privateGPT walkthrough: Creating your own offline GPT Q&A system
A code walkthrough of privateGPT repo on how to build your own offline GPT Q&A system.

Large Language Models (LLMs) have surged in popularity, pushing the boundaries of natural language processing. OpenAI’s GPT-3.5 is a prime example, revolutionizing our technology interactions and sparking innovation. Particularly, LLMs excel in building Question Answering applications on knowledge bases. In this blog, we delve into the top trending GitHub repository for this week: the PrivateGPT repository and do a code walkthrough.

What is privateGPT?
One of the primary concerns associated with employing online interfaces like OpenAI chatGPT or other Large Language Model systems pertains to data privacy, data control, and potential data leakage. The privateGPT repository presents a fully offline alternative for engaging with personal documents. It is constructed using open-source tools and technology, thereby enabling the utilization of LLMs capabilities without compromising data privacy or encountering data leakage issues.

Running privateGPT locally
To run privateGPT locally, users need to install the necessary packages, configure specific variables, and provide their knowledge base for question-answering purposes. Additional information on the installation process and usage can be found in the repository documentation or by referring to a dedicated blog post on the topic.
Essentially you can run it by calling the privateGPT.py file like -
python privateGPT.py
And get a response that also mentions the sources it looked up for context.

Code Walkthrough
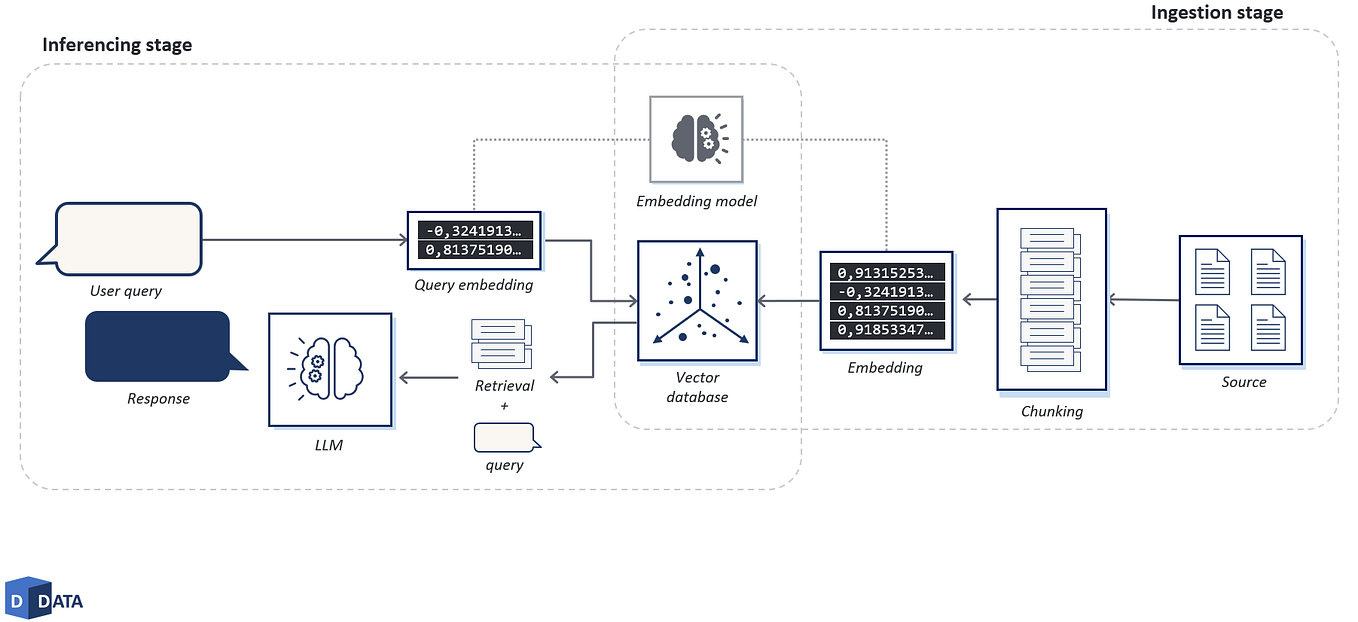
privateGPT code comprises two pipelines:
- Ingestion Pipeline: This pipeline is responsible for converting and storing your documents, as well as generating embeddings for them. The documents are stored in a suitable format, and their embeddings are stored in an embedding database.
- Q&A Interface: This interface accepts user prompts, the embedding database, and an open-source Language Model (LM) model as inputs. It utilizes these inputs to generate responses to the user’s queries.
1. Ingestion Pipeline
Let’s delve into the ingestion pipeline for a closer examination. The ingestion pipeline encompasses the following steps:
- Identifying files with various extensions and retrieving all the knowledge base from the source directory.
- Splitting the documents into smaller chunks based on the parameters of chunk_size and chunk_overlap.
- Initializing the
Huggingfaceembeddingsmodule oflangchain. This involves loading a pre-trained language model from the sentence_transformers library. - Initializing the Chroma database from
langchain.vectorstores. This step involves taking the chunked text and the initialized embedding model and saving it in the embedding database on disk.

Let’s look at these steps one by one.
1.1 Identifying and loading files from the source directory
First, we import the required libraries and various text loaders from langchain.document_loaders.
import os
import glob
from typing import List
from multiprocessing import Pool
from tqdm import tqdm
from langchain.document_loaders import (
CSVLoader,
EverNoteLoader,
PDFMinerLoader,
TextLoader,
UnstructuredEmailLoader,
UnstructuredEPubLoader,
UnstructuredHTMLLoader,
UnstructuredMarkdownLoader,
UnstructuredODTLoader,
UnstructuredPowerPointLoader,
UnstructuredWordDocumentLoader,
)
from langchain.docstore.document import DocumentNext, we define the mapping b/w each extension and their respective langchain document loader. You can read document loader documentation for more available loaders.
# Map file extensions to document loaders and their arguments
LOADER_MAPPING = {
".csv": (CSVLoader, {}),
".doc": (UnstructuredWordDocumentLoader, {}),
".docx": (UnstructuredWordDocumentLoader, {}),
".enex": (EverNoteLoader, {}),
".epub": (UnstructuredEPubLoader, {}),
".html": (UnstructuredHTMLLoader, {}),
".md": (UnstructuredMarkdownLoader, {}),
".odt": (UnstructuredODTLoader, {}),
".pdf": (PDFMinerLoader, {}),
".ppt": (UnstructuredPowerPointLoader, {}),
".pptx": (UnstructuredPowerPointLoader, {}),
".txt": (TextLoader, {"encoding": "utf8"}),
}pNext, we define our single document loader.
def load_single_document(file_path: str) -> Document:
## Find extension of the file
ext = "." + file_path.rsplit(".", 1)[-1]
if ext in LOADER_MAPPING:
# Find the appropriate loader class and arguments
loader_class, loader_args = LOADER_MAPPING[ext]
# Invoke the instance of document loader
loader = loader_class(file_path, **loader_args)
## Return the loaded document
return loader.load()[0]
raise ValueError(f"Unsupported file extension '{ext}'")
git_dir = "../../../../privateGPT/"
loaded_document = load_single_document(git_dir+'source_documents/state_of_the_union.txt')
print(f'Type of loaded document {type(loaded_document)}')
loaded_document
The load_single_document function accomplishes the following steps:
- Extracts the file extension from the given file path.
- Retrieves the corresponding document loader and its arguments from the previously defined
LOADER_MAPPINGdictionary. - Creates an instance of the appropriate document loader.
- Loads the document using the instantiated loader.
- Returns the loaded document.
We can see that load_single_document returns a document of type langchain.schema.Document. Which according to the documentation consists of page_content (the content of the data) and metadata (auxiliary pieces of information describing attributes of the data).
def load_documents(source_dir: str, ignored_files: List[str] = []) -> List[Document]:
"""
Loads all documents from the source documents directory, ignoring specified files
"""
all_files = []
for ext in LOADER_MAPPING:
#Find all the files within source documents which matches the extensions in Loader_Mapping file
all_files.extend(
glob.glob(os.path.join(source_dir, f"**/*{ext}"), recursive=True)
)
## Filtering files from all_files if its in ignored_files
filtered_files = [file_path for file_path in all_files if file_path not in ignored_files]
## Spinning up resource pool
with Pool(processes=os.cpu_count()) as pool:
results = []
with tqdm(total=len(filtered_files), desc='Loading new documents', ncols=80) as pbar:
# Load each document from filtered files list using load_single_document function
for i, doc in enumerate(pool.imap_unordered(load_single_document, filtered_files)):
results.append(doc)
pbar.update()
return resultsThe load_single_documents function carries out the following steps:
- Initializes an empty dictionary called
all_files. - For each extension in the
LOADER_MAPPINGdictionary, it searches for all the files with that extension in the source directory and adds them to theall_fileslist. - Creates a new list named
filtered_filesby removing the files listed in theignored_fileslist from theall_fileslist. - Executes a parallel loading operation on all the files in the
filtered_fileslist using theload_single_documentfunction, and appends the results to the results list. - Returns the list of loaded documents.
loaded_documents = load_documents(git_dir+'source_documents')
print(f"Length of loaded documents: {len(loaded_documents)}")
loaded_documents[0]
You can see we have loaded the state_of_the_union.txt file from the privateGPT repo. As this is the only file in that directory the length of loaded documents is one.
1.2 Splitting the documents into smaller chunks
Now we have seen how we can load multiple documents of different extensions using the load_documents function. The next step is to look at process_document function which loads and splits large documents into smaller chunks.
from langchain.text_splitter import RecursiveCharacterTextSplitter
chunk_size = 500
chunk_overlap = 50
def process_documents(source_dir: str, ignored_files: List[str] = []) -> List[Document]:
"""
Load documents and split in chunks
"""
print(f"Loading documents from {source_dir}")
documents = load_documents(source_dir, ignored_files)
if not documents:
print("No new documents to load")
exit(0)
print(f"Loaded {len(documents)} new documents from {source_dir}")
## Load text splitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
## Split text
texts = text_splitter.split_documents(documents)
print(f"Split into {len(texts)} chunks of text (max. {chunk_size} tokens each)")
return texts
processed_documents = process_documents(git_dir+'source_documents')
The process_documents function performs the following steps:
- Loads all the documents from the
source_dirdirectory using theload_documentsfunction. - Initializes an instance of
RecursiveCharacterTextSplitterfrom thelangchain.text_splittermodule, providing thechunk_sizeandchunk_overlapparameters. This class is responsible for splitting a list of documents into smaller overlapping chunks. [RecursiveCharacterTextSplitterdocumentation]. - Uses the
split_documentsmethod of theRecursiveCharacterTextSplitterinstance to split the loaded documents into smaller chunks. - Returns the resulting list of the smaller document chunks.
1.3 Initializing the embedding model
Next, we load our embedding module which converts the smaller document chunks from previous steps to embeddings.
from langchain.embeddings import HuggingFaceEmbeddings
EMBEDDINGS_MODEL_NAME = "all-MiniLM-L6-v2"
embeddings = HuggingFaceEmbeddings(model_name=EMBEDDINGS_MODEL_NAME)
print("Testing on a single query.")
embedded_vector = embeddings.embed_query("What is your name?")
print(f"Size of embedded vector: {len(embedded_vector)}")
The given code snippet carries out the following steps:
- Imports the
HuggingFaceEmbeddingsfunction from thelangchain.embeddingsmodule. This function is responsible for loading and encapsulating the SentenceTransformers embeddings, which are used for generating dense vector representations of sentences. You can refer to the HuggingFaceEmbeddings documentation for more details. - Loads the
all-MiniLM-L6-v2model from thesentence_transformerslibrary. This model is specifically designed to map sentences and paragraphs into a 384-dimensional dense vector space. It is commonly utilized for tasks such as semantic search and similarity analysis.
We can see that our embedded vector on a sample query returns a 384 dimension vector.
1.4 Embed smaller text and save it in the vector database
The next step involves utilizing the document chunks and the embedding model to store the documents and their corresponding embeddings in a vector database.
from chromadb.config import Settings
from langchain.vectorstores import Chroma
PERSIST_DIRECTORY= git_dir+"db"
# Define the Chroma settings
CHROMA_SETTINGS = Settings(
chroma_db_impl='duckdb+parquet',
persist_directory=PERSIST_DIRECTORY,
anonymized_telemetry=False
)
## Create the embedding database
db = Chroma.from_documents(processed_documents, embeddings, persist_directory=PERSIST_DIRECTORY, client_settings=CHROMA_SETTINGS)
db.persist()
The given code snippet performs the following operations:
- It imports the
Settingsclass from thechromadb.configmodule and theChromaclass from thelangchain.vectorstoresmodule.
2. It creates an instance of the Settings class named CHROMA_SETTINGS, providing several configuration parameters:
chroma_db_implis set to'duckdb+parquet', specifying the implementation to be used for the Chroma vector database.persist_directoryis set to thePERSIST_DIRECTORYvariable defined earlier, indicating the directory where the vector database will be saved.anonymized_telemetryis set toFalse, indicating whether anonymized telemetry data should be collected.
3. It creates a vector database by calling the Chroma.from_documents() method. This method takes the following arguments:
processed_documents: The list of processed documents obtained from the previous step.embeddings: The embeddings object/model used to generate the document embeddings.persist_directory: The directory where the vector database will be persisted, specified by thePERSIST_DIRECTORYvariable.client_settings: The settings object (CHROMA_SETTINGS) containing configuration parameters for the vector database.
4. We use db.persist() to store the index for future retrieval task
## Test the semantic retrieval
db.similarity_search(query="What is the American Rescue Plan?", k= 4)
To test the retrieval of semantic similarity, we can use the similarity_search function. similarity_search function takes a text query as input and returns the top k=4 document chunks from the vector database.
2. Question & Answer Interface
Let’s explore the Q&A interface in more detail. The Q&A interface consists of the following steps:
- Load the vector database and prepare it for the retrieval task.
- Load a pre-trained Large language model from LlamaCpp or GPT4ALL.
- Prompt the user with a query and generate a response using the
RetrievalQApipeline fromlangchain.chains.

Let’s look at these steps one by one.
2.1 Load the vector database
First, we import the required libraries.
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
from chromadb.config import Settings
git_dir = "../../../../privateGPT/"
PERSIST_DIRECTORY= git_dir+"db"
EMBEDDINGS_MODEL_NAME = "all-MiniLM-L6-v2"
# Define the Chroma settings
CHROMA_SETTINGS = Settings(
chroma_db_impl='duckdb+parquet',
persist_directory=PERSIST_DIRECTORY,
anonymized_telemetry=False
)
embeddings = HuggingFaceEmbeddings(model_name=EMBEDDINGS_MODEL_NAME)
db = Chroma(persist_directory=PERSIST_DIRECTORY, embedding_function=embeddings, client_settings=CHROMA_SETTINGS)
retriever = db.as_retriever()
The given code snippet carries out the following steps:
- Loads the embeddings using the
HuggingFaceEmbeddingsfunction, which was previously used to create the embedding store. - Instantiates a Chroma vector database that was created earlier.
- Sets the vector database in retrieval mode.
## Testing retriever
retriever.vectorstore.similarity_search(query = "What is Amercian rescue plan?")
2.2 Load a pre-trained Large language model.
from langchain.llms import GPT4All
MODEL_PATH = git_dir+"models/ggml-gpt4all-j-v1.3-groovy.bin"
MODEL_N_CTX=1000
# Prepare the LLM
llm = GPT4All(model=MODEL_PATH, n_ctx=MODEL_N_CTX, backend='gptj', callbacks=None, verbose=False)
The code snippet above creates an instance of the GPT4All class named llm, which represents the Language Model (LLM) using the GPT-4All model. The constructor of GPT4All takes the following arguments:
- model: The path to the GPT-4All model file specified by the MODEL_PATH variable.
- n_ctx: The context size or maximum length of input sequences specified by the MODEL_N_CTX variable.
- backend: The backend to use for the LLM. In this case, it is set to ‘gptj’.
- callbacks: The callbacks to be used during the LLM execution. In this case, it is set to None.
- verbose: A boolean flag indicating whether to print verbose output during LLM execution. In this case, it is set to False.
2.3 Prompt the user with a query and generate a response
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever, return_source_documents=True)
query = "What is American rescue plan?"
res = qa(query)
answer, docs = res['result'], res['source_documents']
# Get the answer from the chain
# Print the result
print("\n\n> Question:")
print(query)
print("\n> Answer:")
print(answer)
# Print the relevant sources used for the answer
for document in docs:
print("\n> " + document.metadata["source"] + ":")
print(document.page_content)> Question:
What is American rescue plan?
> Answer:
The American Rescue Plan is a program that provides funding to schools to hire teachers and help students make up for lost learning due to the COVID-19 pandemic. It also provides economic relief for tens of millions of Americans by helping them put food on their table, keep a roof over their heads, and cut the cost of health insurance. The plan also helps working people by providing breathing room and giving them a little breathing room. It is a program that helps millions of families on Affordable Care Act plans save $2,400 a year on their health care premiums and combat climate change by cutting energy costs for families an average of $500 a year.
> ../../../../privateGPT/source_documents/state_of_the_union.txt:
The American Rescue Plan gave schools money to hire teachers and help students make up for lost learning.
I urge every parent to make sure your school does just that. And we can all play a part—sign up to be a tutor or a mentor.
Children were also struggling before the pandemic. Bullying, violence, trauma, and the harms of social media.
> ../../../../privateGPT/source_documents/state_of_the_union.txt:
It fueled our efforts to vaccinate the nation and combat COVID-19. It delivered immediate economic relief for tens of millions of Americans.
Helped put food on their table, keep a roof over their heads, and cut the cost of health insurance.
And as my Dad used to say, it gave people a little breathing room.
And unlike the $2 Trillion tax cut passed in the previous administration that benefitted the top 1% of Americans, the American Rescue Plan helped working people—and left no one behind.
> ../../../../privateGPT/source_documents/state_of_the_union.txt:
Look, the American Rescue Plan is helping millions of families on Affordable Care Act plans save $2,400 a year on their health care premiums. Let’s close the coverage gap and make those savings permanent.
Second – cut energy costs for families an average of $500 a year by combatting climate change.
> ../../../../privateGPT/source_documents/state_of_the_union.txt:
That’s why the Justice Department required body cameras, banned chokeholds, and restricted no-knock warrants for its officers.
That’s why the American Rescue Plan provided $350 Billion that cities, states, and counties can use to hire more police and invest in proven strategies like community violence interruption—trusted messengers breaking the cycle of violence and trauma and giving young people hope.Firstly, an instance of the RetrievalQA class named qa is created using the from_chain_type method. The RetrievalQA class is a chain specifically designed for question-answering tasks over an index. Please refer to the documentation for further details. The from_chain_type method takes the following arguments:
llm: The Language Model instance (llm) that was created previously.chain_type: A string representing the type of chain to be used. In this case, it is set to"stuff". There may be other available chain types specific to the question-answering scenario. Please consult the langchain documentation for more information.retriever: An instance of a Chroma database used to retrieve relevant documents for the given query.return_source_documents: A boolean flag indicating whether to return the source documents along with the answer. In this case, it is set toTrue.
Next, the qa instance is used to process a query. The Language Model (LLM) within the qa instance generates a response that includes the query, the answer, and the source documents used as context for generating the answer.
Finally, the answer and source documents are printed out for display.
Conclusion
In this blog post, we explored privateGPT, its implementation, and the code walkthrough for its ingestion pipeline and q&A interface. I hope this blog post has been valuable in understanding privateGPT and its implementation. I recommend my readers try privateGPT on their knowledge base.
I hope you enjoyed reading it. If there is any feedback on the code or just the blog post, feel free to comment below or reach out on LinkedIn.