
Abstract
With the increasing adoption of Function-as-a-Service (FaaS) oriented solutions, there is a growing interest in tools that facilitate benchmarking in these environments. The Orama framework has emerged as a standout solution, offering high configurability and scalability for provisioning, running benchmarks, and performing statistical analysis. This research presents the use of the distributed architecture of the Orama framework in evaluating the main public FaaS providers in situations of high competition. The experimental results demonstrate the framework’s effectiveness in orchestrating load tests with high levels of concurrency. Notably, the study reveals specific characteristics of the providers involved, with Alibaba Function showing excellent performance, registering the lowest average execution time and remaining free of failures. Google Cloud Function and AWS Lambda provide intermediate results at average runtime and report some failures. Meanwhile, Azure Function performs worst in average execution time and cold start. A deeper investigation into the Alibaba Function provider was conducted to verify if its performance maintains a more complex usage scenario, in this case, a use case merging FaaS and Database-as-a-Service.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Global end-user spending on public cloud services is expected to experience a substantial 20.7% growth, reaching a total of $591.8 billion in 2023, compared to $490.3 billion in 2022 [1]. This remarkable projection underscores the robustness of the computing industry in this domain. While the primary cloud models, such as Infrastructure-as-a-Service (IaaS) [2] and Platform-as-a-Service (PaaS), continue to attract significant investment, other models that embrace the concept of Everything-as-a-Service (XaaS) [3] also exhibit promising growth. Notably, serverless-based cloud computing models, like Function-as-a-Service (FaaS) [4], have emerged as the leading programming paradigm for the next generation of cloud computing.
Recently, there has been a growing interest in evaluations and benchmarking tools to analyze cloud service providers’ performance. Notable examples of such tools include Sebs [5], PanOpticon [6], FaaS-Dom [7], BeFaaS [8], and the Orama framework [9, 10]. As cloud computing continues to evolve, providers offer a wide range of strategies, and services are deployed in various regions, making it crucial for these studies to adapt dynamically to real-world scenarios. To address this need for adaptability, this research applies the distributed architecture for the Orama framework [9] to explore a broader range of FaaS scenarios in the main public providers. Leveraging a master/workers architecture, workloads can be effectively distributed among multiple instances, including those geographically dispersed, thereby facilitating the expansion of assessable levels of concurrency.
In experiments, it was verified that the distributed architecture allows high requests. In addition, it was found that the performance calculated between the scenario in which workers were in the same region, and the scenario in which the workers were geographically spread maintained equivalent results, demonstrating that the separation of workers in the proposed architecture does not affect the analysis of the results. In addition, it was possible to observe behaviors intrinsic to the services, such as the superior performance demonstrated by Alibaba Cloud Functions. AWS Lambda and Google Cloud Function both had intermediate results. On the other hand, Azure services obtained the worst results, presenting high average execution times and cold start.
Since Alibaba Function demonstrated a superior result in the tests, a study was conducted specifically with Alibaba Function to determine if, in a more complex scenario involving a Database-as-a-Service service from the provider itself, the good results of Alibaba Function would be maintained or present some significant change that could give rise to some further deepening. This last experiment confirmed the results presented in the previous round.
This article is divided into six parts, the first being this introduction. “Background” section presents the theoretical foundation that supports the work. “Distributed Orama Framework” section describes the distributed implementation of the Orama framework. “Results” section shows the results obtained. “Related Works” section presents the related works, and finally, “Conclusion and Future Work” section presents the conclusions and future work.
Background
Following the NIST [2] definition of traditional cloud models in 2011, which included IaaS, PaaS, and SaaS, major public cloud providers started using different acronyms to name their services. This led to the emergence of the term “XaaS”, encompassing Everything-as-a-Service [3]. In 2014, AWS introduced Lambda, pioneering the Function-as-a-Service model [11]. In the FaaS paradigm, customers provide a piece of code to the provider, usually written in a language supported by the platform. Additionally, clients configure triggers to activate the function, which can be triggered by other services within the provider’s platform or through a REST API.
Function-as-a-Service is designed to operate state-independently, which imposes certain limitations on customers, including restrictions on allocable virtual CPUs (vCPUs), available RAM, and maximum execution time for functions. However, one of the key differentiators that sets FaaS apart from other cloud service models is its unique billing method. Unlike the Infrastructure-as-a-Service (IaaS) model, where customers are charged based on the execution time of instances, FaaS follows a “pay-as-you-go” approach. This means that customers are billed solely based on the activation of the service and the duration of its execution, making it a cost-effective option for executing small, short-lived functions.
Leading public cloud providers have recognized the significance of FaaS and offer their respective FaaS offerings. AWS Lambda, being the pioneer in this domain, leads the way, followed by other major players such as Azure with its Azure Function (AZF), Google Cloud Platform (GCP) with Google Cloud Function (GCF), and Alibaba Cloud with Alibaba Function Compute (AFC). Additionally, providers like Oracle, Digital Ocean, and IBM provide their own FaaS options, showcasing this serverless computing paradigm’s widespread adoption and growing popularity in the cloud market.
Given the abundance of FaaS options available, it becomes crucial to comprehend how providers’ adopted strategies impact service delivery. Given the vast number of regions where major providers are situated, variations in implementations between providers or regions might cater to diverse requirements or, on the contrary, pose hindrances, infeasibility, or high costs. As these strategies are closely guarded trade secrets, the most effective way to uncover and analyze them is by executing benchmarks.
Given these environments’ highly dynamic and constantly evolving nature, benchmarking solutions must be highly configurable, like the Orama Framework, to accurately represent the challenges encountered in real-world scenarios. Consequently, developing solutions catering to the current multi-cloud context should prioritize seamlessly incorporating new providers and their services as they enter the market. This calls for adopting a cloud orchestration solution to ensure efficient management and utilization of these diverse cloud offerings.
Infrastructure Tools
Terraform [12] is a cloud orchestrator designed to facilitate seamless integration with various virtualization and automation platforms, focusing on cloud environments. With Terraform, users can generate lightweight and portable infrastructure definition artifacts, making incorporating these configurations into other solutions simple. While other cloud orchestration solutions like Heat [13] and CloudFormation [14] offer similar approaches to Terraform, a comparative evaluation conducted in [15] revealed that Terraform delivers superior performance and results.
Performance testing [16] is a crucial type of testing that aims to assess the responsiveness, reliability, throughput, interoperability, and scalability of a system or application under various workloads. It involves evaluating the speed and effectiveness of computer systems, networks, software applications, and devices. Performance testing can be conducted on various components, including software applications, system resources, targeted application components, and databases. Automated test suites, such as JMeter [16], are commonly used for performance testing, as they allow for repeatable simulations of different load conditions, such as normal, peak, and exceptional loads. This type of testing helps ensure that a system or application meets the performance specifications claimed by its vendor. In today’s technology landscape, dealing with large and rapid information flows is essential, and any service instability can result in data loss. Queuing mechanisms are employed to ensure the correct processing of requests.
Apache Kafka [17] is a powerful and scalable distributed streaming platform designed to store and process data streams. The Kafka cluster stores data streams, which consist of sequences of continuously produced messages/events from applications and consumed by other applications sequentially and incrementally. The Connect API ingests data into Kafka and exports data streams to external systems like distributed file systems and databases. For data stream processing, the Streams API allows developers to define sophisticated stream processing pipelines that read input streams from Kafka and write results back to it. Apache Kafka aligns with the microservices paradigm, breaking complex solutions into smaller, manageable processes. Container-oriented environments are employed to handle numerous services without managing multiple virtual machines.
Docker [18] plays a vital role in containerization, enabling the packaging of software packages along with their configuration and setup details into containers. These containers can be rapidly deployed without compatibility issues. Docker has been reported to speed up the deployment of software components by 10–15 times. Modern applications often consist of multiple components or containers. For example, a web application may require both a web server and a database component. Docker Compose [18] is a natural extension of Docker that allows developers to compose complex applications. Compositions of components are specified in a Docker Compose file detailing Docker images, configurations, and the relationships between components. The multitude of services supported by container environments can generate vast amounts of data, necessitating sophisticated processing techniques to derive meaningful insights.
Statistical Analysis Tools
Statistical analysis of benchmark results plays a crucial role in understanding various phenomena. One powerful approach for this purpose is factorial design [19], which enables the identification of the impact of mapped factors on the results. By analyzing different factors’ variations in a given scenario, factorial design helps determine if they have a statistically significant effect on the results. Moreover, this method can reveal the presence of previously unmapped factors that might significantly influence the outcomes.
Another valuable statistical analysis tool is the paired t-test [20]. This test assesses the statistical significance of the difference between two results and provides a measure of confidence associated with that difference. Employing the paired t-test can determine whether the difference between two results is meaningful or insignificant. In the latter case, the results can be considered statistically equal.
This research leverages various tools, including Terraform, JMeter, Apache Kafka, Docker, factorial design, and t-test, to implement a specific benchmark solution for a function-as-a-service environment that closely resembles real-world scenarios. These tools collectively aid in proposing a distributed architecture for the Orama framework, with detailed descriptions to be presented in the subsequent section. This architecture aims to enhance the accuracy and representativeness of benchmarking in FaaS environments, providing valuable insights for performance evaluations and comparisons.
Although the statistical analysis tools incorporated into the Orama Framework can assist in observing various events, they are subject to some limitations. The t-test can only analyze benchmarks of up to 30 repetitions, using the t-distribution that supports a maximum of 30 samples. Furthermore, the factorial design allows the verification of only two factors (level of competition and provider). Therefore, the influence of other factors is not adequately identified, being diluted in the sampling error. Still, statistical analyses provide valuable insight into understanding the data dynamics generated in benchmarks.
Distributed Orama Framework
The Orama framework [9, 10] is specifically designed as a benchmarking tool for Function-as-a-Service environments, with a strong focus on cloud environments aligned with the FaaS paradigm. Although it can run benchmarks on other environments, its primary purpose revolves around evaluating FaaS solutions. One of the key features of the Orama framework is its seamless integration with Terraform, which allows for automated provisioning of environments. Incorporating new cloud providers becomes as simple as creating a Terraform infrastructure definition artifact. Similarly, de-provisioning environments can be efficiently performed using Terraform automation facilitated by the Orama framework.
With the Orama framework, the entire process of executing benchmarks is automated based on user-defined settings. It allows users to create multiple test scenarios, enabling parameter variations like the concurrency level, the number of repetitions for each scenario, the intervals between tests, and the execution of warm-up requests. Warm-up requests help observe the cold start phenomenon, a common and impactful aspect in FaaS environments. Overall, the Orama framework streamlines the benchmarking process for FaaS environments, providing an efficient and customizable tool to evaluate performance and behavior under different conditions.

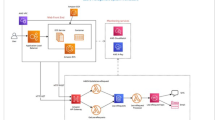
Distributed Orama framework architecture [10]
The Orama framework offers pre-configured use cases that can be seamlessly deployed to major cloud providers without requiring user intervention. These use cases cater to various needs, ranging from simple calculators designed to validate service implementation and correctness to more complex scenarios that involve utilizing other cloud platform services, such as object storage and databases. Users have the flexibility to parameterize these use cases, enabling them to provision different configurations, including variations in the amount of allocable memory and the specific region within the cloud provider for deployment.
In the standalone version of the framework discussed in [9], all components are implemented within a containerized environment, which includes the “benchmarker” responsible for triggering bursts of requests to simulate real-world demands on the environments. However, this approach has some limitations. The level of concurrency that the Orama framework can simulate in the environment is constrained by the available resources on the machine where it is installed. Furthermore, test requests may encounter competition with framework management traffic as framework components communicate via HTTP. These factors can potentially limit the scalability and accuracy of the benchmarking process.
The Orama framework provides convenient pre-configured use cases for easy deployment on major cloud providers. However, in its standalone version, certain limitations related to resource availability and potential competition among framework components must be considered when conducting performance evaluations in this environment.
In [10], a distributed architecture for the Orama framework is presented, as shown in Fig. 1. In the architecture, it is observed that the benchmarker component is deployed outside the main environment. Therefore, its installation can occur in another instance. Furthermore, the number of instances of the benchmarker is variable and can be adjusted to the characteristics of the test to be performed. It is possible, for example, to concentrate the benchmarker’s workers in the same region or to distribute them among several regions. It is also possible to include several workers whose load distribution of requests prevents the saturation of resources on the machine, preventing the occurrence of faults attributed to the test execution worker.
While in the standalone version, the execution of benchmark requests occurs in the same instance as the framework management, in the distributed version, these requests occur in an instance with dedicated resources. This way, it is possible to scale the capacity to execute requests quickly. Once new worker nodes are incorporated, the queue manager starts forwarding blocks of requests to it, expanding the platform’s ability to execute HTTPS requests without burdening communication between the management node and the worker nodes, which occurs through Kafka.

Kafka workflow in Orama framework [10]
The communication between remote benchmarkers (workers) and the main Orama framework environment (master), consisting of frontend, backend, database, and orchestrator components, is facilitated through Apache Kafka, as illustrated in Fig. 1. Kafka manages three types of “topics” to facilitate this communication. The “Health check” topic allows remote workers to notify the master that they are available and ready to receive triggers for executing benchmarks. Once a worker’s health status is updated, it becomes eligible to participate in the distribution of workloads for a specific benchmark. Subsequently, the master’s backend includes a topic with the unique identifier (uuid) of the corresponding worker in Kafka. The remote worker consumes this topic and executes the benchmark tasks assigned to it, as illustrated in Fig. 2. Upon completing the benchmark execution, the remote worker records the partial results and inserts them into a third Apache Kafka topic. These partial results are then consumed by the master’s backend for further processing and analysis. It is worth noting that the Orama framework implements a balancing mechanism to ensure an equitable distribution of requests assigned to each worker for execution in the target environment. This ensures that the benchmarking process remains efficient and reliable.
Figure 2 shows a scenario with three workers and a request to run a benchmark with 2048 concurrent requests. It is possible to notice that all workers are asked for 682 requests, which adds up to 2046 requests. This leaves 2 requests assigned to one of the workers, as shown in Fig. 2 the “Remote Benchmarker Worker 01”. As soon as the backend perceives receiving all partial results, it promotes consolidating the results. If these results do not appear within a configured timeout, the respective partial result is assigned a failure result.
Once the results are consolidated, it is possible to create factorial designs combining two benchmarks and two levels of concurrence. If the benchmarks involve two different providers, it will be possible to observe the influence of the providers on the results, as well as the difference from the concurrence. Using the factorial design established by the Orama framework, it is possible to identify whether the strategies adopted by the providers impact the results and whether the level of concurrence is the factor whose influence prevails. It is still possible to identify the existence of some other factors apart from the provider and the level of concurrence influencing the results, in this case the portion of the influence related to the statistical error will be significantly high.
The distributed architecture of the Orama framework presented in [10] opens up a wide range of possibilities for running benchmarks on FaaS environments. At this moment of leveraging this approach, it is essential to have a tool available that allows the evaluation of environments delivered by providers, including high levels of concurrence and distributed customers, whose characteristics are more similar to critical situations in the real world experienced by solutions supported by FaaS environments.
The next section will present the results of an experiment using the aforementioned architecture. The capabilities of the Orama framework using a distributed approach and the insights obtained from the experiment will be illustrated.
Results
The Orama framework makes it possible to run benchmarks on a FaaS environment in different scenarios, especially with the introduction of the distributed architecture presented in [10]. To explore some possibilities of running benchmarks, two experiments were designed to observe the architecture’s behavior and obtain insights into FaaS environments. Details of how the experiment was conducted will be presented in “Methodology” section, while an analysis of the results is provided in “Outputs Analysis” section.
Methodology
The main objective of the experiments is to analyze the behavior of the distributed architecture of the Orama framework, as well as to observe the behavior of public FaaS providers and high competition situations. Two use cases pre-configured by the Orama Framework (Calculator and DBaaS) were selected for this. The first use case is a simple calculator, whose objective is only to test the implementation and processing flow of the functions in each provider without considering integrations with other services. This simple use case was used in the first experiment in two scenarios: with the Orama workers deployed in the same geographic regions where the provider functions were deployed, as shown in Fig. 3a, that is, they were concentrated in the same region. Another scenario of the first experiment was to place Orama’s workers in different global positions, that is, distributing the bursts over the providers from different points on the planet, as shown in 3b. These scenarios make it possible to observe the behavior of FaaS providers in the face of realistic demand situations, whether coming from close customers or more distant customers.

Experiments scenarios
In a second experiment, Orama framework workers were distributed globally, as shown in Fig. 3c. However, only the Alibaba Cloud provider was involved in this experiment, given that its performance in the first experiment printed the best results. Therefore, a more complex scenario was applied, involving a use case with another cloud service, DBaaS. This experiment allowed viewing a more realistic use case, in addition to a realistic demand, since the joint use of FaaS and DBaaS is quite common for business needs.
Both scenarios were subjected to concurrent requests, from just one simultaneous request up to 2048 with exponential growth. Thus, the FaaS of each provider were submitted individually to loads of 1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, and 2048. Notably, the tests performed with the Orama standalone architecture framework were limited to up to 512 simultaneous requests, noting the limitations of opening a connection with FaaS services imposed by the instance in which the Orama framework was installed. As 2048 was the maximum level of the first experiment, a quantity of 4 benchmarker workers was defined so that each one was responsible for carrying out a maximum of 512 concurrent requests. Furthermore, each battery of tests with different levels of concurrency was repeated 10 times to establish a statistical data mass for further analysis. In the second experiment, another level of concurrency was added, in this case, 4096 simultaneous requests, to expand the understanding of the behavior of Alibaba Cloud in the face of high demand.
In the first scenario (concentrated workers) of the first experiment, the Orama framework was deployed on an instance of GCP’s Compute Engine in the US-East region with 16GB of RAM and 4 vCPUS. Each of the four workers was also deployed in the same GCP region, the servers had 4GB of RAM and 2 vCPUS each. For the second scenario of the first experiment and the second experiment, the master installation of Orama framework was kept on the same instance in the US-East GCP region as used in the first scenario. However, the workers were spread out in other GCP regions such as: asia-northeast1 (Tokyo, Japan), US -West (The Dalles, Oregon, United States), europe-west2 (London, England), and southamerica-east1 (Osasco, Brazil). All instances of GCP used in this experiment ran Debian 11 as the operating system. The FaaS that was the experiment’s target in both scenarios were configured to be deployed in the respective East American regions at each provider, namely AWS Lambda, AZF, GCF, and AFC.
At the end of the execution of the repetitions of both experiments, factorial designs and t-tests were created to analyze the effects of the difference between the providers and the difference between the lowest level of concurrency (only one request) and the highest level, with 2048 concurrent requests in the first experiment and 4096 in the second experiment. The analysis of the obtained results is presented in the next section.
Outputs Analysis
Table 1 presents the consolidated result of all eight test scenarios conducted in the first experiment. It is possible to observe that the provider whose scenarios had the lowest average execution times was AFC, highlighted in bold. Next in very close range are the average execution times for AWS Lambda and GCP. Finally, the average execution times for AZF were the highest in this experiment. In addition, in Table 1, it is also possible to observe that the scenarios with distributed workers have generally higher averages than those found in the scenario with workers concentrated in the same region. This is the expected result since the greater geographic distance between workers and target FaaS should raise averages by introducing higher latency to traverse the network.
Figure 4a presents a comparative result between the scenarios involving AWS Lambda in the first experiment. It may be seen that the average execution time of both scenarios in AWS Lambda follows the growth of the concurrency level from the previous level to the maximum (2048 concurrent requests) when there is a small drop in the average. This decrease in the average execution time after 1024 indicates that, when faced with growing demand, the provider reinforced the service infrastructure to maintain its quality in terms of execution time. Despite this effort by the provider, failures occurred from 256 concurrent requests, as shown in Fig. 4b, which shows the percentage failure rates at each concurrency level. To corroborate the indication that the provider promoted an escalation before 2048 requests and the average time, the failure rate also showed a reduction.
Figure 4c, d show the average execution times of the scenarios involving the GCF and their respective failure rates at each concurrency level, respectively, in the first experiment. It is possible to observe that the graph of the average execution time of the GCF is similar to the same graph for AWS Lambda, in which the average time accompanies the growth of the concurrency level until the provider’s intervention causes a decrease in the average time. However, GCF’s average time threshold is lower than AWS Lambda’s. While in AWS Lambda the peak point is 7.3 s (at 1024 in the distributed scenario), in CGF the peak is recorded at 5.7 s (at 1024 in the distributed scenario). This proximity between AWS Lambda and GCF average times demonstrates a strategic equivalence between providers. Despite this, concerning the failure rate, failures in GCF started only after 1024 requests, while AWS Lambda already had failures at 256. However, the level of failures recorded by GCF was higher than AWS Lambda, because while in AWS Lambda the failures peaked at 8% of requests, in GCF these failures reached around 20%. Another difference in the AWS Lambda and GCF results is the continuous increase in failures demonstrated in the GCF distributed scenario. This indicates that the provider’s monitoring layer had greater difficulty in dealing with requests from different regions than those whose origins were the same.

First experiment comparative results
Unlike AWS Lambda and GCF, which showed a point of reduction in the average execution time, AZF, as shown in Fig. 4e, maintained a continuous growth in the average execution time, registering the highest average times in the first experiment. This indicates that in the AZF environment, there was no reinforcement of the infrastructure as demand grew, although this is a FaaS premise. Despite the high average time, AZF recorded a low failure rate, with failures occurring in only 3% of the 2048 concurrent requests in the distributed scenario, as seen in Fig. 4f.
Figure 4g shows the average AFC execution times. It is possible to observe three points where the provider seems to have reinforced the infrastructure: from 2 to 4 requests, 8 to 16, and 256 to 512. This meant that the provider maintained the lowest average times of the experiment and did not present an increasing curve of the average time, as occurred with the other providers. In addition, there was no failure during the ten repetitions of the test batteries, as shown in Fig. 4h. The AFC result also shows the expected result of the experiment, in which it is possible to observe the same behavior in both scenarios, with workers concentrated in the same region and distributed workers differing only in the average level.

Warm-up times in the first experiment. (1) \(\rightarrow \) Scenario 1 (concentrated workers, and (2) \(\rightarrow \) Scenario 2 (distributed workers)
Another interesting aspect to be analyzed in the first experiment is the cold start phenomenon—the time it takes the provider to put its FaaS into operation for the first time or after a certain period of inactivity. Figure 5 provides the warm-up times for all scenarios of the first experiment. This is the first request made before the battery tests start. The arcing times showed a big difference between AZF and the other providers. While AWS Lambda, GCF, and AFC recorded warm-up times around 1 s, AZF took 89 s in the distributed scenario and 103 s in the concentrated scenario. This difference shows that the AZF deployment strategy is considerably different from the others, and this can significantly impact the performance of applications supported by this service since, after some downtime, AZF FaaS will have a much higher response time than usual, and this will certainly negatively impact the user experience.

Factorial design results in the first experiment
To understand the impact of the provider and concurrence factors on the results of the first experiment, six factorial designs were elaborated comparing the four providers with each other and the minimum and maximum concurrence levels (1 and 2048), as shown in Fig. 6. In Fig. 6a, b d, it is possible to observe the predominance of the concurrence factor, to the detriment of the provider factor, which indicates that in these benchmark results, the providers’ strategies influenced the result less than the differences between the concurrences. In Fig. 6c, e f, the provider factor is predominant, and this corroborates the results shown previously for average execution time and failure rate since AFC participates in both factorial designs.
The result of the t-tests for the six comparisons between the providers in the first experiment is shown in Table 2. It is possible to notice that all the differences between the average results were considered statistically relevant with a 99.95% confidence level. It may be stated that these differences are not irrelevant and may be considered defining the benchmarks’ result.
The first experiment’s results indicated the prominence of AFC, given that its performance in processing FaaS functions with low complexity (calculator) proved to be faster and more reliable than the other providers. However, real-world use cases typically use more complex functions that integrate with other vendor solutions like database solutions such as DBaaS. In the second experiment, AFC was subjected to concurrency demands for a FaaS function that integrates with an Alibaba Cloud DBaaS service (Fig. 7).
Table 3 and Fig. 3 show the results of the average execution times of each activation of the functions implemented in the AFC in all their respective regions involved in the second experiment. It is worth mentioning that the differences in the levels of each result are irrelevant as they may be subject to differences in network latency. The most important thing is to realize that in all regions, the Alibaba Cloud FaaS service maintained similar response times, whether with low demand (1 request) or in the face of high levels of competition (4096 concurrent requests). This demonstrates that the provider applies a transversal policy between its regions and thus delivers uniform performance, regardless of which region its customers request the service for.

AFC regions execution times in the second experiment with DBaaS use case
As observed, the average response times of the AFC services in the second experiment remained at similar levels, despite the increase in demand. However, when observing errors, shown in Fig. 8, a result different from that found in the first experiment is perceived. When the use case was simple, just one calculator, the AFC services did not show errors, even in the face of high demand, such as 2048 concurrent requests. On the other hand, when the use case involves another provider service, in this case, a DBaaS service, the AFC services failed from 512 concurrent requests (US-East). For concurrency levels above 512 concurrent requests, all AFC regions involved in the second experiment failed, reaching 17% of the number of requests in Asia.
It is important to note that each region of the AFC showed a different behavior in the second experiment. In US-East, the error rate remained at 2% between 512 and 2048 requests, increasing to around 7% at 4096 concurrent requests. In the US-West region, there was an oscillation of failures, with the occurrence of about 6% of errors at 1024 and 4096 requests, while at 2048, no errors were registered, showing that some intervention by the provider in that region had an effect after 1024 and returned at 4096 concurrent requests. Europe, Asia, and Oceania regions recorded peaks of around 16% of failures in 2048 of competition. The European and Oceania regions returned to the 10% threshold in the next competition tier (4096). The Asian region increased to around 17% at 4096 concurrent requests.

AFC regions failure rates in the second experiment with DBaaS use case
The appearance of failures in the second experiment indicates that real life is a little tougher for the AFC than the first experiment, which was able to subject the providers. Even so, the AFC results are remarkable because even using a more complex use case, which introduces features that are not only managed by FaaS services, such as DBaaS technical strategies, it was able to record equivalent response times and reliable up to 512 concurrent requests, which is generally very acceptable for most real-world solutions.
It is worth mentioning that the differences in execution time found in the results of this work can be experienced in real environments. These differences can significantly impact the business that is the subject of the computational operation since non-functional requirements can be compromised, such as the maximum waiting time for routine execution and triggering timeouts, among other possibilities for failures. This may result in financial and/or reputational losses for the organizations that are eventually impacted.
The results of this work can serve as input in decision-making processes according to the characteristics and requirements of the real use case. For example, if the use case requires high reliability of the FaaS service, AFC would be the best option among the evaluated providers since it did not present failures. On the other hand, if the use case is very sensitive to cold start, then the Azure provider should be avoided, as it presents high values.
Related Works
This article presents the distributed architecture of the Orama framework executing benchmarks in FaaS environments, including the usage of DBaaS in the composition of the use case. The related work is discussed from the perspective of benchmarking FaaS platforms in general and on serverless benchmark frameworks. A comparison between related works is presented in Table 4.
In the paper [21], the authors used a microbenchmark to investigate two aspects of the FaaS: the differences in observable behavior concerning the computer/memory relation of each FaaS implementation by the providers and the complex pricing models currently in use. They used AWS, IBM, GCP, Azure, and OpenWhisk in their evaluation. However, as presented in this work, the authors did not present an evaluation of their microbenchmark’s performance in different providers’ regions, nor with different levels of concurrence.
The quality impacts of operational tasks in FaaS platforms as a foundation for a new generation of emerging serverless big data processing frameworks and platforms are evaluated in [22]. The authors presented SIEM, a new evaluation method to understand and mitigate the quality impacts of operational tasks. They instantiated SIEM to evaluate deployment package and function configuration changes for four major FaaS providers (AWS, IBM, GCP, and Azure), but only in European regions for the same level of concurrence. In this work, on the other hand, several levels of concurrence are evaluated using two different worker approaches (concentrated and distributed).
PanOpticon [6] provides a comprehensive set of features to deploy end-user business logic across platforms at different resource configurations for fast evaluation of their performance. The authors conducted a set of experiments testing separate features in isolation. An experiment comprising a chat server application was conducted to test the tool’s effectiveness in complex logic scenarios in AWS and GCP. In this work, however, the range of tests that the Orama framework can evaluate was extended beyond the execution of benchmarks on AWS and GCP to include the execution of benchmarks on Azure and Alibaba, two other important players in this market.
FaaS-dom [7] is a modular set of benchmarks for measuring serverless computing that covers the major FaaS providers and contains FaaS workloads (AWS, Azure, Google, and IBM). A strong element of FaaS-dom’s functions is that they were created in various languages and for various providers. However, the operations that the FaaS-dom functions carry out can be viewed as basic, and they lack Orama’s approach to integration with other cloud services.
BeFaaS [8] offers a benchmark methodology for FaaS settings that is application-centric and focuses on evaluating FaaS apps using real-world and prevalent use cases. It offers enhanced result analysis and federated benchmark testing, where the benchmark application is split across several providers. However, It does not provide a superior approach to statistical analysis, such as the factorial design or t-test covered by this study.
In the paper [23], the authors analyzed the architectures of four major FaaS platforms: AWS Lambda, AZF, GCP, and IBM Cloud Functions. The research focused on the services’ capabilities and limitations for highly parallel computations. The design of the platforms revealed two important factors influencing their performance: virtualization technology and scheduling approach. On the other hand, this work focuses on investigating the differences in performance of the main providers with different levels of concurrence.
In the Serverless Benchmark Suite (Sebs) [5], typical workloads are chosen, the implementation is tracked, and the infrastructure is assessed. The benchmark’s applicability to several commercial vendors, including AWS, Azure, and Google Cloud, is guaranteed by the abstract concept of a FaaS implementation. Based on the executed test cases, this work assesses variables including time, CPU, memory, I/O, code size, and cost. However, unlike the Orama framework used in this work, their solution cannot work in a distributed mode.
In [24], the authors run a test flow employing micro benchmarks (CPU, memory, I/O, and network) and macro benchmarks to evaluate FaaS services from AWS, Azure, GCP, and Alibaba in detail (multimedia, map-reduce and machine learning). The tests used specific Java, Node.js, and Python methods that investigated the benchmarking attributes to gauge resource usage efficiency and initialization delay. However, they do not present evaluations in different levels of concurrence nor perform a statistical analysis using factorial design and t-test as is done in this work.
Although the aforementioned work presents an ad hoc evaluation of the providers, its scalability and manageability are limited to the parameters used in the work. On the other hand, this article uses a fully manageable solution prepared for incorporating new providers and use cases.
These solutions present structures for executing specific benchmarks for certain scenarios with limited customization and extension capabilities. This restricts the scope of scenarios that eventual tests can cover, providing a partial view of the performance of the environments evaluated by these approaches. This fact can trigger misinterpretations and lead to incorrect decision-making. A benchmark solution must have the coverage and flexibility necessary to adequately evaluate solutions, especially in a scenario as dynamic as FaaS.
In [10], the distributed architecture of the Orama framework was presented, with which it is possible to perform benchmarks with high levels of concurrency on a FaaS environment, as well as configure the load to be triggered from different locations on the globe, considerably expanding the range of possibilities for benchmarks against state-of-the-art tools. Experiments were carried out that allowed the visualization of the behaviors of FaaS providers from AWS, GCP, Azure, and Alibaba in a simple scenario but a realistic and everyday use case that merged the FaaS service with another cloud service, such as the DBaaS that is explored in this work.
Conclusion and Future Work
In this work, the distributed architecture of the Orama framework, which allows one to perform benchmarks with high levels of concurrency on a FaaS environment and configure the load to be triggered from different locations on the globe, was applied. The goal was understand the behavior of the main public FaaS providers, such as AWS Lambda, Google Cloud Functions, Azure Functions, and Alibaba Functions Compute.
The Orama framework allows the visualization of different scenarios for the same use case, especially for concurrency levels above 512 concurrent requests. This is the amount observed as the safest maximum for management by an intermediate configuration instance. In addition, it was evidenced that the Orama framework, in its distributed architecture, can visualize the same behavior as the FaaS provider when subjected to a concentrated and distributed approach of bursts of requests and eventual differences.
In the experiments, it was also evident that the AFC FaaS delivers greater consistency in average execution time and occurrence of failures, followed by AWS Lambda and CGF, which registered close results, and finally, the AZF results with high average execution times and cold start. In an experiment using a more common solution in real environments, which use multiple technologies, the good performance of the AFC provider was ratified, which maintained predictable levels of response, even in the face of high demand. In addition, with up to 512 simultaneous requests, the AFC response proved very reliable.
The results obtained in this work are limited to the scenarios analyzed. They can be affected by changing parameters in the benchmarks, such as concurrency level, distribution of workers and their geographic positions, and adjacent services of the respective clouds.
In future work, other providers, such as IBM, Huawei, Tencent, and Oracle, will be integrated into the Orama framework to expand the coverage of the analyses presented in this work. Furthermore, experiments that include a larger number of distributed workers can evaluate even higher levels of concurrency. Furthermore, evolutions in the Orama framework will allow the analysis of benchmark results using percentiles.
References
Gartner: Gartner forecasts worldwide public cloud end-user spending to reach nearly 600 billion in 2023 (Online); 01-Jan-2023; https://tinyurl.com/3z72zebw; 2022.
MELL P, Grance T. The NIST definition of cloud computing. National Institute of Standards and Tecnology; 2011.
Duan Y, Fu G, Zhou N, Sun X, Narendra NC, Hu B. Everything as a service (XaaS) on the cloud: origins. Curr Future Trends. 2015;00:621–8.
Schleier-Smith J, Sreekanti V, Khandelwal A, Carreira J, Yadwadkar NJ, Popa RA, Gonzalez JE, Stoica I, Patterson DA. What serverless computing is and should become: the next phase of cloud computing. ACM. 2021;64(5):76–84.
Copik M, Kwasniewski G, Besta M, Podstawski M, Hoefler T. SeBS: A serverless benchmark suite for function-as-a-service computing, 2021.
Somu N, Daw N, Bellur U, Kulkarni P. Panopticon: a comprehensive benchmarking tool for serverless applications. In: 2020 COMSNETS; 2020. p. 144–51.
Maissen P, Felber P, Kropf P, Schiavoni V. Faasdom. In: Proceedings of the 14th ACM international conference on distributed and event-based systems; 2020.
Grambow M, Pfandzelter T, Burchard L, Schubert C, Zhao M, Bermbach D. BeFaaS: an application-centric benchmarking framework for FaaS platforms; 2021.
Carvalho L, Araujo A. Orama: A benchmark framework for function-as-a-service. In: Proceedings of the 12th CLOSER. SciTePress, Online; 2022. INSTICC. p. 313–22.
de Carvalho LR, Kamienski B, Araujo A. FaaS Benchmarking over Orama Framework’s Distributed Architecture. In: Proceedings of the 13th international conference on cloud computing and services science, vol 1: CLOSER. SciTePress, Prague; 2023. INSTICC. p. 67–77.
Motta, MADC, Reboucas De Carvalho, L, Rosa, MJF, Favacho De Araujo, AP. Comparison of FaaS platform performance in private clouds. In: Proceedings of the 12th CLOSER. SciTePress, Online; 2022. INSTICC. p. 109–20.
HashiCorp: Terraform: Write, Plan, Apply (Online); 11-Aug-2021. https://www.terraform.io; 2021. https://www.terraform.io/. Accessed 2021-05-31.
Gupta PR, Taneja S, Datt A. Using heat and ceilometer for providing autoscaling in openstack. JIMS8I Int J Inform Commun Comput Technol. 2014;2(2):84–9.
Wittig M, Wittig A. Amazon web services in action. New York: Simon and Schuster; 2018.
Carvalho LR, Araujo APF. Performance comparison of terraform and cloudify as multicloud orchestrators. In: 2020 20th IEEE/ACM CCGRID; 2020. p. 380–9.
Erinle B. Performance testing with JMeter 2.9. Packt Publishing Ltd, United Kingdom; 2013. ISBN: 9781782165842.
Sax MJ. In: Sakr, S., Zomaya, A. (eds.) Apache Kafka. Cham: Springer; 2018. p. 1–8. ISBN: 978-3-319-63962-8.
Ibrahim MH, Sayagh M, Hassan AE. A study of how docker compose is used to compose multi-component systems. Empir Softw Eng. 2021;26(6):128.
Jain R. The art of computer systems: Techniques for experimental design, measurement, simulation, and modeling. London: Wiley; 1991. ISBN:13.978-0471503361.
Hsu H, Lachenbruch PA. Paired \(t\) test. London: Wiley; 2014.
Back T, Andrikopoulos V. Using a microbenchmark to compare function as a service solutions. In: ECSOCC. London: Springer; 2018. p. 146–60.
Kuhlenkamp J, Werner S, Borges MC, El Tal K, Tai S. An evaluation of FAAS platforms as a foundation for serverless big data processing. In: Proceedings of the 12th IEEE/ACM. UCC’19. ACM, NY, USA; 2019. p. 1–9.
Barcelona-Pons D, García-López P. Benchmarking parallelism in FaaS platforms. Fut Gener Comput Syst. 2021;124:268–84.
Wen J, Liu Y, Chen Z, Chen J, Ma Y. Characterizing commodity serverless computing platforms; 2020. https://doi.org/10.48550/ARXIV.2012.00992.
Acknowledgements
Partially funded by CNPq/AWS 64/2022 BioCloud2 (n\(^{\textrm{o}}\) 421828/2022-6).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there is no Conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the topical collection “Recent Trends on Cloud Computing and Services Science” guest edited by Claus Pahl and Maarten van Steen.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
de Carvalho, L.R., Kamienski, B. & Araujo, A. Main FaaS Providers Behavior Under High Concurrency: An Evaluation with Orama Framework Distributed Architecture. SN COMPUT. SCI. 5, 541 (2024). https://doi.org/10.1007/s42979-024-02895-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42979-024-02895-1