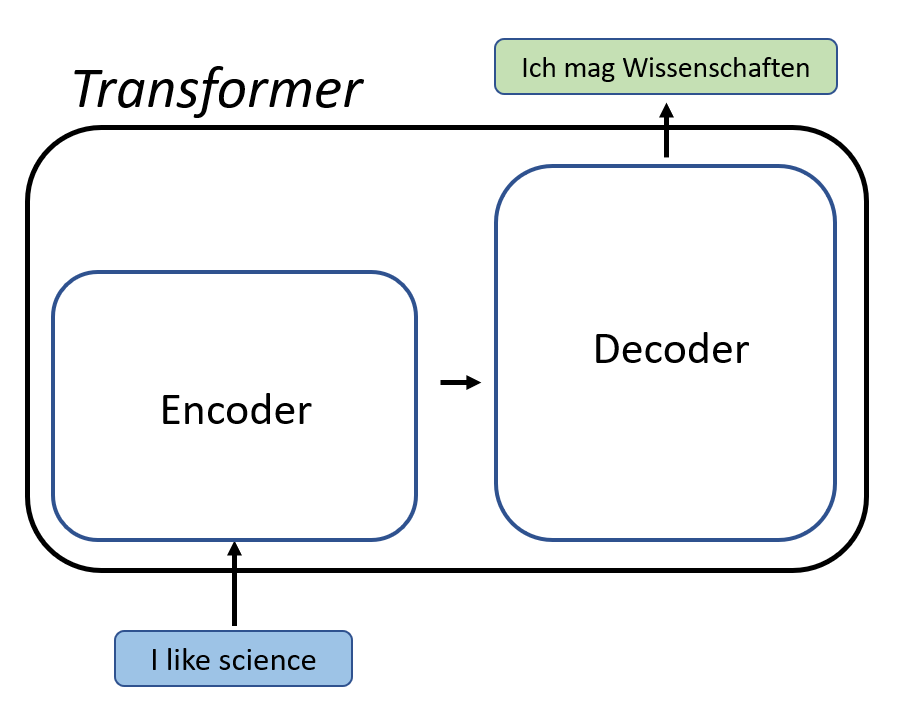
Machine Translation(Encoder-Decoder Model)!
A guide to understand and build a simple model which translates English To Hindi.

Contents-
1-Introduction.
2-Prior knowledge.
3-Architecture of Encoder-Decoder.
4-Understanding the Encoder part of the model.
5-Understanding the Decoder part of the model in Training Phase.
6-Understanding the Decoder part of the model in Test Phase.
7- Code
8-Results.
9-References.
Introduction-
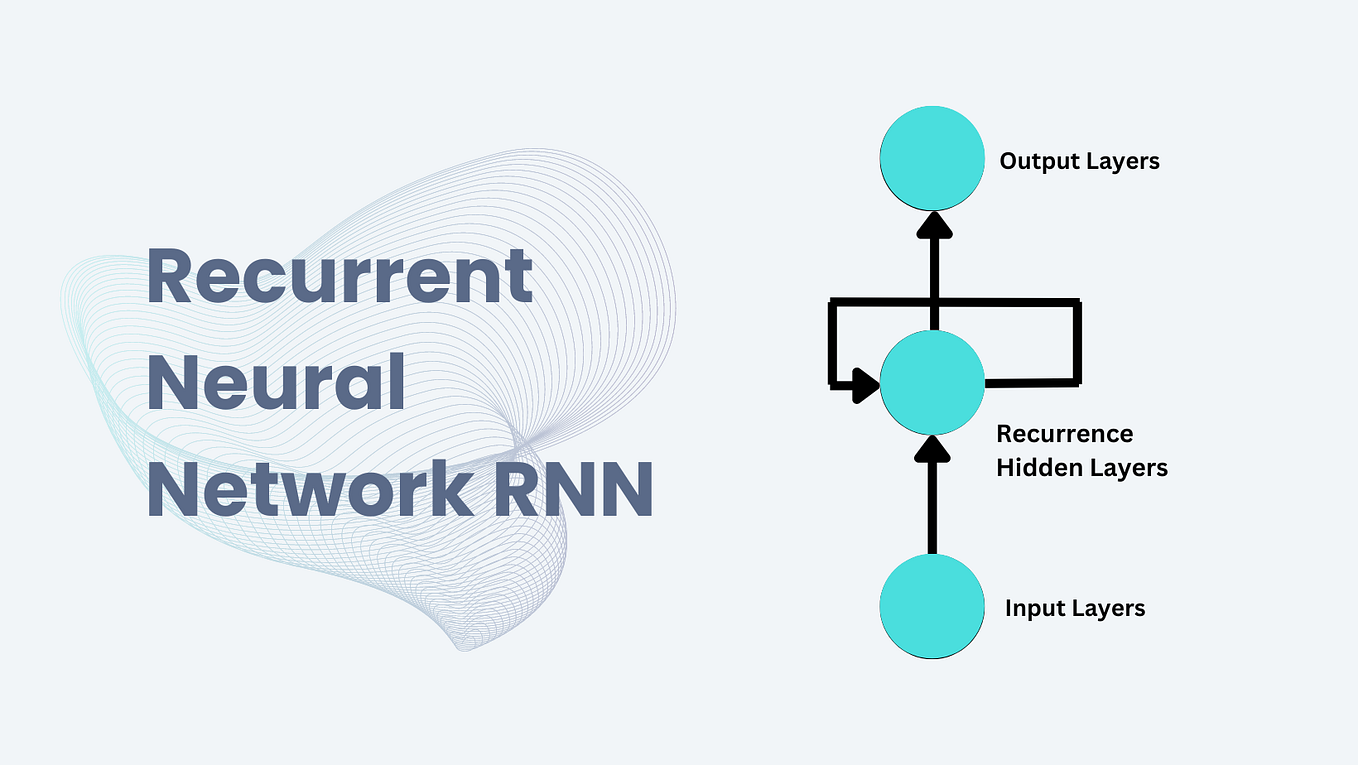
The encoder-decoder model is a way of using recurrent neural networks for sequence-to-sequence prediction problems.
It was initially developed for machine translation problems, although it has proven successful at related sequence-to-sequence prediction problems such as text summarization and question answering.
The approach involves two recurrent neural networks, one to encode the input sequence, called the encoder, and a second to decode the encoded input sequence into the target sequence called the decoder.
Following are some of the application of sequence to sequence models-
- Chatbots
- Machine Translation
- Text summary
- Image captioning
Prior Knowledge-
- Concepts of RNN / LSTM /GRU and also working of LSTM in Keras are required to understand this post.
The architecture of Encoder-Decoder -
The overall structure of sequence to sequence model(encoder-decoder) which is commonly used is as shown below-

It consists of 3 parts: encoder, intermediate vector and decoder.
Encoder-It accepts a single element of the input sequence at each time step, process it, collects information for that element and propagates it forward.
Intermediate vector- This is the final internal state produced from the encoder part of the model. It contains information about the entire input sequence to help the decoder make accurate predictions.
Decoder- given the entire sentence, it predicts an output at each time step.
Understanding the Encoder part of the model-
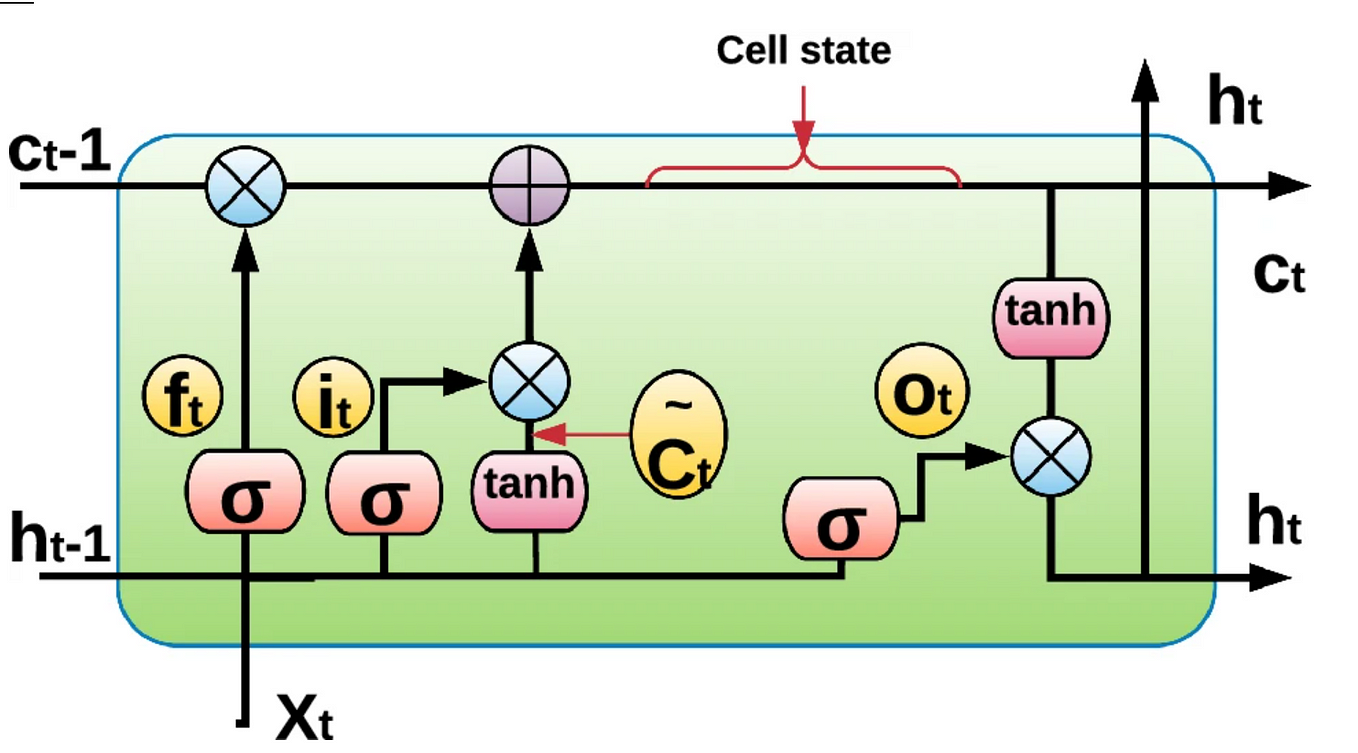
- The encoder is basically LSTM/GRU cell.
- An encoder takes the input sequence and encapsulates the information as the internal state vectors.
- Outputs of the encoder are rejected and only internal states are used.
Let’s understand how encoder part of the model works-

LSTM takes only one element at a time, so if the input sequence is of length m, then LSTM takes m time steps to read the entire sequence.
- Xt is the input at time step t.
- ht and ct are internal states at time step t of the LSTM and for GRU there is only one internal state ht.
- Yt is the output at time step t.
Let’s consider an example of English to Hindi translation-

Inputs of Encoder Xt-
Consider the English sentence- India is beautiful country. This sequence can be thought of as a sentence containing 4 words (India, is, beautiful, country). So here
X1 =’India’
X2=’is’
X3= ‘beautiful’
X4=’country’.
Therefore LSTM will read this sequence word by word in 4-time step as follows-

Here each Xt (each word) is represented as a vector using the word embedding, which converts each word into a vector of fixed length.
Now coming to internal states (ht,ct) -
- It learns what the LSTM has read until time step t. For e.g when t=2, it remembers that LSTM has read ‘India is ‘.
- The initial states ho, co(both are vectors) is initialized randomly or with zeroes.
- Remember the dimension of ho, co is same as the number of units in LSTM cell.
- The final state h4,c4 contains the crux of the entire input sequence India is beautiful country.
The output of encoder Yt-
Yt at each time steps is the predictions of the LSTM at each time step. In machine translation problems, we generate the outputs when we have read the entire input sequence. So Yt at each time step in the encoder is of no use so we discard it.
So summarizing the encoder part of the model-
The encoder will read the English sentence word by word and store the final internal states (known as an intermediate vector) of the LSTM generated after the last time step and since the output will be generated once the entire sequence is read, therefore outputs (Yt) of the Encoder at each time step are discarded.
Understanding the Decoder part of the model in the Training Phase-
The working of the decoder is different during the training and testing phase unlike the encoder part of the model which works in the same fashion in training and test phase.
Let’s understand the working of the decoder part during training phase-
Taking the running example of translating India is beautiful country to its Hindi counterpart, just like encoder, the decoder also generates the output sentence word by word.
So we want to generate the output — भारत खूबसूरत देश है
For the decoder to recognize the starting and end of the sequence, we will add START_ at the beginning of the output sequence and _END at the end of the output sequence.
So our Output sentence will be START_भारत खूबसूरत देश है _END
Let’s understand the working visually-

- The initial states (ho, co) of the decoder is set to the final states of the encoder. It can be thought of as that the decoder is trained to generate the output based on the information gathered by the encoder.
- Firstly, we input the START_ so that the decoder starts generating the next word. And after the last word in the Hindi sentence, we make the decoder learn to predict the _END.
- Here we use the teacher forcing technique where the input at each time step is actual output and not the predicted output from the last time step.
- At last, the loss is calculated on the predicted outputs from each time step and the errors are backpropagated through time to update the parameters of the model.
- The final states of the decoder are discarded as we got the output hence it is of no use.
Summarizing the encoder-decoder visually-

Understanding the Decoder part of the model in Test Phase-

Process of the Decoder in the test period-
- The initial states of the decoder are set to the final states of the encoder.
- LSTM in the decoder process single word at every time step.
- Input to the decoder always starts with the START_.
- The internal states generated after every time step is fed as the initial states of the next time step. for e.g At t=1, the internal states produced after inputting START_ is fed as the initial states at t=2.
- The output produced at each time step is fed as input in the next time step.
- We get to know about the end of the sequence when the decoder predicts the END_.
Code -
Now as we have understood how encoder-decoder model works, let’s see the code of translating English to Hindi.
- Load the data and see some of the data points.

- Second step is to pre-process the data to make it clean and easy to process.

- After preprocessing, add the START_ and _END to the Hindi sentence create the vocabulary of all the unique English and Hindi words and compute the vocabulary sizes and the length of the maximum sentence of both the English and Hindi language

- Next,we create 4 Python dictionaries to convert a given word into an integer index and vice-versa.

- Now we will split the data into train and test and define a function which generates the data for train and test in batches.

- Next step is to define the encoder-decoder architecture.


- Train the model for 100 epochs. After training it’s time for prediction on test data.
- So we will set up for test mode as follows-

- Finally, we will generate the output by defining the following function and later calling it.

Results-
- Result on train data- the below diagram shows that our model is performing decently on the train data.

- Result on test data- As shown below the obtained results is not very good on test data but it is okayish because firstly it is not a state of the art model, it is a very simple model and secondly, the dataset used here is too small to produce decent result.

References-
- https://arxiv.org/pdf/1409.3215.pdf
- https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
- https://www.kaggle.com/aiswaryaramachandran/english-to-hindi-neural-machine-translation
Thank you for reading till the end!!