(本文經合作夥伴 若水 AI Blog 授權轉載,並同意 TechOrange 編寫導讀與修訂標題,原文標題為 〈2021台灣人工智慧小聚@若水:如何用少量AI數據,做好機器學習?〉。)
【我們為什麼挑選這篇文章】對於許多企業、團隊而言,在 AI專案剛起步時,常認為無法蒐集大量數據將是一大致命傷,然而近年在 ML 社群中出現一個新概念: Few shot learning,譯為「小樣本學習」或「小數據學習」,讓團隊透過現有的小量數據進行 AI 模型的訓練,連 AI 大神吳恩達也曾提及,小數據將成為 AI 下一步趨勢。
本篇文章重點摘錄台灣人工智慧學校工程師黃書璵,針對小樣本學習進行使用情境介紹,以及小樣本學習的 4 個實作方法與目標設定解析。(責任編輯:何泰霖)
作者:若水 Flow AI Blog 編輯團隊
2005 年左右,隨著大企業內部開始推動自動化、機器學習,不同種類的大數據因應而生。但擁有大數據,真的就等於擁有商業價值嗎?
數據量變大,意味著收集和訓練數據的成本越高,或許單筆數據的花費因而降低,但對一般企業來說,實在很難花費大量成本取得大數據。於是,小數據模型訓練(Few shot learning) 因此興起。
著名科技調查研究機構 Gartner 於 2020 年發布的《AI 技術成熟度曲線》報告就提到,有 2 件事值得我們關注,一個是小數據,另一個則是數據處理(annotation)。
今年 3 月,台灣人工智慧學校與若水合辦了疫後第一場小聚,報名人數突破百人。搭著 Gartner 的時代趨勢,由台灣人工智慧學校的工程師黃書璵,分享小量數據模型訓練以及數據處理的實戰經驗。(更多關於台灣人工智慧學校小聚)
什麼情況適用小數據學習(Few shot learning)?
當訓練數據量不足,或訓練數據不夠多元的時候,你可能會需要使用小數據學習(Few shot learning)技術。小數據學習的目標,是基於舊有的數據或模型做出調整,以利模型能針對未知的新任務快速學習。
一般來說,小數據學習適合的場景和優勢有三種。
第一,希望模型本身的學習方式比較接近人類,不需要太多數據就可以學到一些東西。例如中文字辨識的 AI 模型,如果已經可以掌握點、撇、勾等基本筆順的辨識原則,遇到新的圖資時,便可以用這些已知原則做類推判斷。
第二,遇到新種類的命題,希望用來改善稀有數據的建模。例如想要辨識剛出現的新型態電腦病毒,或者辨識居家高齡者是否跌倒,這些情境往往難以收集到大量的數據樣本。
第三,希望節省數據收集,還有標註的人力成本。例如有十萬筆數據,每筆都需要標註上百個特徵,此時便會希望能夠抓出其中具代表性的數據來做標註、學習,而剩下的部分即使未標註亦可以幫助機器學習。
小數據學習,如何著手開始?
如果你已經有了一批數據,加上有一個既有的模型,如何透過小數據,做出更好的模型擬合(Fitting)效果呢?解決方案就藏在數據和模型之中。
第一個方式很像數據的無性繁殖,也就是拿既有的少量數據,去生成更多不同特徵的數據。可以訓練一個 GAN 生成對抗網絡模型去做數據擴增,也可以訓練相似數據的合成。
例如,你有大量的老虎、狗和花豹的圖資,可是貓的圖資就只有三張。此時,可以先試著用比較相似的圖資算出 Correlation,找出相對的 pair,把老虎的圖資透過模型訓練,生成轉換成貓的圖資。接著,再去訓練狗到貓的轉換,還有花豹到貓的轉換等,貓的圖資就會越來越多。
第二個方式,在不改變數據情況下,可以嘗試改變模型的學習目標。例如,把舊模型的部分數據放到新模型內,讓新模型去學習怎麼比較出答案。
當圖片被轉換到高維度空間,透過距離函式便可算出距離,兩者之間數值越近就是同類,越遠就是不同類。例如兩隻貓在這個空間上的距離很近,但貓和老鼠距離就很遠。模型只要去學這兩張照片是不是同一種類即可。這個技術應用在人臉辨識上,可以去辨認出目標對象是不是本人,還是有別人假冒。
第三個方式,訓練一個新模型做多工學習,利用不同任務 (task)之間的共同性,增加模型的適用範圍。例如模型學會中文語法後,可以應用在日本語法上面,但套用不同的字彙。
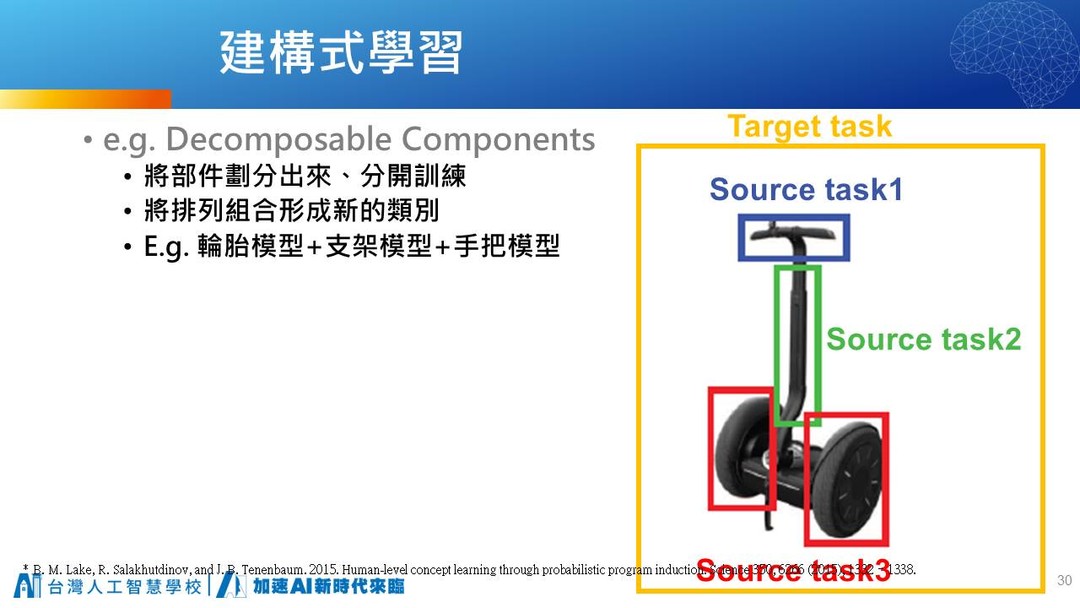
第四個方式,建構式的模型學習。先讓模型分別學習不同部分的特徵,最後再合併起來,學習如何整合判斷。
例如一台代步機,可能會有手把,長柄和輪子三種特徵。第一步,是先訓練出三個模型,分別是辨識手把,辨識長柄和辨識輪子的模型。接著,只要訓練這三者如何整合判斷,就可以得出答案。
網路上有很多的免費 dataset 或神經網路的論文可以下載,很容易做出厲害的人流監控 AI 在電腦 demo,模型安裝起來好像很厲害,也真的能偵測到人進出。
因為模型只能偵測出門口有人,卻無法告訴你相機跟門口距離多遠,門口在相機的哪裡,這些都不是神經網路可以幫你解決的,而是基礎工。
很多工程師跌進神經網路的世界裡面,卻忘了基礎工,也沒有意識到神經網路的能力,其實是來自於數據,最後什麼都解決不了。所以諸如若水這類 AI 數據服務公司在做的數據處理工作,其實很重要。
小數據學習訓練不起來?可能是模型目標問題
如果上述方式都不太能達到你想要的目的,或許可以回頭想想,是不是一開始設定給模型的學習核心方向,需要被調整?比較誇張的例子,就像你希望模型最終能學會辨識中文,但在建模型時卻設定成要辨識英文的字根字首。
此時,可能需要讓模型學習初始化,或者更新參數,以優化既有模型為導向做機器學習。
機器學習其實很像爬山,只不過目標不是往山峰爬,而是往谷底爬。在模型的虛擬多維度空間中,從某個隨機的起始點開始,透過機器一次次調整參數,在一連串山峰山谷的座標數字中反覆試錯,試圖逐步讓落點下降到谷底的地方,到達預設的最佳著陸點。這個過程稱為「梯度下降」。
調整參數時,雖然工程師會試著把舊的任務(task 1)參數應用在新的任務(task 2)上,但兩者的目標其實不相同,就像是有兩座山谷,所以怎麼抓梯度下降的起始點,才能降落到最佳著陸點,不會卡在半路上,會是一個需要反覆嘗試和評估的地方。
有一些方式,可以讓模型自動化的去找出最佳起始點,學習如何初始化。舉其中一種方式,叫做爬蟲(Reptile)。顧名思義,就像蜥蜴在爬行時,會分別伸出左右腳,身體再跟著逐步前進一樣,爬蟲會從某一個隨機的點開始更新參數,逐步地部分優化 task 1 和 task 2 的位置,找出最佳著陸點。
如果需要更多和小數據 AI 相關的資源,例如圖資、演算法、模型等,建議可以參考Pytorch learn2learn、Facebook higher、Amazon Xfer、或 Open AI GPT-3 等網站找尋你需要的工具。
(本文經合作夥伴 若水 AI Blog 授權轉載,並同意 TechOrange 編寫導讀與修訂標題,原文標題為 〈2021台灣人工智慧小聚@若水:如何用少量AI數據,做好機器學習?〉;首圖來源:freepik。)
你可能會有興趣
Google、軟銀都陣亡過!盤點 AI 專案失敗的 4 大原因
做機器學習,數據和模型哪個重要?吳恩達的「二八定律」告訴你真相
【神工智慧】台灣宮廟推出 AI 股價預測 APP,武財神加持買股有比較賺?