有哪些AI生成视频的工具网站?
50 个回答


一、Moonvalley 介绍
Moonvalley,号称地表最强的 「AI 视频生成工具」,到底有多厉害?今天一起来看一下~


这是 Moonvalley 官网的介绍:
Moonvalley 是一个开创性的新型文本到视频的生成式 AI 模型。用简单的文本即可创建出惊人的电影和动画视频。
下面这些,都是通过 Moonvalley,用简单的文本描述生成的。






二、注册及基本使用
一)在 Discord 中加入 Moonvalley
Moonvalley 和 Midjourney 一样,都是搭在 Discord 上的。
所以第一步,注册/登录 Discord:https://discord.com
登录后,点击红框中的图标「探索可发现的服务器」


在搜索框中输入「Moonvalley」


点进去


点「加入 moonvalley」


然后会弹出 4 个问题,根据自己情况回答就好了,最后点「完成」。
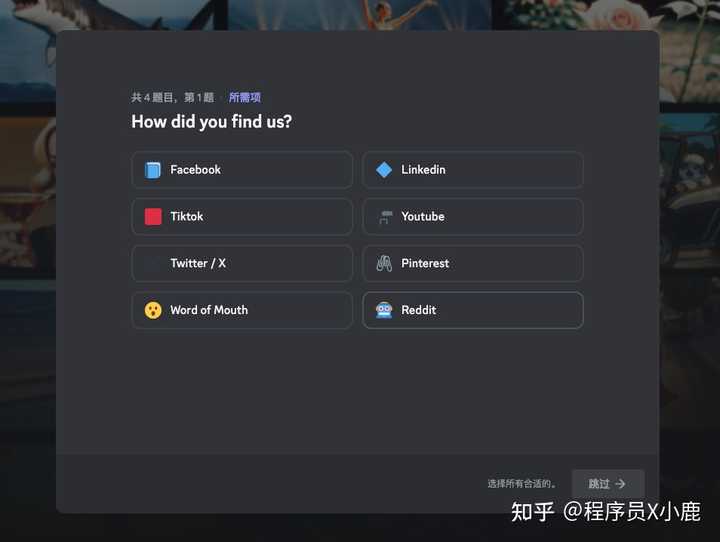









二)创建子分区(可选)
这是进入 Moonvalley 之后的界面。


左侧 1 区,是 Moonvalley 的 6 个公共会话区域,任意点击一个进去,就可以开始生成视频了。
但由于是公共区域,所以我们生成的视频,可以被所有人看到。同样,我们也可以看到其他人生成的视频。
为了防止我们生成的视频被刷走,一般会自己单独建立一个子区。
建立子区的方式:
选择公共区域的任何一个点进去,然后点击上图「2」所示的图标,再点「创建」。
输入「子区名称」并随意输入「一条消息」,就可以开始对话了。如下图所示。


三)生成视频
输入框中输入 /create,然后依次按照提示输入参数即可。
其中, prompt、style、duration 这三项是必选,negative 和 seed 是可选。




1、prompt
输入我们想生成视频的描述词(英文)。可以按 Midjourney 的提示词规则来写。
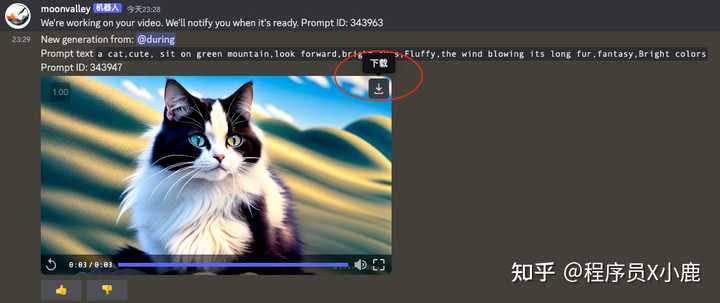
示例中的提示词供参考:a cat,cute, sit on green mountain,look forward,bright eyes,Fluffy,the wind blowing its long fur,fantasy,Bright colors
2、style
目前有这 5 种风格:
Comic book:连环漫画
Fantasy:幻想
Anime/Manga:动画
Realism:写实
3D Animation:3D 动画
不同的风格都可以试一试。
3、duration


Short:视频时长 1 秒,平均等待 2-5 分钟
Medium:视频时长 3 秒,平均等待 4-8 分钟
Long:视频时长 5 秒,平均等待 8-12 分钟
4、negative(可选)
负向提示词
5、seed(可选)
种子。和 Midjourney 和 Stable Diffusion 中的 seed 一个意思。
最后,觉得视频满意,就可以点「下载」了。

三、不同风格对比
下面是使用相同的提示词、不同的风格,生成的视频,大家可以感受一下。
连环漫画风
 AI视频生成工具Moonvalley-Comichttps://www.zhihu.com/video/1703836024608968705
AI视频生成工具Moonvalley-Comichttps://www.zhihu.com/video/1703836024608968705幻想风
 AI视频生成工具Moonvalley-幻想https://www.zhihu.com/video/1703836331250339840
AI视频生成工具Moonvalley-幻想https://www.zhihu.com/video/1703836331250339840动漫风
 AI视频生成工具Moonvalley-动漫https://www.zhihu.com/video/1703839198350618624
AI视频生成工具Moonvalley-动漫https://www.zhihu.com/video/1703839198350618624写实风
 AI视频生成工具Moonvalley-写实https://www.zhihu.com/video/1703836742153555968
AI视频生成工具Moonvalley-写实https://www.zhihu.com/video/17038367421535559683D 动画风
 AI视频生成工具Moonvalley-3Dhttps://www.zhihu.com/video/1703836815159648256
AI视频生成工具Moonvalley-3Dhttps://www.zhihu.com/video/1703836815159648256好了,以上就是今天想分享的内容~




AI 视频工具:我在AI视频生成领域的革命:Runway、Stable Video Diffusion与Pika三大神器全面解析这篇文章中提到的目前技术最好的三款视频工具。本文是根据最新消息,对AI视频工具的更新内容,关注我,实时了解AI工具及应用的最新资讯。
今天介绍的三款图片+动作生成视频项目都是国产项目,一是剪辑魔法师(剪辑魔法师 - 操作简单易上手的视频剪辑_视频编辑软件),第二阿里的Animate Anyone,第三是字节跳动的MagicAnimate。三个项目的技术路线是一样的,显然属于竞品。其中阿里的Animate Anyone没有公开代码,没有demo,只是发了一篇宣传文章;字节跳动的MagicAnimate公开了代码,也公开了demo,感兴趣去试一下。





两款声音+图片生成视频项目:一个是微软GAIA;一个是字节与阿里联手推出的VividTalk产品。也就是让图片说话的两个产品。




AI 视频工具,真的越来越精彩了。
一、剪辑魔法师
https://www.xunjieshipin.com/jianjimofashi?stzhcjl20240305-3315229245
首先介绍到“剪辑魔法师”,相比其它工具而言,其实它更像是一款剪辑工具并融合了AI技术,软件中搭载各种不同的美化功能和大量的剪辑模式,让我们可以进行搭配剪辑,但今天重点介绍的是它的AI核心功能——“文字转视频”;
整个生成过程只需要我们输入一个大致的视频主题,随后在正文部分可以对视频主题扩充具体的要求,例如需要出现的元素、场景、人物情绪等等,脚本确认完成后点击“生成视频”等待片刻即可得到视频内容;
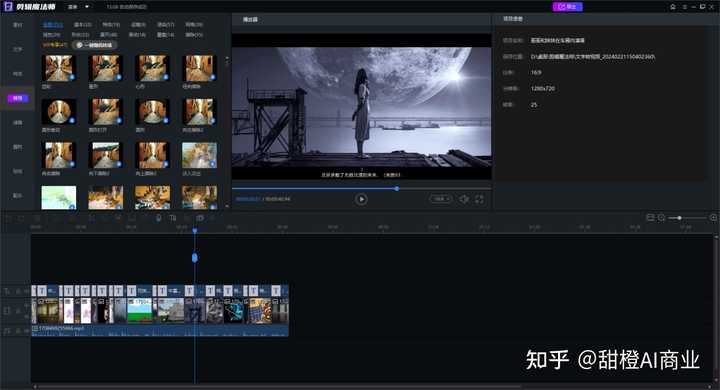

待视频生成完成后,我们便可以跟其它剪辑工具一样对其进行一番操作,手法基本如出一辙,素材修改、添加、编辑,各种震撼转场、特效、滤镜等等的润色,在这里都可以任我们挑选!众所周知,AI生成视频的效果全靠我们输入的关键词,只要掌握得当,视频效果绝对差不到哪里去!
 https://www.zhihu.com/video/1748353315539460096
https://www.zhihu.com/video/1748353315539460096剪辑魔法师项目地址:
https://www.xunjieshipin.com/jianjimofashi?stzhcjl20240305-3315229245
二、阿里的Animate Anyone
Animate Anyone是一个由阿里巴巴集团的研究人员开发的人物动画框架。这个框架能够将人物照片转化为由特定姿势序列控制的动画视频,同时保证人物外观的一致性和时间稳定性。它通过设计ReferenceNet来保留人物的精细外观特征,通过引入一个高效的Pose Guider来实现动作控制,以及通过有效的时间建模方法来确保视频帧之间的平滑过渡。
 https://www.zhihu.com/video/1715682692207685632
https://www.zhihu.com/video/1715682692207685632Animate Anyone的实现原理主要包括三个关键组件:ReferenceNet,Pose Guider和Temporal Layer。ReferenceNet是一个特征提取网络,用于提取参考图像中的空间细节。Pose Guider是一个轻量级的网络,用于将运动控制信号集成到去噪过程中。Temporal Layer则用于捕捉视频帧之间的时间依赖关系,确保角色运动的连续性。
 https://www.zhihu.com/video/1715683636559609856
https://www.zhihu.com/video/1715683636559609856在应用方面,Animate Anyone不仅可以应用于一般的字符动画,而且在特定的基准测试中,如时尚视频合成和人类舞蹈生成,也表现出色。此外,它还能处理各种类型的字符动画,包括全身人物图像、半身肖像、卡通角色和类人角色。这个框架有可能成为未来各种图像到视频应用的基础方法,激发更多创新和创造性的应用。
 https://www.zhihu.com/video/1715683555554963456
https://www.zhihu.com/video/1715683555554963456没有公开代码,没有demo,只是发表了一篇论文宣传,文章地址:https://humanaigc.github.io/animate-anyone/。
三、字节跳动的MagicAnimate
与阿里的Animate Anyone类似,MagicAnimate也是一种基于扩散模型的人类图像动画框架,旨在增强时间一致性,忠实地保留参考图像,并提高动画的真实感。该框架由视频扩散模型和外观编码器组成,分别用于时间建模和身份保护。为了支持长视频动画,研究者设计了一种简单的视频融合策略,以在推理过程中产生平滑的视频过渡。
 https://www.zhihu.com/video/1715685269163012097
https://www.zhihu.com/video/1715685269163012097实现原理:给定参考图像和目标DensePose运动序列,MagicAnimate使用视频扩散模型和外观编码器进行时间建模和身份保护。设计了一种简单的视频融合策略,以在推理过程中实现平滑的视频过渡。
 https://www.zhihu.com/video/1715685408484990976
https://www.zhihu.com/video/1715685408484990976应用:
1、未知领域动画:MagicAnimate可以为油画和电影角色等未知领域图像制作跑步或做瑜伽的动画。
2、结合T2I扩散模型:将MagicAnimate与DALLE-3生成的参考图像结合,制作各种动作的动画。
3、多人动画:根据给定的运动,为多个人制作动画。
与阿里的Animate Anyone相比,画面质量,人物一致性上、手部和面部动作 MagicAnimate 差一些,但MagicAnimate支持多人。
代码公开了,可以去魔改;demo也放出来了,去体验一下吧。
MagicAnimate网址:https://github.com/magic-research/magic-animate
Huggingface上的在线测试地址:MagicAnimate - a Hugging Face Space by zcxu-eric
四、微软GAIA
微软的GAIA(Generative AI for Avatar)框架,是一个用于零-shot(仅使用单张肖像照片)生成逼真说话头像的视频数据驱动方法。GAIA消除了领域先验,提高了生成头像的自然度和多样性。其实现原理主要包括两个阶段:1)将每帧画面分离为运动和外观表示;2)根据语音和参考肖像照片生成运动序列。为实现这一目标,研究者收集了一个包含16K独特演讲者的大型高质量说话头像数据集,用于训练模型。
GAIA框架包括两个主要部分:一个变分自编码器(VAE)和一个扩散模型。VAE负责从视频帧中提取运动和外观表示,通过训练学会重构输入帧。扩散模型则用于根据语音特征和参考帧生成运动序列。在推理阶段,扩散模型根据输入语音和目标头像照片生成运动序列,然后与照片结合,通过VAE解码器合成输出视频。
GAIA框架具有以下功能和模式:
1、视频驱动的说话头像生成(Video-driven Talking Avatar Generation):给定一个视频作为驱动,GAIA可以生成与输入视频具有相似外观和动态的说话头像。这可以用于跨视频角色替换。
 https://www.zhihu.com/video/1715689838802755584
https://www.zhihu.com/video/17156898388027555842、语音驱动的说话头像生成(Speech-driven Talking Avatar Generation):仅使用一张静态肖像图片和语音作为输入,GAIA可以生成与语音同步的逼真说话头像视频。
 https://www.zhihu.com/video/1715689880145731585
https://www.zhihu.com/video/17156898801457315853、可控姿态的说话头像生成(Pose-controllable Talking Avatar Generation):GAIA支持通过设置关键姿态(如头部姿势、眼睛注视方向等)来控制生成的说话头像视频。这意味着用户可以自定义角色的姿态,同时保持唇部动作与语音同步。
 https://www.zhihu.com/video/1715689931417186304
https://www.zhihu.com/video/17156899314171863044、全可控的说话头像生成(Fully Controllable Talking Avatar Generation):GAIA允许对生成的说话头像视频进行更细粒度的控制,例如分别控制角色的嘴巴、眼睛和其他面部特征。这为生成具有特定表情和动作的逼真视频提供了更大灵活性。
5、文本指导的头像生成(Text-instructed Avatar Generation):GAIA框架可以响应文本指令生成说话头像视频。例如,当给定一个静态肖像图片时,模型可以根据文本指令(如“微笑”或“向左看”)生成相应的视频。
以上功能太牛逼了,你做过的照片说话的项目,有比这个牛的吗?GAIA还未公开。
这是项目地址:https://microsoft.github.io/GAIA/
五、字节与阿里联手推出的VividTalk产品
VividTalk是一种新颖的通用框架,支持生成高质量、富有表现力的面部表情和自然头部姿势的说话头视频。该方法由两个串联的阶段组成:音频到网格生成(Audio-To-Mesh Generation)和网格到视频生成(Mesh-To-Video Generation)。在音频到网格生成阶段,该方法将音频映射到非刚性表情运动和刚性头部运动。对于表情运动,同时使用混合形状(blendshape)和顶点偏移(vertex offset)作为中间表示,以最大化模型的表现能力。对于刚性头部运动,提出了一种新颖的可学习头部姿势代码库(Learnable Head Pose Codebook)和两阶段训练机制。在网格到视频生成阶段,使用双分支运动VAE(Variational Auto-Encoder)和生成器将驱动的网格转换为密集的运动,并用于合成最终的视频。
 https://www.zhihu.com/video/1715693511116955648
https://www.zhihu.com/video/1715693511116955648VividTalk 支持对各种风格的面部图像进行动画处理,例如人类、现实主义和卡通。


使用VividTalk,您可以根据各种音频语言片段创建会说话的头像视频。VividTalk用最先进方法在口型同步、头部姿势自然度、身份保留和视频质量方面效果不错。
VividTalk项目地址:https://humanaigc.github.io/vivid-talk/
就这样了,关注我,跟踪AI技术的最新进展。