






文章目录
- 时间线:
- 一、经典论文
- 目标检测:
- 1.1 AlexNet-2012:ImageNet Classification with Deep Convolutional Neural Networks
- 1.2 OverFeat 2013
- 1.3 RCNN 2014
- 1.4 SPPNet 2014
- 1.5 VGGNet 2014
- 1.6 Faster RCNN 2015
- 1.7 YOLOV1 2015
- 1.8 ResNet 2015
- 1.9 SSD 2015
- 1.10 DenseNet 2016
- 1.11 YOLO9000 2016
- 1.12 FPN 2017
- 1.13 Mask RCNN 2017
- 1.14 RetinaNet 2017
- 图像分割:
- 1.15 FCN 2015
- 1.16 UNet 2015
- 1.17 SegNet 2016
- 1.18 Deeplab v1 2017
- 1.19 Deeplab v3 2017
- 1.20 CARAFE 2019
- 二、综述论文
- 2.1 Deep Learning for Generic Object Detection: A Survey
- 2.2 A Comprehensive Study of Real-Time Object Detection Net- works Across Multiple Domains: A Survey
- 2.3 Agricultural Object Detection with You Look Only Once (YOLO) Algorithm: A Bibliometric and Systematic Literature Review
- 2.3 基于深度学习的目标检测算法研究综述2020-曹燕,李欢,王天宝 ( 成都信息工程大学 四川 成都 610225)
- 2.4 基于深度学习的目标检测技术的研究综述-罗元,王薄宇,陈旭(重庆邮电大学光电工程学院,重庆 400065)
时间线:
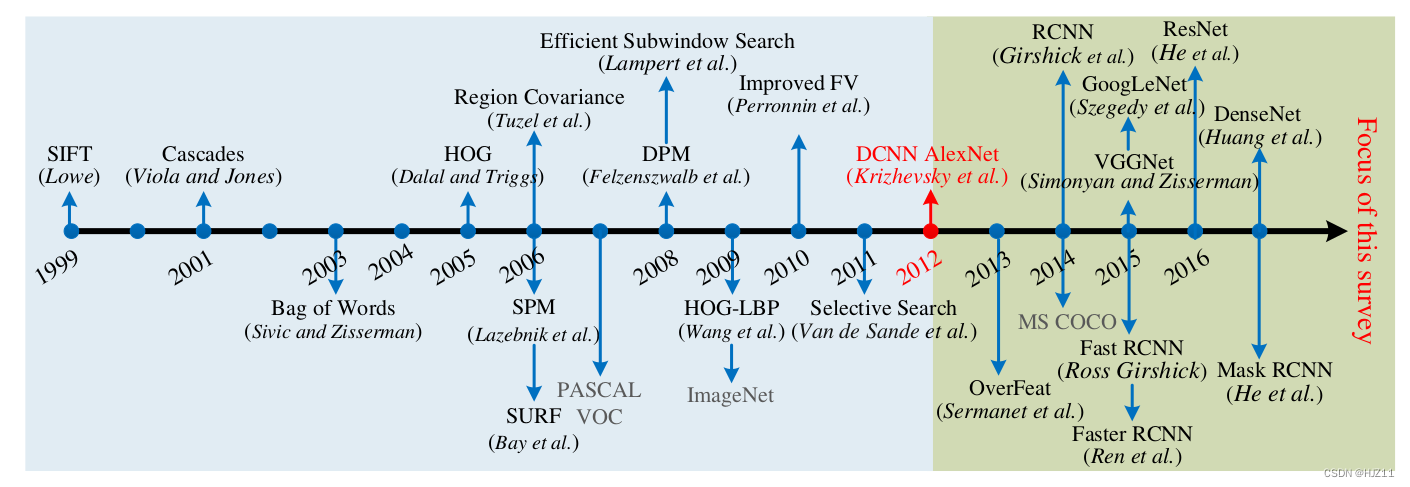

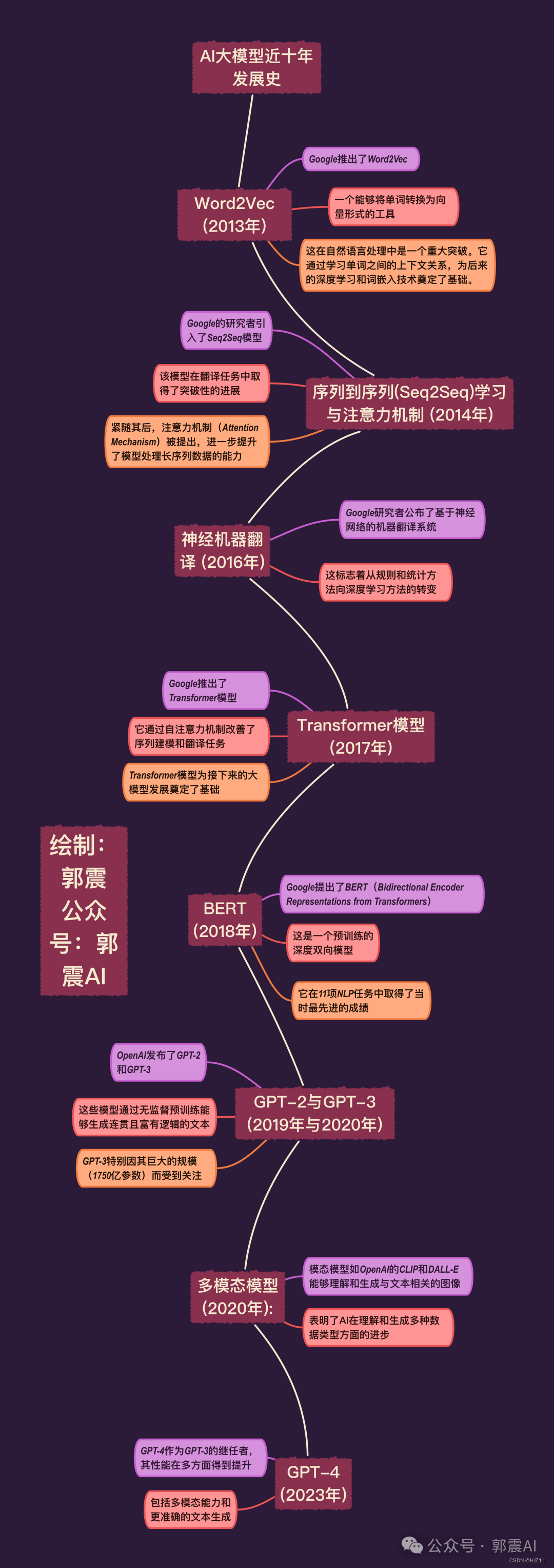
一、经典论文
目标检测:
1.1 AlexNet-2012:ImageNet Classification with Deep Convolutional Neural Networks
摘要:训练了一个大型深度卷积神经网络,ImageNet LSVRC-2010,ILSVRC-2012 竞赛,并取得了 15.3% 的获胜前 5 名测试错误率,而第二名的测试错误率为 26.2%。“dropout”的正则化方法.
1 引言:当前的物体识别方法充分利用了机器学习方法。为了提高它们的性能,我们可以收集更大的数据集,学习更强大的模型,并使用更好的技术来防止过度拟合。卷积神经网络(CNN)就是这样一类模型。它们的容量可以通过改变深度和广度来控制,并且它们还对图像的性质(即统计的平稳性和像素依赖性的局部性)做出强有力且基本正确的假设。我们编写了高度优化的 2D 卷积 GPU 实现以及训练卷积神经网络固有的所有其他操作,并公开发布。使用了几个防止过度拟合的有效技术。网络的大小主要受到当前 GPU 上可用内存量以及愿意容忍的训练时间的限制。网络需要五到六天的时间在两个 GTX 580 3GB GPU 上进行训练。我们所有的实验都表明,只需等待更快的 GPU 和更大的数据集可用,我们的结果就可以得到改善。
2 ImageNet 数据集是一个包含超过 1500 万张标记高分辨率图像的数据集,属于大约 22,000 个类别。ILSVRC 使用 ImageNet 的子集,每个类别包含大约 1000 个图像。总共大约有 120 万张训练图像、5 万张验证图像和 15 万张测试图像。 ImageNet 由可变分辨率图像组成,而我们的系统需要恒定的固定分辨率 256 × 256。,我们首先重新缩放图像,使短边的长度为 256,然后从生成的图像中裁剪出中央 256 × 256 的图像。除了从每个像素中减去训练集的平均活动之外,我们没有以任何其他方式预处理图像。因此,我们根据像素的(居中)原始 RGB 值来训练我们的网络。
3 架构:五个卷积层和三个全连接层;使用 ReLU 的深度卷积神经网络的训练速度比使用 tanh 单元的深度卷积神经网络快几倍。更快的学习对在大型数据集上训练的大型模型的性能有很大影响。
图 1:使用 ReLU(实线)的四层卷积神经网络在 CIFAR-10 上达到 25% 的训练错误率,比使用 tanh 神经元(虚线)的等效网络快六倍。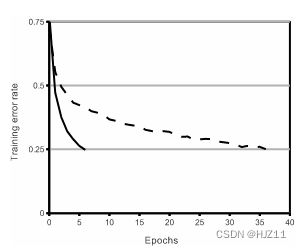
3.3 局部响应归一化,我们在某些层中应用 ReLU 非线性之后应用了这种归一化;响应归一化将 top-1 和 top-5 错误率分别降低了 1.4% 和 1.2%
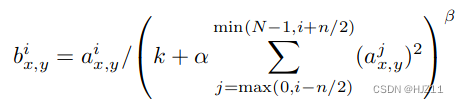
3.4 重叠池化,与非重叠方案 s = 相比,该方案将 top-1 和 top-5 错误率分别降低了 0.4% 和 0.3%
3.5 总体架构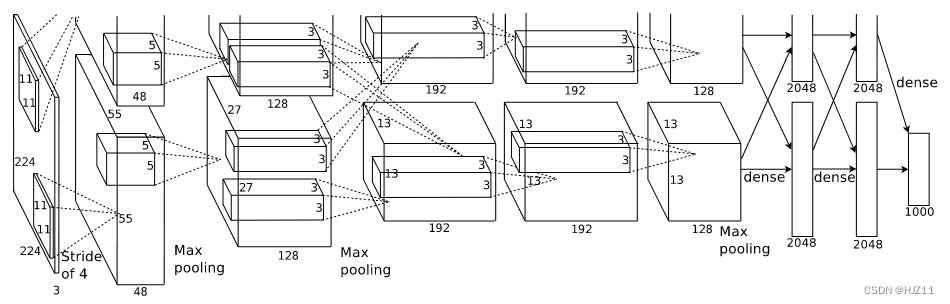
该网络包含八个带有权重的层;前五个是卷积的,其余三个是全连接的。最后一个全连接层的输出被馈送到 1000 路 softmax,生成 1000 个类标签的分布。
4 减少过度拟合
4.1 数据增强
数据增强的第一种形式包括生成图像平移和水平反射。我们通过从 256×256 图像中提取随机 224×224 块(及其水平反射)并在这些提取的块上训练我们的网络来实现此目的。在测试时,网络通过提取五个 224 × 224 补丁(四个角补丁和中心补丁)及其水平反射(因此总共十个补丁)来进行预测,并对网络的 softmax 层做出的预测进行平均在十个补丁上。数据增强的第二种形式包括改变训练图像中 RGB 通道的强度。具体来说,我们对整个 ImageNet 训练集中的 RGB 像素值集执行 PCA。对于每个训练图像,我们添加多个找到的主成分,
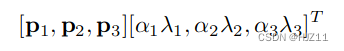
该方案大致捕捉了自然图像的一个重要属性,即对象身份对于照明强度和颜色的变化是不变的。该方案将top-1错误率降低了1%以上。
4.2 Dropout
以 0.5 的概率将每个隐藏神经元的输出设置为零。这项技术减少了神经元复杂的共同适应,因为神经元不能依赖于特定其他神经元的存在。因此,它被迫学习更强大的特征,如果没有 dropout,我们的网络就会表现出严重的过度拟合。 Dropout 大约使收敛所需的迭代次数增加了一倍。
5 学习细节
我们使用随机梯度下降法训练模型,批量大小为 128 个示例,动量为 0.9,权重衰减为 0.0005。我们发现这种少量的权重衰减对于模型的学习很重要。换句话说,这里的权重衰减不仅仅是一个正则化器:它减少了模型的训练误差。权重w的更新规则为:
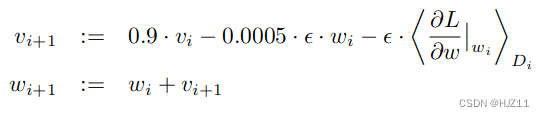
我们通过 120 万张图像的训练集对网络进行了大约 90 个周期的训练,这在两个 NVIDIA GTX 580 3GB GPU 上花费了五到六天的时间。
6 结果
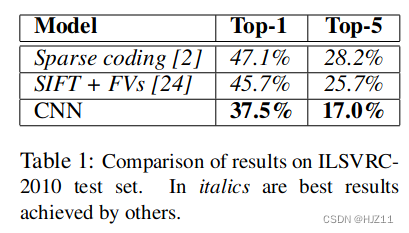
7 讨论
我们的结果表明,大型深度卷积神经网络能够使用纯监督学习在极具挑战性的数据集上取得破纪录的结果。深度对于实现我们的成果确实很重要。
最终,我们希望在视频序列上使用非常大和深的卷积网络。
1.2 OverFeat 2013
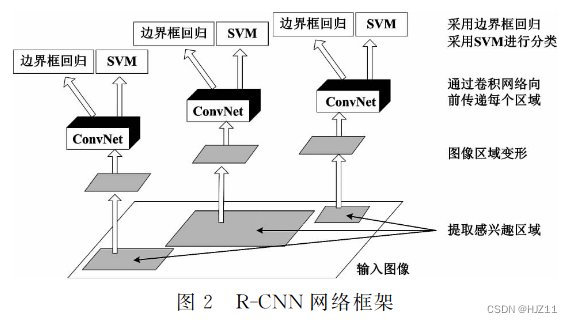
1.3 RCNN 2014
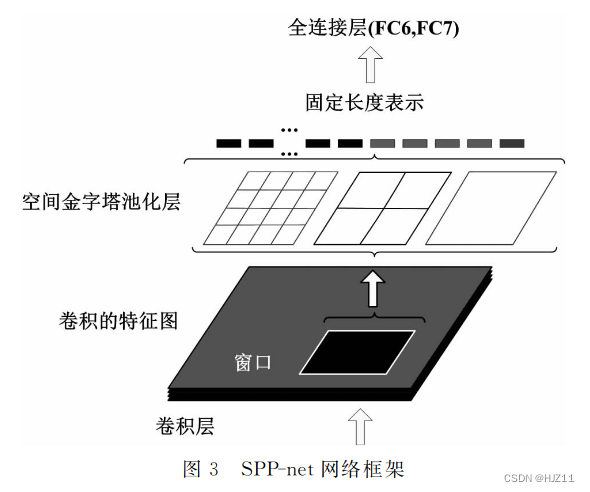
1.4 SPPNet 2014
1.5 VGGNet 2014
1.6 Faster RCNN 2015
1.7 YOLOV1 2015
1.8 ResNet 2015
1.9 SSD 2015
1.10 DenseNet 2016
1.11 YOLO9000 2016
1.12 FPN 2017
1.13 Mask RCNN 2017
1.14 RetinaNet 2017
图像分割:
1.15 FCN 2015
1.16 UNet 2015
1.17 SegNet 2016
1.18 Deeplab v1 2017
1.19 Deeplab v3 2017
1.20 CARAFE 2019
二、综述论文
2.1 Deep Learning for Generic Object Detection: A Survey
-Li Liu 1,2 · Wanli Ouyang 3 · Xiaogang Wang 4 ·
Paul Fieguth 5 · Jie Chen 2 · Xinwang Liu 1 · Matti Pietikäinen 2
Received: 12 September 2018
2.2 A Comprehensive Study of Real-Time Object Detection Net- works Across Multiple Domains: A Survey
2.3 Agricultural Object Detection with You Look Only Once (YOLO) Algorithm: A Bibliometric and Systematic Literature Review
2.3 基于深度学习的目标检测算法研究综述2020-曹燕,李欢,王天宝 ( 成都信息工程大学 四川 成都 610225)
摘要: 传统的目标检测算法主要依赖于人工选取的特征来对物体进行检测。深度学习作为一种特征学习方法能够自动学习到目标 的有用特征,避免了人工提取特征,同时能够保证良好的检测效果。本文首先介绍基于深度学习的目标检测算法研究进 展,其次总结目标检测算法中常见的难题与解决措施,最后对目标检测算法的可能发展方向进行展望。
-
目标检测主要是对输入图像中的物体类别和 位置进行判 断,实质上是图像分类和目标定位的结 合,是计算机视觉领域中的一个重要研究方向。
-
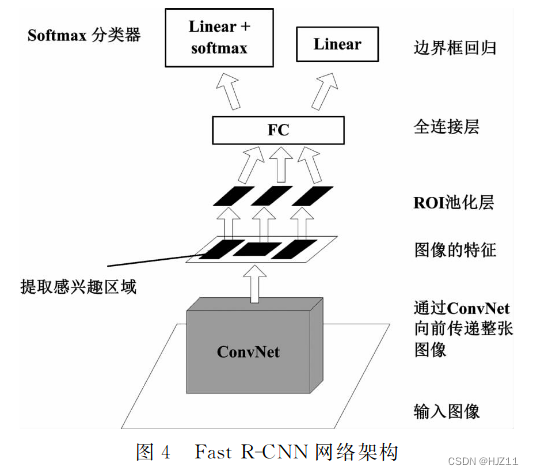
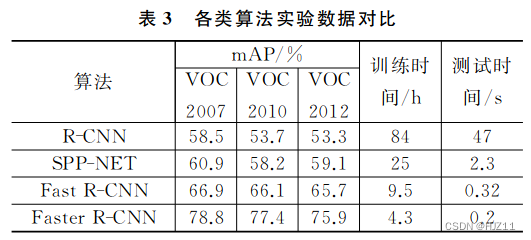
基于分类的检测算法小结: 目标检测算法不仅要求有较高的准确度,同时也 要求能够满足实时性。R-CNN、SPP-Net、Fast R-CNN
采用 Selective Search 的方法相对于传统目标检测算 法在精度和速度上都有所提升。但 由 于 Selective
Search 聚类方法会消耗大量的时间,现在基于分类的 方法比如 Faster R-CNN、FPN、Mask R-CNN 等大多使 用
RPN 来产生候选区域,在速度和精度上又有了进一步提升,但实时性仍不理想 -
基于回归的检测算法小结 :基于回归的目标检测算法在速度上相对于基于 分类的算法有大幅提升,基于分类的目标检测算法主
要优势在于较高的精确度。随着算法的改进,一些基 于回归的目标检测算法既有较高的精度又有较快的
检测速度,其精确度甚至超过大部分基于分类的目标 检测算法 -
总结:近年来,目标检测算法蓬勃发展,基于深度学习 的目标检测框架仍是目标检测任务的主流方向。目 前大部分目标检测算法采用 anchor
机制,在特征图 上产生大量密集的 anchor,再对这些 anchor 进行进一 步的分类和位置校准。但大量 anchor 容易产生正负
样本不平衡的问题,同时针对不同数据集需要设置不 同尺度与长宽比的 anchor。如何设计合适的 anchor
还需要进一步研究。一些研究人员尝试使用 anchorfree 的方法[62-63]来检测目标,但这一类方法对主干网
络的要求相对较高。除此之外,如何优化目标检测框 架,设计更好的损失函数、更适合目标检测任务的网
络来更好地提取特征仍旧是未来目标检测算法的重 点研究方向。”
2.4 基于深度学习的目标检测技术的研究综述-罗元,王薄宇,陈旭(重庆邮电大学光电工程学院,重庆 400065)
摘 要 : 文章首先对国内外目标检测技术的最新研究进展进行了梳 理 ,并分析和总结了传统目标检测方法的优缺点;然后详细介绍了几种基于深度学习的目标检测技 术 及 其 优 缺 点 ;最后讨论了现阶段深度学习存在的问题和未来的发展方向。
1 传统目标检测的研究现状:传 统 的 目 标 检测算法还存在以下三点问题:
1)基于滑动窗 口 的 目 标 区 域 检 测 方 法 耗 时 长、 窗口存在冗余;
2)基 于 手 工 提 取 的 特 征 信 息 在 面 对 环 境 多 样 性 的变化条件下鲁棒性较差;
3)对 于 大 数 据 的 视 频 或 图 片 信 息 的 处 理 能 力 较 差 ,计 算 能 力 有 限 。
2 基于深度学习的目标检测的研究现状
““双 阶 段 ”目 标 检 测 算 法 框 架 的 技 术演进 过 程是:R-CNN→SPP-net→Fast R-CNN→ Faster R-CNN→Mask R-CNN。”
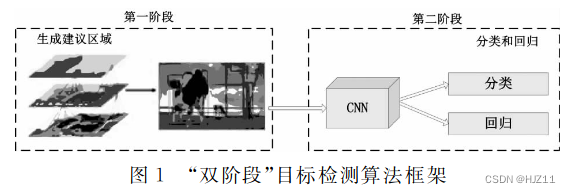

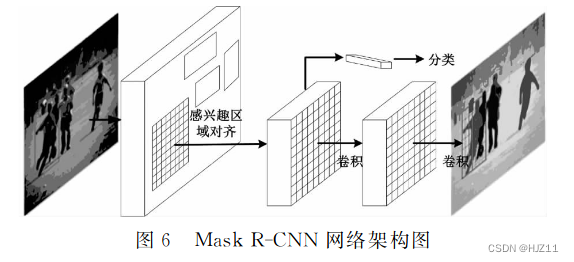
单阶段:
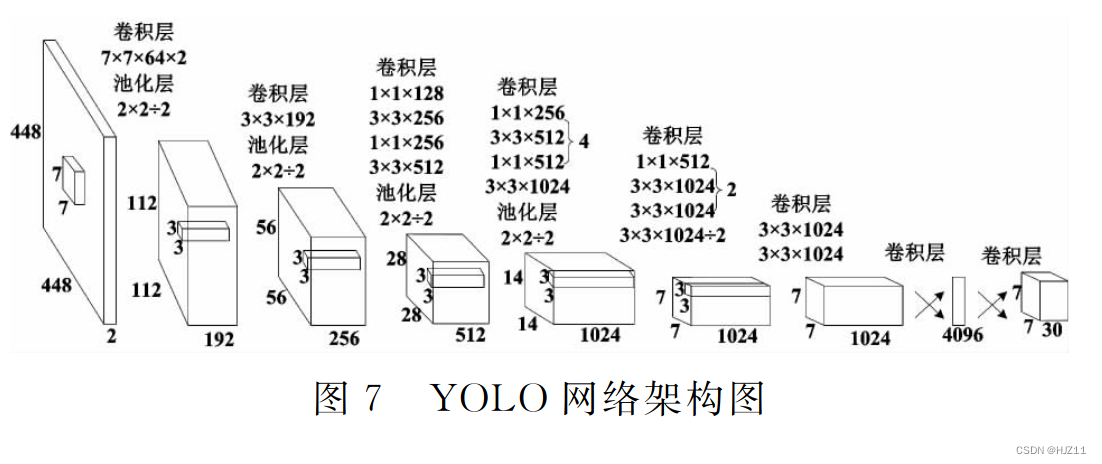
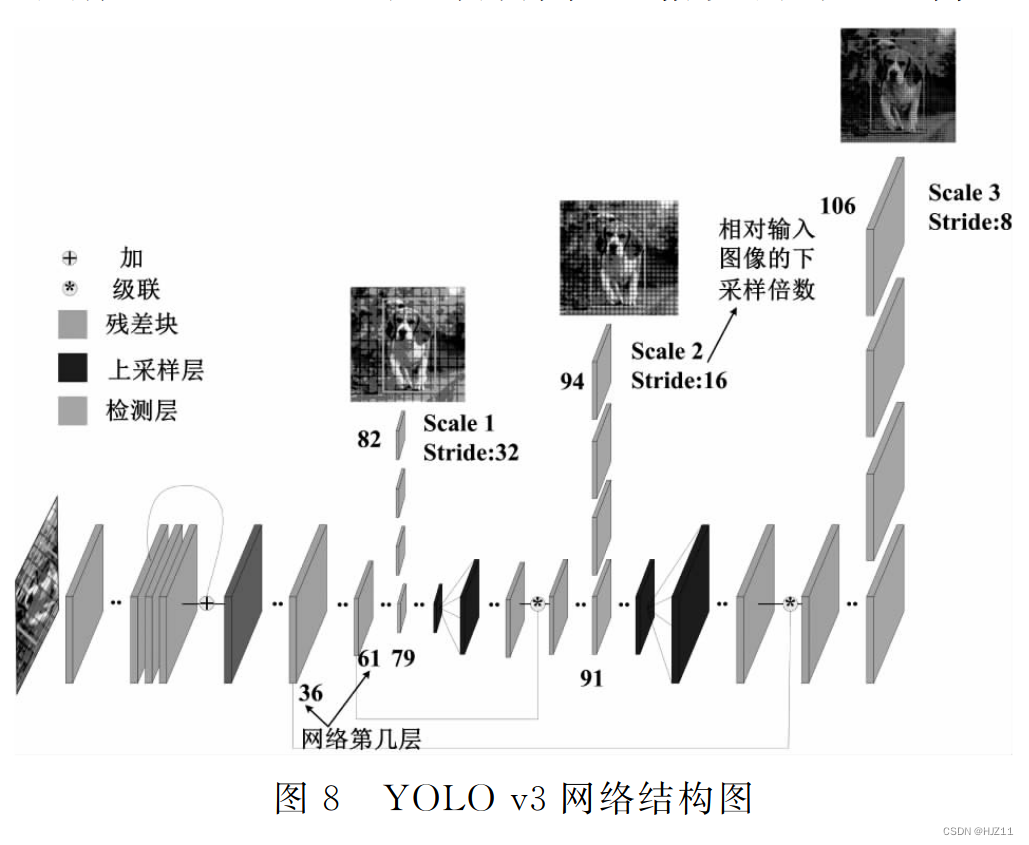

64G内存+GTX1080Ti:
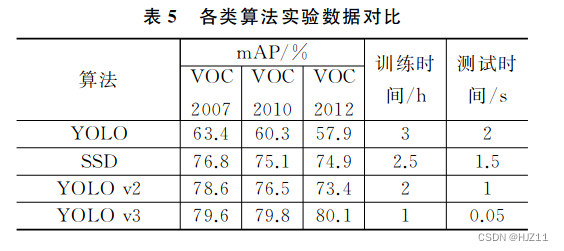

ImageNet是目前 世 界 上 图 像 识 别 领 域 最 大 的数据 集。 如 图 11 所 示,ImageNet数 据 集 总 共 有 1 500万张图片,分 为 2.2 万 类,且 每 一 张 图 片 都 经 过人工的严格筛选与标记。

















 1163
1163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









