A Movie Recommendation System in Python from Scratch
In this article, I explain simply how to build a movie recommendation system in Python!

After a short break from writing, we are back! Today we will speak about a very exciting topic: Recommendation Systems.
1. Introduction
Does the sentence “Since you liked/watched X, you might also like Y” ring a bell?
Well, it surely does!
A huge majority of people use on a daily basis services and websites like Amazon, YouTube, and Netflix. These services are excellent in suggesting recommendations based on the user’s preferences. For example, Netflix can accurately suggest interesting movies based on the user’s movie-watching history and liking. Amazon, is also excellent in recommending new items to the client according to the history of item purchasing or browsing (items watched/bought in the past). Finally, YouTube does the same job by recommending new videos that a watcher might like according to historical information and preferences (e.g. views, likes, etc).
Recommendation systems are tools and methods aiming at suggesting relevant items to users. As explained in the previous paragraph, they are widely used in various industries, such as retail, entertainment, and online services, to personalize the user experience by suggesting products, services, media content, and more.
2. Families recommendation systems
There are many types/families of recommendation systems but here we we only speak about the 2 most widely used without going deep in terms of their mathematical formulations.
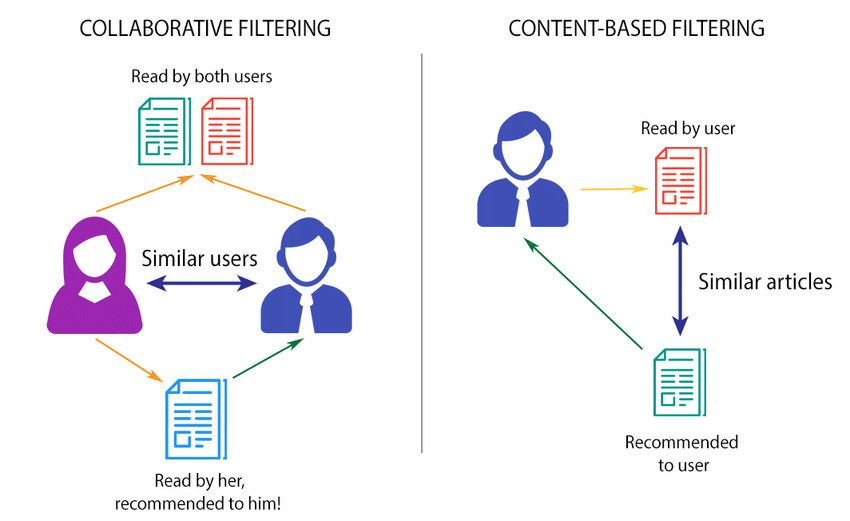
A) Content-Based Filtering
This approach recommends items similar to what a user has liked in the past, based on features associated with the items. The system analyzes the properties of items (like categories, tags, and descriptions) and uses this information to recommend new items with similar properties.
Example: In a movie recommendation system, if a user has liked action movies in the past then the system might recommend movies from the same genre.
B) Collaborative Filtering
This is one of the most commonly used approaches. Collaborative Filtering recommends items based on similarity measures between users and/or items. The basic assumption behind the algorithm is that users with similar interests have common preferences. It can be further divided into two sub-types User-based and Item-based [1]. Collaborative filtering uses a user-item matrix to generate recommendations. This matrix contains the values that indicate a user’s preference towards a given item.
Example: Let’s quickly see a toy example and how we can estimate the similarity between users according to the ratings. Below we have 3 users and 3 movies. The elements of the matrix are movie ratings from each user (NaN means to rating available).

To estimate the similarity of user A and B we can use the cosine similarity or distance. If you are confusing these 2 terms, have a look here. For 2 vectors A and B we define the Cosine Similarity as:

Let’s now estimate the similarity between user A and B.
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# build the user-item matrix
user_item = np.array([[5,4,1],[0, 3, 2],[2, 0, 3]])
row_index_user_A = 0
row_index_user_B = 1
# estimate the cosine similarity
cs = cosine_similarity([user_item[row_index_user_A]],[user_item[row_index_user_B]])[0][0]
print(f"The cosine similarity between user A and B according to their movie rating pattern is: {cs}")
# 0.593. Python Implementation
Now that we understand the main concepts around Recommendation systems let’s build a recommendation system that uses Collaborative Filtering.
We will use the movie rating dataset from Amazon! Let’s get started.
# Importing the libraries
import numpy as np
import pandas as pd
import sklearn
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.neighbors import NearestNeighbors
# rating dataset
ratings = pd.read_csv("https://s3-us-west-2.amazonaws.com/recommender-tutorial/ratings.csv")
# movie dataset
movies = pd.read_csv("https://s3-us-west-2.amazonaws.com/recommender-tutorial/movies.csv")
print(f"unique movieId's: {len(ratings['movieId'].unique())}")
print(f"unique users: {len(ratings['userId'].unique())}")The above prints:
unique movieId's: 9724
unique users: 610Let’s perform some EDA (exploratory data analysis) quickly to understand our data better before we build the recommendation system.
Question): What is the user rating frequency? How many ratings each user has provided?
# we will estimate the user rating counts
user_rating_counts = ratings["userId","rating"]].groupby(["userId"]).count().reset_index()
user_rating_counts.columns = ["userId", "n_ratings"]
user_rating_counts.head(3)Observation: We can see that we have users that provide a huge amount of ratings and others that provide very few ratings.
| userId | n_ratings |
|--------|-----------|
| 1 | 232 |
| 2 | 29 |
| 3 | 39 |
We can also plot the rating frequency distribution:
plt.hist(user_freq["n_ratings"])
plt.xlabel("n_ratings")
plt.ylabel("counts")
plt.title("User Rating Frequency")
sns.despine()
Observation: Impressive! There are users that have provided more than 2500 movie ratings!
The user-item matrix
Moving on to the core of the method, let’s now build the user-item matrix that will serve as the core of our recommendation system.
# pandas pivot function is great for this occasion here
X = pd.pivot(ratings, index='movieId', columns='userId', values='rating').fillna(0)
# mappers to be able to map an index of the matrix X back to a movie or user ID
user_index_to_id = {i:j for i,j in enumerate(X.columns)}
movie_index_to_id = {i:j for i,j in enumerate(X.index)}
user_id_to_index = {j:i for i,j in enumerate(X.columns)}
movie_id_to_index = {j:i for i,j in enumerate(X.index)}
print(X.shape)The shape of our matrix X is (9724, 610) since we have 9724 unique movies and 610 unique users in the dataset.
Next, we will build a function that takes as input a target movie ID and then it returns some movie recommendations according to the similarity of the target movie with all others. The core model here is a `NearestNeighbors` learner that is fitted on the user-item matrix X. The samples are the movies and the features are the users’ ratings according to how we have structured the matrix X.
Note: This is a form of item-based collaborative filtering since similarities between items are calculated based on the ratings given to those items by the users. We will use the cosine distance as a metric, and we will request k movie recommendations. Code inspired by https://www.kaggle.com/code/luubaoyen/movie-recommendation-with-models.
def recommendation_movie_system(target_movie_id, k, metric='cosine'):
# we will store the recommendations in a list named `recommendations`
recommendations = []
# Map movie_id to movie index to slice matrix X
movie_ind = movie_id_to_index[target_movie_id] # this is an index now
movie_vec = X.values[movie_ind].reshape(1,-1) # this is a vector of shape [1, 610] for the given movie id
# refine the Uunsupervised learner for implementing neighbor searches
knn = NearestNeighbors(n_neighbors=k+1, metric=metric).fit(X)
_ , neigh_ind = knn.kneighbors(movie_vec)
recommendations = [movie_index_to_id[neigh_ind[0][i]] for i in range(k+1)]
# we will pop the first element as this is the same item as the target_movie_id
recommendations.pop(0)
return recommendationsIn summary, the code is implementing item-based collaborative filtering to recommend similar movies based on the ratings given by users.
Let’s use this function now to see how it works. We will use Toy Story (1995) movie as the target movie to get 5 other recommendations.
# Target movie ID in order to find similar movies
target_movie_id = 1
get_n_recommendations = 5
similar_movie_ids = recommendation_movie_system(target_movie_id, k=get_n_recommendations)We will convert these now to movie titles!
# mapper of movie id to movie title
movie_titles = dict(zip(movies.movieId, movies.title))
# extract the movie titles of the estimated recommendations
pritn([movie_titles[i] for i in similar_movie_ids])['Toy Story 2 (1999)',
'Jurassic Park (1993)',
'Independence Day (a.k.a. ID4) (1996)',
'Star Wars: Episode IV - A New Hope (1977)',
'Forrest Gump (1994)']Summary: We used as a target movie the “Toy Story (1995)” and we got the above 5 recommendations like “Toy Story 2 (1999)” and “Jurassic Park (1993)”.
Nice! They are like “Toy Story 1 (1992)”. It makes a lot of sense, no?
5. Recommendations according to a specific user’s previous ratings
As a final step, let’s now use as a target a specific user rather that a specific movie and get some recommendations for the specific users. This is now user-based collaborative filtering.
We will find the movie with the max rating assigned by this target user and then use the approach used in the previous section to get our 5 recommendations.
We will start with the movie with the max rating by the specific user and find similar movies.
def recommend_for_user(target_user_id, movie_titles, k=get_n_recommendations):
# get the ratings of this target user
user_ratings = ratings.query(' userId == @target_user_id ')
# find the movie id with max rating from this user. If many, get the first found
max_rated_by_target_user = user_ratings.query(' rating == rating.max() ').iloc[0]
target_movie_id = max_rated_by_target_user['movieId']
max_movie_title = movie_titles[target_movie_id]
# get recommendations based on the target_movie_id
similar_movie_ids = recommendation_movie_system(target_movie_id, X, k=k)
print(f"Since you liked a lot {max_movie_title}, you might also like:")
print(f"\n")
return max_movie_id, max_movie_title, similar_movie_idsLet’s target the user with userId = 150and get 5 movie recommendations for this user.
# our target user
target_user_id = 150
get_n_recommendations = 5
# run the recommendation system for this user
_ ,_ ,_ = recommend_for_user(target_user_id, X, movie_titles, k=get_n_recommendations)This prints:Since you liked a lot Twelve Monkeys (a.k.a. 12 Monkeys) (1995), you might also like:
Pulp Fiction (1994)
Terminator 2: Judgment Day (1991)
Independence Day (a.k.a. ID4) (1996)
Seven (a.k.a. Se7en) (1995)
Fargo (1996)
Great! We can now target a specific user and according to his preferences and get some tailored movie recommendations.
The full code can be found here: https://github.com/seralouk/RecommendationSystem
6. Conclusions
Recommendation Systems are very powerful tools and can be found everywhere nowadays. The three main types of Recommendation Systems are Collaborative, Content-based and Hybrid. Through the utilization of these 3 main methods these systems are able to offer customized recommendations to consumers for content, movies, or items.
These systems use sophisticated methods such as closest neighbors (covered in this tutorial) and matrix factorization (not covered here) to find hidden patterns in item attributes and user behavior.
That’s all! Hope you liked this article!
If you liked and found this article useful, follow me and make sure you subscribe to my mailing list and become a member:
- My mailing list in just 5 seconds: https://seralouk.medium.com/subscribe
- Become a member and support me: https://seralouk.medium.com/membership
Any questions? Post them as a comment and I will reply as soon as possible.