





























Snowflake just announced their new state-of-the-art enterprise-grade open source LLM (large language model)—Snowflake Arctic—which is expected to create ripples in the AI community. Snowflake Arctic stands out from the rest due to its unique and innovative Dense Mixture of Experts hybrid transformer architecture, which delivers top-tier intelligence with exceptional efficiency on a large scale. It has an astonishing 480 Billion parameters spread across 128 fine-grained experts and uses a top-2 gating technique to choose 17 Billion active parameters. A standout feature of Snowflake Arctic is its open nature—Snowflake has released its weights under an Apache 2.0 license—setting a new bar for openness in enterprise AI technology. Arctic's outstanding performance exceeds both open source and closed source models, such as DBRX, Llama, Mixtral, Grok, and others, effectively cementing its position as the best LLM for enterprise applications.
In this article, we will cover everything you need to know about Snowflake Arctic, including the essential features it offers, the sorts of models it has released, its architecture, and how it was trained. Also, we will explore how it differs from other top open source LLM models like DBRX, Llama, Mixtral, and others to see how it differs in performance and architecture.
Snowflake and its Enterprise Grade Open Source LLM — Snowflake Arctic
Large language models—LLM for short—are advanced machine learning models that are trained using a massive corpus of text data, allowing them to generate and analyze language just like we do. They can tackle all sorts of tasks, like:
- Creating meaningful text based on the given prompts
- Translating between languages
- Providing context-aware responses to queries
- Identifying sentiment or emotions in text
The secret sauce behind LLMs is a mix of deep learning techniques and powerful transformer-based architectures. These systems help analyze and understand language better by focusing on the most significant parts of the input.
LLMs have numerous real-world use cases, such as:
- Helping to write articles, stories, and even poetry
- Powering conversational agents and chatbots
- Providing seamless language translation services
… and so much more!
So, the next time you engage with an AI that feels almost human, remember that a Large Language Model is probably the brains behind it!
Several Open LLMs (Large Language Models) are now gaining popularity and adoption. Let's have a look at some popular names:
- Grok-1: Developed by xAI, Grok is a state-of-the-art Mixture of Experts (MoE) model. It has a whopping 314 Billion parameters, and its architecture is tailored for efficiency, outperforming conventional large language models. Grok-1’s design allows for selective activation of weights, which contributes to its enhanced performance during both pre-training and inference tasks.
- Llama (Large Language Model Meta AI): Developed by Meta AI, Llama is a family of autoregressive large language models. It consists of several model sizes ranging from 7 Billion to 65 Billion+ parameters (in the initial release), with the following versions, such as Llama 2 and Llama 3, having larger models of up to 70 Billion and 400 Billion+ parameters, respectively. These models are trained on a massive dataset gathered from a variety of publicly available sources, including web pages, books, code repositories, and scientific articles.
- DBRX: Developed by Databricks, DBRX is an open source LLM that has set new benchmarks for open LLMs and is especially strong as a code model. It uses a fine-grained Mixture of Experts (MoE) architecture that improves efficiency in both the training and inference stages. DBRX provides a compelling combination of performance and efficiency, with 132 Billion parameters in total, 36 Billion of which are active at any time.
- Snowflake Arctic: Developed by Snowflake, is an open, enterprise-grade LLM that stands out with its Dense Mixture of Experts (MoE) hybrid transformer architecture. It has an astonishing 480 Billion parameters, with 17 Billion active at any given time, made possible by a top-2 gating technique. This architecture allows Snowflake Arctic to activate 50% or fewer tokens than comparable-sized models, improving efficiency and performance. Arctic's 128 expert layers demonstrate its ability to handle complex tasks, establishing a new standard in the field of open source LLM. We'll get into further detail in the next section!
What is Snowflake Arctic?
Snowflake Arctic, a state-of-the-art large language model developed by Snowflake's AI research team, was announced on April 24, 2024. Arctic is a ground-breaking achievement in enterprise AI, combining top-tier intelligence with unprecedented efficiency and a solid dedication to openness.
Snowflake Arctic utilizes a unique Dense Mixture of Experts (MoE) Hybrid transformer architecture, with 480B parameters distributed over 128 fine-grained experts, and uses top-2 gating to choose 17B active parameters.
Snowflake Arctic has several key features, such as:
1) Efficiently Intelligent
Snowflake Arctic excels at complex enterprise tasks, such as SQL generation, coding, and instruction following. It frequently surpasses other models in industry benchmark tests, proving its ability to deal with complicated, real-world situations.
2) Breakthrough Efficiency
Snowflake Arctic is powered by a unique Dense-MoE Hybrid transformer architecture, Arctic delivers top-tier performance at a fraction of the development cost compared to similar models.
3) Truly Open Source
Snowflake has released Snowflake Arctic under an Apache 2.0 license, providing ungated access to its weights and code.
4) Enterprise AI Focused
Snowflake Arctic model is specifically tailored for enterprise AI needs, focusing on high-quality tasks for enterprise. It's great for core applications like data analysis and automation and shines in outperforming larger models without needing lots of computing power.
Snowflake Arctic Models
To meet various enterprise AI needs, Snowflake has introduced two major models within the Snowflake Arctic family:
- Snowflake Arctic Instruct: This variant of the Snowflake Arctic model is fine-tuned to excel in generating high-quality responses from natural language prompts.
- Snowflake Arctic Base: This is a pre-trained version of the Snowflake Arctic model that can be used as a foundational language model in a variety of applications. It does not require further fine-tuning for tasks such as retrieval-augmented generation, making it a versatile and ready-to-use option for enterprises.
Snowflake also just launched the Snowflake Arctic family of text embedding models, which includes five text embedding models. These embedded text models, which were optimized for retrieval tasks, were released to the open source community in mid-April under an Apache 2.0 license. The models are:
- Snowflake-arctic-embed-m
- Snowflake-arctic-embed-l
- Snowflake-arctic-embed-m-long
- Snowflake-arctic-embed-xs
- Snowflake-arctic-embed-s
Snowflake Arctic Training Process and Architecture—What Makes it Special?
What actually distinguishes Snowflake Arctic from other LLMs is its unique training approach and architecture, which were carefully crafted by the Snowflake AI research team. Their goal was to pioneer new ground in cost-effective training and transparency. Snowflake Arctic provides a unique solution for enterprises that prioritizes performance and accessibility.
Dense + Mixture of Experts (MoE) Hybrid Architecture
Snowflake Arctic combines a 10 Billion dense transformer model with a massive residual 128 experts * 3.66 Billion parameter Mixture of Experts (MoE) Multilayer perceptron (MLP) component, resulting in a total of 480 Billion parameters and 17 Billion active parameters chosen using top-2 gating technique.
Many-but-Condensed Experts
One significant innovation is Snowflake Arctic's "many-but-condensed" expert approach. It uses 128 fine-grained experts, far more than typical Mixture of Experts (MoE) models which use only ~8-16 experts. Having a large number of experts increases the routing flexibility and combinatorial modeling power. However, Snowflake Arctic mitigates potential overhead by making these experts "condensed"—each expert is 3.66 Billion parameters rather than the hundreds of Billions used in other models. This condensed size allows for efficient expert activation during inference.
Architecture
Training vanilla Mixture of Experts (MoE) architectures with many experts is computationally inefficient due to the massive communication overhead between experts. Its architecture cleverly mitigates this through system-model co-design.
Snowflake Arctic's architecture allows for overlapping communication and computation by combining the dense transformer with the residual Mixture of Experts (MoE) component. This combination between model and systems allows hiding a significant portion of the communication overhead, allowing for exceptionally efficient Mixture of Experts (MoE) training.
How Was Snowflake Arctic Created?
Snowflake Arctic was created through extensive training effort, using cutting-edge infrastructure and techniques.
1) Hardware Infrastructure
Snowflake Arctic was created through a massive training effort leveraging cutting-edge infrastructure. The model was trained using a specialized cluster of over 1,000 GPUs. This immense computational power required around $2 million in computational resources, which is remarkably cost-effective compared to other models.
2) Training Process
Most open source LLMs follow a generic pre-training approach. In contrast, Snowflake Arctic was trained in a three-stage curriculum, with each stage focusing on different data compositions to optimize the model's performance on enterprise-focused tasks. The training process for Arctic was split into three distinct stages totaling around 3.5 Trillion tokens:
- Phase 1: 1 Trillion tokens
- Phase 2: 1.5 Trillion tokens
- Phase 3: 1 Trillion tokens
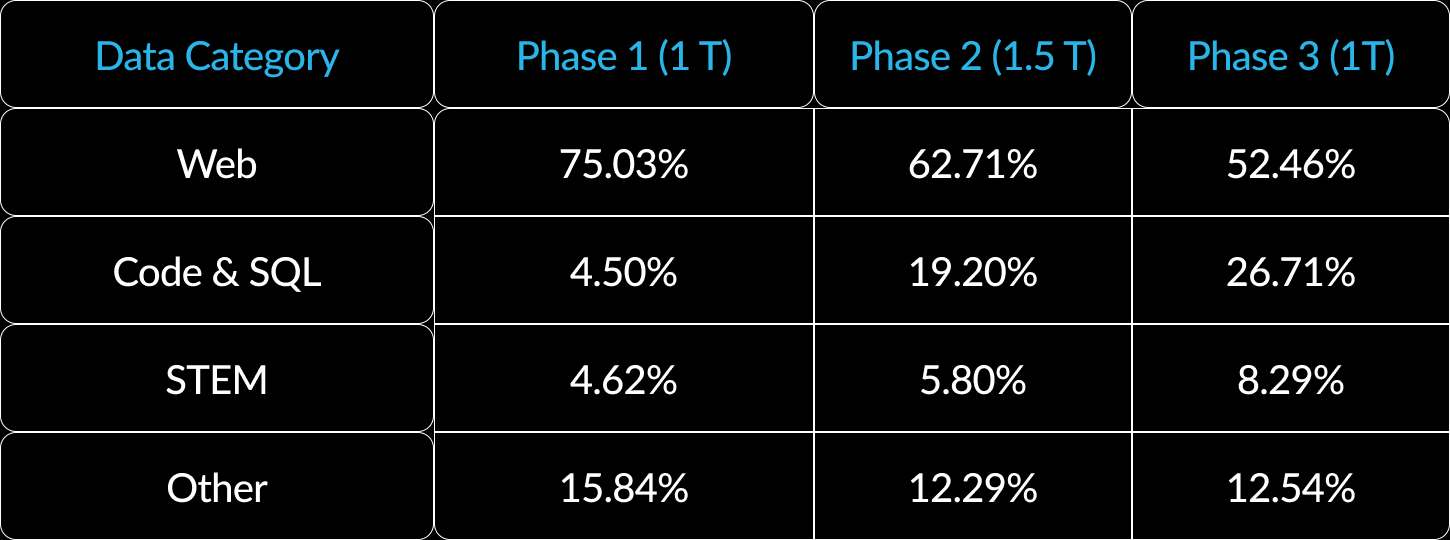
This multi-stage approach allowed different competencies to be wired logically, analogous to how humans acquire knowledge incrementally.
3) Development Process and Timeline
Snowflake states that the AI research team relied on publicly available data throughout the procedure. Some of the key public datasets used are:
The entire process of dataset collection, model architecture design, multi-phase training, and iterative refinement spanned approximately 3 months from start to the release of Snowflake Arctic.
Snowflake AI research team was able to improve Arctic's performance on complex enterprise tasks like SQL creation, coding, and instruction following by merging these disparate data sources and using a precisely crafted three-stage curriculum.
How Does Snowflake Arctic Performance Compare Against Other Models?
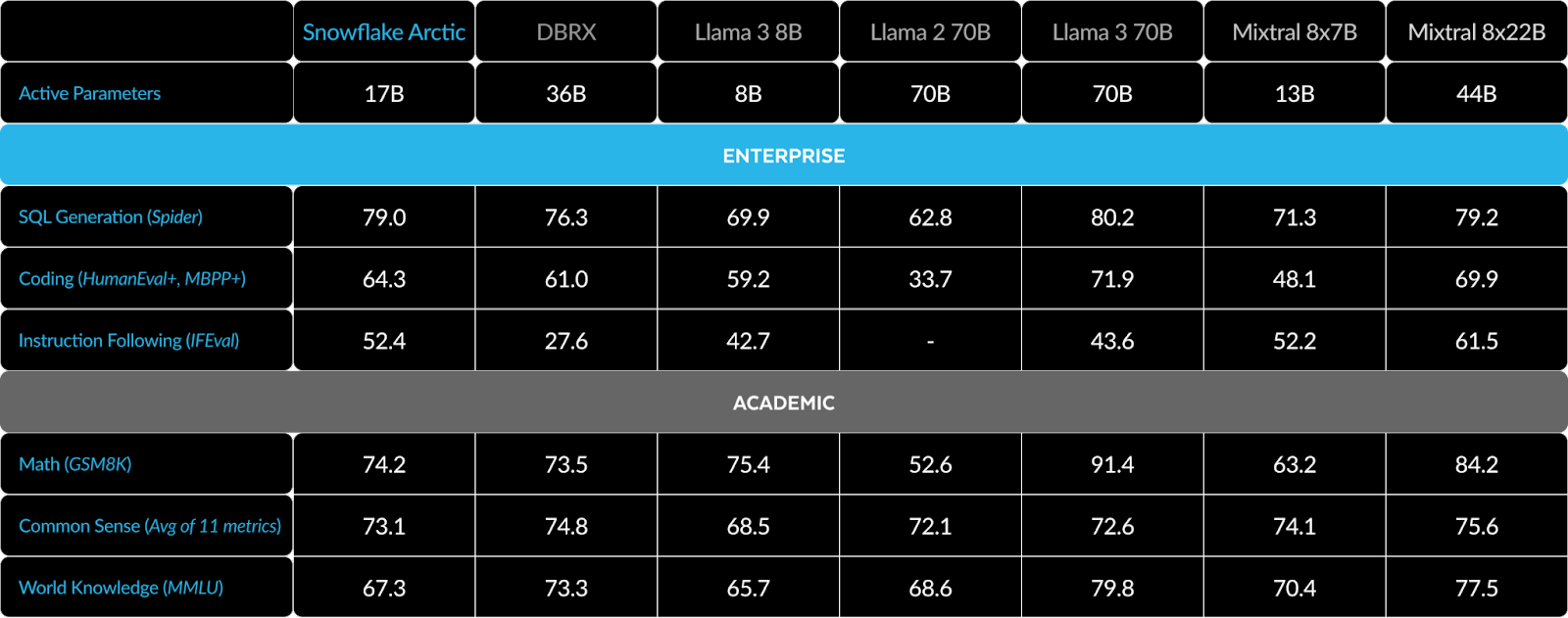
Snowflake has introduced two models—Snowflake Arctic Base and Snowflake Arctic Instruct. Snowflake Arctic Instruct is a general-purpose model that excels in various benchmarks. Let's delve into the technical details of how Snowflake Arctic Instruct compares against popular open LLM models. Here's a breakdown of how Arctic stacks up against models like DBRX, Llama (3 8B, 2 70B, 3 70B), and Mixtral (8x7B, 8x22B):
Snowflake Arctic vs. Databricks DBRX
Let's dive into the detailed comparison between Snowflake Arctic and DBRX across several key benchmarks:
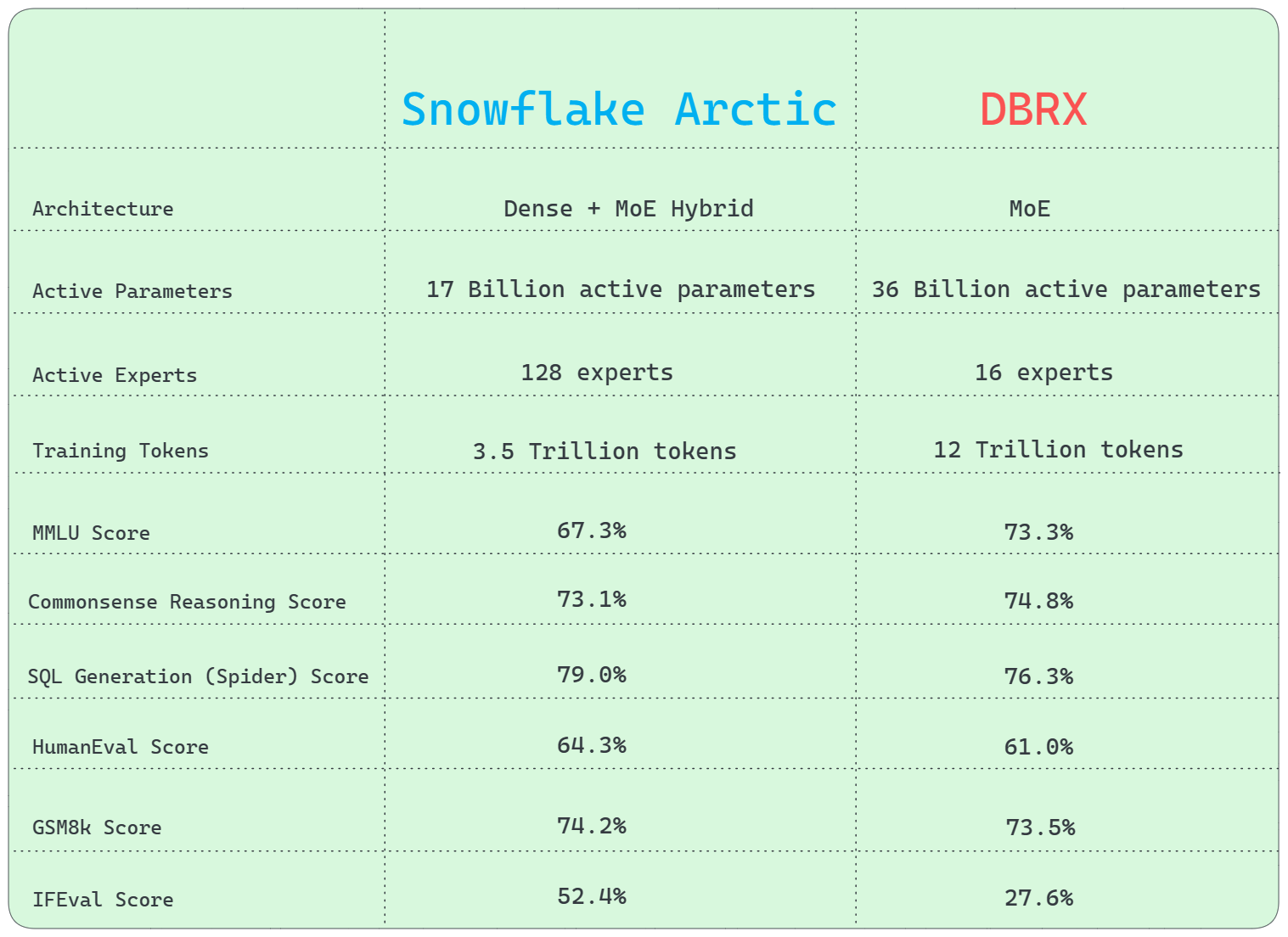
1) Architecture Difference
DBRX uses a fine-grained Mixture of Experts (MoE) architecture, whereas Arctic uses a distinctive Dense + Mixture of Experts (MoE) Hybrid transformer architecture, combining a dense model with a residual MoE component for efficient training and inference.
2) Active Parameters
In terms of active parameters, DBRX has a significant advantage over Snowflake Arctic, with a remarkable 36 Billion active parameters to Snowflake Arctic's 17 Billion.
3) Active Experts
Snowflake Arctic can activate up to 128 experts at the same time. This demonstrates its potential to leverage a larger number of experts than DBRX, which can activate 16 experts.
4) Training Tokens
Snowflake Arctic's training involved 3.5 Trillion tokens, while DBRX was trained on a substantially larger dataset of 12 Trillion tokens.
5) General Knowledge
MMLU (Multiple-choice Model-Linguistic Understanding) benchmark shows that DBRX outperforms Snowflake Arctic.
- MMLU score: 67.3% (Snowflake Arctic Instruct) vs. 73.3% (DBRX Instruct)
6) Commonsense Reasoning
Both Snowflake Arctic and DBRX perform similarly on commonsense reasoning benchmarks.
- Score: 73.1% (Snowflake Arctic Instruct) vs. 74.8% (DBRX Instruct)
7) SQL Generation
Snowflake Arctic beats DBRX in SQL generation tasks, as shown by the Spider benchmark test.
- SQL Generation (Spider) score: 79.0% (Snowflake Arctic Instruct) vs. 76.3% (DBRX Instruct)
8) Programming and Mathematical Reasoning
Snowflake Arctic excels at programming and mathematical reasoning, scoring higher on the HumanEval and GSM8k benchmarks.
- HumanEval score: 64.3% (Snowflake Arctic Instruct) vs. 61.0% (DBRX Instruct)
- GSM8k score: 74.2% (Snowflake Arctic Instruct) vs. 73.5% (DBRX Instruct)
9) Instruction Following (IFEval)
This benchmark assesses a model's ability to follow textual instructions in a variety of tasks, including reasoning, planning, and problem-solving. Snowflake Arctic outperformed DBRX in this benchmark. Here is the score:
- IFEval Score: 52.4% (Snowflake Arctic Instruct) vs. 27.6% (DBRX Instruct)
Snowflake Arctic vs. Llama 3 8B
Let's take a closer look at Snowflake Arctic vs. Llama 3 8B:
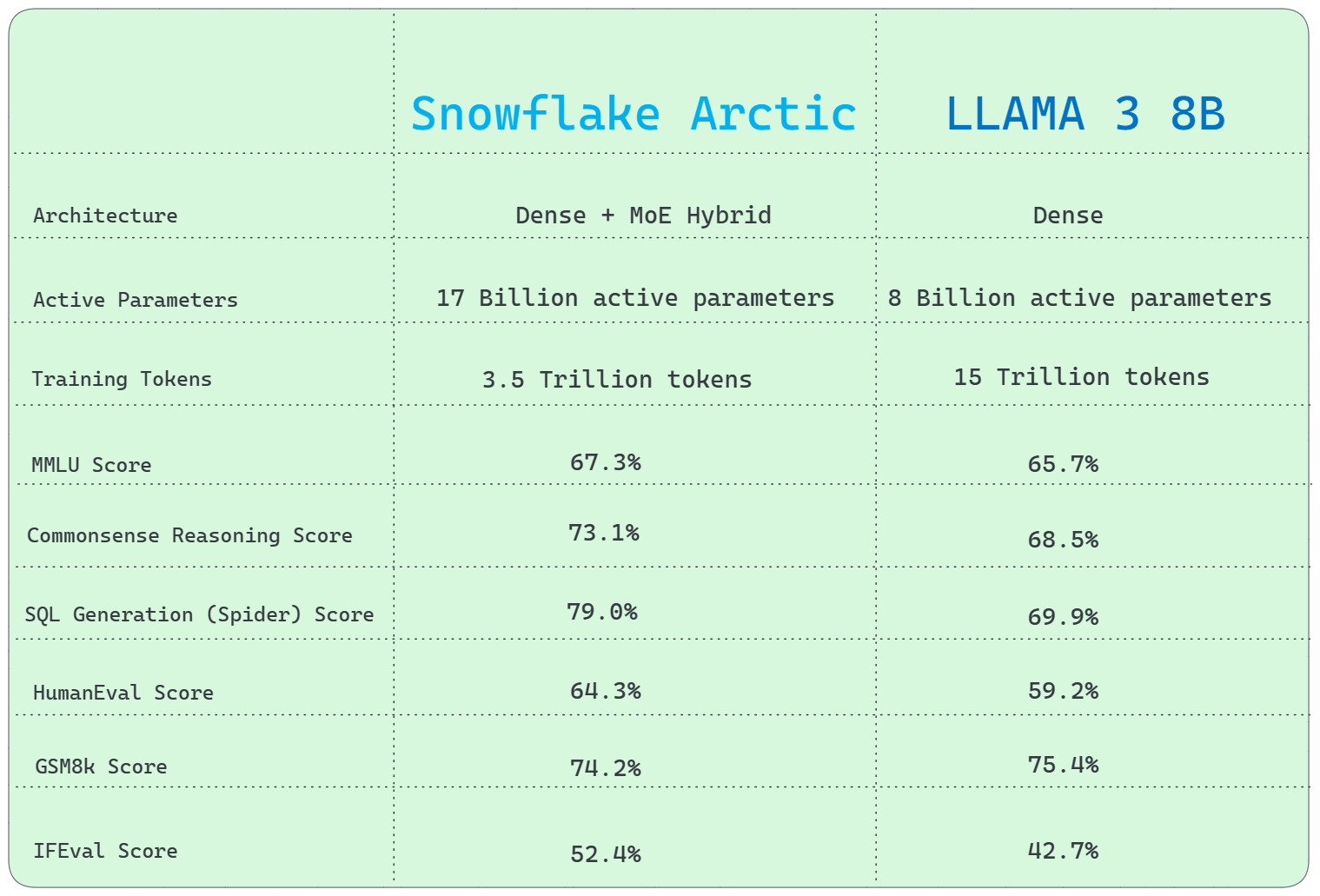
1) Architecture Difference
Llama 3 8B uses a traditional Dense architecture, while Snowflake Arctic utilizes a unique Dense + Mixture of Experts (MoE) Hybrid transformer architecture.
2) Active Parameters
Snowflake Arctic has a significant advantage over Llama 3 8B, with 17 Billion active parameters compared to Llama 3 8B's 8 Billion.
3) Training Tokens
Snowflake Arctic trained using 3.5 Trillion tokens, but Llama 3 8B trained with a much bigger dataset of 15 Trillion tokens.
4) General Knowledge
MMLU (Multiple-choice Model-Linguistic Understanding) (or General Knowledge) benchmark shows that Snowflake Arctic outperforms Llama 3 8B.
- MMLU Score: 67.3% (Snowflake Arctic Instruct) vs. 65.7% (Llama 3 8B)
5) Commonsense Reasoning
In terms of common sense reasoning, Snowflake Arctic outperforms Llama 3 8B.
- Score: 73.1% (Snowflake Arctic Instruct) vs. 68.5% (Llama 3 8B)
6) SQL Generation
Snowflake Arctic completely outperforms Llama 3 8B in SQL generation tasks, as shown by the Spider benchmark test.
- SQL Generation (Spider) Score: 79.0% (Snowflake Arctic Instruct) vs. 69.9% (Llama 3 8B)
8) Programming and Mathematical Reasoning
Snowflake Arctic excels at programming but falls slightly behind Llama 3 8B in mathematical reasoning. Here's the HumanEval and Math(GSM8k) benchmark scores.
- HumanEval score: 64.3% (Snowflake Arctic Instruct) vs. 59.2% (Llama 3 8B)
- GSM8k Score: 74.2% (Snowflake Arctic Instruct) vs. 75.4% (Llama 3 8B)
7) Instruction Following (IFEval)
Snowflake Arctic outperforms Llama 3 8B in instruction following benchmark. Here is the score:
- IFEval Score: 52.4% (Snowflake Arctic Instruct) vs. 42.7% (Llama 3 8B)
Snowflake Arctic vs. Llama 2 70B
Let's take a closer look at Snowflake Arctic vs. Llama 2 70B:
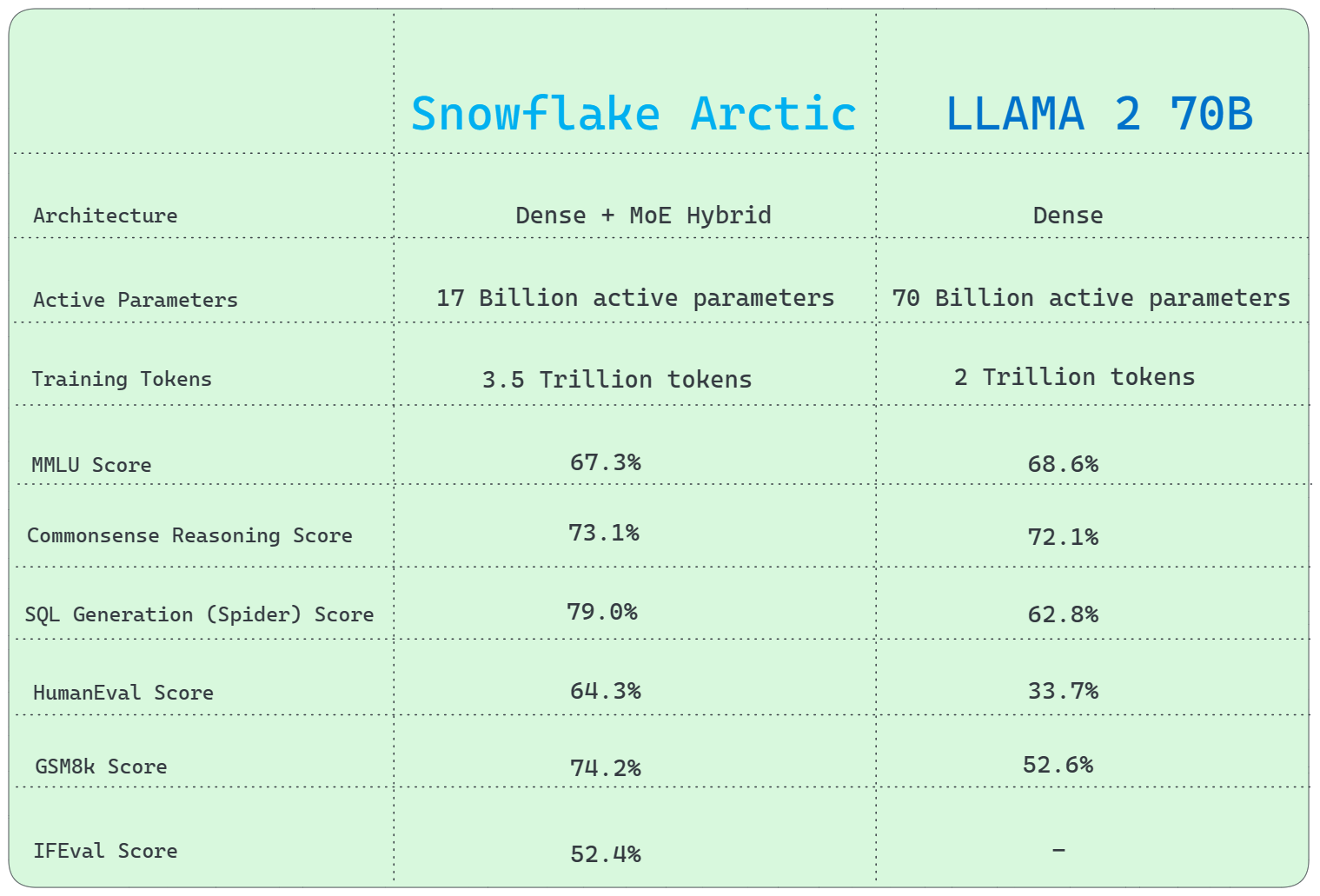
1) Architecture Difference
Llama 2 70B utilizes a conventional Dense architecture, whereas Snowflake Arctic uses a distinctive Dense + Mixture of Experts (MoE) Hybrid transformer architecture.
2) Active Parameters
Llama 2 70B has a huge advantage with 70 Billion active parameters, significantly more than Snowflake Arctic's 17 Billion.
3) Training Tokens
Snowflake Arctic's training involved 3.5 Trillion tokens, while Llama 2 70B was trained on 2 Trillion tokens.
4) General Knowledge
MMLU (Multiple-choice Model-Linguistic Understanding) (or General Knowledge) benchmark shows that Llama 2 70B outperforms Snowflake Arctic.
- MMLU Score: 67.3% (Snowflake Arctic Instruct) vs. 68.6% (Llama 2 70B)
5) Commonsense Reasoning
Snowflake Arctic outperforms Llama 2 70B in terms of common sense reasoning.
- Score: 73.1% (Snowflake Arctic Instruct) vs. 72.1% (Llama 2 70B)
6) SQL Generation
Snowflake Arctic outperforms Llama 2 70B in SQL generation tasks, as demonstrated by the Spider benchmark test.
- SQL Generation (Spider) Score: 79.0% (Snowflake Arctic Instruct) vs. 62.8% (Llama 2 70B)
8) Programming and Mathematical Reasoning
Snowflake Arctic excels at programming and mathematical reasoning, scoring higher on the HumanEval and GSM8k benchmarks than Llama 2 70B.
- HumanEval score: 64.3% (Snowflake Arctic Instruct) vs. 33.7% (Llama 2 70B)
- GSM8k Score: 74.2% (Snowflake Arctic Instruct) vs. 52.6% (Llama 2 70B)
Snowflake Arctic vs. Llama 3 70B
Let's take a closer look at Snowflake Arctic vs. Llama 3 70B:
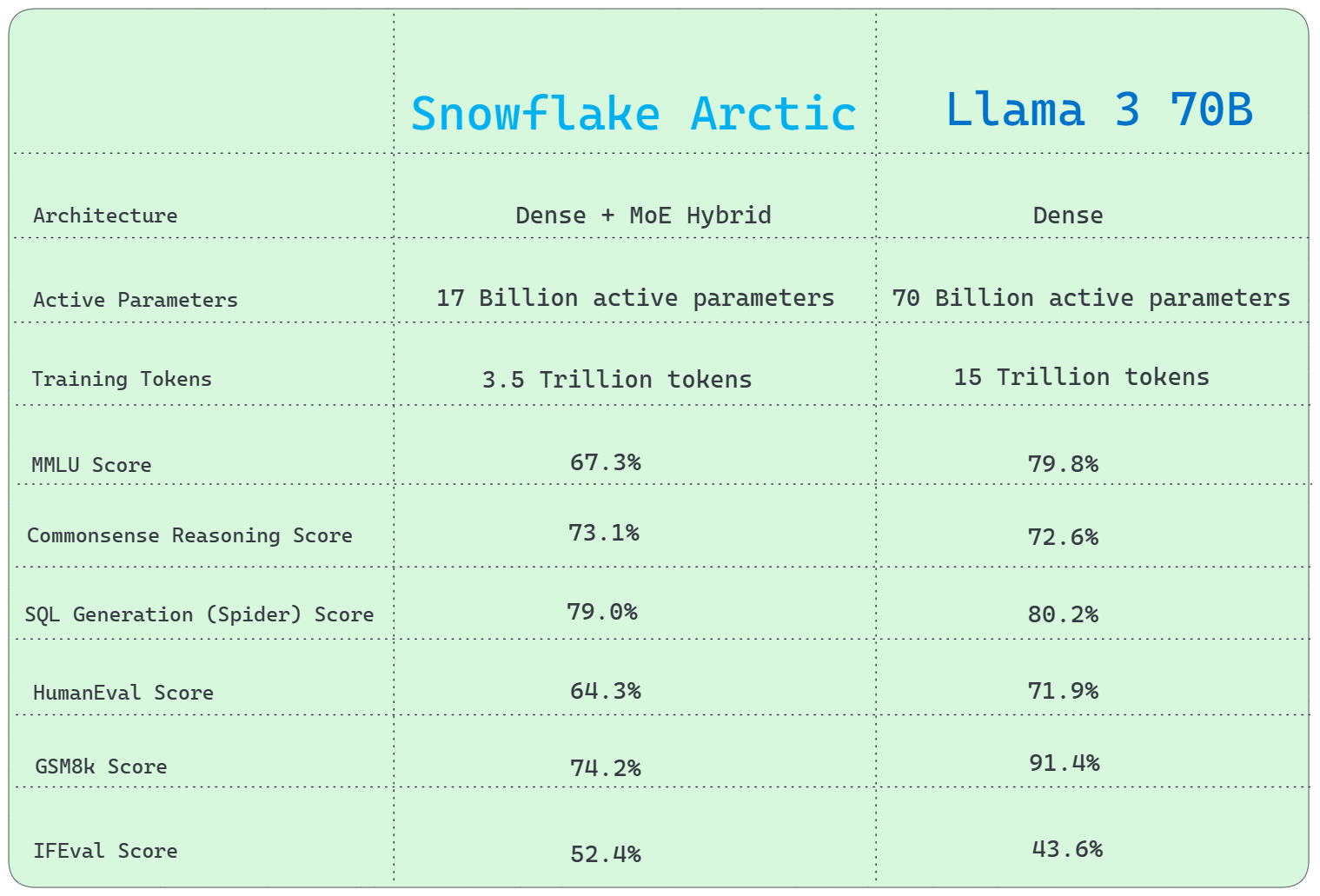
1) Architecture Difference
Llama 3 70B utilizes a conventional Dense architecture, whereas Snowflake Arctic uses a distinctive Dense + Mixture of Experts (MoE) Hybrid transformer architecture.
2) Active Parameters
In terms of active parameters, Llama 3 70B has a huge advantage over Snowflake Arctic, with an amazing 70 Billion active parameters over Snowflake Arctic's 17 Billion active parameters.
3) Training Tokens
Snowflake Arctic was trained using 3.5 Trillion tokens, whereas Llama 3 70B was trained on a massively larger dataset of 15 Trillion tokens.
4) General Knowledge
MMLU (Multiple-choice Model-Linguistic Understanding) (or General knowledge) benchmark indicates better performance for Llama 3 70B over Snowflake Arctic.
- MMLU Score: 67.3% (Snowflake Arctic Instruct) vs. 79.8% (Llama 3 70B)
5) Commonsense Reasoning
Snowflake Arctic performs really well on common sense reasoning compared to Llama 3 70B.
- Score: 73.1% (Snowflake Arctic Instruct) vs. 72.6% (Llama 3 70B)
6) SQL Generation
Snowflake Arctic is head-to-head with Llama 3 70B in SQL generation tasks, as demonstrated by the Spider benchmark test.
- SQL Generation (Spider) Score: 79.0% (Snowflake Arctic Instruct) vs. 80.2% (Llama 3 70B)
8) Programming and Mathematical Reasoning
Snowflake Arctic excels at programming but falls slightly behind Llama 3 70B in mathematical reasoning. Here's the HumanEval and Math(GSM8k) benchmark scores.
- HumanEval score: 64.3% (Snowflake Arctic Instruct) vs. 71.9% (Llama 3 70B)
- GSM8k Score: 74.2% (Snowflake Arctic Instruct) vs. 91.4% (Llama 3 70B)
7) Instruction Following (IFEval)
Snowflake Arctic performs slightly better than Llama 3 70B in instruction following benchmark. Here is the score:
- IFEval Score: 52.4% (Snowflake Arctic Instruct) vs. 43.6% (Llama 3 70B)
Snowflake Arctic vs. Mixtral 8x7B
Let's take a closer look at Snowflake Arctic vs. Mixtral 8x7B:
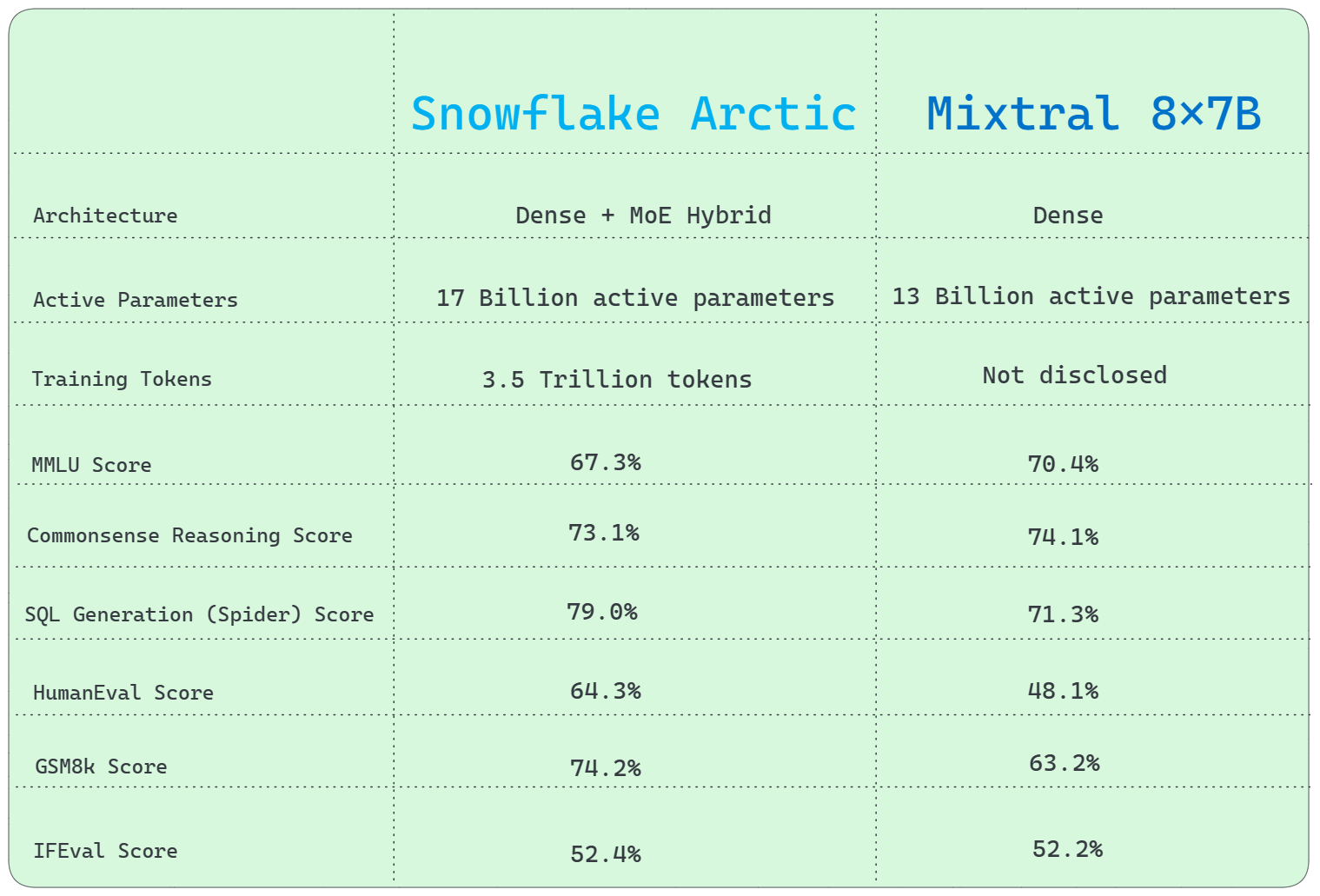
1) Architecture Difference
Mixtral 8x7B utilizes a conventional Mixture of Experts (MoE) architecture, whereas Snowflake Arctic employs a distinctive Dense + Mixture of Experts (MoE) Hybrid transformer architecture.
2) Active Parameters
Snowflake Arctic has 17 Billion active parameters, while Mixtral 8x7B contains 13 Billion active parameters.
3) Active Experts
Snowflake Arctic can activate up to 128 experts at the same time. This demonstrates its ability to use a larger number of experts than Mixtral 8x7B, which can activate 8 experts at once.
4) Training Tokens
Snowflake Arctic's training required 3.5 Trillion tokens, while Mixtral 8x7B is not disclosed.
5) General Knowledge
MMLU (Multiple-choice Model-Linguistic Understanding)(or General knowledge) benchmark indicates better performance for Mixtral 8x7B over Snowflake Arctic.
- MMLU score: 67.3% (Snowflake Arctic Instruct) vs. 70.4% (Mixtral 8x7B)
6) Commonsense Reasoning
Both Snowflake Arctic and Mixtral 8x7B perform similarly on commonsense reasoning benchmarks.
- Score: 73.1% (Snowflake Arctic Instruct) vs. 74.1% (Mixtral 8x7B)
7) SQL Generation
Snowflake Arctic outperforms Mixtral 8x7B in SQL generation tasks, as demonstrated by the Spider benchmark test.
- SQL Generation (Spider) Score: 79.0% (Snowflake Arctic Instruct) vs. 71.3% (Mixtral 8x7B)
8) Programming and Mathematical Reasoning
Snowflake Arctic excels at programming and mathematical reasoning, scoring higher on the HumanEval and GSM8k benchmarks.
- HumanEval score: 64.3% (Snowflake Arctic Instruct) vs. 48.1% (Mixtral 8x7B)
- GSM8k score: 74.2% (Snowflake Arctic Instruct) vs. 63.2% (Mixtral 8x7B)
9) Instruction Following (IFEval)
Snowflake Arctic performs slightly better than Llama 3 8B in the instruction following benchmark. Here is the score:
- IFEval Score: 52.4% (Snowflake Arctic Instruct) vs. 52.2% (Mixtral 8x7B)
Snowflake Arctic vs. Mixtral 8x22B
Let's take a closer look at Snowflake Arctic vs. Mixtral 8x22B:
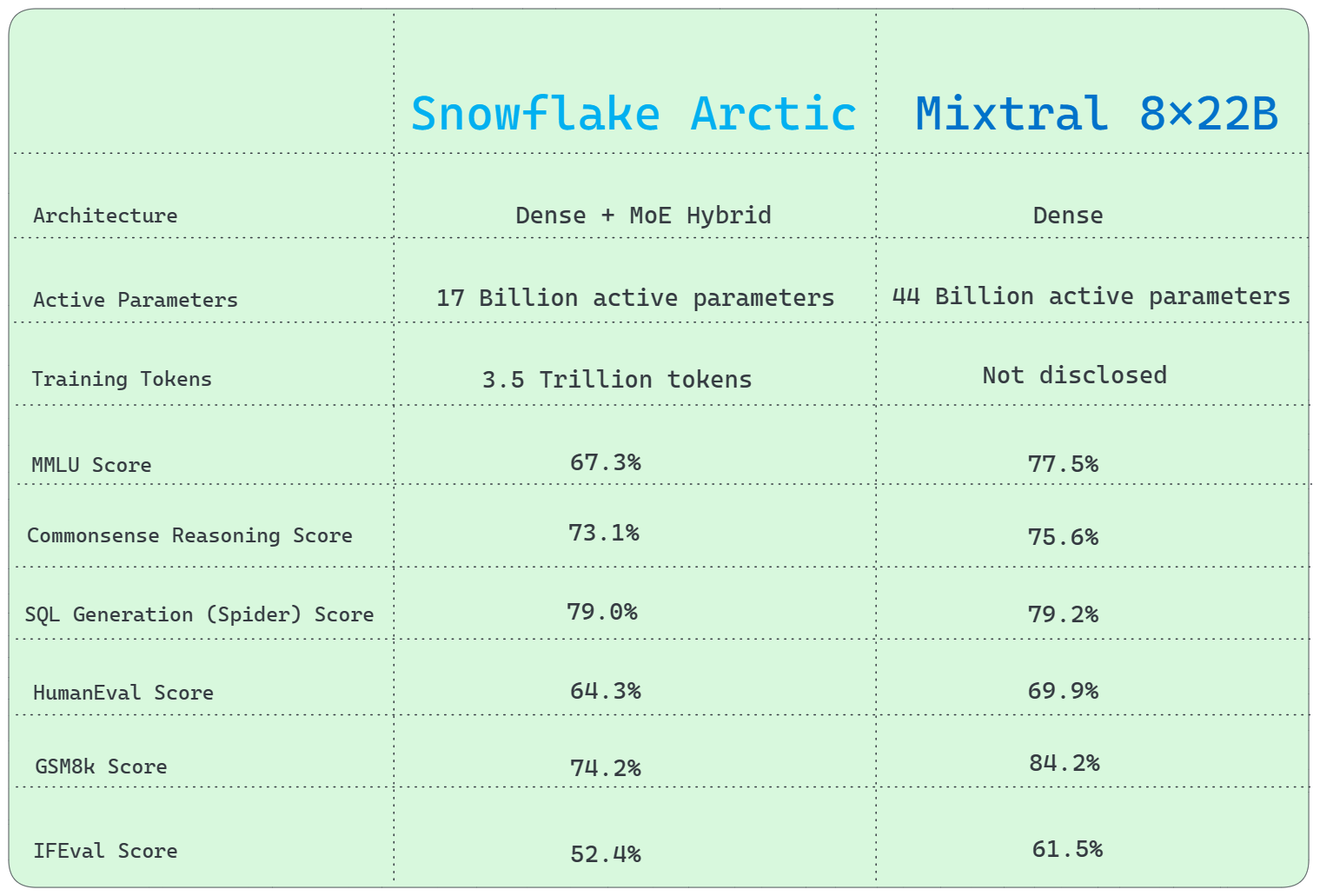
1) Architecture Difference
Mixtral 8x22B utilizes a conventional Mixture of Experts (MoE) architecture, whereas Snowflake Arctic utilizes a distinctive Dense + MoE Hybrid transformer architecture.
2) Active Parameters
Mixtral 8x22B has a significant advantage over Snowflake Arctic in terms of active parameters, with 44 Billion vs 17 Billion.
3) Active Experts
Snowflake Arctic can activate up to 128 experts at the same time. This demonstrates its ability to use a larger number of experts than Mixtral 8x22B, which can activate only 8 experts at once.
4) Training Tokens
Snowflake Arctic's training involved 3.5 Trillion tokens, while Mixtral 8x22B is not disclosed.
5) General Knowledge
MMLU (Multiple-choice Model-Linguistic Understanding) benchmark shows that Mixtral 8x22B outperforms Snowflake Arctic.
- MMLU score: 67.3% (Snowflake Arctic Instruct) vs. 77.5% (Mixtral 8x22B)
6) Commonsense Reasoning
Mixtral 8x22B performs relatively better performance levels on commonsense reasoning benchmarks.
- Score: 67.3% (Snowflake Arctic Instruct) vs. 75.6% (Mixtral 8x22B)
7) SQL Generation
Snowflake Arctic and Mixtral 8x22B perform relatively similarly in SQL generation tasks, as demonstrated by the Spider benchmark test.
- SQL Generation (Spider) score: 79.0% (Snowflake Arctic Instruct) vs. 79.2% (Mixtral 8x22B)
8) Programming and Mathematical Reasoning
Mixtral 8x22B excels at programming and mathematical reasoning, scoring higher on the HumanEval and GSM8k benchmarks.
- HumanEval score: 64.3% (Snowflake Arctic Instruct) vs. 69.9% (Mixtral 8x22B)
- GSM8k score: 74.2% (Snowflake Arctic Instruct) vs. 84.2% (Mixtral 8x22B)
9) Instruction Following (IFEval)
Mixtral 8x22B performs slightly better than Snowflake Arctic in instruction following benchmark. Here is the score:
- IFEval Score: 52.4% (Snowflake Arctic Instruct) vs. 61.5% (Mixtral 8x22B)
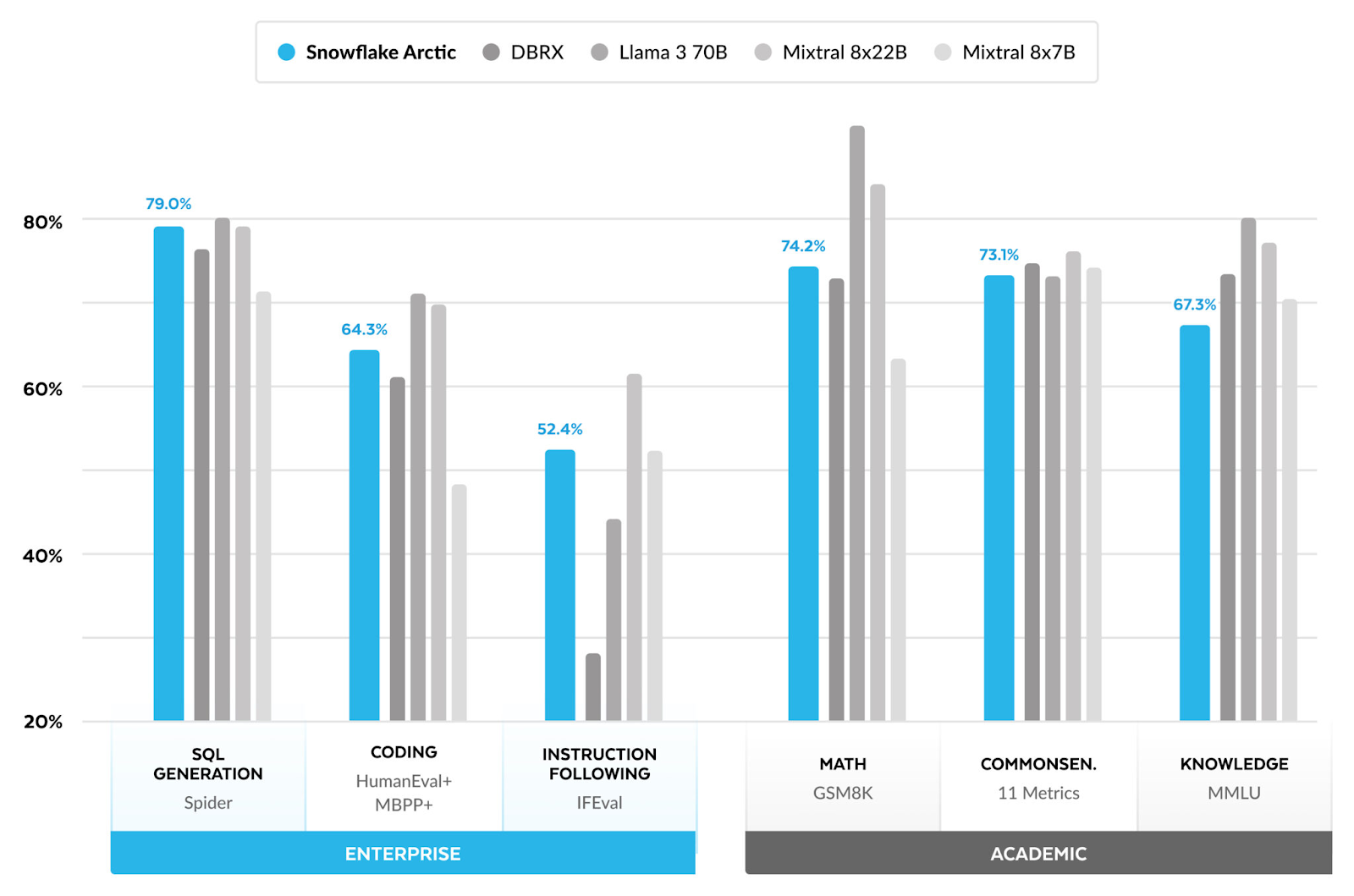
Check out the following table to get more in-depth insights into the benchmark performance differences between Snowflake Arctic and other open source LLM models.
How Does Snowflake Arctic Perform on Long-Context Tasks?
Snowflake Arctic excels in long-context tasks with its impressive 4,096 token attention context window. This capability allows Snowflake Arctic to process and analyze up to 4,096 tokens simultaneously, significantly boosting its ability to handle complex and lengthy inputs. The result is improved context awareness and more accurate, logical outputs. Although its context window is smaller than that of some larger LLMs, such as Gpt 4 Turbo(32k tokens), Claude 2(100k tokens), Claude 3 Opus(200K tokens), and Gemini 1.5 Pro(1 Million tokens), it is still competent at performing the majority of long-context tasks found in enterprise environments.
What makes this even more impressive is that the Snowflake team is actively working on extending this capability to support unlimited sequence generation through a sliding window approach and special attention "sinks", which will further enhance Snowflake Arctic's performance on long-context tasks and solidify its position as a top contender in the world of enterprise LLM.
Where to Find Snowflake Arctic in Action—Live Demo
To experience the power of Snowflake Arctic firsthand, you can explore various live demo platforms where the model is showcased:
1) Snowflake Cortex
You can use the Snowflake Arctic model in Snowflake Cortex's COMPLETE LLM function. Check out this step-by-step guide for setting up and using the Snowflake Arctic model with Snowflake Cortex functions. All you need to do is specify 'snowflake-arctic' as the model argument when calling the COMPLETE function.
For example:
SELECT SNOWFLAKE.CORTEX.COMPLETE('snowflake-arctic', 'Write a brief introduction about Snowflake Arctic');2) Streamlit Community Cloud
Snowflake has partnered with Streamlit to provide a live demo of Arctic on the Streamlit Community Cloud platform.
3) Hugging Face
You can find Snowflake Arctic demos and interactive playground environments on the Hugging Face platform.
4) NVIDIA API Catalog
NVIDIA offers Arctic demos and integration samples through their API catalog.
5) Replicate
Replicate hosts live demos and API integrations for Snowflake Arctic, allowing you to experience the model's capabilities firsthand.
Coming Soon:
Snowflake has stated that Snowflake Arctic will soon be available for a live demo and integration on various other platforms:
…and more coming soon!
Conclusion
And that’s a wrap! Snowflake just took its first big step towards building an enterprise-grade truly open source LLM called Snowflake Arctic. Arctic's pioneering Dense-Mixture of Experts (MoE) Hybrid architecture establishes a new standard for cost-effective training and inference of large language models, making it accessible to enterprises of any size. Snowflake Arctic is designed to enable enterprises to fully utilize AI by excelling at complicated tasks such as SQL creation, coding, and instruction following. Its higher performance, combined with its genuinely open nature and the availability of open research results, promotes collaboration and innovation in the AI community.
In this article, we have covered:
- What is a Large Language Model?
- What is Snowflake Arctic?
- List of available Snowflake Arctic models
- Snowflake Arctic Training Process and Architecture—What Makes it Special?
- How Was Snowflake Arctic Created?
- How Does Snowflake Arctic Performance Compare Against Other Models?
- How Does Snowflake Arctic Perform on Long-Context Tasks ?
- Step-By-Step Guide to Setup Snowflake Arctic
- Where to Find Snowflake Arctic in Action—Live Demo
… and so much more!
FAQs
What is Snowflake Arctic?
Snowflake Arctic is an open source LLM developed by Snowflake, featuring a unique Dense Mixture of Experts (MoE) hybrid transformer architecture.
What makes Snowflake Arctic different from other LLMs?
Snowflake Arctic stands out due to its unique Dense-Mixture of Experts (MoE) Hybrid architecture, which combines a dense transformer model with a residual Mixture of Experts (MoE) component.
How many parameters does Snowflake Arctic have?
Snowflake Arctic has a total of 480 Billion parameters, with 17 Billion active parameters chosen using a top-2 gating technique.
What makes Snowflake Arctic's architecture unique?
Snowflake Arctic combines a 10 Billion dense transformer model with a massive residual 128 expert * 3.66 Billion parameter Mixture of Experts (MoE) Multilayer Perceptron (MLP) component.
How many experts does Snowflake Arctic have?
Snowflake Arctic has 128 fine-grained experts, which is more than typical Mixture of Experts (MoE) models that use only 8-16 experts.
What is the purpose of having many experts in Snowflake Arctic?
Having a large number of experts increases the routing flexibility and combinatorial modeling power of the model.
How was Snowflake Arctic trained?
Snowflake Arctic was trained in a three-stage curriculum, with each stage focusing on different data compositions to optimize the model's performance on enterprise-focused tasks.
How many tokens was Snowflake Arctic trained on?
Snowflake Arctic was trained on a total of 3.5 Trillion tokens.
What datasets were used to train Snowflake Arctic?
Some of the key public datasets used to train Snowflake Arctic include RefinedWeb, C4, RedPajama, and StarCoder.
What are the two main models within the Snowflake Arctic family?
The two main models within the Snowflake Arctic family are Snowflake Arctic Instruct and Snowflake Arctic Base.
What is the difference between Snowflake Arctic Instruct and Snowflake Arctic Base?
Snowflake Arctic Instruct is fine-tuned to excel in generating high-quality responses from natural language prompts, while Snowflake Arctic Base is a pre-trained version that can be used as a foundational language model.
How does Snowflake Arctic perform on long-context tasks?
Snowflake Arctic is capable of handling long-context tasks due to its 4K attention context window, which allows it to analyze and process up to 4,000 tokens simultaneously.
What is the advantage of Snowflake Arctic's "many-but-condensed" expert approach?
The "many-but-condensed" expert approach in Snowflake Arctic mitigates potential overhead by making the experts "condensed" (each expert is 3.66 Billion parameters), allowing for efficient expert activation during inference.
How was Snowflake Arctic's architecture designed to improve training efficiency?
Snowflake Arctic's architecture allows for overlapping communication and computation by combining the dense transformer with the residual MoE component, hiding a significant portion of the communication overhead.
What hardware infrastructure was used to train Snowflake Arctic?
Snowflake Arctic was trained using a specialized cluster of over 1,000 GPUs.
How much computational resources were used to train Snowflake Arctic?
The training of Snowflake Arctic required around $2 million in computational resources, which is remarkably cost-effective for a model of its capabilities.
How long did the development process of Snowflake Arctic take?
The entire process of dataset collection, model architecture design, multi-phase training, and iterative refinement spanned approximately 3 months from start to the release of Snowflake Arctic.
Under what license was Snowflake Arctic released?
Snowflake Arctic was released under an Apache 2.0 license, providing ungated access to its weights and code.









