多个因素决定一个结果,如何分析每个因素对结果的影响程度?
7 个回答

- 如果是线性回归分析可以使用标准化回归系数进行分析。
在线性回归里,如果自变量对因变量有显著性影响,但是研究者还想进一步查看谁的影响大,此时可以查看标准化回归系数。标准化回归系数值大于0时正向影响,该值越大说明影响越大。标准化回归系数值小于0时负向影响,该值越小说明影响越大。
举个例子进行说明(文末有操作数据可以进行分析)。
一、案例与数据
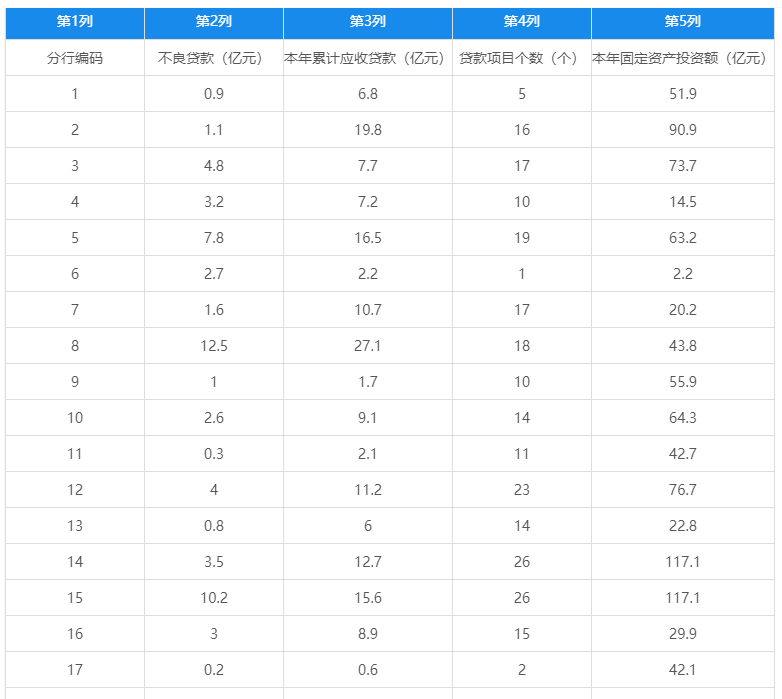
一家大型商业银行在多地区设有分行,其业务主要是进行基础设施建设,国家重点项目建设,固定资产投资等项目的贷款。近年来,该银行的贷款额平稳增长,但不良贷款额也有较大比例的提高,这给银行业务的发展带来较大压力。为弄清楚不良贷款形成的原因,管理者希望利用银行业务的有关数据做一些统计分析,想要知道“本年累积应收贷款”、 “贷款项目个数”以及“本年固定资产投资额”对“不良贷款”是否有影响,如果有影响,它们之间谁的影响更大?部分数据如下(数据虚构无实际意义):

二、分析问题
管理者想要研究“本年累积应收贷款”、 “贷款项目个数”以及“本年固定资产投资额”对“不良贷款”是否有影响,如果有影响,分析影响程度,其中以“不良贷款”作为因变量, “本年累积应收贷款”、 “贷款项目个数”以及“本年固定资产投资额”作为自变量研究影响关系,可以考虑线性回归、方差分析等,由于自变量和因变量均为定量变量,所以选择线性回归进行分析。
三、初探基本关系
在进行线性回归之前,首先需要对数据进行查看基本关系,然后进行检验数据是否满足参与线性回归分析的基本条件。基本关系包括数据的相关关系以及共线性的查看。
1.相关关系
在回归分析前一般需要做相关分析,因为有了相关关系,才可能有回归影响关系;如果没有相关关系,是不应该有回归影响关系的。所以进行初步查看,结果如下:
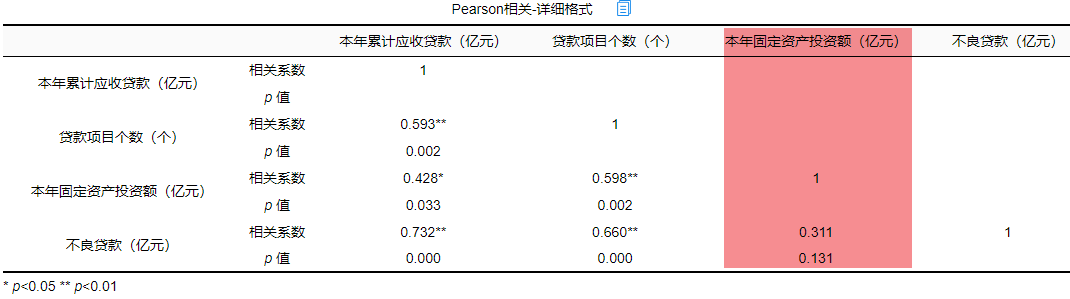

将“本年累计应收贷款”、“贷款项目个数”、“本年固定资产投资额”以及“不良贷款”之间进行两两相关分析。除了“本年固定资产投资额”和“不良贷款”之间p值大于0.05,其余两两之间分析p值均小于0.05,所以不良贷款与本年固定资产投资额没有相关关系,也即说明进行回归分析时不放入本年固定资产投资额。接下来查看数据是否存在共线性。
2.共线性
共线性是指线性回归模型中的解释变量之间由于存在精确相关关系或高度相关关系(例如相关系数大于0.8)而使模型估计失真或难以估计准确。共线性的存在可能会降低估计的精准度,并且稳定性也会降低。无法判断单独变量的影响。回归方程的标准误差增大。变量显著性可能会失去意义等等。所以在分析前需要对共线性问题进行检查。
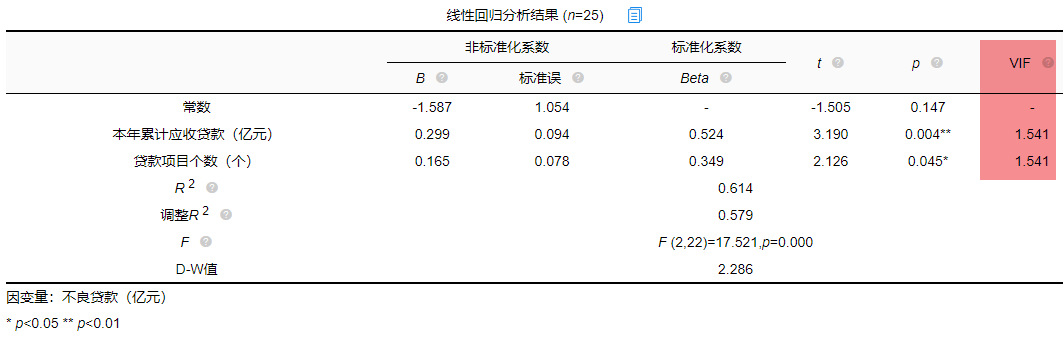

一般VIF值大于10(严格来说大于5),存在共线性问题,从分析结果中可以看到VIF值小于10,所以不存在共线性,如果存在共线性问题则不能使用线性回归,可以使用岭回归、Lasso回归等进行分析。
四、前提条件检验
大多数方法进行分析时,都有假设或者分析的前提条件,线性回归也不例外。线性回归分析的前提条件概括为四个:线性、独立、正态和方差齐性,接下来一一检验。
1.线性
一般检验数据之间的线性关系,是为了考察因变量随自变量值变化的情况,可以做相关分析从侧面进行说明或者利用散点图进行说明,散点图更加直观,所以本次选择散点图进行描述(SPSSAU可视化→散点图)。结果如下:
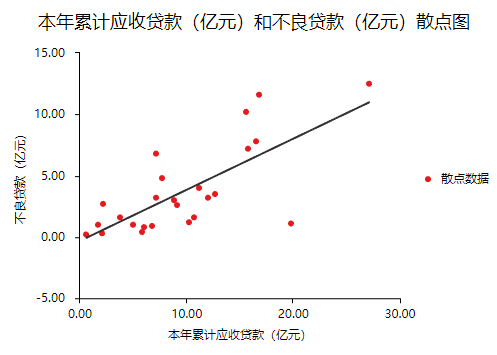

以“不良贷款(亿元)”作为Y轴,“本年累计应收贷款(亿元)”作为X轴建立散点图,发现“不良贷款(亿元)”与“本年累计应收贷款(亿元)”为线性关系。以同样的方法对“贷款项目个数”和“不良贷款”建立散点图,也存在线性关系。
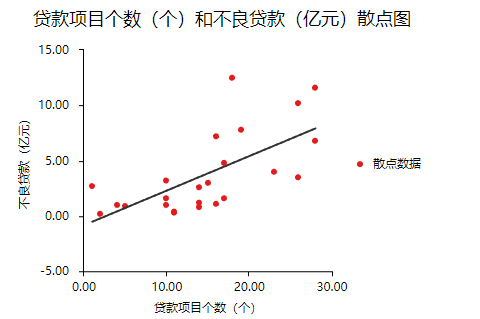

如果不呈现线性关系可以尝试通过变量变换进行修正,常用的变量变换的方法有对数变换、倒数变换等等。
2.独立
独立是指残差是独立的。特别是,时间序列数据中的连续残差之间没有相关性。可以查看DW值,一般在DW值在2附近(比如1.7-2.3之间),则说明没有自相关性,模型构建良好,反之若DW值明显偏离2,则说明具有自相关性,模型构建较差(一般如果不是时间序列数据也可以不用过度关注)。尝试构建回归分析模型发现DW值为2.286。
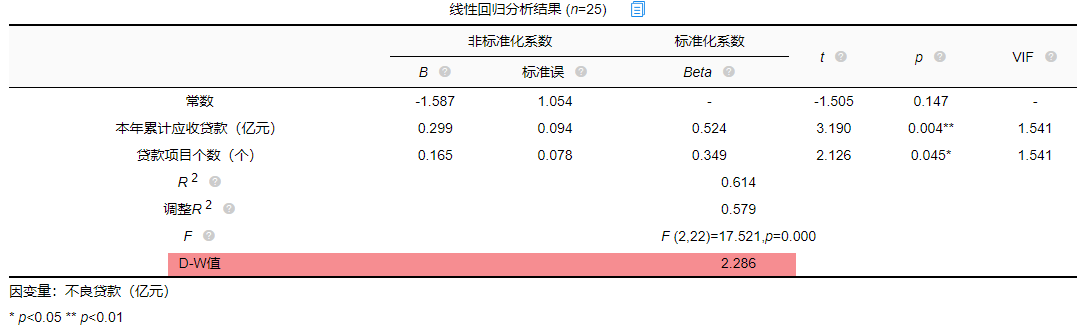

从结果中可以看出DW值为2.286在2的附近,表示模型构建良好。接下来进行验证“正态”。
3.正态
正态表示残差服从正态分布。其方差σ2 = var (ei)反映了回归模型的精度,一般 σ 越小,用所得到回归模型预测y的精确度越高。建立回归分析模型得到残差与预测值,利用残差绘制直方图查看残差是否满足正态分布,结果如下:
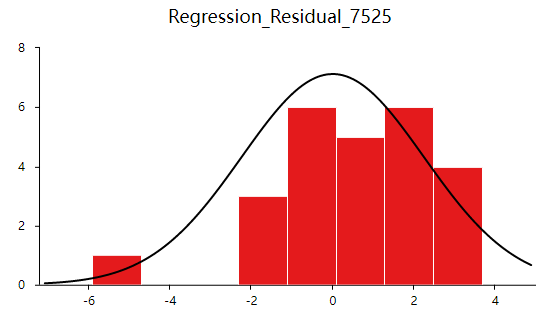

如果直方图呈现‘中间高,两边低,左右基本对称的 “钟形图”则基本服从正态分析,但是数据量过少等也可能影响结果导致很难呈现出标准的正态分布,如果是这种情况如果看见‘钟形’也可以可以接受的。上图可以看出,数据呈现的分布并不对称,但是也出现近似‘钟形’曲线,所以也可以接受。残差满足正态分布,接下来验证方差齐性。
4.方差齐性
方差齐性是指残差的大小不随所有变量取值水平的改变而改变,即方差齐性。那么如何进行呢?首先对残差和预测值进行标准化,与标准化残差为Y轴,标准化预测值为X轴绘制散点图,如果所有点均匀分布在直线Y=0的两侧,则可以认为是方差齐性,结果如下:
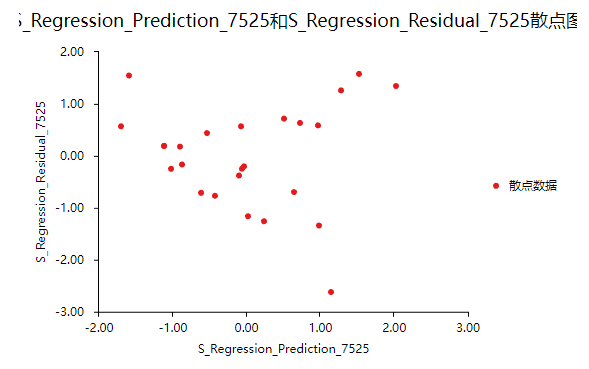

从散点图可以发现数据大致均匀分布在Y=0的两侧,所以可认为是方差齐性,综上,数据满足回归分析的前提假设。可以进行线性回归。
五、回归分析
由上述分析与检验最后以“不良贷款(亿元)”为因变量,“本年累积应收贷款(亿元)”和“贷款项目个数(个)”为自变量构建线性回归模型。分析将从模型效果以及模型结果两部分进行说明。
1.模型效果说明
模型效果说明包括F检验以及模型拟合优度。
F检验


F检验主要是观测被解释变量的线性关系是否显著,上表可以看出,进行回归方程的显著性检验时,统计量F=17.521,对应的p值小于0.05,所以说明被解释变量的线性关系是显著的,可以建立模型。那么模型的拟合优度又是怎么样的?接下来进行说明。
拟合优度


模型拟合优度一般查看R方值(决定系数,模型拟合指标),如果R方为0.3代表自变量可以解释因变量30%的变化原因,一般越接近1说明拟合越好,但是很多研究中不会过多关注其大小,原因在于多数时候我们更在乎X对于Y是否有影响关系。从上表可以看出,模型R方值为0.614,调整R方为0.579。调整R方也是模型拟合指标。当x个数较多是调整R²比R²更为准确。
意味着“本年累积应收贷款(亿元)”和“贷款项目个数(个)”可以解释“不良贷款”61.4%变化原因。可见,模型拟合优度良好,说明被解释变量可以被模型大部分解释。接下来对模型结果进行解释。
2.模型结果解释
管理者想要知道“本年累积应收贷款”、 “贷款项目个数”以及“本年固定资产投资额”对“不良贷款”是否有影响,如果有影响,它们之间谁的影响更大?因为前面的相关分析中得到了“本年固定资产投资额”与“不良贷款”之间没有相关关系,一般情况下没有相关关系是没有影响关系的,所以分析“本年累积应收贷款”、 “贷款项目个数”对“不良贷款”的影响关系,模型结果分为“是否有影响”以及“影响程度”进行阐述。首先查看自变量对因变量是否有影响。
是否有影响
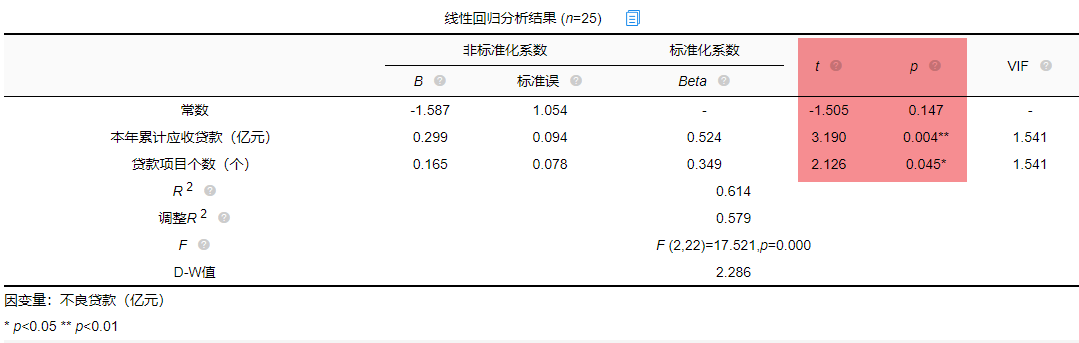

从上表可以看出,本年累计应收贷款分析项的t值为3.190,p值小于0.05说明此项具有显著性,即本年累计应收贷款对不良贷款有影响,贷款项目个数分析项的t值为2.126,p值小于0.05也说明此项具有显著性,即贷款项目个数对不良贷款有影响,二者对不良贷款有影响,具体谁影响大接下来进行说明。
影响程度
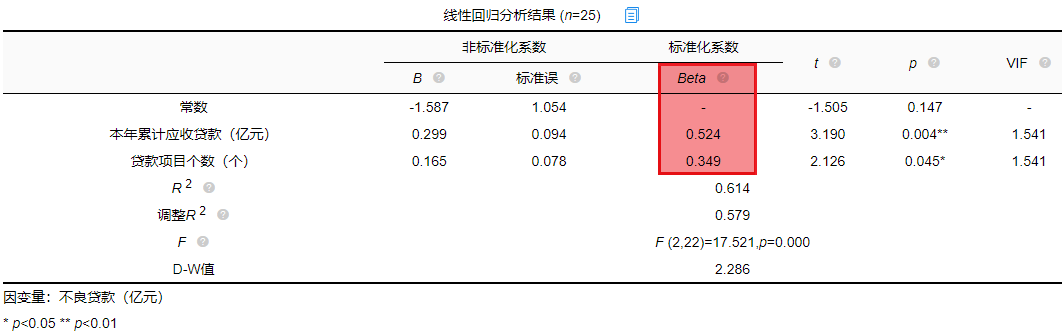

一般有影响关系才会去比较影响程度大小,影响程度大小需要查看标准化系数,标准化系数的绝对值越大表明自变量对因变量的反应越大,即影响程度越大,从上表中可以看出0.524>0.349,说明本年累积应收贷款相比较贷款项目个数对不良贷款影响更大。
除此之外,如果利用回归分析进行预测等,可以使用非标准化系数进行构建模型公式,具体不在赘述,可以进入SPSSAU官网进行查看。
六、总结
利用线性回归对管理者的问题进行分析,首先对数据的进本关系进行查看以及探索数据是否满足线性回归分析的条件,对数据处理后进行线性回归分析,发现“本年累积应收贷款”、 “贷款项目个数”对“不良贷款”有影响,并且查看标准化系数发现“本年累积应收贷款”影响程度更大,这对于管理者后续分析提供了有效信息。分析完毕。
案例数据:

写在前面的话:时不时有小伙伴会咨询多重线性回归、logistic回归和Cox回归的区别,本文虽不是专门讲三者区别的文章,但是文中有个表也许会对你有所帮助哦。
之前的内容里,我们介绍了在观察性研究中,当预后因素在暴露组和对照组间分布不均衡时,最简单的处理办法就是对研究资料按照混杂因素来进行分层分析,从而达到控制混杂因素的目的。
然而,分层分析仅仅适用于混杂因素较少,且多为分类变量的情况。当我们的研究中存在较多的混杂因素,且混杂因素较为复杂(例如混杂因素为多分类变量或连续变量)时,应该如何对混杂因素进行控制和调整呢?
今天我们就来一起讨论下,大家平时最常用到的多因素调整分析法。
多因素调整分析
多因素分析是相对于单因素分析而言,单因素分析仅关注一个因素在组间的差异或对结局事件的效应大小,而不考虑其他因素的影响。但实际上一种结局事件的发生和发展,常常受到多个因素的共同作用,因此仅采用单因素分析往往并不十分合理。多因素分析则是把多个变量之间的内在联系和相互影响考虑在内,同时分析多个因素对结局的影响。
在观察性研究中,我们通常可以构建一个多因素调整的回归方程,来探讨对结局有独立作用的影响因素。其中方程的因变量为结局事件,而自变量既包括研究者关注的暴露/处理因素(如药物、手术等),也包括其他可以影响结局的混杂因素(如年龄、性别、疾病严重程度等)。
三种回归模型
在多因素调整分析方法中,根据因变量的类型不同,我们最常应用到的三种回归模型即:多重线性回归、logistic回归及Cox回归。三种回归模型应用的条件和区别如表1所示。
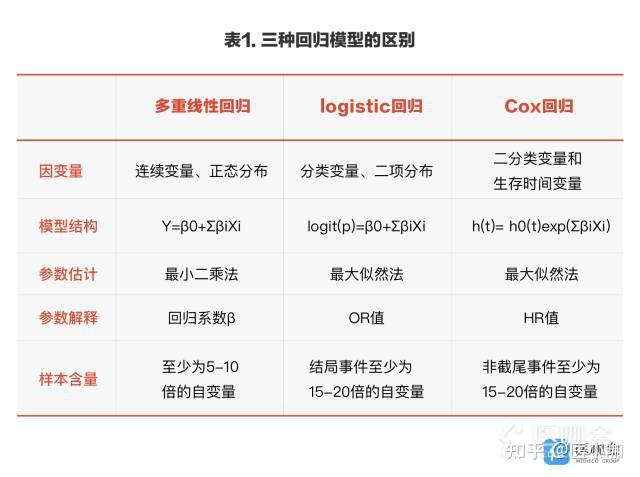

需要强调的是,应用回归模型进行多因素调整时,任何回归模型都是一个黑匣子,一定要考虑到每个回归模型的使用条件及模型的稳定性,如因变量的类型、分布特点、自变量之间的独立性、共线性等问题,切忌不要盲目套用模型,以免得出错误的结果。
考虑三个问题
我们在既往的内容中已经详细介绍过了关于三种回归模型的软件操作步骤,很多研究者就认为把所有混杂因素全部都放进回归模型中进行拟合,不就都可以调整了么?事情当然没有这么简单,统计分析并不是简单的数字游戏。
(统计操作教程可从以下合集中找到:【合集】75种统计方法的SPSS详细操作)
JAMA期刊发表的一篇文章《Adjusted Analyses in Studies Addressing Therapy and Harm》,总结了在进行多因素调整分析时,研究者需要关注的3个问题:
1. Did the investigator identify all known prognostic factors for the outcome of interest?(研究人员是否已经识别出所有与结局事件相关的预后因素?)
第一个问题要求研究人员尽可能全面地收集研究对象的基线特征,特别是根据专业知识和前期文献报道认为与结局事件密切相关的因素。当然除了已知的影响因素外,可能还会存在其他未知的残余混杂因素,这些混杂因素也会对结果造成一定的偏倚,因此为了减少残余的混杂偏倚,我们需要尽可能识别更多的混杂因素,保证信息的全面性。
2. Did the investigator accurately measure all these prognostic factors?(这些预后因素是否被准确地测量?)
准确测量预后因素在多因素分析中尤为重要,因为不准确的测量值无法反映预后因素对结局的真实效应,这样就会在原有混杂偏倚的基础上引入新的测量偏倚,也叫信息偏倚。为了保证测量的准确性,应尽可能使用客观指标,减少主观判断,提高检测的灵敏度。
3. Did the investigator conduct an adjusted analysis that included all these prognostic factors?(在多因素调整分析中,是否校正了所有已知的预后因素?)
常常会有人问到,到底应该在多因素分析的回归模型中放入多少个混杂因素来进行调整呢?是不是放入的混杂因素越多,研究结果就更准确呢?事实上这个问题并没有一个明确的答案,控制混杂因素的个数主要取决于发生结局事件的多少。控制的混杂因素越多,所需要的结局事件的例数就越多。
孙振球主编《医学统计学》第4版中提到,对于多重线性回归模型,样本量应至少为5-10倍的自变量个数,而对于logistic回归和Cox回归,结局事件则应至少为15-20倍的自变量个数,供大家作为参考。
研究实例
我们以2007年JAMA期刊发表一篇文献为例,该研究从美国心血管合作项目(Cooperative Cardiovascular Project)中纳入了122124名(65-84岁)在1994-1995年因急性心肌梗死入院治疗的患者形成观察队列,并通过美国Medicare医疗保险系统对其进行长达7年的结局事件随访。
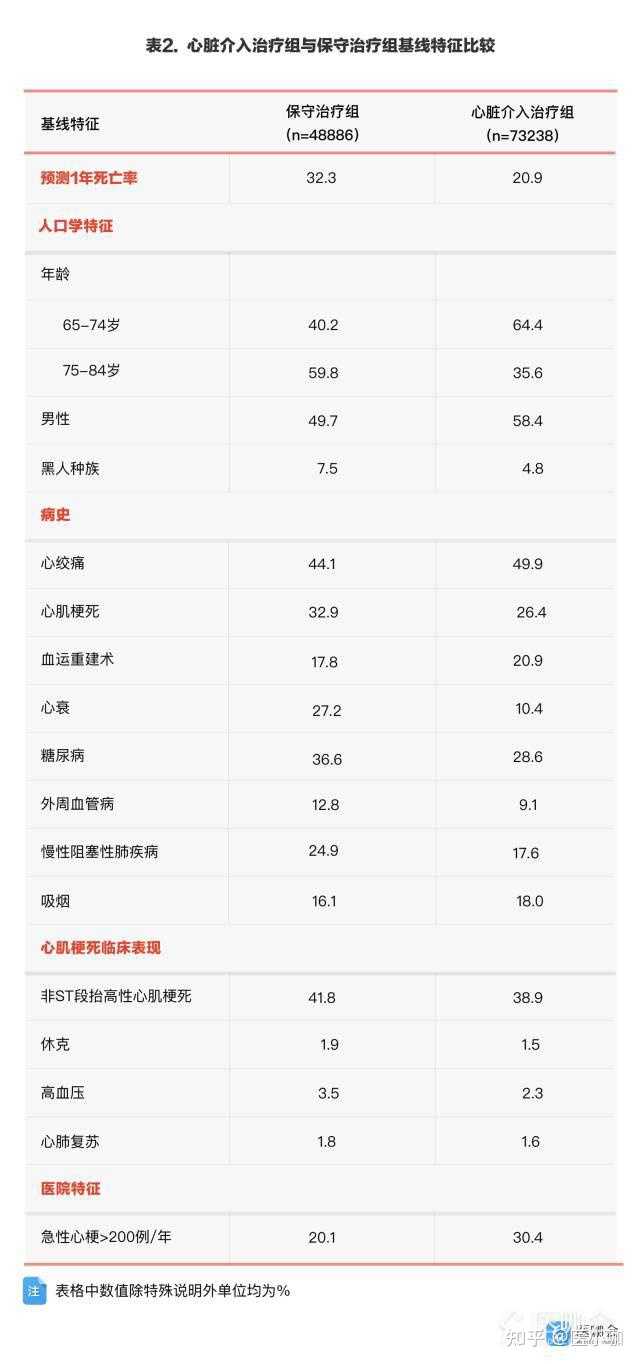
研究发现其中有60%的患者(73238)在住院30天内接受了心脏介入治疗,而40%的患者(48886)接受了保守治疗。通过比较两组患者的基线特点,结果显示心脏介入治疗组的患者与保守治疗组的患者相比,更为年轻、男性比例更多、发生休克、高血压的比例更少等,其他基线特征如表2所示。

由于两组人群中基线特征分布严重不均衡,研究者拟采用多因素调整的方法构建回归模型,以此评估心脏介入治疗对急性心肌梗死患者预后的影响作用。在该研究4年的随访时间里一共有50699名患者发生死亡,研究者一共筛选出65个与心梗后死亡相关的影响因素,放入到Cox回归模型中进行调整。
结果显示,在未调整混杂因素前,HR=0.37(95% CI:0.36-0.37),提示与保守治疗相比,心脏介入治疗可以有效降低心梗患者63%的死亡相对风险。而经过多因素调整后,HR=0.51(95% CI:0.50-0.52),提示心脏介入治疗可以有效降低心梗患者49%的死亡相对风险。
我们可以发现,经过多因素调整后心脏介入治疗对于心梗患者死亡风险的保护作用被削弱,说明多因素调整起到了一定的控制混杂因素的作用。但是作者也在文中提到,仍然有一些因素缺失或者未被记录到,如饮酒量、慢性炎症疾病等因素,这些因素也可能会造成一定的混杂偏倚,因此心脏介入治疗对心梗患者死亡风险的保护作用仍有可能被高估,其真实效应还有待进一步考究。
总结一下,多因素调整分析法,是在观察性研究中控制混杂因素应用最为广泛的一种方法,而且调整后回归模型的参数解释也非常直观易懂。但是由于研究者往往无法全面收集信息,或者无法进行准确测量,或者仍存在一些未知的混杂因素,而回归模型中需要调整的混杂因素的个数又往往受到结局事件的限制,这些都会对多因素回归模型的结果造成一定的偏倚,在应用时也需要多加注意。
参考文献
[1] JAMA. 2017 Feb 21;317(7):748-759
[2] 孙振球《医学统计学》第4版
[3] JAMA. 2007 Jan 17; 297(3): 278–285
更多阅读: