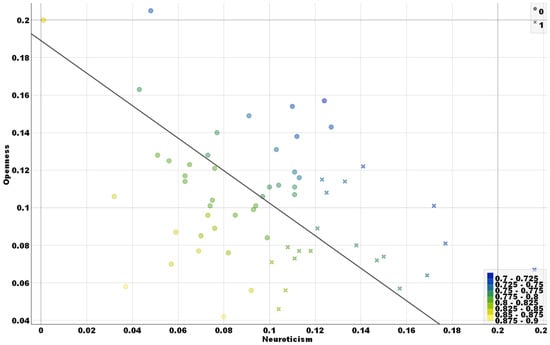
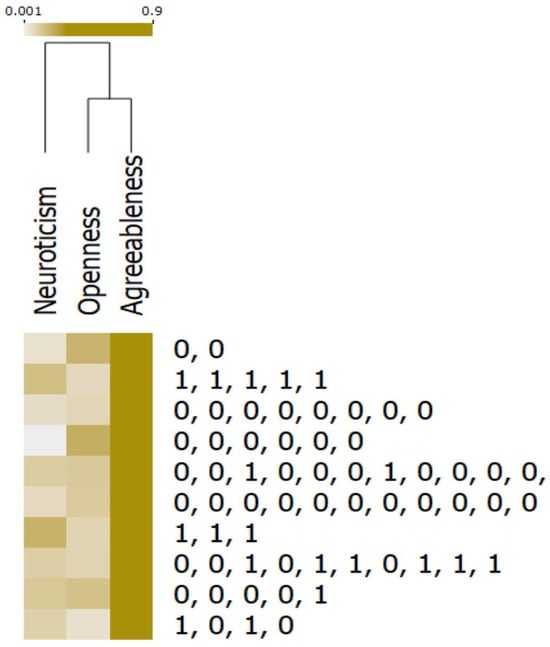
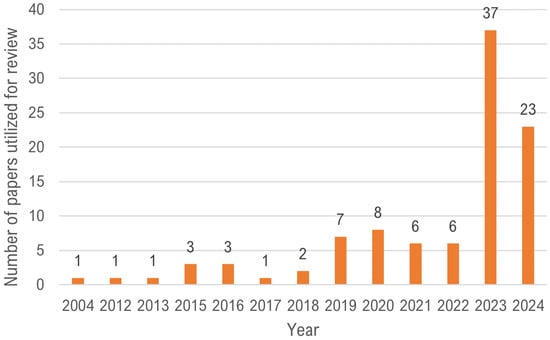
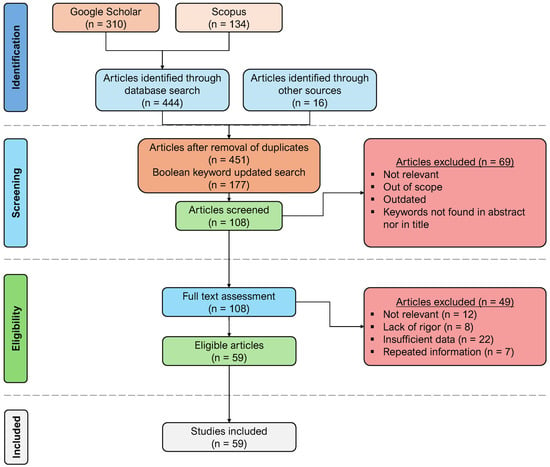
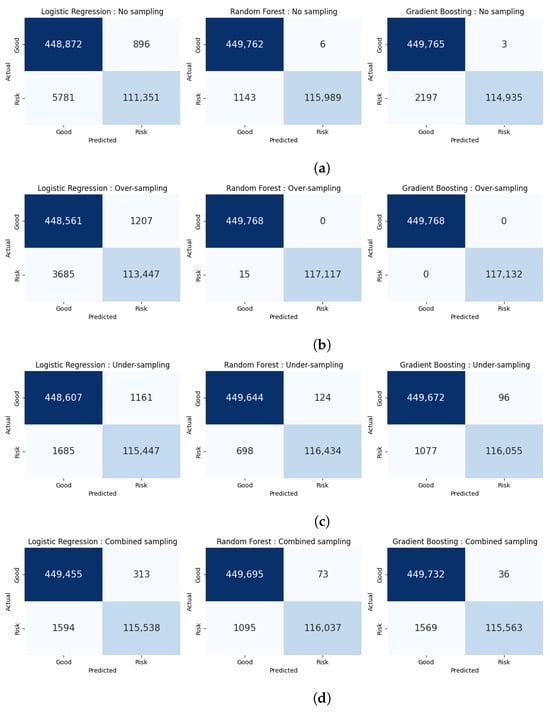
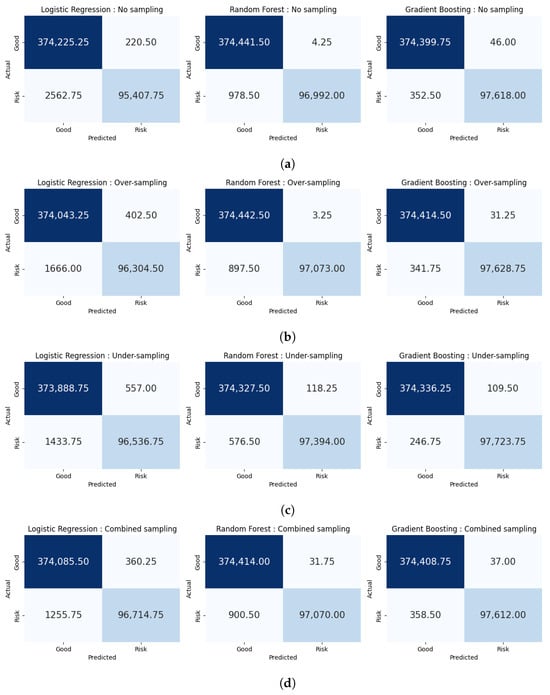
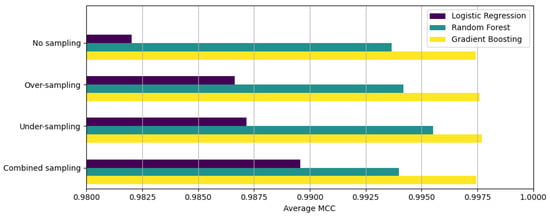
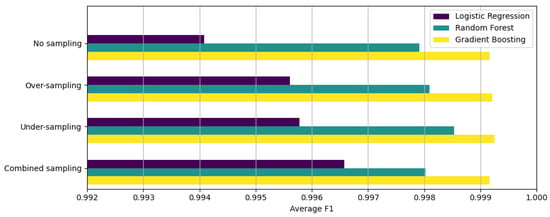
Figure 1






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
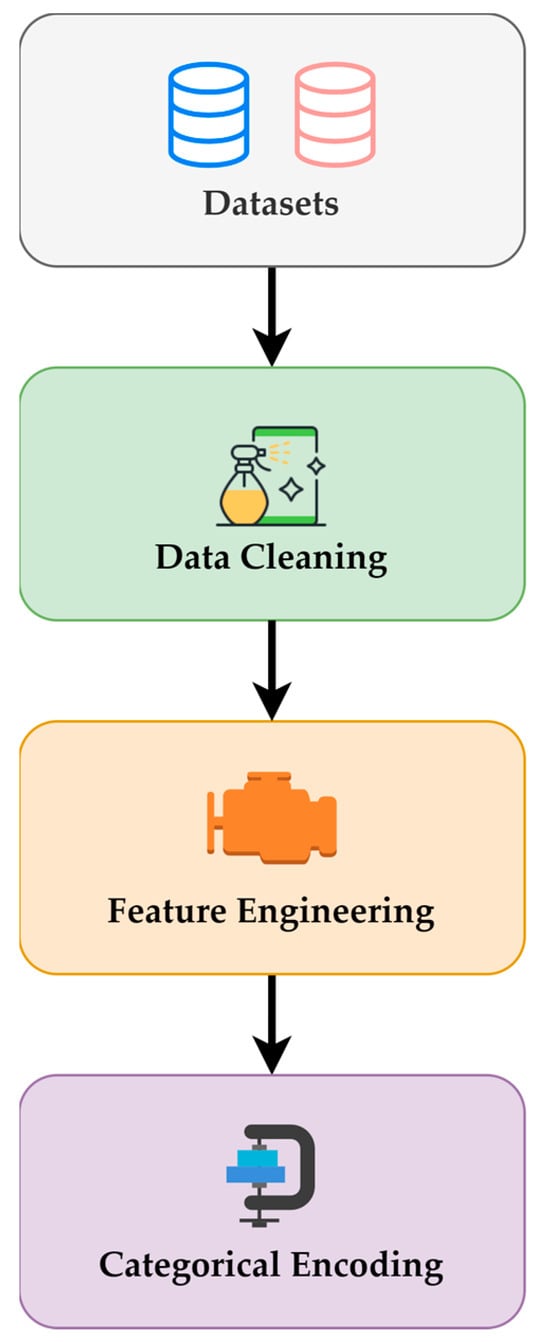{kind=link}
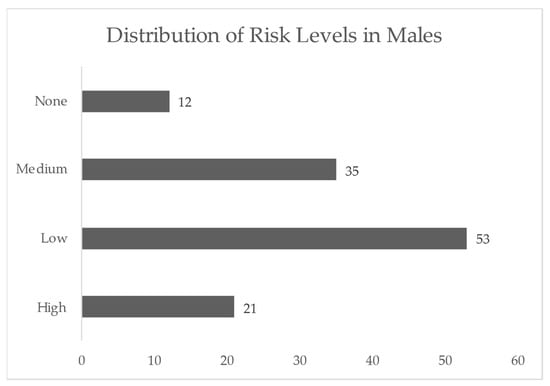{kind=link}
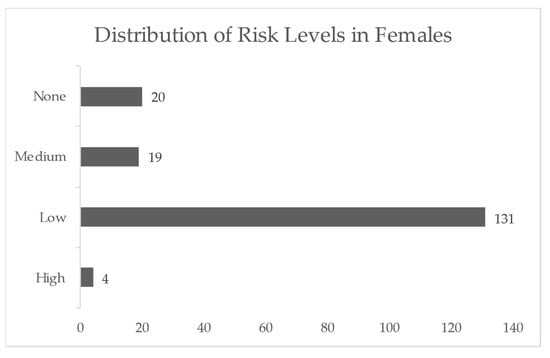{kind=link}
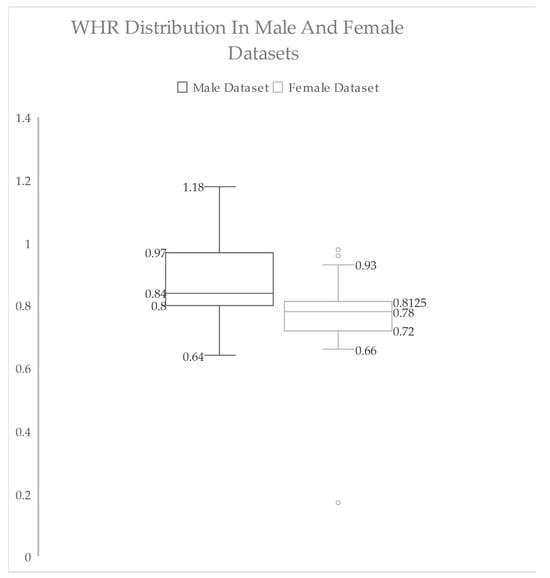{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
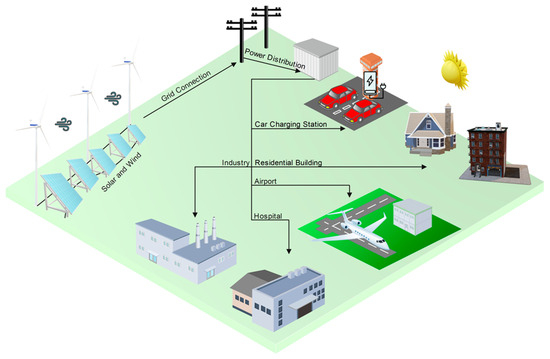{kind=link}
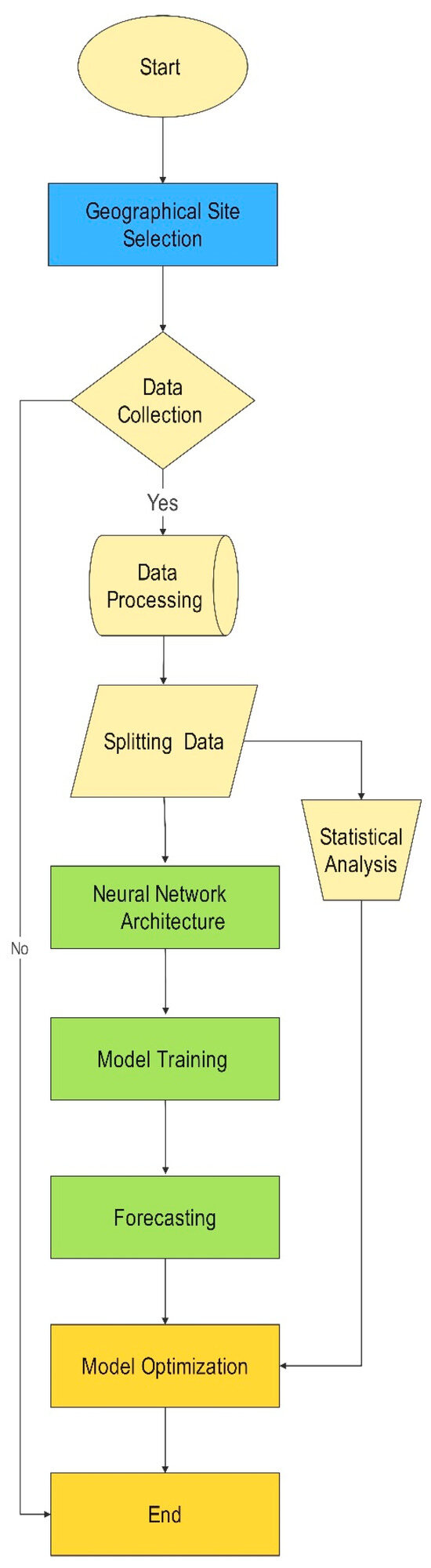{kind=link}
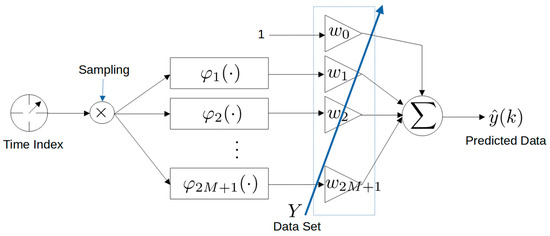{kind=link}
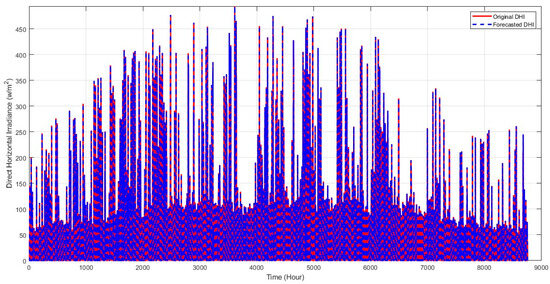{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
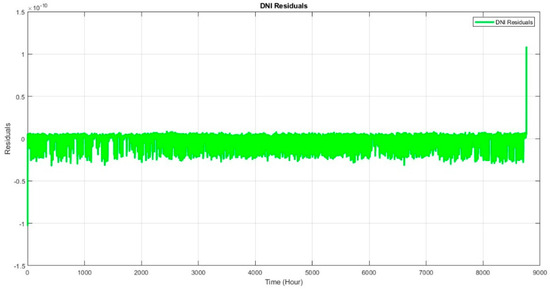{kind=link}
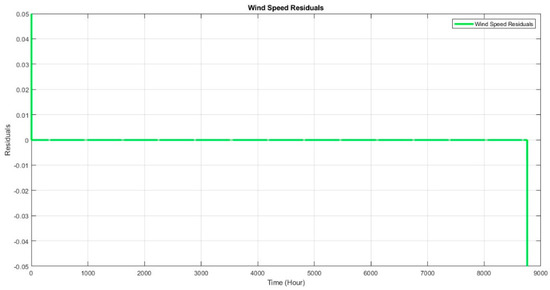{kind=link}
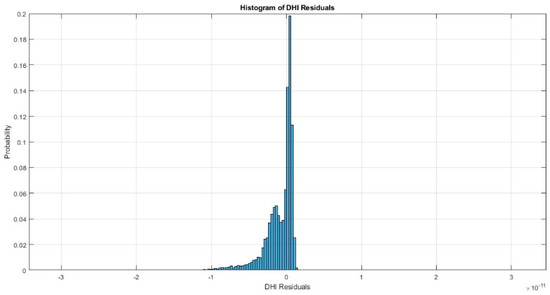{kind=link}
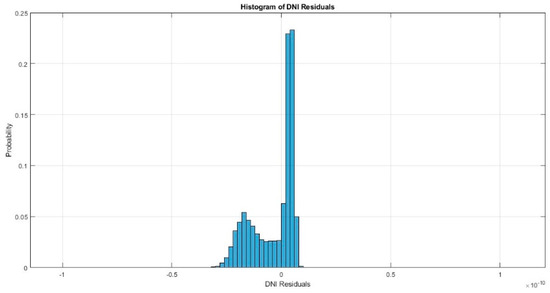{kind=link}
{kind=link}
{kind=link}