【我們為什麼挑選這篇文章】近年 AI 大舉應用,除了技術日越趨複雜,有時甚至需同時滿足機器學習、深度學習的需求,現有的硬體足以應付嗎?過去曾介紹一家半導體新創 Graphcore 針對 AI 技術開發出 IPU,改善 CPU、GPU 無法克服的困境。
除了解決運算效能的挑戰,AI 訓練上也會遇到記憶體容量與頻寬的問題。此篇文章為 Berkeley Artificial Intelligence Research(BAIR)專家 Amir Gholami 針對 AI 訓練上常遇到的「記憶體撞牆」問題提出三大解方。(責任編輯:何泰霖)
本文經 AI 新媒體量子位(公眾號 ID:QbitAI)授權轉載,轉載請連繫出處
作者:量子位
AI 訓練的運算量每年都在大幅增長,最近有研究指出,AI 訓練未來的瓶頸不是被運算能力限制,而是被 GPU 記憶體阻礙。
AI 加速器通常會簡化或刪除其他部分,以提高硬體的峰值浮點計算能力(FLOPS),但是在記憶體和通訊的問題上卻難以解決。
無論是在晶片內部、晶片之間,還是 AI 加速器之間的通訊,都已成為 AI 訓練的瓶頸。
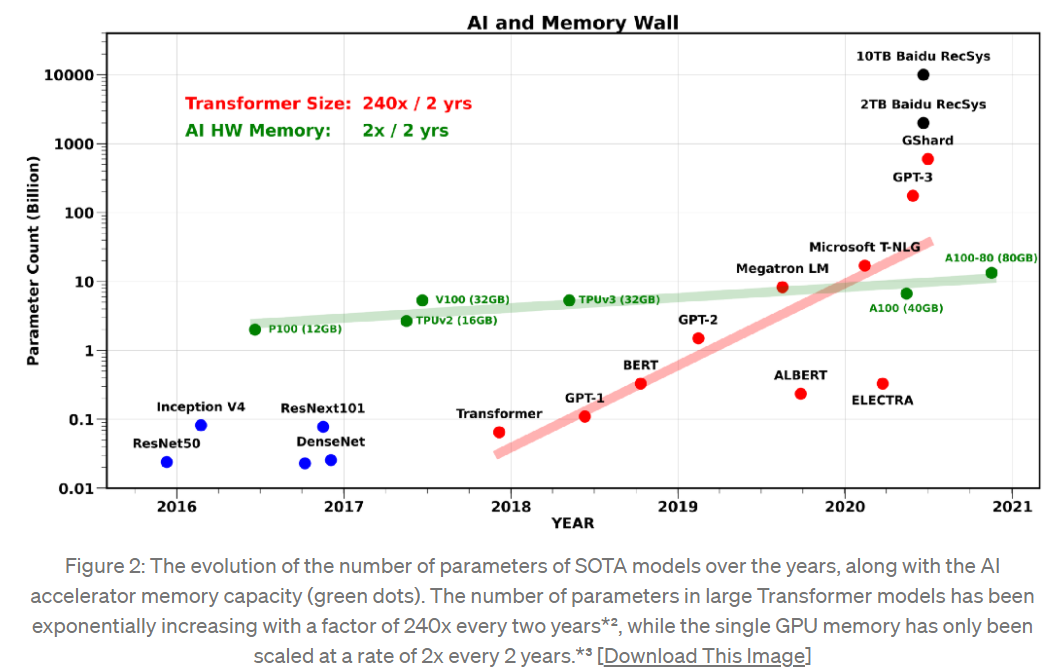
Transformer 模型中的參數數量(紅色)呈現出 2 年 240 倍的超指數增長,而單個GPU 記憶體(綠色)僅以每 2 年 2 倍的速度擴大。
訓練 AI 模型的記憶體需求,通常是參數數量的好幾倍。因為訓練過程中需要儲存中間激勵函數(intermediate activations),通常會比參數(不含嵌入)的數量增加 3-4 倍的記憶體。
於是,AI 訓練不可避免地遇上了「記憶體撞牆」(Memory Wall),記憶體撞牆不僅是記憶體容量問題,也包括記憶體傳輸的頻寬。
在很多情況下,數據傳輸的容量和速度,都沒有觸摸到記憶體牆。
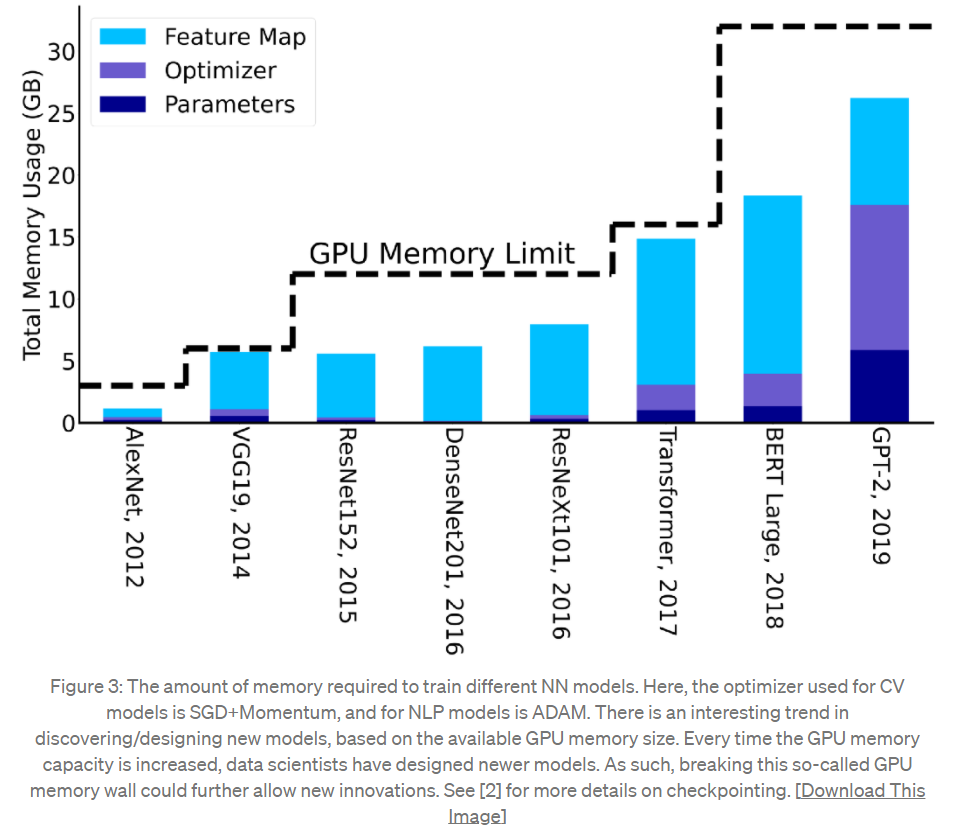
從上圖中可以看出,每當 GPU 記憶體容量增加時,開發人員就會設計出新模型;2019 年 GPT-2 所需的記憶體容量,已經是 2012 年 AlexNet 的 7 倍以上。
自 Google 團隊在 2017 年提出 Transformer,模型所需的記憶體容量開始大幅增長。
為何不靠擴充 GPU 解決?
那麼,為了擺脫單一硬體有限的記憶體容量和頻寬,是否可以使用分散式記憶體的方式,將訓練水平擴充到多個 AI 加速器呢?
事實上,這同樣也會面臨記憶體撞牆的問題,並且在神經網路加速器之間移動數據,比在單一晶片上移動數據還要慢且低效。
與單系統記憶體的情況類似,擴展頻寬的技術難題尚未被解決。水平擴充(scale-out)僅能在計算密集,且少量數據傳輸需求的情況下才能運作。
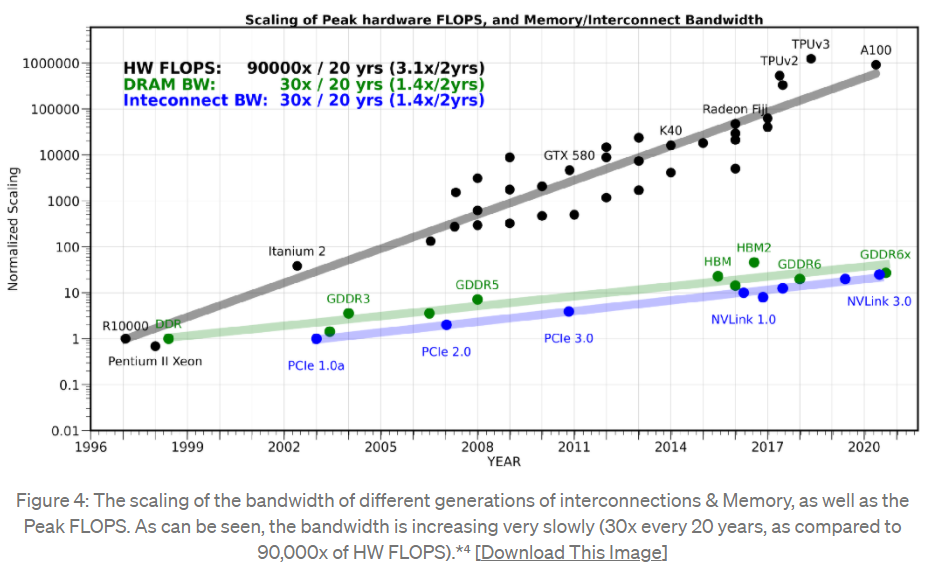
從上圖中可以看出,20 年之間,運算設備的峰值計算能力提高了 90,000 倍,雖然顯存從 DDR 發展到 GDDR6x ,且能夠用於顯卡、遊戲終端和高效能運算,接口標準也從 PCIe1.0a 升級到 NVLink3.0。
但是和運算能力的提高幅度相比,通訊頻寬的增長只有 30 倍,可說是非常緩慢。
由於運算能力和記憶體之間的差距越來越大,訓練更大的模型也會更加困難。
三大方法解決「記憶體撞牆」
怎麼樣解決記憶體限制的問題?作者 Amir Gholami 從三個方面進行了分析。
▪️新型態的訓練方法
訓練神經網路模型的一大挑戰,就是要進行暴力超參數調整。雖然可以透過二階隨機優化方法來實現,不過這種方法卻也增加 3-4 倍的記憶體佔用量,這一點仍需解決。
微軟的 Zero Redundancy Optimizer 方法(一種萬億級模型參數訓練方法),實現了在相同記憶體下,透過去除多餘的優化狀態變數,來訓練 8 倍大的模型。
另一方法是在傳遞過程中只儲存或檢查激勵函數的子集,而不保存所有的激勵函數,儘管會增加運算量,但能有效將記憶體減少 5 倍占用率,且僅增加 20% 的運算量。
此外,從單精度算法到半精度(FP16)算法的進展,使硬體運算能力提高了 10 倍以上,可以進一步研究適合 INT8 精讀訓練的優化算法。
微軟除了 ZeRO ,在 AI 訓練與應用上還有哪些好用神器?報名 4/7(三)線上雲端盛會-Data 與 AI 主題,了解如何透過單一平台將 SQL、 Spark 技術、 ETL/ELT 管線整合!
▪️2 種更高效的部署方法
部署最新的 SOTA 模型(例如:GPT-3)是一個很大的挑戰,在於推理上需要應用分散式記憶體部署。而這可以透過降低精度或刪除冗餘的參數,來壓縮這些模型,以進行推理。
雖然在訓練和推理上都可以透過降低精度進行運算,但在訓練上想要將精度降低至 FP16 以下仍相當困難。然而在現行技術上,推理的精度已經可以降低至 INT4, 且讓模型能在極小的誤差下,減少 8 倍的佔用空間和延遲 。
而在刪除冗餘參數的方法上,可能遇到準確率下降的致命性問題。不過,以目前的方法能夠刪減 30% 結構化稀疏性的神經元,以及 80% 非結構化稀疏性的神經元,以保證對準確性的影響最小。
▪️新型態的 AI 加速器
雖然很難同時提高記憶體頻寬和峰值浮點計算能力,但是其實可以犧牲峰值運算能力,以獲得更好的頻寬。
在頻寬受限的問題上, CPU 的性能要比 GPU 好得多,但是與 GPU 相比, CPU 的峰值計算能力要小一個數量級左右。
因此,可以研究一種在二者之間的另一種架構,實現更高效的快取。
研究數據可至下方參考資料連結查看。
(本文經 AI 新媒體量子位 授權轉載,並同意 TechOrange 編寫導讀與修訂標題,原文標題為 〈AI訓練的最大障礙不是算力,而是“內存牆”〉。首圖來源:Shutterstock)
你可能有興趣
AI 大規模應用的關鍵:ModelOps 打造「生生流轉」模型生態系
什麼是「IPU」?從西方半導體界唯一的獨角獸 Graphcore 開始講起吧!